






点击下方卡片,关注“具身智能之心”公众号
作者丨KAIXIN BAI等
编辑丨具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
写在前面&出发点
导航和操作是具身人工智能(Embodied AI, EAI)中的核心能力,但在现实世界中训练具备这些能力的智能体面临着高昂的成本和时间复杂性。因此,仿真到现实的迁移(sim-to-real transfer)成为了一种关键方法,然而仿真与现实之间的差距依然存在。我们探讨了物理模拟器如何通过分析以往综述中被忽视的特性来缩小这一差距。我们还分析了它们在导航和操作任务中的特点,以及硬件要求。此外,我们提供了一个包含基准数据集、评估指标、仿真平台和前沿方法(如世界模型和几何等变)的资源,以帮助研究人员在考虑硬件限制的情况下选择合适的工具。
文章首发于国内首个具身智能全栈学习社区:具身智能之心知识星球!
一些介绍
具身人工智能(EAI)指机器人等智能体借助传感器和行动与物理环境交互。导航和操作是现代机器人应用中 EAI 的关键能力,任务要求智能体感知、理解并与环境交互。人工智能领域的进展让基于学习的强化学习(RL)和模仿学习(IL)等方法在训练导航和操作智能体上颇具潜力。但收集现实世界数据训练这类智能体成本高昂,尤其考虑不同实体形式(如机器人设计或传感器差异)时。模拟器提供了经济且可扩展的解决方案,能让机器人在大规模多样化数据集上高效训练。智能体通过仿真到现实的迁移部署到现实世界,即仿真环境中训练的智能体适配现实世界。不过,仿真到现实的方法存在仿真与现实的差距,这源于模拟环境和现实环境在物理动力学(如摩擦、碰撞、流体行为)及视觉渲染(如光照、相机曝光)上的差异。先进的模拟器,如可微且高度逼真的 Genesis,通过精确物理建模和逼真渲染缩小了这一差距,提升了在模拟环境中训练的智能体向现实世界机器人转移的适用性。
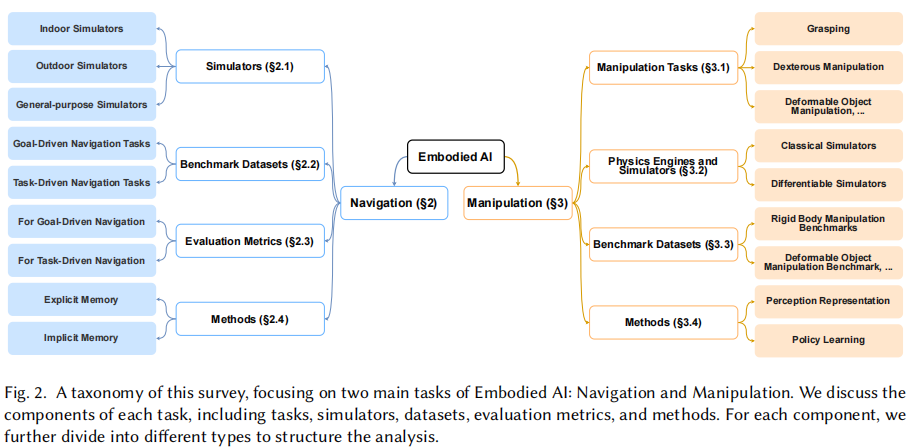
本综述全面概述了具身人工智能中机器人导航和操作的最新进展,突出了物理模拟器的作用。它深入探讨了模拟器的功能特性,并对相关任务、数据集、评估指标和前沿方法进行了分析。这为研究人员提供了见解,帮助他们选择符合自身需求的工具。
如图 1 所示,自 2019 年以来,导航和操作领域取得了快速进展。受数据驱动方法的推动,这两个领域都有了显著的进步。2020 年至 2022 年间,导航和操作的发展加速。大规模数据集的引入,包括那些包含大量演示数据的数据集,通过模仿学习实现了更好的模型泛化。从 2022 年起,基础模型、世界模型和视觉 - 语言 - 行动(VLA)模型的兴起标志着又一次飞跃。

在导航方面,技术越来越多地采用隐式记忆,如基于潜在表示的记忆、基础模型和世界模型。这些进展得到了互联网规模的训练数据和大规模导航数据集的支持,如 iGibson、ALFRED 和 Habitat-Matterport 3D 语义数据集,为能够在不同环境中进行最小化特定任务调整的通用导航智能体奠定了基础。
与此同时,操作方法从早期基于强化学习的方法显著发展到模仿学习、扩散策略和 VLA 模型。2020 年至 2022 年间引入的大规模数据集,包括 GraspNet-10 亿、ManiSkill 和 SoftGym,使操作智能体能够通过在不同任务的大规模数据集上进行预训练来实现更好的泛化。2023 年至 2025 年,VLA 模型,如 RT-2 和 RT-X,集成了视觉、语言和行动,能够在多模态环境中进行更复杂的操作。这种从 RL 到 IL、DP 和 VLA 的演变反映了向数据丰富的多模态策略的转变,支持了能够处理包括语言和图像在内的多模态输入、并能在无需特定任务重新训练的情况下适应不同操作场景的通用模型的开发。
鉴于 EAI 的快速发展,全面的综述对于整合这些进展并提供结构化的概述至关重要。本文详细探讨了 EAI,重点关注导航、操作以及为支持它们而设计的物理模拟器,如图 2 所示。我们研究了相关任务、模拟器、数据集、评估指标和方法,为研究人员和工程师创建了一个全面的资源。本综述有助于选择与硬件能力和研究目标相匹配的模拟器、基准数据集和方法,从而推动 EAI 中导航和操作智能体的发展。
导航
导航是具身人工智能智能体的重要能力,可用于自动驾驶汽车、个人助理、救援机器人等现实应用。但直接在现实世界训练这些智能体存在成本高、时间受限、有安全风险、设置环境开销大以及收集大规模训练数据困难等挑战。
