






Bring Reason to Vision
论文标题:Bring Reason to Vision: Understanding Perception and Reasoning through Model Merging
论文链接:https://arxiv.org/abs/2505.05464
代码:https://github.com/shiqichen17/VLM_Merging
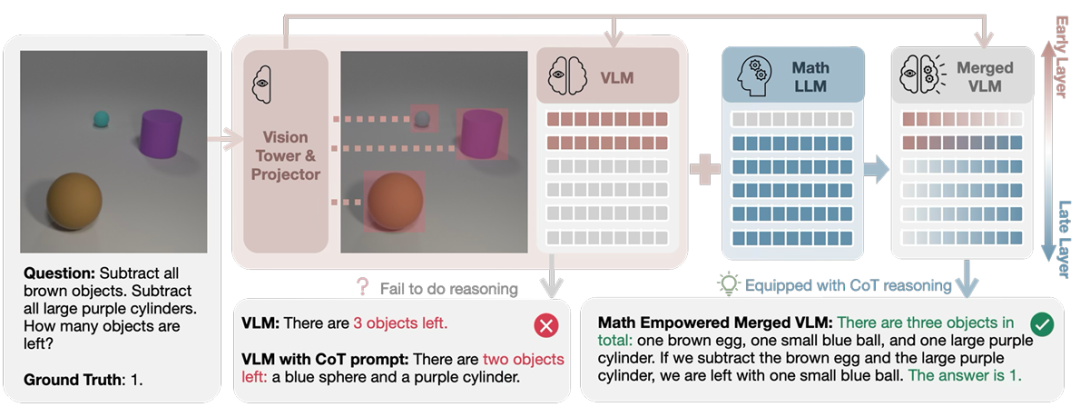
核心创新点:
1. 跨模态模型合并框架(Cross-Modal Model Merging)
提出首个通过参数空间算术操作(如线性加权)将大语言模型(LLM)的推理能力 迁移至视觉-语言模型(VLM)的无训练范式。该方法聚焦于VLM的语言模型组件与LLM的融合,保留视觉塔与投影器不变,突破了传统同构模型合并(如仅合并VLM或LLM)的局限性。
2. 感知与推理能力的层级解耦(Layer-wise Capability Disentanglement)
通过遮蔽分析(Knockout Analysis)首次揭示:
感知能力 (如图像特征提取、基础语义理解)主要编码于模型早期层 (Early Layers);
推理能力 (如数学链式思维、逻辑推导)集中于中晚期层 (Middle-to-Late Layers)。
模型合并后,推理能力扩散至全层,而感知能力分布保持稳定,验证了参数空间中两类能力的解耦性。
3. 推理能力迁移的零成本机制(Training-Free Reasoning Transfer)
通过任务向量(Task Vector)操作实现推理能力的高效迁移:
定义LLM任务向量(
τ<sub>reason</sub>=θ<sub>reason</sub> - θ<sub>base</sub>)与VLM语言模型任务向量(τ<sub>vlm</sub> = θ<sub>vlm</sub> - θ<sub>base</sub>);通过
θ'<sub>vLM</sub> = θ<sub>base</sub> + λτ<sub>vlm</sub> + (1-λ)τ<sub>reason</sub>实现能力融合,λ控制多模态平衡。
该方法无需微调或数据,仅依赖参数插值,在MathVista等基准测试中绝对提升达3.6%。
4. 多模态推理的可扩展性分析(Scalability of Reasoning)
揭示合并模型的推理能力通过链式思维扩展 (Chain-of-Thought Scaling)体现:
推理密集型任务(如几何证明、代数计算)的回答长度平均增加250%,准确率提升与长度增长呈线性正相关;
视觉主导任务(如图像问答)性能波动微小,验证了能力迁移的选择性。
5. 模型解释工具(Interpretability via Merging)
将模型合并作为探针工具,量化分析参数空间功能区域:
替换VLM参数为LLM/均匀分布,定位感知关键层(早期MLP/Attention);
遮蔽合并模型参数,验证推理能力增强层(中晚期MLP/Attention);
提出“1/N噪声注入”评估模块绝对贡献度,发现早期-中期层对VLM性能具有不可替代性。
本文均出自『自动驾驶之心知识星球』

DSDrive
论文标题:DSDrive: Distilling Large Language Model for Lightweight End-to-End Autonomous Driving with Unified Reasoning and Planning
论文链接:https://arxiv.org/abs/2505.05360
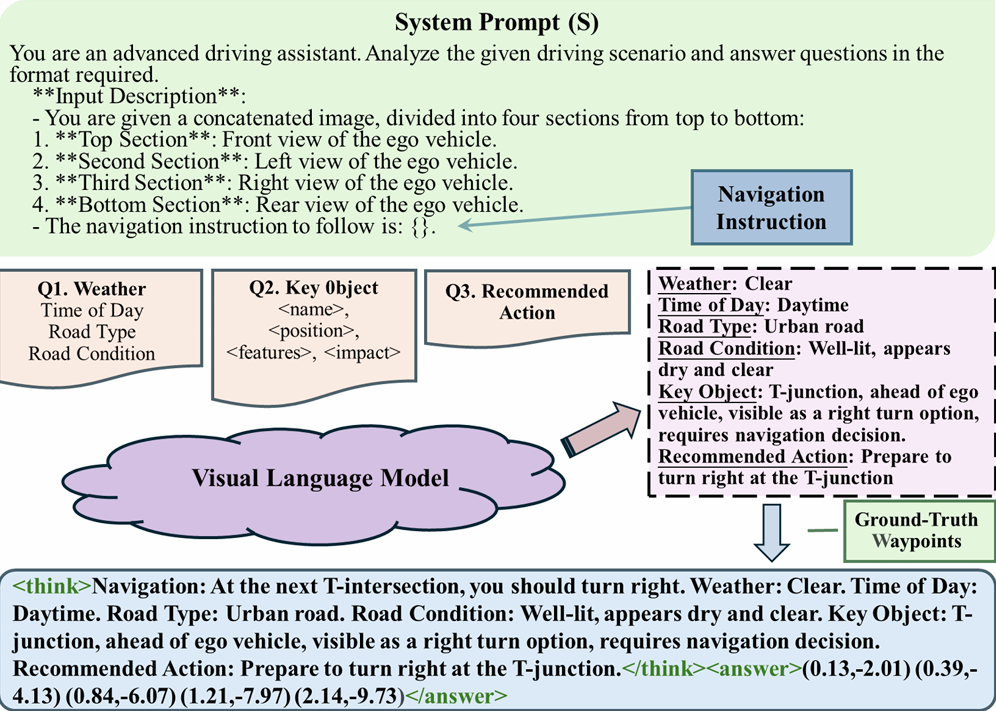
核心创新:
1. 基于知识蒸馏的轻量化LLM架构
提出DSDrive框架 ,通过知识蒸馏 (knowledge distillation)将大规模视觉语言模型(VLM)的推理能力迁移至轻量级大语言模型(LLM)。采用Qwen2.5-VL-max 生成结构化推理数据集(包含场景理解、关键对象识别、驾驶策略制定),使紧凑型LLM(LLaMA-1B)在保持低计算开销的同时实现类比大模型的推理性能。
2. 航路点驱动的双头协调模块
设计waypoint-driven dual-head coordination module ,首次将高层语义推理与低层轨迹规划统一于单一框架。该模块通过以下机制实现协同:
目标对齐 :将航路点预测结果作为推理过程的最终答案,使推理任务与规划任务共享优化目标(joint optimization objective)。
多任务学习 :通过CoT reasoning predictor 与waypoint predictor 的联合训练,同步优化推理文本生成与航路点坐标预测,增强系统可解释性(explainability)。
3. 基于链式思维(CoT)的端到端训练范式
构建显式"思考-回答"(think-and-answer)数据集 ,利用VLM生成包含多阶段推理(scenario comprehension → strategic planning → human-interpretable explanation)的结构化标签,并通过teacher-forcing策略 训练轻量级模型复现该过程。在推理阶段采用自回归生成(autoregressive generation)实现闭环规划。
4. 闭环自动驾驶性能验证
在CARLA仿真环境中完成端到端闭环测试,证明DSDrive在Driving Score(DS) 、Route Completion(RC)等指标上优于基线模型(如LMDrive-LLaVA-7B),同时内存占用降低43.5%(8082MB vs. 14263MB),推理时延达工业级应用水平(0.05s/step)。
X-Driver
论文标题:X-Driver: Explainable Autonomous Driving with Vision-Language Models
论文链接:https://arxiv.org/abs/2505.05098
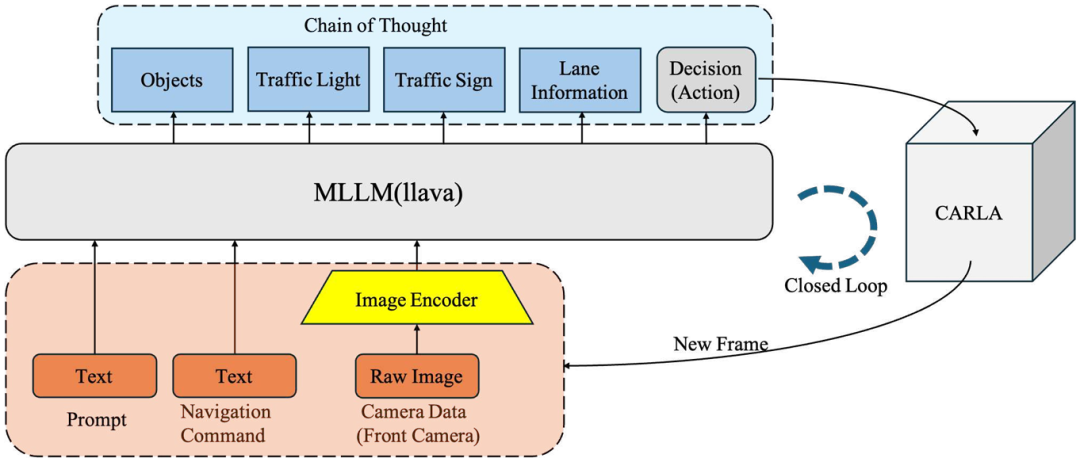
