



作者 | AI 驾驶员 编辑 | 智驾实验室
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文

本报告介绍了2024年自主挑战赛的第一名解决方案——无需地图的驾驶。在报告中,作者引入了一种新颖的在线地图构建流程LGmap,该方法采用长距离时间模型。
首先,作者提出了对称视角变换(SVT),一个混合视角变换模块。作者的方法克服了正向稀疏特征表示的限制,并利用深度感知和SD先验信息。
其次,作者提出了分层时间融合(HTF)模块。它从局部到全局利用时间信息,这增强了构建具有高稳定性的长距离高清地图的能力。最后,作者提出了一种新颖的人行横道重采样方法。简化的行人横道表示加速了基于实例注意力的解码器的收敛性能。
作者的方法在无需地图的驾驶OpenLaneV2测试集上达到了0.66的UniScore。
1 Introduction
高清晰度(HD)地图是为高精度自动驾驶设计的,它包含实例 Level 的矢量表示,如人行横道、车道分隔线、道路边界等。道路拓扑和交通规则的丰富语义信息对自动驾驶导航至关重要。无地图驾驶轨迹[2]旨在从车载周围摄像头图像和SD地图动态构建局部HD地图。在这项工作中,作者提出了一种多阶段框架,将2D/3D元素检测和拓扑预测任务解耦。
作者的方法主要关注三个方面来应对竞争。
从近到远的融合。作者提出了一种创新的方法,将前向投影和后向投影策略与SD地图融合和深度监督相结合。
从局部到全局的融合。作者提出了一种新颖的在线地图构建流程,适用于短距离和长距离,整合了流式策略和堆叠策略。
人行横道重采样。作者将人行横道简化为4个角点,然后在每条边上均匀采样6个点。
2 Method
本节介绍了作者方法的具体细节。作者首先介绍LGmap架构的主要流程,如图1所示。然后呈现区域组件和车道线段组件。此外,作者引入了交通元素。最后,作者描述了基于注意力的拓扑推理头。
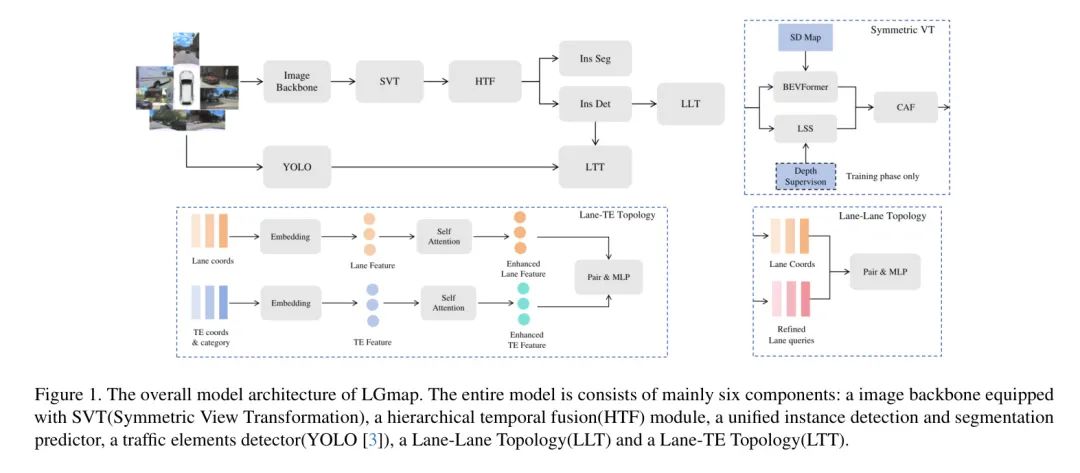
Pipeline
2.1.1 Encoder
主要有两种视图变换类型,正向投影和反向投影。Lift-Splat-Shoot (LSS)[4] 利用深度分布来模拟每个像素深度的不确定性。但正向投影的缺点是离散且稀疏的鸟瞰图(BEV)表示。BEVFormer [5] 将3D点反向投影回2D图像。作为一种反向投影,BEVFormer的一个局限性是由于遮挡导致的3D与2D空间之间的虚假相关性。为了解决这些问题,作者引入了一种对称视图变换。每个相机的深度图是从与激光雷达点云同步生成的。LSS只在训练阶段使用深度监督。给定场景的SD图,作者沿着每条多段线均匀采样固定数量的点。通过正弦嵌入,BEVFormer在每个编码器层将SD图的特性表示与来自视觉输入的特性之间应用交叉注意力。为了融合BEV表示,作者使用了基于通道注意力的融合模块。