为应对这些挑战,仿真到现实的迁移成为常用方法。不过,成功实现仿真到现实的迁移需解决两个关键问题:一是视觉仿真与现实的差距,模拟器中相机传感器要渲染逼真图像,使智能体的感知模块适应现实世界的视觉观察;二是物理仿真与现实的差距,现实世界地形不平,导航需机器人有强移动能力,模拟器中的物理引擎要准确复制碰撞动力学,为机器人本体感受传感器提供真实反馈,让在仿真中训练的移动控制策略能无缝适应现实世界的物理约束,以保证部署时的可靠性能。
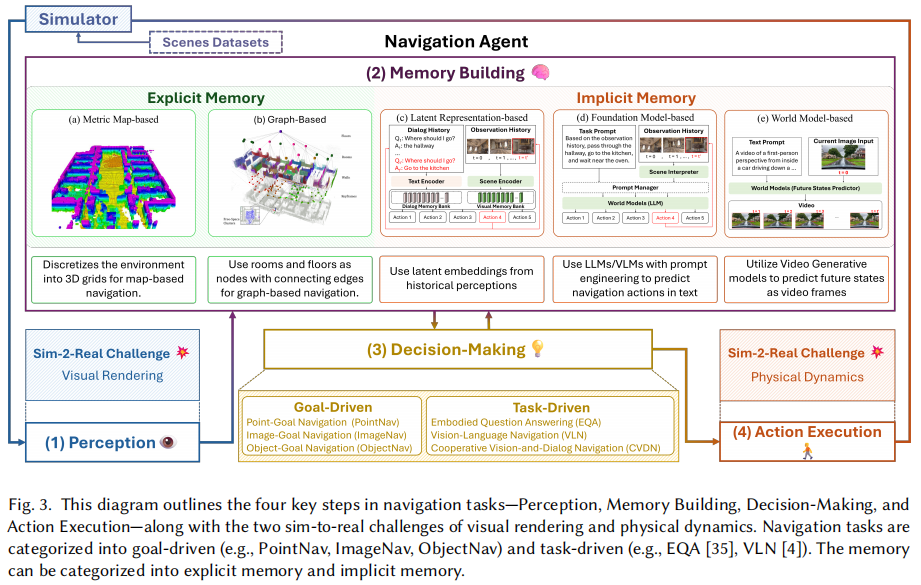
在图 3 中,我们详细分解了模拟器中智能体的导航过程,突出了四个关键步骤,并展示了仿真到现实的挑战是如何出现的。这些步骤是:
感知:智能体通过模拟器渲染的感官数据(图像或点云)感知环境,面临视觉仿真与现实的差距。现实世界导航有部分可观测性,智能体只能感知局部环境,需探索积累局部观察来构建全局记忆。
记忆构建:因部分可观测性,智能体要构建维护环境全局记忆。传统上依赖显式记忆,包括基于度量地图的记忆(为精细导航和避障提供精确空间布局,如占用网格)和基于图的记忆(将环境表示为节点和边,用于更粗粒度高级规划,如拓扑地图)。
决策:智能体利用记忆规划行动以达特定目标,分为两种类型。目标驱动导航(智能体瞄准特定位置,如点目标导航的点、图像目标导航的图像、物体目标导航的物体)和任务驱动导航(智能体遵循文本指令,如具身问答、视觉语言导航、合作视觉对话导航等)。
行动执行:智能体在模拟环境中执行动作。训练有移动能力的智能体时,成功的仿真到现实迁移要求模拟器准确复制现实世界物理特性,通过真实模拟物理交互(如不平坦地形碰撞)和各种表面摩擦来解决物理仿真与现实的差距。
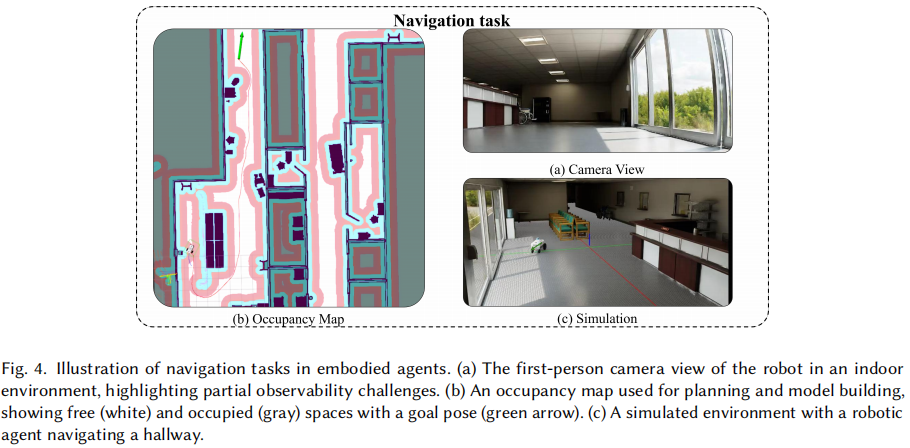
在详细分解导航过程之后,图 4 展示了这些步骤在模拟环境中的演示。具体来说,在图(a)中,第一人称相机视图展示了具有逼真渲染的感知,如玻璃门附近逼真的室外光线、准确的相机曝光和详细的室内阴影,缩小了视觉仿真与现实的差距。这个视图还突出了部分可观测性的挑战,因为机器人只能感知其直接周围环境,并且必须逐步构建环境的全局记忆。在图(b)中,占用地图通过提供自由和占用区域的空间表示,展示了显式记忆构建,轮式机器人使用它来规划路径并避开障碍物。最后,在图(c)中,机器人通过走廊执行其规划的路径,展示了行动执行。
模拟器
现代导航模拟器按环境可扩展性分为三类:室内模拟器针对如家庭的结构化小规模环境定制,适用于个人助理等应用;室外模拟器用于大规模、动态的室外环境,常用于自动驾驶汽车;通用模拟器可定制为室内或室外环境。模拟器支持的环境规模影响导航任务选择和智能体设计,如室内模拟器渲染的小规模环境用显式记忆即可,室外模拟器的大规模开放世界环境需世界模型管理。模拟器要解决视觉和物理仿真与现实的差距,才能有效部署到现实世界。研究人员分析了如 Habitat、AI2-THOR、CARLA、AirSim、ThreeDWorld 和 Isaac Sim 等模拟器的环境,展示了其视觉渲染能力,为选择合适模拟器及评估缩小仿真与现实差距的能力提供了全面指南。

1.室内模拟器:
室内模拟器适用于结构化小规模环境,适合开发可在家庭等室内区域导航的个人助理机器人等应用。现有室内模拟器常利用现实世界环境扫描或先进渲染技术,来减小视觉仿真与现实的差距,同时重点简化碰撞检测。以 Matterport3D 模拟器为例,其利用 Matterport3D 数据集(含从 194,400 张 RGB-D 图像提取的 10,800 个全景视图,涵盖 90 个不同现实世界场景),通过现实世界扫描实现高视觉保真度,缩小视觉仿真与现实的差距(模拟感知与实际相机输出相似)。但 Matterport3D 模拟器没有物理动力学,缺乏物理引擎,导航限制在预先计算的视点(平均相距 2.25 米)间的离散转换,通过可行走路径隐式检测碰撞,这种离散设计不适合训练智能体在不平坦地形上导航(因为需实际物理交互) 。Habitat-Sim从多个数据集及合成 CAD 模型渲染多样 3D 重建场景,在 GPU 上渲染速度超 10,000 帧 / 秒;集成 RGB-D 传感器噪声模型提升感知真实感;采用 Bullet 物理引擎模拟刚体动力学,实现准确碰撞检测与移动;与 Habitat-Lab 库集成,便于开展多种导航任务,是灵活的研究平台。AI2-THOR利用 Unity3D 的 PBR 提供逼真视觉效果,支持域随机化增强视觉仿真到现实的迁移;基于 Unity 的物理引擎实现逼真碰撞检测与移动;ProcTHOR 扩展通过程序生成 10,000 个独特房屋,增强可扩展性,丰富室内导航环境,利于策略泛化。iGibson使用带 BRDF 模型的 PBR 模拟逼真光交互,结合域随机化缩小视觉差距;采用 Bullet 物理引擎确保碰撞和移动动力学准确;适配多种智能体形式,覆盖 15 个室内场景,还可通过数据集扩展。