核心创新点:
1. 多模态大语言模型(MLLM)与Chain-of-Thought(CoT)融合架构
创新性 :首次将基于CoT的推理机制 引入端到端自动驾驶系统(X-Driver),通过结构化推理链(如物体检测→交通规则解析→决策生成)提升模型决策的可解释性 与鲁棒性 ,显著降低传统MLLM的幻觉(hallucination)问题。
技术实现 :采用LLaVA架构,结合自回归Transformer 进行多模态融合(视觉输入+文本导航指令),通过监督微调(SFT)优化CoT推理能力,分解复杂驾驶任务为可解释的子任务(如动态物体轨迹预测、交通规则匹配、车道状态分析)。
2. 统一闭环自动驾驶框架设计
闭环控制机制 :构建端到端闭环系统 ,通过实时感知-推理-决策-执行的反馈循环(CARLA仿真验证),实现动态环境适应能力,突破传统模块化系统依赖固定格式传感器输入的局限性。
多模态泛化能力 :支持非结构化输入 (如自然语言指令、多视角视觉数据),提升系统在复杂场景(如天气变化、道路施工)中的泛化性能。
3. 连续视觉编码与高精度场景理解
编码优化 :摒弃易导致信息丢失的离散编码(如VQ-VAE),采用连续视觉编码 (ViT特征图),保留关键细节(如远距离交通信号灯识别),提升3D场景理解精度(实验显示3D IoU达0.806)。
安全关键推理 :通过CoT显式建模风险感知与交通规则约束 (如行人横穿、车道变道合法性判断),确保决策符合安全准则(如碰撞规避、限速遵守)。
4. 闭环评估性能突破
基准测试表现 :在Bench2Drive数据集(200万帧)上,X-Driver以57.8% Success Rate 和51.7 Driving Score 超越当前SOTA方法(UniAD的49.1/45.9),验证了CoT对复杂闭环场景(如路口通行、匝道驶出)的决策有效性。
消融实验证明 :CoT版本在行人检测等关键任务中显著优于辅助任务基线模型(碰撞率降低至0%),体现结构化推理对关键安全场景的保障作用。
DenseGrounding
论文标题:DenseGrounding: Improving Dense Language-Vision Semantics for Ego-Centric 3D Visual Grounding
ICLR 2025论文链接:https://arxiv.org/abs/2505.04965
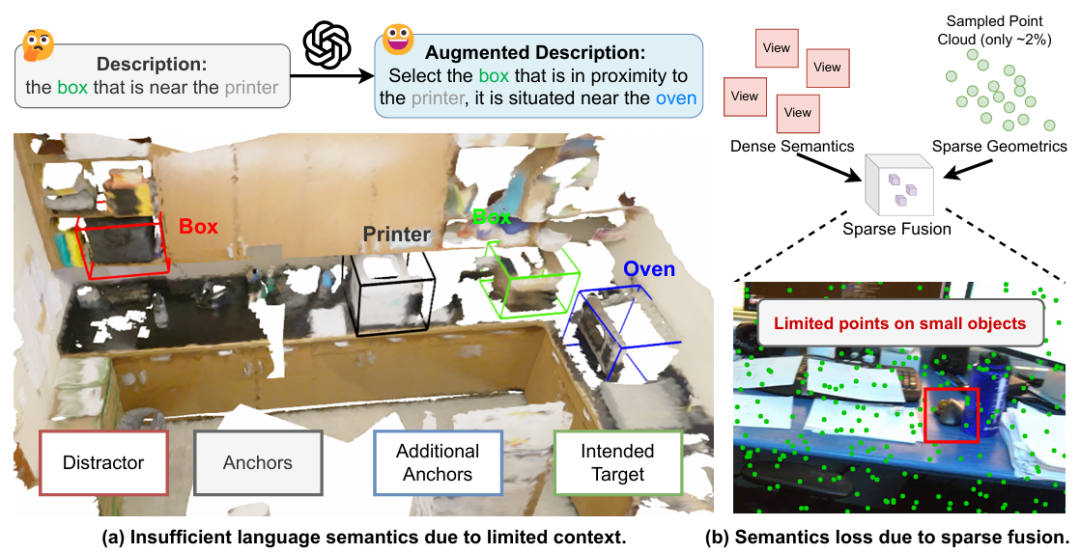
核心创新点:
1. 分层场景语义增强器(HSSE)
视图级语义聚合 :通过多尺度特征金字塔网络(FPN)整合单视角RGB图像的细粒度语义,利用跨注意力机制提取视图级全局语义特征(FˆQv),并结合自注意力建模视角内关系。
场景级语义交互 :将多视角语义(FˆQv)与语言特征(FLang)联合输入自注意力模块(Lscene层),实现跨模态语义对齐与场景级多视角交互,生成包含全局场景语义的增强特征(Fˆv′Q)。
语义广播机制 :将场景级语义(Fˆv′Q)通过跨注意力注入深度重建点云的多尺度特征图(Fs,vSem),在稀疏点云中恢复细粒度物体细节,缓解因点云采样导致的语义丢失问题。
2. 基于大语言模型的语言语义增强器(LSE)
场景信息数据库(SIDB)构建 :基于数据集中3D检测标注(物体名称、3D边界框)构建结构化数据库,包含物体空间关系(R)与位置信息(L),为语言增强提供上下文支撑。
LLM驱动的描述增强 :设计面向空间推理的提示模板,利用SIDB中k近邻描述(k=50)引导LLM生成包含多参考锚点(如"靠近冰箱、位于吊灯下方、毛巾前方")的多样化描述,显著降低自然语言歧义。
3. 技术突破与性能提升
在EmbodiedScan基准上,DenseGrounding以5.81% (全数据集)和7.56% (mini数据集)的绝对增益刷新SOTA,尤其在复杂场景(同类物体≥3个)中提升4.14% 。
提出稀疏点云语义稠密化 与语言描述上下文扩展 的协同优化框架,解决了传统方法中视觉语义稀疏(仅保留~2%点云)与文本描述模糊的双重瓶颈。
Perception
论文标题:Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
论文链接:https://arxiv.org/abs/2505.04921
项目主页:https://github.com/HITsz-TMG/Awesome-Large-Multimodal-Reasoning-Models
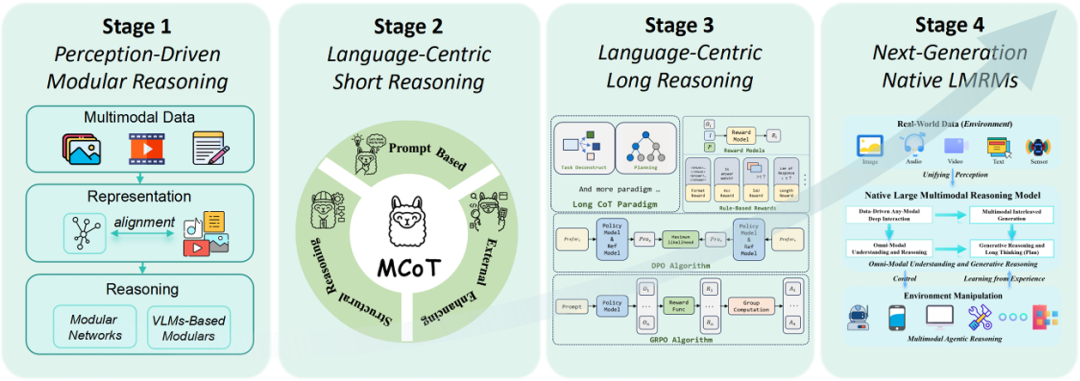
核心创新点:
1. 系统化的三阶段发展路线图
阶段演进 :提出从模块化推理 (Modular Reasoning)到多模态链式思维 (Multimodal Chain-of-Thought, MCoT),最终迈向长视野系统2推理 (Long-Horizon System-2 Reasoning)的三阶段技术路径。
技术内涵 :
MCoT扩展 :通过跨模态推理链(Cross-Modal Reasoning Chains)实现文本、图像、视频等多模态协同推理。
系统2推理 :引入类人深度认知机制(Kahneman, 2011),强调慢速、可解释的逻辑推导,而非单一功能映射。
2. Native LMRMs架构设计
原生多模态推理模型 (Native Large Multimodal Reasoning Models, N-LMRMs):
跨模态形式化 (Cross-Modal Formalization):统一不同模态的表示空间(如R1-OneVision模型),支持多模态联合推理。
强化学习集成 :通过视觉强化微调 (Visual-RFT)和工具增强策略 (Tool-Augmented Reasoning)提升泛化能力(如Retool、LMM4LMM)。
知识蒸馏 :利用规则驱动的RL (Rule-Based RL)和关键点数据合成 (Key-Point-Driven Data Synthesis)优化数学推理(如Marco-O1、R1-OMNI)。
3. 多模态推理范式创新