2.1.2 Decoder
为了处理具有不同形状先验的不同地图元素,作者扩展了实例级检测解码器,增加了额外的分割任务。基于统一 Transformer 的实例检测和分割解码器从像素级分类任务和区域级回归任务中受益。额外的分割分支加快了实例级特征嵌入的收敛性能。
2.1.3 Temporal fusion
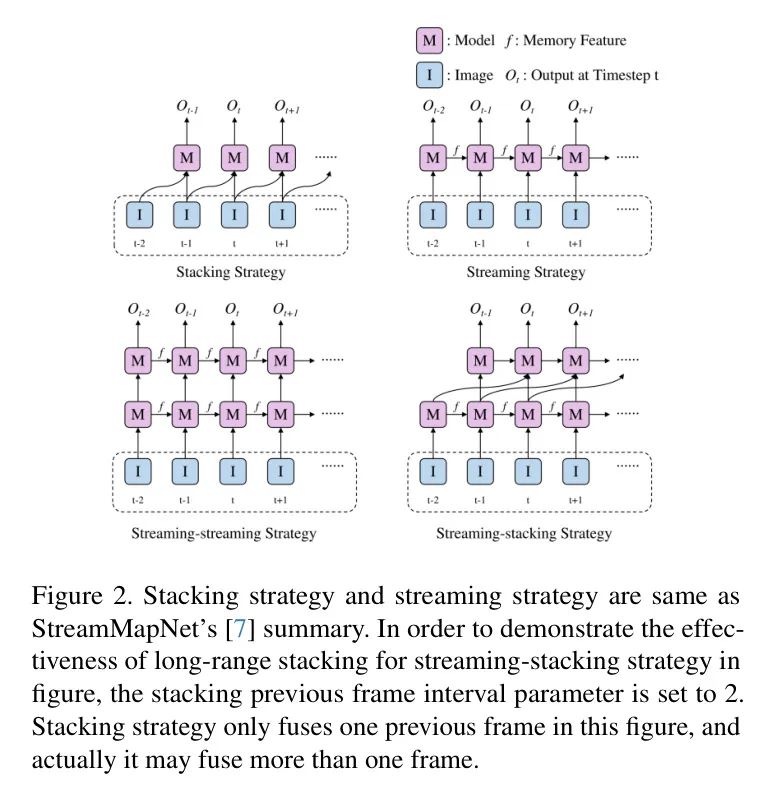
流式策略有助于更长时间的时间关联,因为传播的隐藏状态编码了所有历史信息。但是,像convGRU [6]这样的时间融合器仍可能面临遗忘问题。堆叠策略可能整合来自特定先前帧的特征,提供了在长距离信息融合中的灵活性。计算成本与融合的帧数线性相关。作者提出了一种新颖的分层时间融合(HTF)。分层时间融合充分利用了流式策略的局部融合能力和堆叠策略的长距离融合能力。与堆叠策略相比,它最大限度地减少了内存和延迟成本。在这里,作者介绍了HTF的两个变体,即流式-流式策略和流式-堆叠策略,如图2所示。对于流式-堆叠策略,在训练阶段,作者从最新的M个先前帧中随机选择N帧用于堆叠模式层。在测试阶段,通过一定的距离步长选择N帧。
2.1.4 Loss functions
首先,作者采用了与MapTR [8]相同的分类损失、点对点损失和边缘方向损失。其次,作者采用了与MapTRv2 [9]相同的图像分割辅助密集预测损失和深度预测损失。第三,作者采用了BEV实例分割损失。最后,作者采用了几何3D损失。与忽略Z轴的GeMap [10]的几何损失不同,作者将欧几里得损失的维度从2D扩展到3D。### 区域
受到Machmap [11]的启发,作者将人行横道简化为四个角。然后将这四个角统一为MapTR形式的N个点。主要区别在于MapTR使用20个均匀采样的点,MachMap使用4个点,而作者沿着每条边均匀采样6个点,如图3所示。
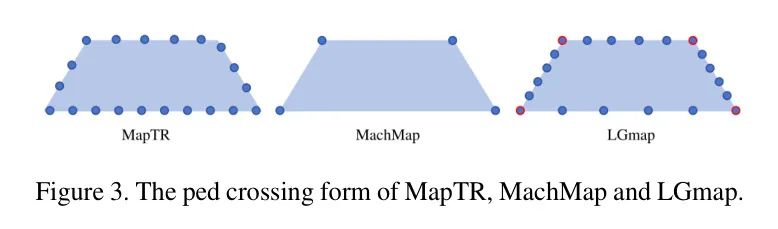
作者的人行横道表示保留了四个角作为关键点,这些是基本的形状先验。更重要的是,人行横道的排列比MapTR简单。与一个20个点的多边形MapTR的40个等效排列相比,LGmap只需要8个。作者不使用逐点排列,而只使用角点排列。最后,保留角点有利于实例 Query 嵌入。
Lane segments
基于回归分支的中心线输出,引入了一个偏移分支来预测左右车道边界的位置偏移,并引入两个分类分支来预测车道边界的属性,参考LaneSegNet [2]。
Traffic elements
作者采用YOLOv8作为基本的2D检测器,并且额外使用YOLOv9[3]进行模型集成。基于OpenlaneV2数据集,作者提出了一系列数据增强方法,不包括HSV变换和水平翻转,因为这些技巧可能导致交通灯和交通标志方向的混淆。数据集中类别的分布高度不平衡,有些类别的差异达到一个数量级。此外,在测试集上生成的伪标签也提高了结果。作者采用测试时增强(TTA),缩放范围在0.7-1.4之间,以改善小物体和大物体的召回率。