2.室外模拟器:
CARLA 和 AirSim 为自动驾驶汽车和机器人提供城市区域和自然地形的模拟环境。它们都利用虚幻引擎 4 的 PhysX,通过光线追踪和基于物理的渲染(PBR)实现逼真的渲染,同时采用域随机化来最小化视觉仿真与现实的差距。然而,这些先进功能带来了显著的计算开销。具体来说,CARLA 是一个专为自动驾驶定制的开源模拟器,支持 CARLA2Real 等工具以进一步增强真实感,并使用 PhysX 进行物理模拟,管理车辆动力学、碰撞检测和移动。相比之下,AirSim 使用自定义物理引擎进行速度优化,以处理碰撞检测和移动,并集成了 IMU 和 GPS 等逼真的传感器模型,以准确复制现实世界的条件。
3.通用模拟器:
通用模拟器可支持室内外场景,具备高保真视觉效果与精确物理模拟,但计算复杂,常需高端 GPU 或高效训练框架。ThreeDWorld (TDW)基于 Unity3D 构建,运用 PBR 和 HDRI 照明实现逼真渲染,减小视觉模拟与现实差距;采用 PhysX 物理引擎,支持布料、流体模拟及逼真碰撞检测,还能支持运输挑战等涉及室内外的任务。Isaac Sim由 NVIDIA 开发,利用 RTX 技术进行光线追踪渲染,缩小视觉模拟与现实差距;借助 PhysX 引擎提供精确动力学;与 Isaac Lab 集成后,支持路径规划等任务的强化学习和模仿学习,场景覆盖仓库到室外环境。这些模拟器的高保真模拟有助于策略在现实场景的部署。为应对高计算需求,常采用分层训练框架,如先由 RL 或 PD 控制器处理移动和短程导航,再通过基于深度学习的路径规划器(如路标点预测器)进行后续规划。
基准数据集
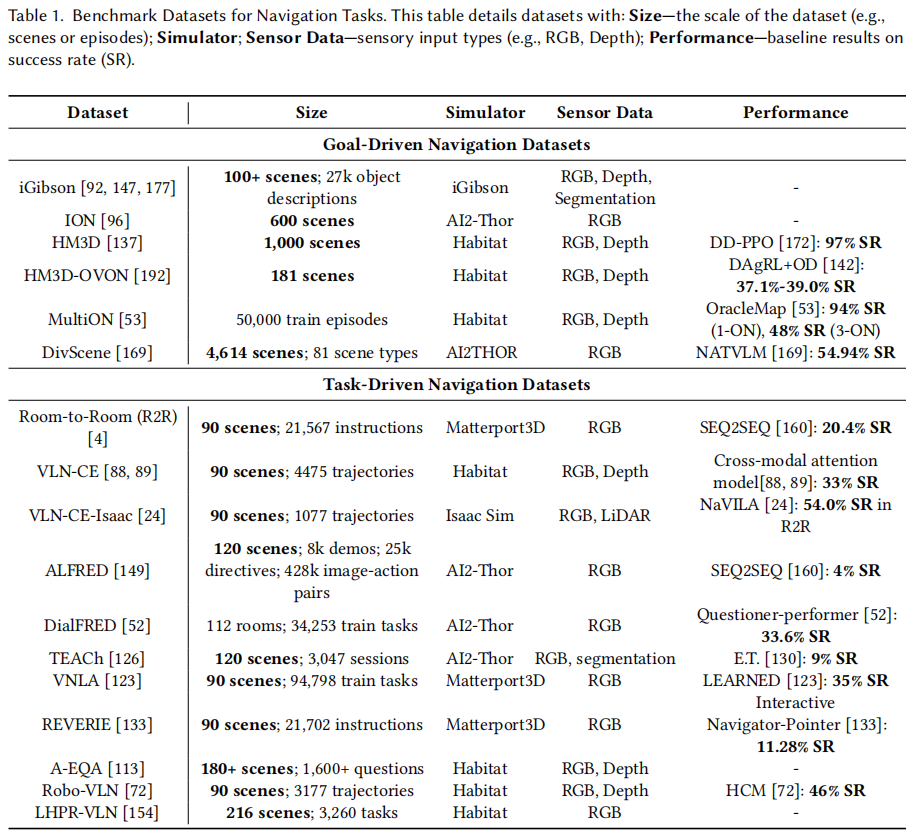
具身人工智能的导航任务有目标驱动导航(像点导航、图像导航、物体导航,智能体追求预定义目标)和任务驱动导航(如具身问答、视觉语言导航,智能体解释并按复杂文本指令行动)。为方便在模拟器中训练和评估执行这些任务的智能体,提出了各种基准数据集,且每个数据集常与特定模拟平台搭配。本节将详细研究导航基准数据集,会根据其支持的任务分为目标驱动导航和任务驱动导航两类。表 1 总结了这些基准数据集的关键属性,突出了它们的规模、传感器数据和性能指标。HM3D(1000 个场景)和 DivScene(4614 个场景)等数据集能提供广阔环境,助力智能体在不同场景中实现泛化。部分数据集如 VLN-CE、VLN-CE-Isaac、Robo-VLN 可提供专家轨迹,用于训练模仿学习策略。传感器数据(如深度输入)能提供空间感知线索,iGibson 和 TEACh 等数据集的分割数据可让智能体实现对周围环境的语义理解。此外,相关表格列出了应用于各数据集的基线方法及其成功率(SR),方便比较不同基准任务上方法的性能。
1.目标驱动导航数据集:
目标驱动导航数据集不断发展,面临的挑战从基本空间导航变为复杂物体交互和多目标推理。早期的 Matterport3D 数据集提供 3D 室内环境,但有表面缺失等问题。Habitat-Matterport 3D (HM3D) 数据集改善了这些情况,减少了表面缺失等伪影,提供高保真重建,缩小视觉模拟与现实的差距。HM3D-OVON 数据集引入开放词汇物体目标导航,让智能体导航到未见过的物体类别。实例物体导航 (ION) 数据集关注基于颜色、材料等属性导航到特定物体实例。多物体导航 (MultiON) 数据集增加任务复杂性,测试智能体记忆和规划能力,不过这些数据集环境静态,无需智能体与物体交互。现实导航更动态,iGibson 数据集引入交互式导航,要求智能体在杂乱室内环境中操纵物体以达目标。随着大语言模型出现,DIVSCENE 数据集利用基于 GPT-4 的 HOLODECK 系统生成多样环境,通过广度优先搜索 (BFS) 生成专家轨迹,提升智能体在不同环境的泛化能力。
2.任务驱动导航数据集:
任务驱动导航数据集从基本指令跟随基准发展为增强现实用的交互式框架。基于 Matterport3D 构建的 R2R 数据集,通过让智能体在离散环境中遵循自然语言指令,确立了 VLN。VLN-CE 数据集利用 R2R 的 3D 重建环境适配到连续设置,VLN-CE-Isaac 为腿式机器人定制 VLN-CE 数据集,纳入基于 LiDAR 的地形适应。但这些数据集多利用低级逐步指令,要求智能体无额外帮助执行命令。VNLA 数据集提供更高级指令,允许智能体请求语言指导,关注有效求助策略。ALFRED、DialFRED 和 TEACh 等数据集集成导航、物体操纵和对话,ALFRED 专注按指令完成家庭任务,DialFRED 和 TEACh 类似 VNLA,通过对话澄清来增强 ALFRED。另外,A-EQA 数据集用于解决 EQA 问题,让智能体探索环境回答开放词汇问题。
评估指标
不同类型导航任务需定制评估指标。目标驱动导航专注于高效到达预定义目标(如坐标、图像、物体),常用成功率、路径长度、完成时间等定量指标衡量。任务驱动导航要求智能体按文本指令行动或探索环境后回答问题,需评估动作与指令的一致性及答案准确性的指标。本节将分析这些指标,并探索其在两类任务中的属性。此外,我们通过四个关键视角评估这些指标 —— 尺度不变性、顺序不变性、安全合规性和能源效率,如图 6 所示。这些视角考虑了关键的现实因素:尺度不变性使指标在室内外各种环境尺度下都稳健;顺序不变性让智能体可通过不同路径达成导航目标,因现实中存在多条有效路径;安全合规性评估智能体避开碰撞和危险区域的能力;能源效率通过路径长度或导航持续时间等近似评估资源优化情况。
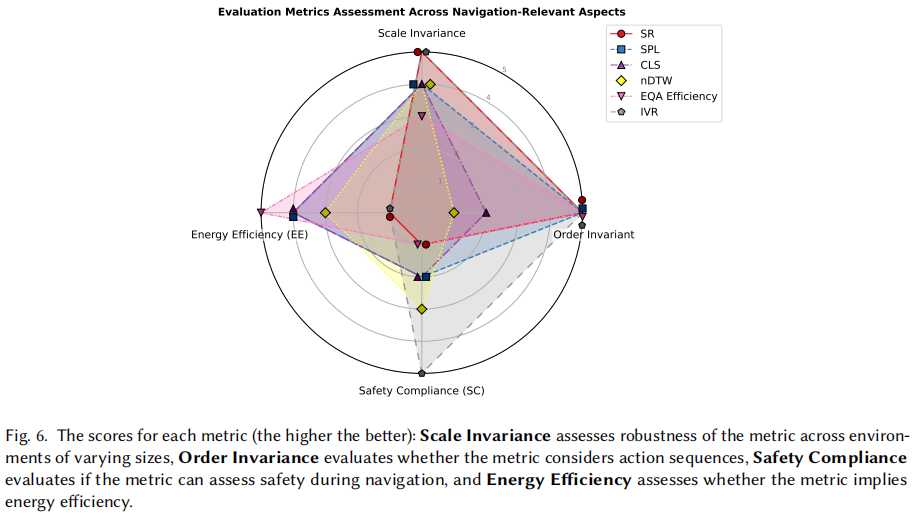
1.目标驱动导航任务的指标:
在目标驱动导航中,智能体旨在到达特定目标(如坐标、图像或物体),评估指标优先考虑任务完成情况和效率。成功率 (SR) 衡量智能体成功到达目标的情节比例,提供了性能的基本指标。对于物体目标导航,实例定位成功率 (ILSR) 扩展了 SR,要求智能体不仅要接近目标物体,还要在其他可见实例中正确识别它 —— 例如,在杂乱的房间中区分红色椅子和蓝色椅子 —— 从而评估定位和识别能力。为了纳入路径效率,路径长度加权成功率 (SPL) 定义为:
其中 N 是情节数, 是成功指标, 是最短路径长度, 是实际路径长度,它在成功与低效惩罚之间取得平衡。
2.任务驱动导航任务的指标:
任务驱动导航包括诸如跟随文本指令或在探索后回答问题等任务。像视觉语言导航 (VLN) 这样的任务可能要求智能体按照逐步指令导航特定路径。因此,这些任务需要比较预测路径与参考路径的指标。例如,长度加权覆盖得分 (CLS) 评估与参考路径的路径对齐情况。它定义为 ,其中路径覆盖 衡量预测路径 P 和参考路径 R 的空间覆盖范围,长度得分 (LS) 衡量预测路径的长度与参考路径的长度匹配程度。此外,归一化动态时间规整 (nDTW) 通过考虑空间对齐和采取的动作序列扩展了这一点。它生成一个从 0 到 1 的相似性得分,得分越高反映在位置和顺序方面与参考路径的对齐越好。CLS 和 nDTW 都通过参考路径长度对得分进行归一化来确保尺度不变性。此外,Song 等人将 VLN 任务中的逐步指令分解为多个子任务,并提出独立成功率 (ISR) 指标来独立评估每个子任务的完成情况,从而能够对 “左转,找到门” 等复杂指令进行细致的评估。在具身问答 (EQA) 中,EQA 效率定义为:
它将答案正确性(通过从 1 到 5 的 LLM 匹配得分 )与探索效率相结合,鼓励智能体通过更短的路径收集准确信息。最后,指令违反率 (IVR) 计算为:
它量化了常识约束(如乱穿马路)的违反情况,直接解决了智能体对人类设定的安全规则的遵守情况。
方法
1.显式记忆:
基于度量地图的方法:将环境离散化为网格、点云等构建地图,简化路径查找。如 Fu 等人用占用网格地图计算测地距离优化最短路径;Chen 等人融合语义特征提升探索性能;Huang 等人构建语义网格地图定位目标物体。但基于地图的方法在广阔环境中,因维护和更新大规模地图需大量计算资源,可扩展性有限。
基于图的方法:图捕获环境拓扑或物体空间关系,对于大环境,拓扑图将关键地标表示为节点、可通行路径表示为边。如 Savinov 等人用半参数拓扑记忆规划路径;Chaplot 等人引入神经拓扑 SLAM 生成探索路线;Beeching 等人训练神经规划器实现灵活导航;Yang 等人构建知识图推断物体位置。基于图的方法利用环境拓扑结构,可使用经典算法找最短路径,图神经网络还可提取高级特征辅助动作规划。
2.隐式记忆:
基于潜在表示的方法:显式记忆结构需频繁更新有计算开销,基于潜在表示的方法将观察和动作序列编码为潜在向量推断导航动作。如 Zhu 等人开发基于对话的导航系统,Hong 等人引入 VLN-BERT 保持和更新动态状态。但这些方法易出现累积误差,且在长距离导航任务中,因压缩过程丢弃空间细节,记忆大规模环境布局有挑战。
基于基础模型的方法:利用大规模预训练模型(大语言模型或视觉语言模型),将场景和语言指令编码为文本标记或潜在嵌入。如 Zhou 等人的 NavGPT 依赖 LLM 解释场景、跟踪进度、选择动作;Zheng 等人的 NaviLLM 集成视觉和文本信息生成动作。但仅依赖文本描述易丢失视觉细节,且易产生幻觉,MapNav 将 VLM 与度量地图结合以提高导航精确性。
基于世界模型的方法:学习预测未来环境状态指导导航,生成大规模合成数据集解决机器人数据集稀缺问题,增强泛化能力,辅助轨迹优化。如 Bar 等人训练导航世界模型生成未来帧评估路径;X-Mobility 采用潜在世界模型预测环境动力学;NVIDIA 的 Cosmos Predict 预测未来状态,Cosmos Reason 解释预测以指导导航决策。
操作
通过仿真到现实训练操作智能体,需理解智能体感知系统中的几何细节,并使用能模拟现实物理动力学的模拟器。以机器人拧瓶盖为例,需准确感知物体形状姿态,模拟器要模拟物理相互作用才能实现成功迁移。所以当前操作研究聚焦于推进感知建模,开发模拟器和物理引擎,其中可微模拟器备受关注。操作任务复杂程度不一,简单任务用 2D 传感器和基本抓手即可,复杂的灵巧手部操作则需 3D 感知和多指手,体现出感知、表示、模拟器和硬件要求随任务难度而变。为全面分析操作研究,本节将按以下顺序展开:先对关键操作任务分类分析,评估复杂性与硬件要求;接着探索物理引擎和模拟器;再调查基准数据集;最后研究感知表示和策略学习的核心操作方法。
操作任务
为了更好地理解操作相关的挑战,我们首先根据复杂性和所需的自由度(DoFs)对关键操作任务及其相关硬件进行分类,如图 7 所示。下面,我们详细探讨每个任务:
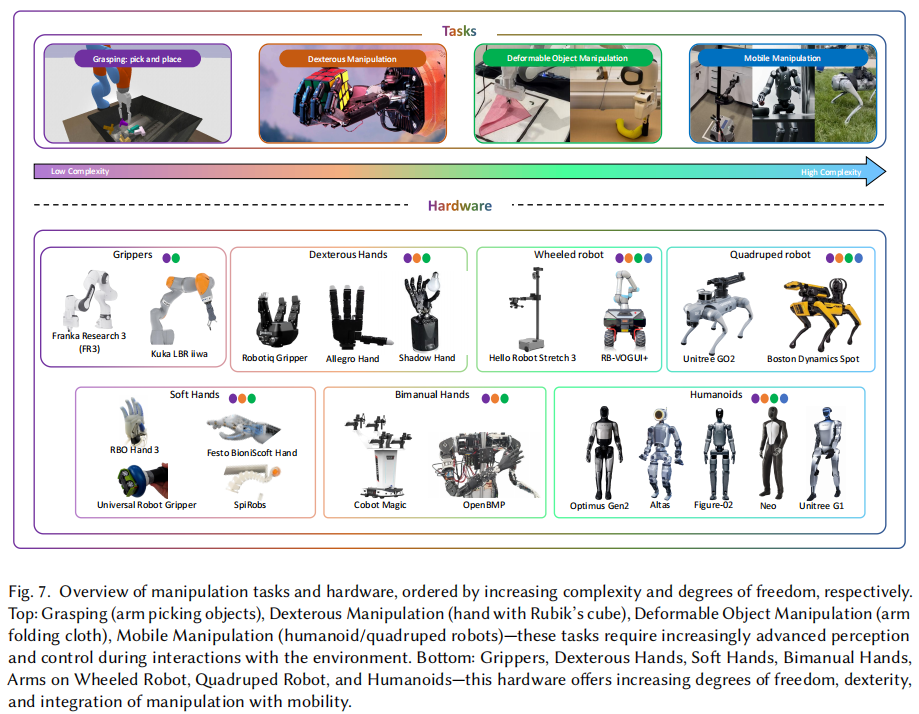
1.抓取:机器人学基本任务,指拾取和放置物体。平面抓取有三个自由度,用于抓取平面物体;完整 3D 抓取需六个自由度,处理任意姿态物体,需高自由度机械臂实现有效协调。
2.灵巧操作:多指手的手部内操作,采用手指步态等技术控制手中物体方向,如拧魔方、转笔,需手指精确协调,处理复杂接触动力学,对复杂形状物体,像 MuJoCo 模拟器可有效模拟手指与物体间摩擦力和多点接触。
3.可变形物体操作:处理如布料、绳索等软材料,其各点相对距离不固定,状态空间复杂,像打结、折叠衣服等任务需实时监测物体几何变形,精确控制以适应材料特性。
4.移动操作:安装在有导航能力移动平台上的机械臂操作,如轮式、四足、人形机器人,要求机器人既能导航又能操作物体,如机器人导航到厨房、打开抽屉、拿起杯子。
5.开放世界操作:解决 “无限可变性问题”,机器人在非结构化和动态环境中处理新物体,需从有限训练数据中泛化,适应新物体、材料和条件。
6.易碎物体操作:处理易碎物品,常用由橡胶等材料制成的软机器人抓手,采用气动等执行器控制手指运动,确保均匀压力分布,精确力控制需实时反馈和自适应控制策略,通过视觉或触觉反馈检测易碎性也很关键,准确模拟物体属性对训练重要。
7.双手操作:采用双臂系统如 ALOHA 执行单臂无法完成的需协调任务,如组装乐高积木。
物理引擎和模拟器
操作模拟器和导航模拟器一样,需解决物理和视觉仿真与现实的差距,以保障机器人智能体的有效训练与部署。对于操作任务而言,缩小物理仿真与现实的差距尤为关键,因为操作涉及更多物体间的交互。模拟操作任务要对复杂物理交互(如多点接触)、特定材料的摩擦(如石头、冰面)和碰撞力进行建模,且随着任务复杂性增加(如灵巧操作比平面抓取的碰撞更多),这些建模更为复杂。准确模拟动力学对开发可无缝应用于现实场景的控制策略十分重要。对于视觉仿真到现实的差距,模拟器采用先进的渲染技术,如光线追踪和逼真的深度降噪,来创建与现实世界条件紧密匹配的逼真环境,如图 8 所示。我们将探索为操作任务设计的各种物理引擎和模拟器。我们将比较经典引擎,如 MuJoCo 和 Isaac Sim,与可微引擎,如 Dojo 和 Genesis,评估它们在物理动力学建模和视觉保真度方面的能力。此外,我们将突出它们发展中的关键里程碑,并提供不同仿真平台的详细比较,如图 9 和表 2 所示。