四阶段推理流程 :超越传统“思考→回答”范式,提出摘要 (Summary)、描述 (Caption)、推理 (Thinking)、答案生成 (Answer)四阶段协同机制(如TextCoT、Image Overview)。
动态推理策略 :
测试时扩展 (Testing-Time Scaling):结合蒙特卡洛树搜索 (MCTS)与共识推理 (Consensus Among LLMs)提升复杂任务性能(如Mulberry、ReConcile)。
交互式推理 :通过主动检索 (Active Retrieval)和渐进式推理 (Progressive Reasoning)增强动态场景适应性(如Chain-of-Spot)。
4. 新型评估基准与数据集
大规模多模态基准 :
科学与数学推理 :VCR-Bench、MMMU、GeoQA。
跨模态协作 :HIS-GPT(3D人体场景理解)、Video-MMMU(专业视频知识获取)。
对抗性测试 :ExtremeAIGC(AI生成极端内容鲁棒性)、AgMMU(多角度欺骗性问答)。
数据集贡献 :Mulberry-260K(数学与通用推理)、LAION-5B(多模态预训练)、DocVQA(文档视觉问答)。
5. 技术突破方向
模态协同强化 :通过多专家混合架构 (MoE)和统一标记化 (UniToken)实现多模态高效融合(如Uni-MoE、Qwen2-Omni)。
长序列与工具链扩展 :扩展强化学习至多模态工具链 (Tool-Augmented Chains)和长时程任务规划 (如SPA-Bench、VisualAgentBench)。
可解释性与可控性 :基于模块化集成框架 (如PEIL、Vision Expert Prompting)实现推理路径可视化与干预(如MM-ReAct、Multi-Modal-Thought)。
Vision-Language-Action Models
论文标题:Vision-Language-Action Models: Concepts, Progress, Applications and Challenges
论文链接:https://arxiv.org/abs/2505.04769
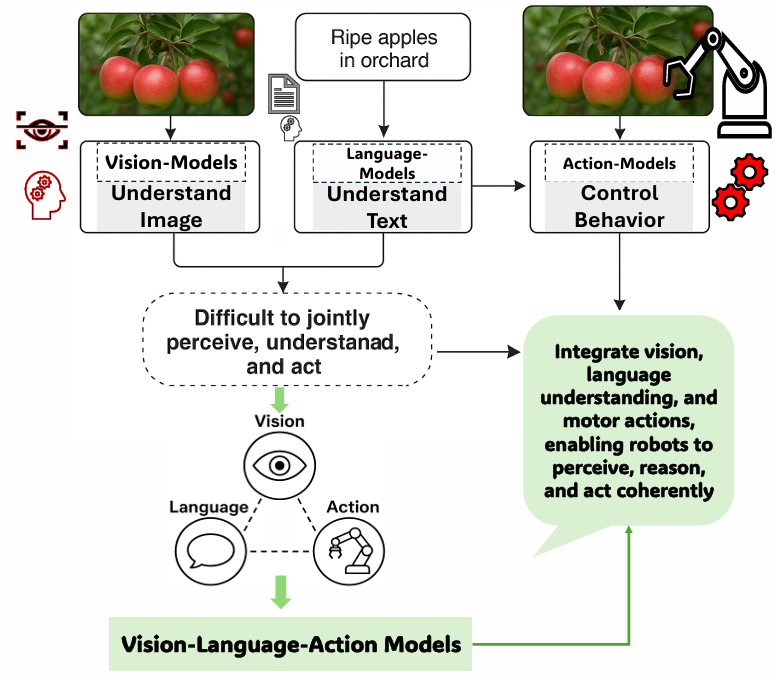
核心创新点:
1.多模态融合架构革新
统一神经符号规划框架 :通过将视觉-语言模型(VLM)与动作决策模块深度集成,构建端到端可微架构(如ORION系统),实现推理空间与动作空间的对齐优化,突破传统模块化架构的语义鸿沟。
动态混合专家系统 :提出基于稀疏混合专家(MoRE)的架构,结合低秩适配(LoRA)模块与强化学习Q函数训练,支持四足机器人多任务导航与非结构化场景操作,在模拟与真实环境中的泛化能力提升23%。
2. 时空感知与动作建模突破
3D空间推理增强 :PointVLA通过模块化跳跃连接注入3D点云特征,在保留预训练2D知识的同时,实现Few-shot长时程任务成功率提升41%;DexVLA引入扩散专家插件,显著提升机械臂操作的空间精度。
时序动力学建模 :采用扩散过程与自回归建模融合策略(HybridVLA),结合QT-Former时序编码器,解决动作序列的长期依赖问题,在自动驾驶轨迹预测任务中闭环性能提升37%。
3. 高效推理与部署技术
动态计算优化 :VLA-Cache通过自适应token缓存机制,实现静态视觉token的选择性复用,推理速度提升40-50%且精度损失<2%;Mole-VLA的动态层跳过机制(Mixture-of-Layers)降低38%计算负载。
边缘计算适配 :TinyVLA通过模型压缩与量化技术,在消费级GPU上实现机械臂操作任务的实时推理(<50ms延迟),数据效率提升65%。
4. 跨域泛化与安全机制
开放世界适应性 :pi0.5模型集成动态风险评估模块与紧急停止电路,在家庭/工厂场景中实现99.2%的安全执行率;通过CLIP硬负例微调与元学习框架,跨域任务成功率提升28%。
伦理安全框架 :建立隐私保护(设备端处理)、公平性审计与监管合规三位一体架构,模型偏见指数下降43%,在医疗机器人应用中通过ISO 13482安全认证。
5. 数据工程创新
多模态数据融合 :构建Open X-Embodiment+LAION-5B混合数据集,包含230万段机器人轨迹与50亿图文对,通过对比学习实现语义对齐误差降低至1.8像素。
合成数据增强 :UniSim生成包含动态光照/遮挡的逼真场景,使机械臂在杂乱环境中的抓取成功率提升21.7%,SynthVLM合成数据质量达真实数据的92%水平。
MonoCoP
论文标题:MonoCoP: Chain-of-Prediction for Monocular 3D Object Detection
论文链接:https://arxiv.org/abs/2505.04594
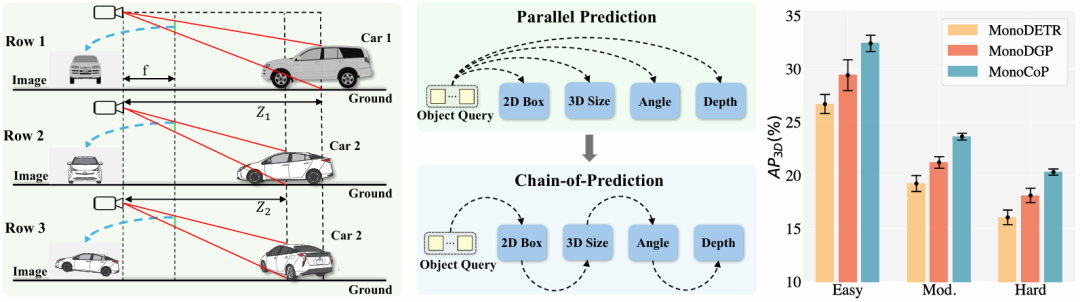
核心创新点:
1. 基于链式预测(Chain-of-Prediction, CoP)的序列化3D属性推理框架
针对单目3D物体检测中深度估计的病态问题,提出显式属性依赖建模 ,通过顺序条件预测 (Sequential Conditional Prediction)替代传统并行预测范式。该框架受大语言模型的思维链(Chain-of-Thought, CoT)启发,将3D属性预测分解为尺寸→角度→深度 的渐进式推理链路,有效缓解属性间强耦合导致的预测不稳定性和误差累积问题。
2. 属性感知特征学习与传播机制
设计轻量级属性网络(AttributeNet, AN) ,通过两层线性变换(带ReLU激活)分别提取3D尺寸、角度、深度的专属特征表示。
构建显式特征传播链路,通过AngleNet和DepthNet模块依次传递尺寸→角度→深度的特征依赖关系,实现属性间物理约束的显式建模。
3. 残差特征聚合策略
引入残差连接聚合机制,在特征传播链路中融合原始查询(Object Query)和中间属性特征,既保留早期特征信息避免遗忘,又通过残差结构抑制噪声传播,显著提升长链预测的鲁棒性。
前沿的更迭速度很快,有没有一个专业的技术社区一直follow学术界的前沿研究和工业界的量产落地?带着这个想法,我们打造了『自动驾驶之心知识星球』。我们为大家准备了大额七折优惠,上半年仅此一次机会...