Lane-Lane topology
作者使用了TopoMLP方法[12]。首先,作者将中心线坐标传递给MLP,并将其添加到精炼的 Query 特征中。最后,作者应用MLP进行拓扑分类。
Lane-Traffic topology
作者使用中心线的坐标以及交通元素边界框的坐标和类别。由于没有使用特征嵌入,作者使用车道段和交通元素的真实数据进行拓扑模型的训练。通过与上游检测模型的解耦,拓扑的训练和预测过程变得更加方便。由于交叉口的复杂性,作者使用自注意力来促进元素间的信息交换并获得相对关系。
3 Experiments
Implementation details
作者基于MapTRv2代码库[9]构建了作者的系统。训练设置。作者采用了两种数据增强方法,分别是图像数据增强和BEV数据增强,例如随机旋转、缩放、裁剪和翻转。为了进行消融研究,作者使用了在ImageNet数据集上预训练的ResNet50[13]。并将ViT-L[14]作为放大图像 Backbone 网络。作者使用nuScenes数据集通过向量地图构建任务对ViT模型进行预训练。在训练大规模模型时,作者在16个A800 GPU上使用批量大小为16,使用AdamW[15]优化器,学习率为6e-4。层级的 学习率衰减为0.9。ViT的部分冻结块数量为3。输入图像的分辨率为。并且,从 Backbone 网络中的图像特征以16的步长进行下采样。深度网络预测从1米到56米的深度。BEV特征图的分辨率为。作者通过两个阶段训练模型。单帧模式训练48个周期,流式堆叠模式训练36个周期。在时间融合模式期间,作者将ViT的部分冻结块数量改为12。并关闭图像和BEV数据增强。
Ablation Study
3.2.1 SymmetricVT
作者通过消融研究来检验SVT组件的有效性,使用OpenlaneV2数据集[1]。以BEVFormer [5]和LSS [4]作为 Baseline ,表1显示在验证集上最佳得分为40.36%。与最佳 Baseline 相比,结合BEVFormer和LSS使mAP提高了0.5%。在加入图像数据增强和BEV数据增强后,模型性能提升到了43.75%。
3.2.2 时间融合

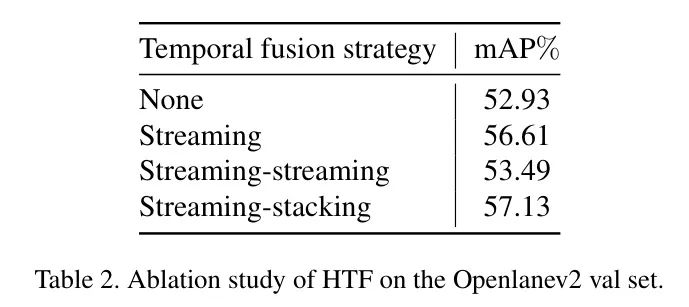
作者通过训练72个周期的ResNet50预训练权重建立了一个单帧 Baseline 模型。然后所有实验都通过12个周期微调 Baseline 模型。作者使用单帧模式微调 Baseline 模型,模型可以达到52.93%的mAP得分,如表2所示。对于流式策略,作者使用一个convGRU [6]作为密集融合编码器。其性能提高了3.7%。对于流式-流式策略,使用两层而不是一层的convGRU。不幸的是,与单帧相比,性能只提高了0.56%。对于流式-堆叠模式,在训练阶段作者从最近的10帧中选择4帧用于堆叠模式的层,并在测试阶段使用一定的距离步长5、10、15、20米。性能达到了57.13%的mAP。