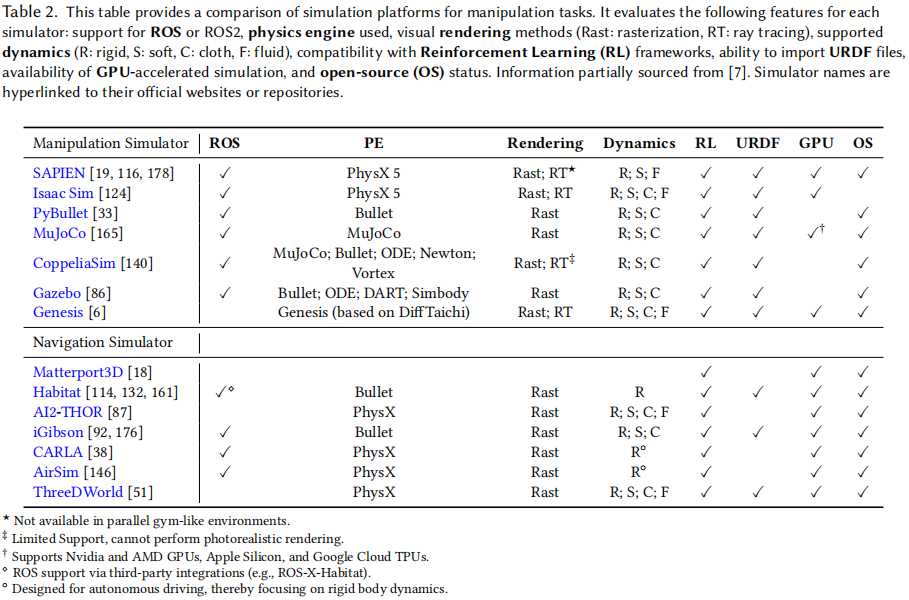
1.经典物理引擎和模拟器:
经典模拟器以传统力学模拟物理动力学和接触建模,是机器人仿真基础,以下是关键经典模拟器及其应对物理和视觉仿真到现实挑战的方式:
(1)Gazebo:与机器人操作系统 (ROS) 紧密集成,支持多种物理引擎(如 DART、ODE、Bullet)进行刚体动力学模拟。视觉上利用开源 3D 图形引擎 (OGRE),支持 GPU 加速着色,但无光线追踪和逼真视觉效果。
(2)PyBullet:专注速度和效率,基于 Bullet 物理引擎,提供 GPU 加速和连续碰撞检测。使用线性互补问题 (LCP) 接触模型,计算量大且接触点处对摩擦锥近似不准确。渲染通过 OpenGL 光栅化,不支持光线追踪和深度噪声模拟,难以缩小视觉仿真到现实差距。
(3)MuJoCo:注重接触动力学精度,在灵巧操作中有用,多关节系统模拟出色,准确建模接触,使用广义坐标捕获机器人操纵器动力学,实现稳定、富含摩擦的交互,但软接触模型碰撞时可能穿透。视觉上基于 OpenGL 光栅化渲染,无硬件加速实时光线追踪,限制视觉保真度,支持多线程加快强化学习速度。
(4)Isaac Sim 和 SAPIEN:在逼真渲染方面表现突出,利用 GPU 加速的光栅化和实时光线追踪创建逼真环境,缩小视觉仿真到现实差距。SAPIEN 支持内置先进深度噪声模拟,生成逼真深度图,提高仿真到现实迁移能力。二者使用 Nvidia PhysX 引擎进行物理模拟,可对刚体、软体和流体动力学进行强大模拟。
(5)CoppeliaSim:支持多种物理引擎(MuJoCo、Bullet、ODE、Newton、Vortex),能模拟刚体、软体和布料动力学,可根据任务定制物理模拟,但缺乏 GPU 加速影响效率。渲染主要基于 OpenGL 光栅化,部分支持光线追踪,逼真度不如 Isaac Sim 和 SAPIEN。
2.可微物理引擎和模拟器
可微物理引擎计算模拟状态相对输入(动作、物体姿态等)的梯度,通过可微函数对现实物理建模,使策略能针对现实性能优化,提升对现实应用的适应性与可迁移性。
(1)Dojo:基于优化第一原理设计,改进接触建模,将接触仿真表述为优化问题,提供运动学梯度信息,应用隐函数定理给出平滑可微的梯度。
(2)DiffTaichi:是用于可微模拟器的编程语言,采用 megakernel 方法,合并多个计算阶段为一个 CUDA 内核,充分利用 GPU 加速仿真。
(3)Genesis:基于 DiffTaichi 构建的开源模拟器,针对可微仿真全面优化,支持基于梯度对神经网络控制器优化,仿真速度比现有 GPU 加速模拟器快 10 到 80 倍,还包含光线追踪系统用于逼真渲染,以及生成数据引擎,可将自然语言转换为多模态数据用于自主训练环境生成。
基准数据集
我们在这里概述了为推动各类操作任务而开发的基准数据集。这些数据集对增强智能体在不同任务、环境及机器人平台上的泛化能力十分关键。文中按基准数据集所支持的操作任务进行分类,涵盖从简单刚体操作到复杂移动操作场景,再到需智能体整合多模态输入的语言条件操作。同时,还探索了为训练智能体视觉感知模块而定制的数据集,这种分类有助于研究人员找到符合自身研究需求的数据集。图 10 比较了这些操作基准数据集。上图以对数尺度展示了数据集内容的规模和多样性,y 轴表示数量,x 轴列出基准数据集的名称。每个条形代表数据集中一个关键元素(如环境、任务、场景、物体类型)的数量,选择该元素以反映其重点,并按类别进行着色。下图评估了不同方法的性能,y 轴表示平均成功率 (%),x 轴列出相同的基准数据集。每个条形代表各种方法在基准任务上的平均成功率,按评估的任务进行着色。这些图共同描述了数据集的特征和性能结果,使研究人员能够分析数据的可用性和不同任务的方法性能基线。
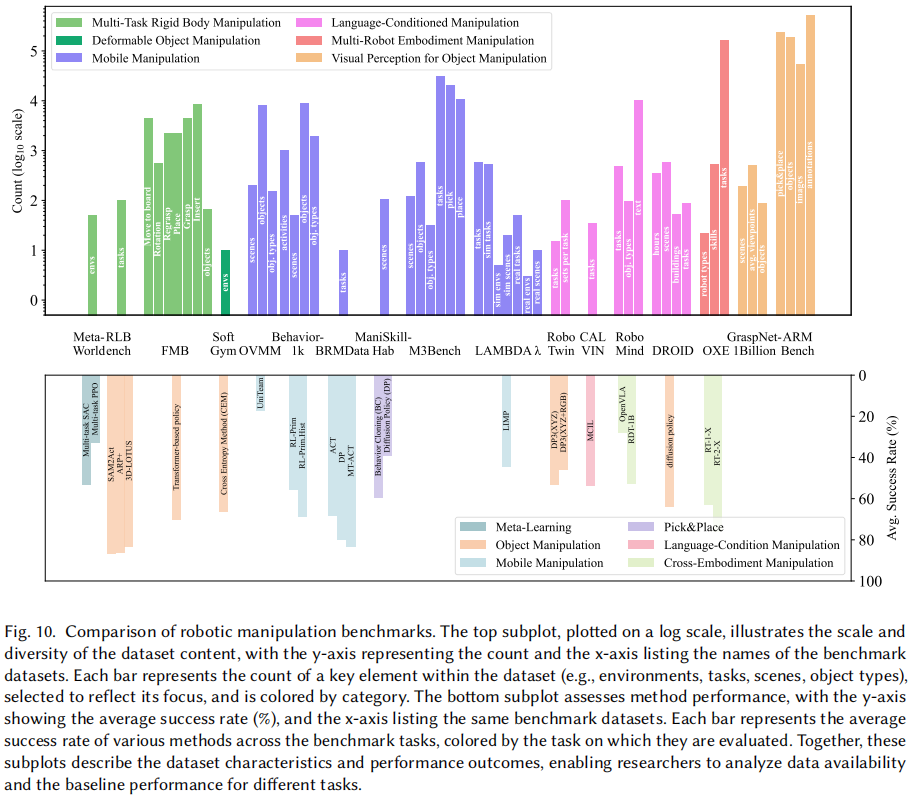
1.刚体操作基准:Meta-World 有 50 个刚体操作环境,RLBench 含 100 个任务,二者用于训练智能体掌握基本技能并评估其对新任务的泛化能力。
2.可变形物体操作基准:SoftGym 有 10 个模拟环境,Plasticinelab 用 DiffTaichi 进行可微软体模拟,但它们关注单一材料和简单任务,缺乏多样性。GRIP 数据集引入全面基准,包含软、刚性抓手与 1200 个不同物体交互,基于高保真、并行化的 IPC 模拟器,提供变形和应力分布详细模拟数据。