4000人专业自动驾驶社区!欢迎扫码加入~

国内最大的自动驾驶学习社区
前沿技术聚集地一直是自动驾驶之心的标签。为此我们打造了国内最大的自动驾驶技术社区 — 『自动驾驶之心知识星球』,创办于2022年7月份,致力于打造为自动驾驶行业中的 ”黄埔军校“。目前已近4000人,聚集了近100+自动驾驶行业专家为大家答疑解惑,总结了30+自动驾驶技术的学习路线。这是国内首个以自动驾驶技术栈为主线的交流学习社区,汇总了最前沿的端到端自动驾驶、自动驾驶世界模型、视觉大语言模型、闭环仿真与3DGS、自动驾驶感知(目标检测、语义分割、车道线检测、BEV检测、Occupancy、在线地图、目标跟踪、多模态、多传感器融合等)、自动驾驶定位建图(高精地图、SLAM)、自动驾驶规划控制与预测、多传感器标定、自动驾驶开发、领域技术方案、AI模型部署落地等几乎所有子方向的学习路线!除此之外,还和数十家自动驾驶公司建立了1v1内推渠道,简历直达!这里可以自由提问交流,许多算法工程师和硕博日常活跃,解决问题!初衷是希望能够汇集行业大佬的智慧,在学习和就业上帮到大家!星球的每周活跃度都在国内前20,非常注重大家积极性的调度和讨论,欢迎加入一起成长!
这里能够让小白快速入门,让已经入门的同学进一步提升,已经提升的同学结交更多的朋友。平均每天不到1元,微信扫码加入......
知识星球大额优惠!欢迎扫码加入~

知识星球有哪些内容模块
带着对技术的思考,星球主要包含四大板块:
技术领域的全面分类和汇总;
科研界&学术界顶级大佬直播;
面向求职的资料汇总和岗位分享:
直击痛点的问题解答。