3.2.3 Ped crossing resampling
作者使用了与MapTR相同的基于分层注意力解码器作为 Baseline 。如表3所示,模型的性能达到了33.6%的DET-a得分。然后作者将解码器改为实例注意力,模型的性能提升了0.45%。最后,作者利用行人过街重采样来将性能提升到35.42%。

3.2.4 Traffic elements
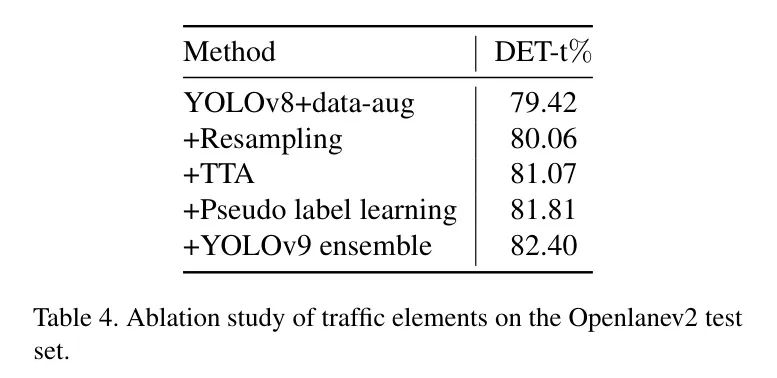
作者使用COCO预训练模型,并对其进行40轮微调作为作者的2D检测器 Baseline 。数据集通过5到20倍的比例进行重采样。整个模型使用AdamW优化器进行优化,学习率为0.04,分辨率为。然后作者通过0.3的阈值生成伪标签。如表4所示,采用数据增强的YOLOv8-x在DET-l上的得分可以达到79.42%。重采样的应用性能提高了0.64%。TTA进一步提高了1.0%的得分。作者使用伪标签将性能提升到81.81%。最后,YOLOv8和YOLOv9[3]的模型集成将性能提升到82.4%。
3.2.5 Lane segments
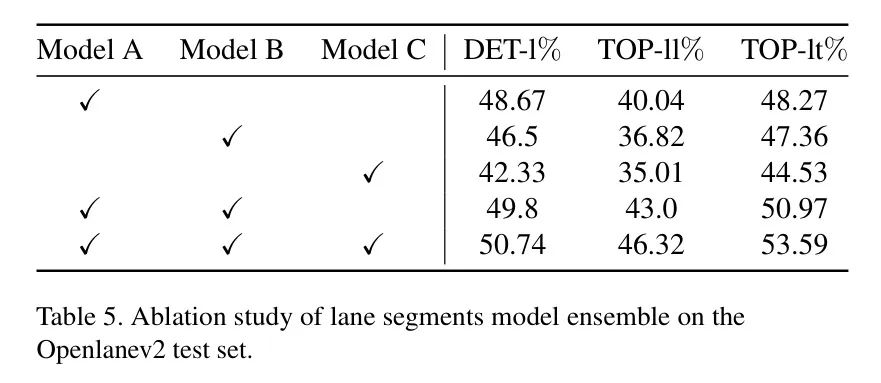
作者训练了三个版本的模型,使用了不同的 Backbone 网络(ViT [14], InternImage-XL [16])以及不同的输入图像分辨率比例(0.5, 0.75, 1)。在集成过程中,作者采用了一种融合策略,该策略结合了相似度较低的预测。最初,模型按照它们的评估分数排序,最佳模型作为基础模型,其余两个模型随后作为 Proposal 模型进行整合。从表5中可以看出,集成的模型越多,性能提升越显著。
4 Conclusion
在这项工作中,作者重新思考了无地图驾驶中2D/3D元素检测和拓扑推理的流程。首先,作者采用对称视角变换(SVT)将正向投影和反向投影相结合,以形成互补优势。其次,作者引入分层时间融合(HTF)技术,以稳定地从局部到全局整合时间特征。
此外,作者通过一种新颖的重采样方法改进了行人横穿表示。最终,LGmap是 无地图驾驶赛道上的第一名解决方案,达到了0.66的UniScore。
参考
[1].LGmap: Local-to-Global Mapping Network for Online Long-Range Vectorized HD Map Construction.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 1159
1159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