3.移动操作基准:移动操作基准评估智能体在需导航和操作任务上的表现。OVMM 基准有 200 个人工编写的 3D 场景、7892 个物体;Behavior-1k 基于 Omnigibson 模拟器,含 1000 项家庭活动、50 个交互式场景、超 1900 种物体类型和 9000 多个物体模型;ManiSkill-Hab 专注于 ManiSkill3 平台上的三个长期家庭任务,以超 30000 FPS 提供逼真模拟;BRMData 提供 10 种家庭任务,智能体需用移动平台上的双臂完成。
4.语言条件操作基准:语言条件操作基准评估机器人解释和执行自然语言指令的能力。CALVIN 有 34 个长期任务及特定多步骤指令;RoboTwin 利用大语言模型生成操作环境和任务;RoboMind 提供 55000 个真实演示轨迹、跨越 279 个任务和 61 个物体,适应多种环境;DROID 有 76000 个真实演示轨迹、跨越 564 个场景和 86 个任务。
5.多机器人实体集合数据集:Open X-Embodiment 使用 22 种机器人类型数据训练 X - 机器人策略,有超 100 万个任务演示轨迹,是最大开源真实机器人数据集。
6.视觉感知数据集:Graspnet-1 Billion 用于增强抓取和感知任务,含 97280 张图像,标注有 6D 物体姿态和抓取点,涵盖 88 个物体,提供超 11 亿个抓取姿态。
方法
强大且可泛化的机器人操作依赖于准确的环境感知和有效的控制策略。该领域的研究主要集中在两个主要方向:感知表示和策略学习。感知表示涉及从场景中提取丰富的 3D 或多模态信息以指导操作。策略学习侧重于生成用于任务执行的精确控制命令。
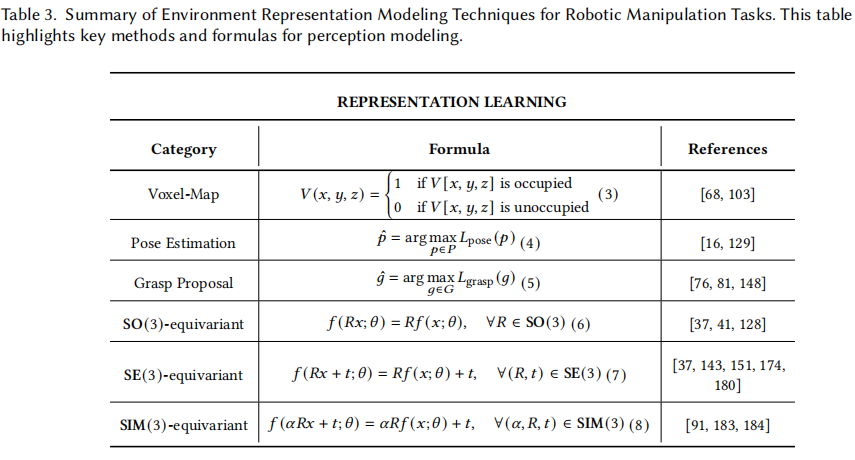
1.感知表示:
感知是机器人操作的基础,3D 空间细节程度因任务复杂性而异。感知表示方法按粒度分类:
(1)体素地图表示:基于体素的表示将 3D 空间离散为占用网格,每个体素反映坐标占用情况。例如,VoxPoser 和 VoxAct-B 结合体素网格和视觉语言模型。VoxPoser 用视觉语言模型解释语言指令,生成突出任务相关区域的体素地图;VoxAct-B 用于双手操作。这些方法能识别场景中任务特定感兴趣区域,如在拾取和放置任务中,体素地图可突出物体把手以便抓取。
(2)物体级表示:多项工作关注物体级表示,如 6D 姿态估计和基于功能的抓取提议。6D 姿态估计预测物体位置和方向,如 Pix2Pose 用像素级坐标回归从 RGB 图像估计 3D 坐标,无需纹理 3D 模型;FoundationPose 提供统一框架用于 6D 姿态估计和物体跟踪,兼容基于模型的方法和神经隐式表示。语言嵌入辐射场(LERF)结合视觉语言模型和 3D 场景表示生成零样本任务特定抓取提议,LERF-TOGO 利用自然语言提示查询任务特定物体区域;F3RM 提取语义特征融入 3D 表示,实现少样本抓取和放置学习;GraspSPlats 通过显式高斯溅射提高抓取选择效率和准确性以实现实时提议。
(3)SO (3)、SE (3) 和 SIM (3) 等变表示:等变表示使操作智能体感知模块能在各种变换下对不同输入泛化。SO (3) 等变性确保输入 3D 点云旋转时,学习到的表示同步旋转;SE (3) 等变性包含旋转和平移变换,让模型在物体不同位置和方向上泛化;SIM (3) 等变性还考虑尺度变换,可对不同大小物体进行操作。
(4)SO (3)- 等变表示:向量神经元网络(VNNs)实现了对 3D 点云的 SO (3) 等变表示学习,定义如公式 6。这一属性确保网络 f 的输出与输入 x 以相同方式旋转。VNNs 的关键机制是保留输入的旋转信息。具体来说,VNNs 将神经元扩展为 3D 向量,并在线性层中应用满足 (对于任何旋转群 R)的线性变换。对于非线性层,VNNs 通过在与旋转无关的方向上裁剪特征 V 来扩展 ReLU。具体而言,除了线性变换后的特征 ,VNNs 还学习第二个权重 U,它产生一个方向向量 。非线性层的输出为:
内积是旋转不变的,因为 ,使得整个裁剪操作具有旋转不变性。池化层和批归一化也被设计为保留输入的方向信息,确保整个模型的输出保持旋转等变。