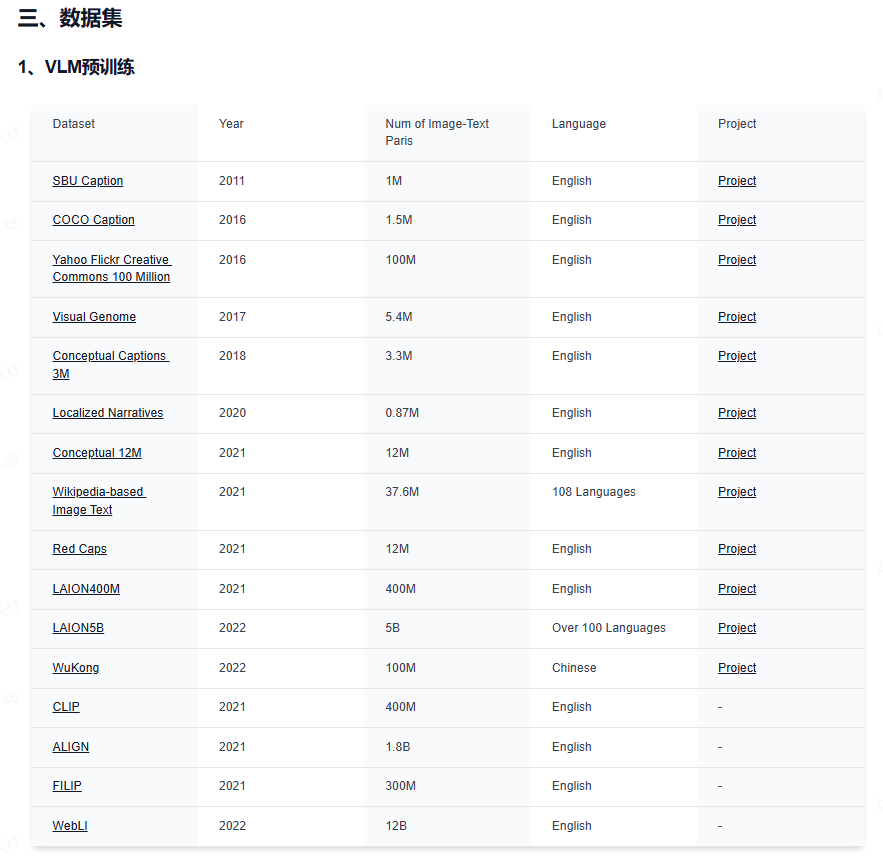
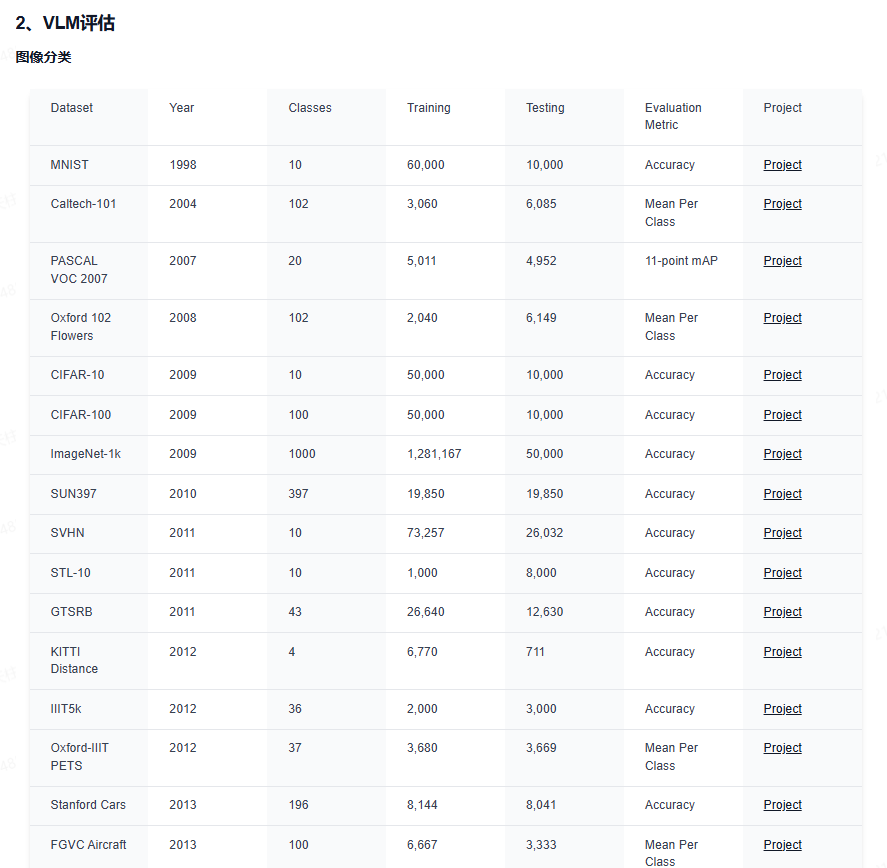
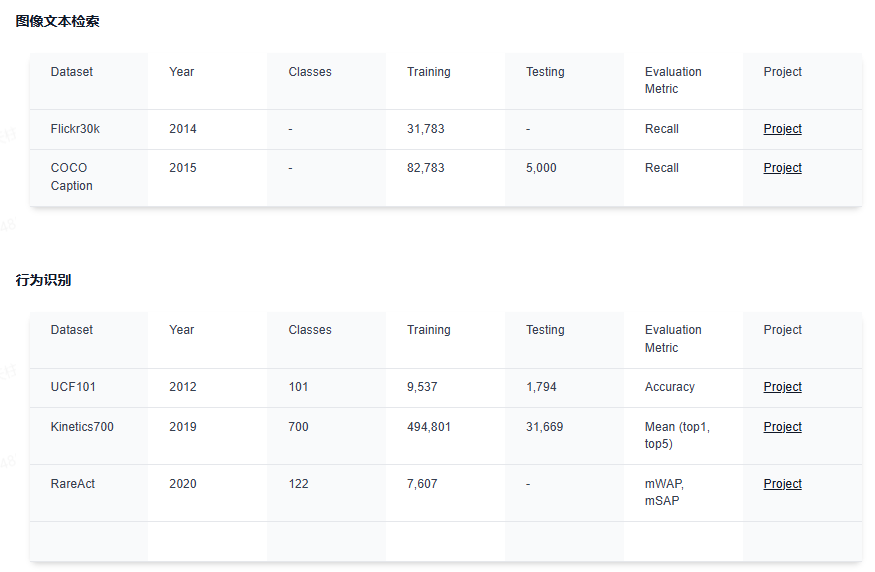
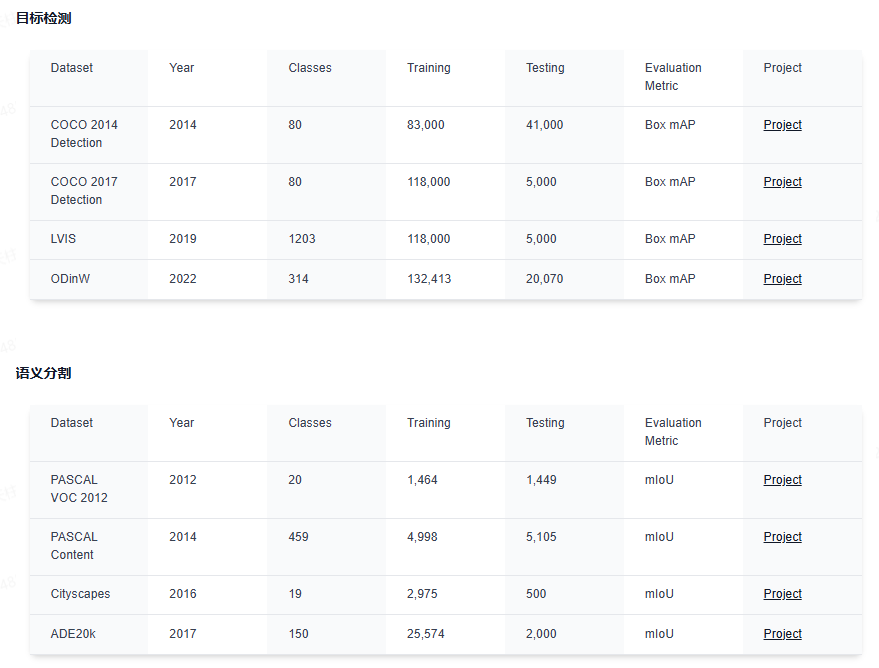
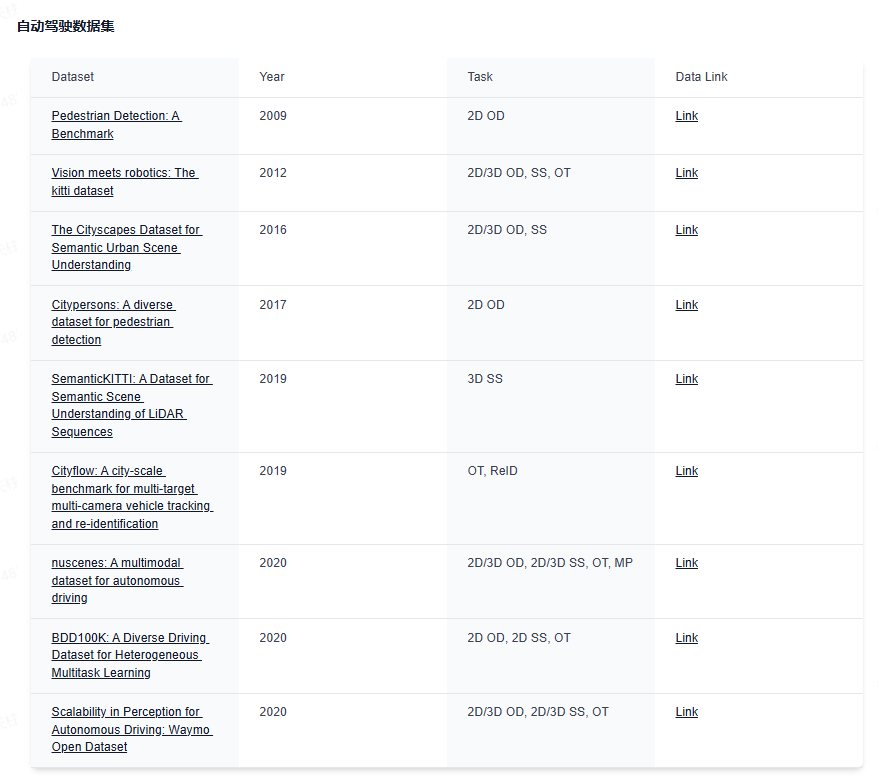
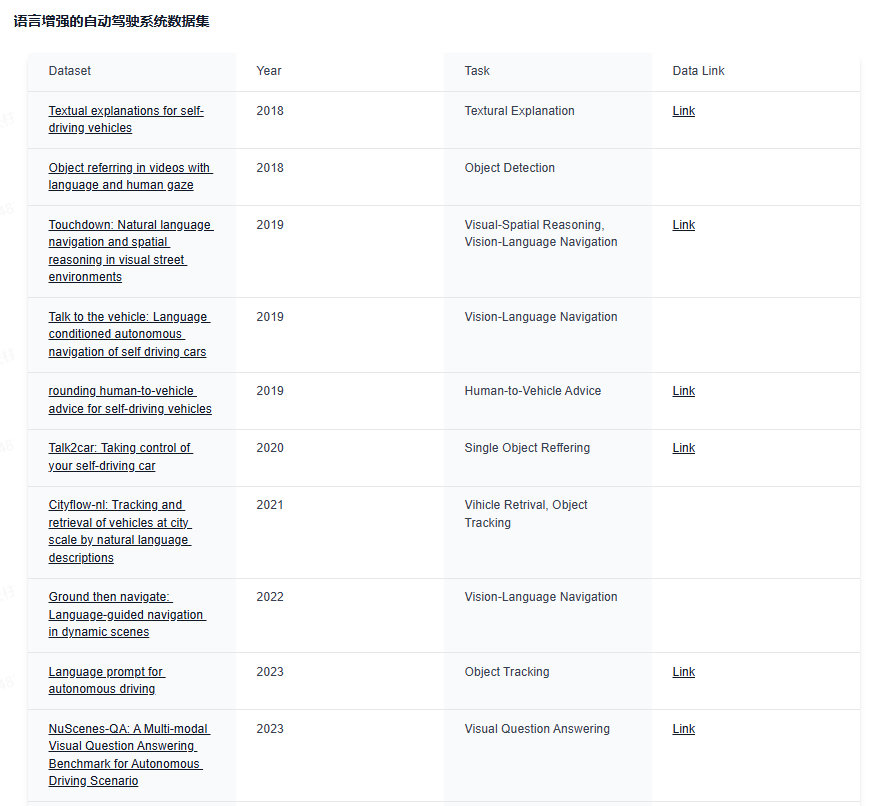
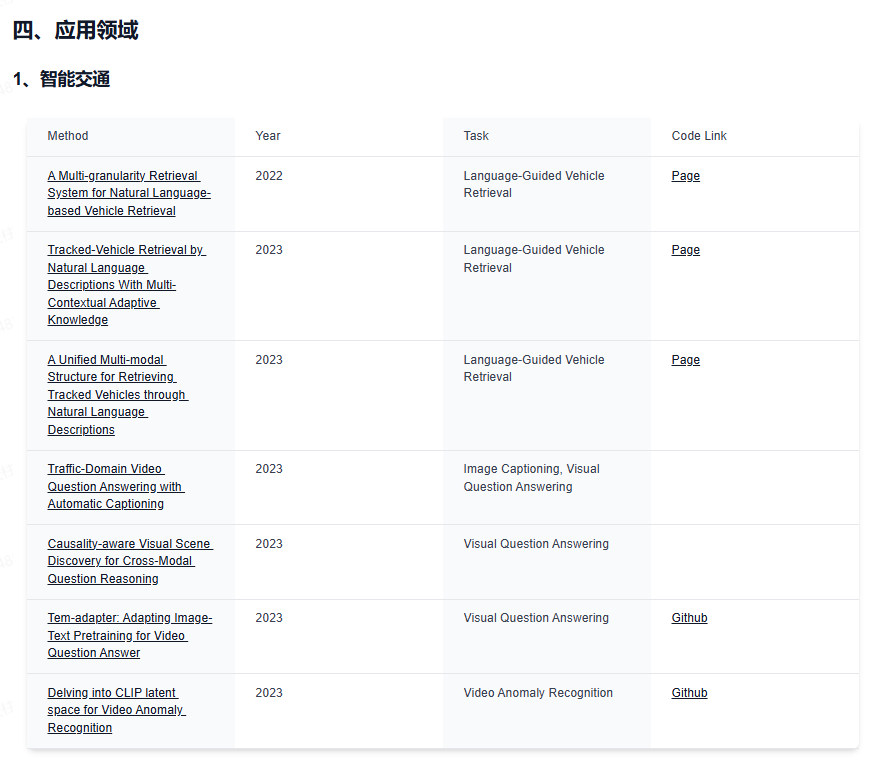
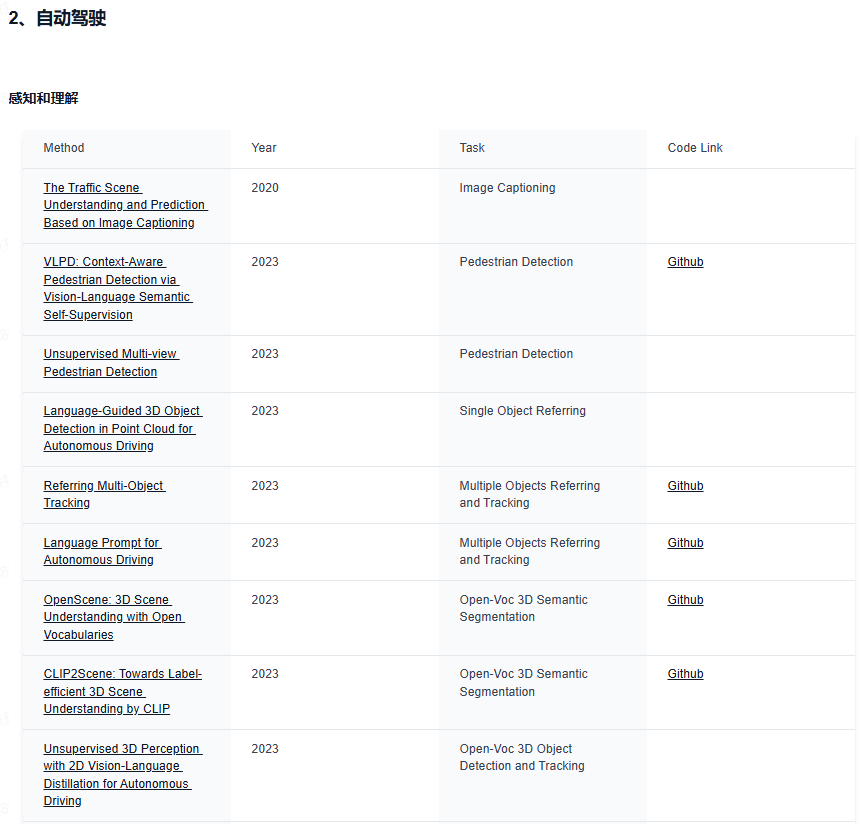
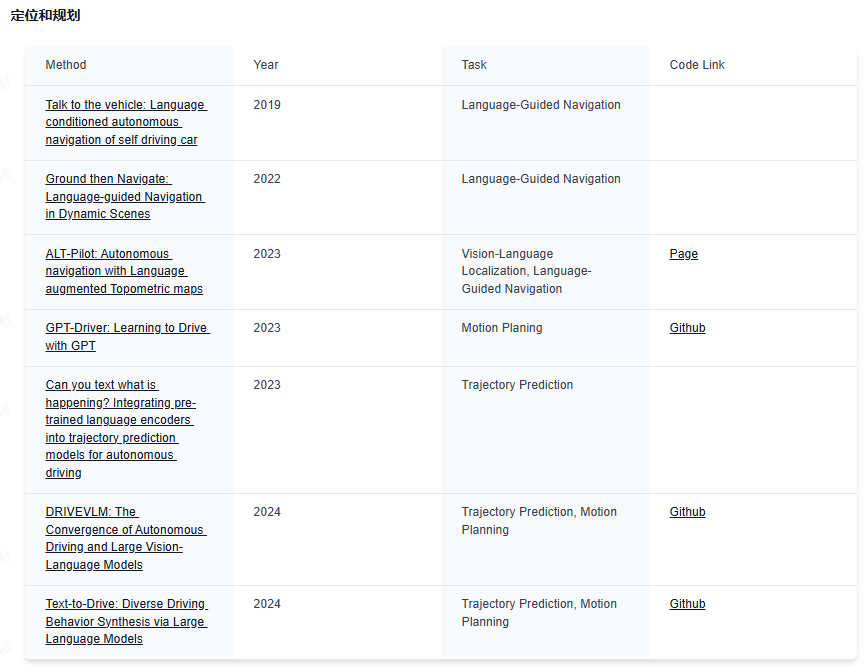
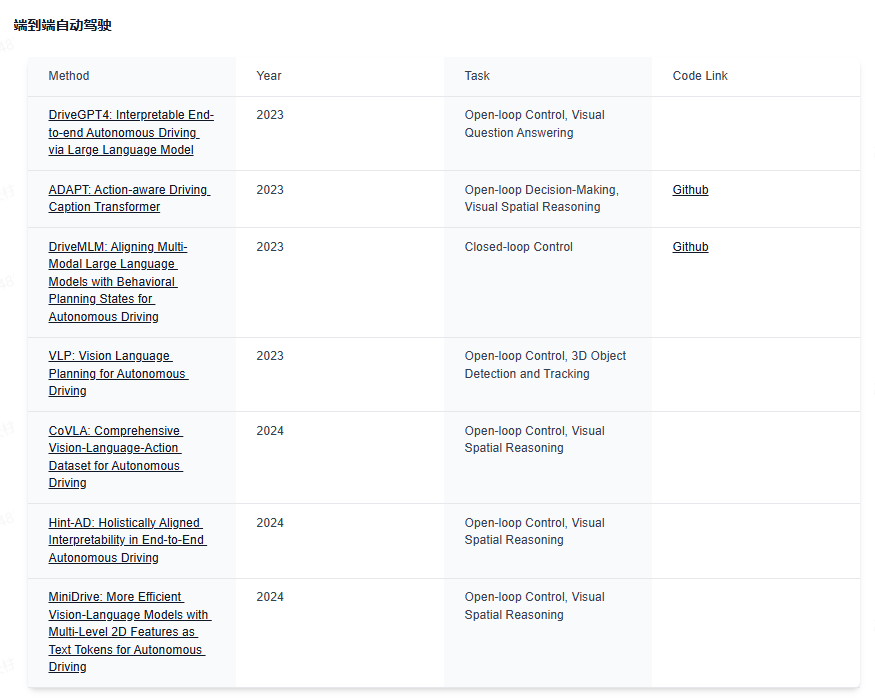
下面给大家分享下业内最前沿的四大技术方向,星球都汇总了哪些内容:视觉大语言模型、世界模型、扩散模型和端到端自动驾驶。前沿文章、数据集汇总、综述归纳应用尽有~
视觉大语言模型



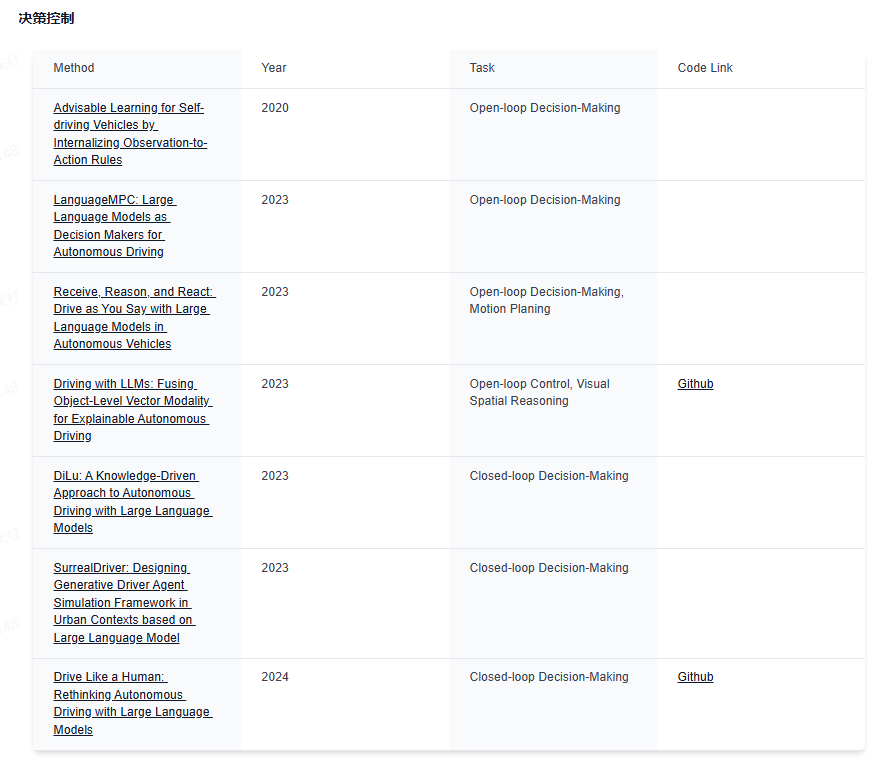
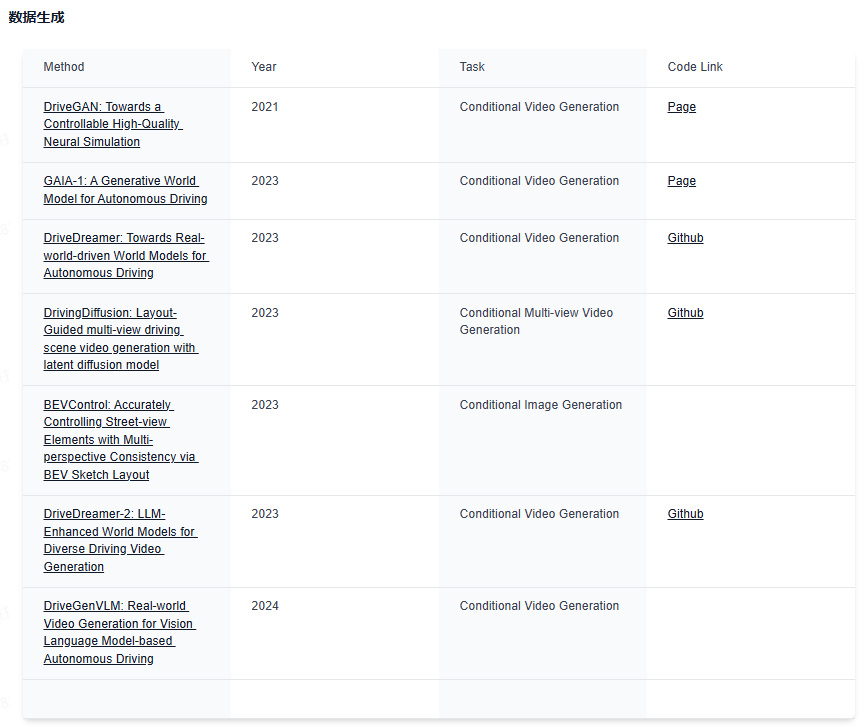
世界模型



扩散模型






端到端自动驾驶











星友独家权益
第一时间掌握自动驾驶相关的学术进展和量产落地应用;
免费获得100+专业嘉宾的答疑解惑(有问必答)
永久免费浏览、下载星球内容(目前近5000干货内容,每天更新)
所有自动驾驶之心的付费课程8折优惠(价值近3000元)
学术界&工业界前沿直播视频免费无限期回放(一年近100场)
免费咨询求职招聘相关问题加入
专属VIP群,获得最新资讯
技术领域汇总
星球内已经打磨出近30+的学习路线,涉及视觉大语言模型VLM、世界模型、端到端自动驾驶、BEV感知、动态/静态障碍物检测、多传感器融合、多传感器标定、目标跟踪、模型部署与CUDA加速、仿真等方向,沉淀了大量工程上的解决方案、学术上的优化思路!星球主要内容一览:

前沿视频直播
除了日常的文档、问答分享,星球内部会不定期邀请CVPR、ICCV、ECCV、NIPS、TPAMI等各类顶会顶刊作者以及国内外各大顶尖自动驾驶公司团队前来直播分享,就死磕两件事,如何落地量产和搞研究,非常适合工业界和学术界的小伙伴!目前星球内已经积累了大量的视频干货,涉及近50个子方向!视频直播内部每周1~2次,每年计划100场左右。
今年的直播会重点聚焦在VLA、大模型、扩散模型、具身智能等前沿内容!
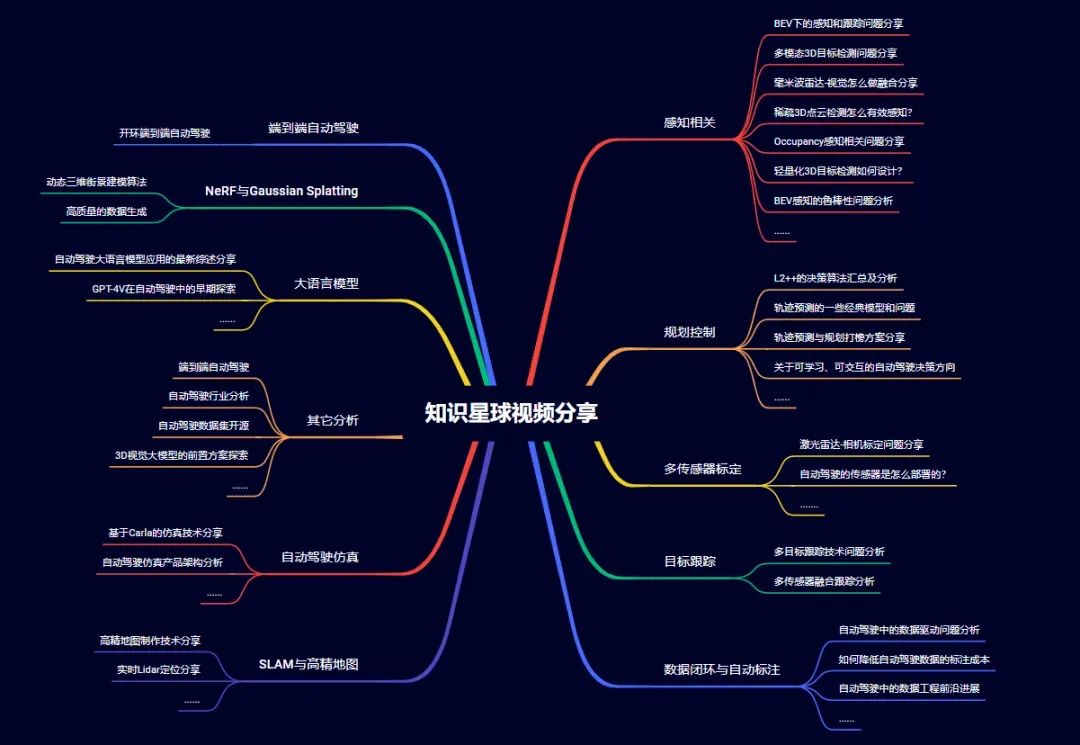
自动驾驶求职
星球内部针对常见的技术方案、问题难点展开了汇总,自研了国内首个自动驾驶求职一百问系列,大家可以实时查找学习!目前已经完成TensorRT模型部署与CUDA加速、毫米波雷达视觉融合、车道线检测、规划控制、BEV感知、轨迹预测、多传感器标定、Occupancy、NeRF、4D毫米波雷达、多模态3D感知等多个系列。部分内容一览:






星球日常问答
自动驾驶之心知识星球的定位是直接面向学术界和工业界,汇总下最近的相关问答:
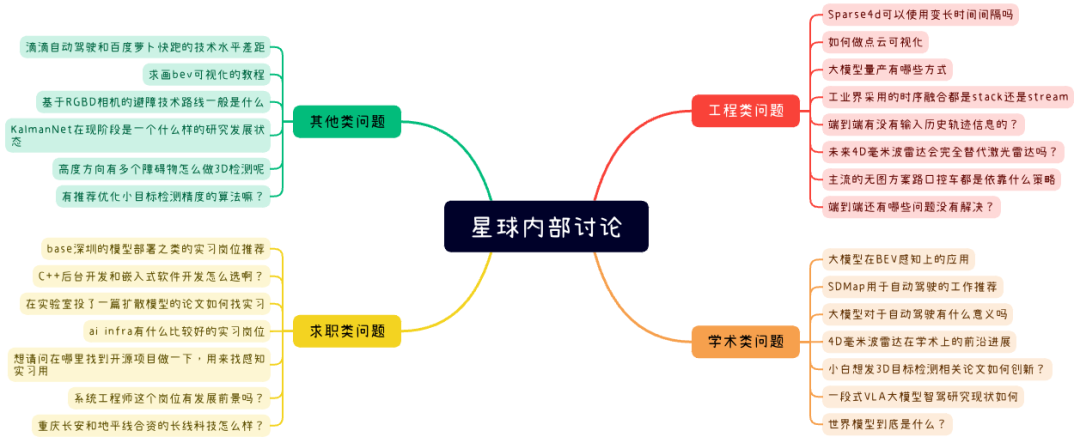
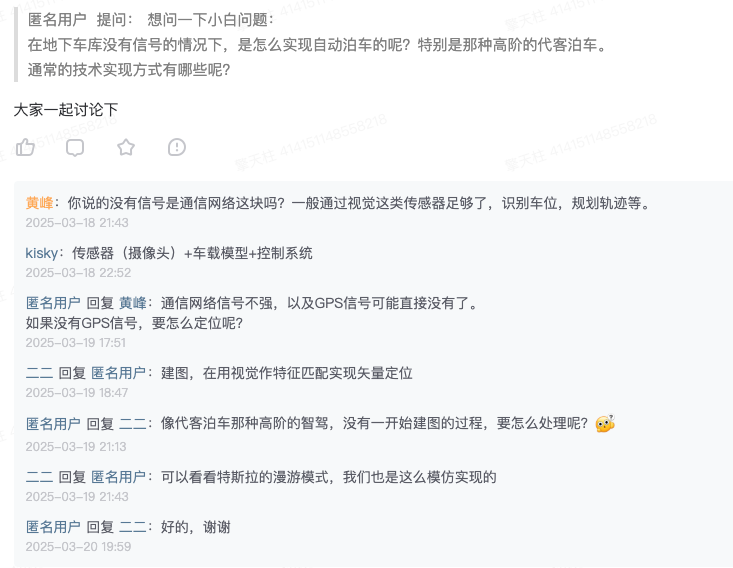
日常交流最实际的工程、学术问题和求职择业相关!摘取一些最近的问答分享给大家,我们秉承着有问必答的原则和星友交流,尽可能的输出第一线的专业知识!









星球嘉宾组成
这么多的领域问题,需要行业最专业的回答。为了保证回答的准确性,星球创始人都是行业算法专家,基本可以cover主流的算法方向。除此之外,我们进一步扩展了星球嘉宾阵容,持续邀请到行业100+大佬。
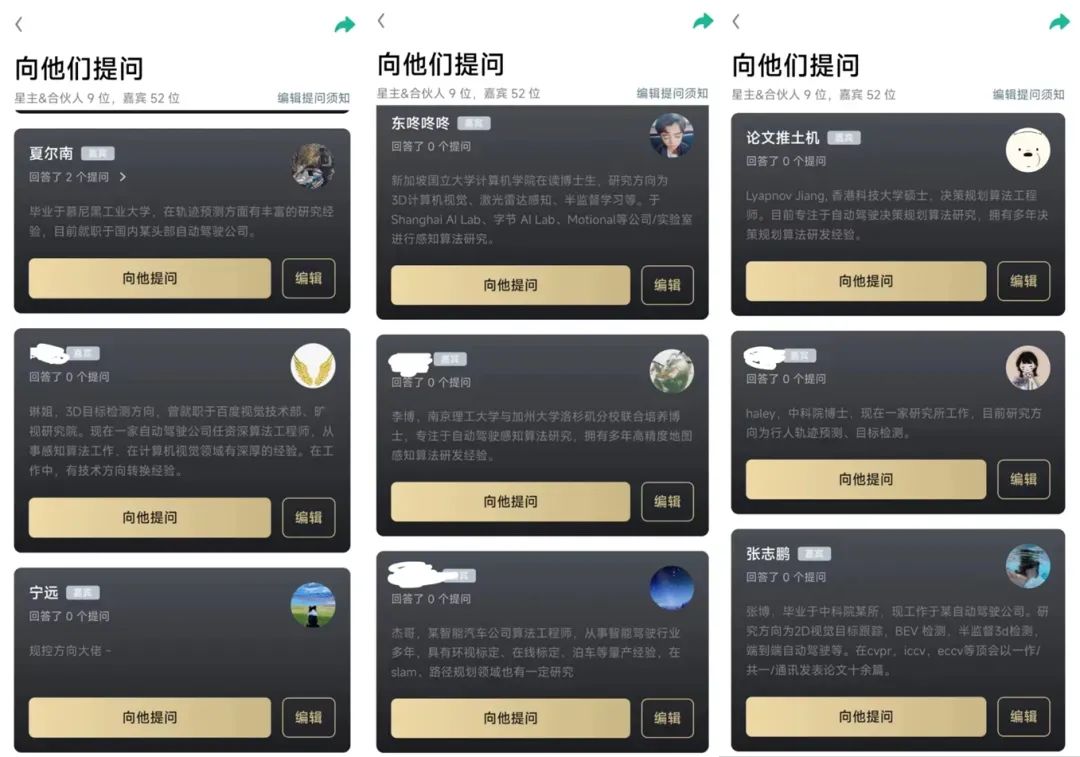
自动驾驶之心同时面向学术界和工业界领域展开,星球嘉宾分布在国内外顶级高校和头部自动驾驶公司,行业一手信息第一时间掌握!
星球成员的背景
星友们也都是卧虎藏龙,主要来自地平线、蔚来、小鹏、理想汽车、AI Lab、商汤科技、旷视科技、百度、阿里、网易、Momenta、Intel、Nvidia、赢彻科技、图森未来、智加科技、AutoX、大疆、上汽、集度、斑马、华为等业界知名公司,以及苏黎世理工、卡耐基梅隆大学、普渡大学、东京大学、香港中文大学、香港科技大学、香港大学、清华大学、上海交大、复旦大学、浙江大学、中科大、南京大学、东南大学、同济大学、上海科技大学、哈工大等国内外知名高校;
日常更新和维护
日常paper分享:视觉大语言模型VLM、世界模型、扩散模型、具身智能、BEV感知、3D目标检测、多模态融合、语义分割、车道线、多任务学习、点云深度学习、多目标跟踪、传感器空间和时间同步、鱼眼感知与模型、轨迹预测、端到端自动驾驶、轨迹预测、高精地图、SLAM、规划控制、V2X、Occupancy network、NerF、Gaussian Splatting、测速测距、强化学习、VIT、轻量化等;
职位与面经分享:自动驾驶行业职位内推、面经分享、入门学习路线分享;
日常问答交流:和嘉宾星主交流领域学术工业最新进展,包括领域方案、工程实战问题、学术界前沿动态;

面向对象与群体
星球创建的初衷是为了给自动驾驶行业提供一个技术交流平台,包括需要入门的在校本科/硕士/博士生,以及想要转行或者进阶的算法工程人员;除此之外,我们还和许多公司建立了校招/社招内推,包括地平线、百度、蔚来汽车、理想汽车、小鹏、momenta、赢彻科技、AutoX、华为、集度、滴滴、Nvidia、高通、纵目科技、魔视智能、斑马汽车、博世、纽劢科技、寒武纪等!
如果您是自动驾驶和AI公司的创始人、高管、产品经理、运营人员或者数据/高精地图相关公司,也非常欢迎加入,资源的对接与引进也是我们一直在推动的!我们坚信自动驾驶能够改变人类未来出行,想要加入该行业推动社会进步的小伙伴们,星球内部准备了基础到进阶模块,算法讲解+代码实现,轻松搞定学习!
欢迎加入
欢迎大家扫码加入自动驾驶之心知识星球,我们诚邀更多学员的加入,一起创造一个全技术栈的自动驾驶开发者社区!星球成员的加入平均每天不到1元,欢迎扫码加入一起学习一起卷!


















 2090
2090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