(5)SE (3)- 等变表示:神经描述符场(NDFs)从 3D 物体坐标生成到描述符(也称为特征向量)的连续 SE (3) 映射,用于下游操作任务。这些描述符在任何刚性变换(旋转和平移)下保持一致。形式上,描述符函数 f 满足公式 7,其中 是 SE3 群的一个元素,x 是来自物体点云 P 的 3D 查询点。NDFs 使用向量神经元确保 SO (3) 等变性,并通过将 VNNs 与通过平均中心偏移 ( )的平移相结合来实现 SE (3) 等变性,确保函数仅考虑点云中点的相对变换,这些变换对于刚体变换保持不变。相关工作如等变描述符场(EDFs)将 NDFs 扩展为 “双等变”,以处理被抓取物体和放置目标在 3D 空间中独立移动的情况。此外,Useek 通过检测 SE (3) 等效关键点,实现对任意 6 自由度姿态物体的操作。而且,Equi-GSPR 和 SURFELREG 将 SE (3) 等变特征应用于点云配准,进一步提高了 3D 感知的鲁棒性。
(6)SIM (3)- 等变表示:最近的工作探索了 SIM (3) 等变学习,它将 SE (3) 扩展到包括尺度,如公式 8 所示。EFEM 引入了一种基于符号距离函数(SDF)编码器 - 解码器的 SIM (3) 等变形状先验学习: , 。这里,Φ 是一个基于 VN 的编码器,将点云 P 映射到潜在嵌入 e,Ψ 预测查询位置 x 处的 SDF。VNNs 和平均中心确保旋转和平移等变性,而尺度等变性通过通道归一化强制执行。
(7)视觉触觉感知:触觉传感器使机器人能够感知摩擦和表面纹理,实现精确抓取和灵巧的手部内操作。与 RGB-D 相机不同,触觉传感器能够通过接触补充视觉数据,解决了 RGB-D 相机在检测视觉遮挡物体形状时的局限性。例如,NeuralFeels 和 DIGIT 360 将视觉和触觉集成在多指机器人手中,通过让系统准确估计物体的姿态和形状,即使在视觉遮挡下也能增强空间感知。
2.策略学习:
具身操作的进展集中在基于学习的方法,策略 根据当前状态 和先前动作 确定下一个动作 ,在马尔可夫决策过程框架内运行。
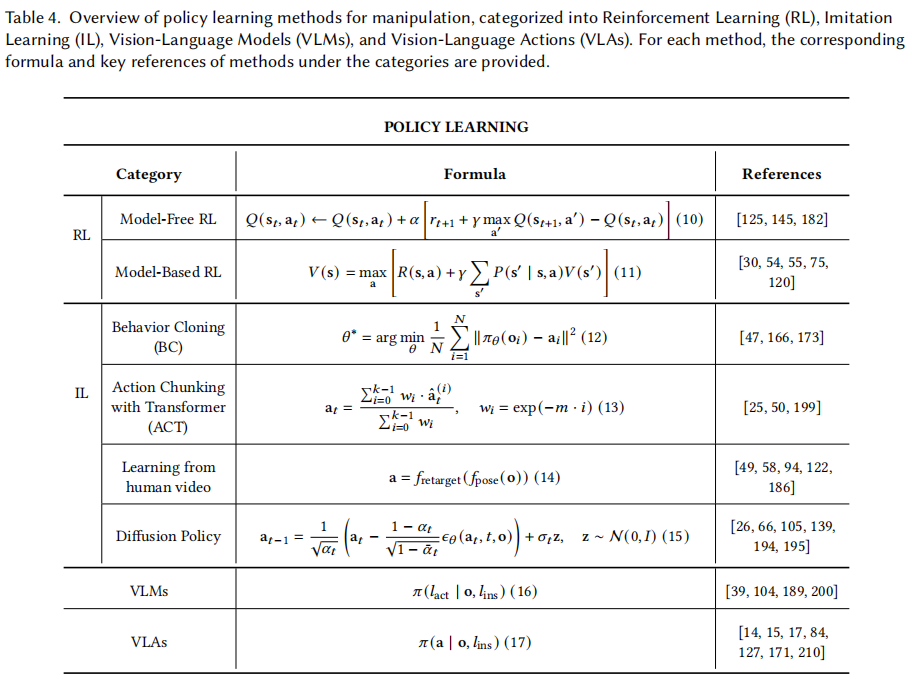
(1)强化学习(RL):分为无模型和基于模型两类。无模型 RL 直接优化策略,如 Q 学习;基于模型 RL 构建状态模型用于规划决策,如 OpenAI 用无模型近端策略优化进行灵巧操作,Nagabandi 等人用神经网络近似状态转移分布用于在线规划,这两种方法依赖大量试错,处理复杂任务效率低。
(2)模仿学习(IL):用专家演示指导 RL 智能体,如人类婴儿模仿父母。行为克隆(BC)是 IL 基本算法,如 MOMART 框架应用 BC 于移动操作任务。BC 早期预测差异会导致偏离训练分布,Zhao 等人引入基于 transformer 的动作分块(ACT),Feng 等人采用交叉注意力机制整合多模态感官输入。一些研究结合 IL 与 RL,IL 面临动作数据稀缺问题,可利用大规模人类动作视频解决。
(3)扩散策略(DPs):利用去噪扩散概率模型根据观察生成动作数据,扩散模型在 IL 优化中表现出色。Liu 等人提出 RDT-1B 泛化输出动作空间,增强知识可转移性,部分研究专注学习基于点云的 3D 表示,3D 扩散策略在复杂环境中表现优越,集成扩散模型可对复杂动作分布建模以实现精细操作学习。
(4)视觉语言模型(VLMs):在视觉语言推理中表现出色。如 EMMA 将视觉观察转换为文本描述生成动作,PaLM-E 集成文本指令标记和观察图像嵌入推理动作,OK-Robot 扫描环境创建导航地图定位物体,AlignBot 微调 LLaVA 生成任务计划。
(5)视觉 - 语言 - 动作模型(VLAs):机器人 transformer-1(RT-1)是基础,VLAs 使 VLMs 能从高级指令生成低级动作。RT-2 结合高级语义理解和低级控制,RT-H 引入语言 - 运动层次结构,Pan 等人开发框架在 VLA 控制和扩散策略间切换处理精细操作,Diffusion-VLA 集成 LLMs 与扩散模型, 用流匹配技术生成电机动作,RT-X 在 OXE 存储库训练通用策略,OpenVLA 是 RT-X 开源版本。
(6)等变策略学习:VLMs 和扩散策略未明确学习几何变换泛化,EquivAct 利用 EFEM 编码器学习 SIM (3) 等变视觉运动策略,Equibot 结合 SIM (3) 等变编码器与扩散策略处理多模态数据并预测未来动作。
未来方向
1.高效学习:Lin 等人证明扩展数据可使单任务策略泛化,但与生物系统的高效适应(人类和动物能以较少经验快速适应新任务)形成对比。未来研究方向是开发提高学习效率的算法和系统创新,如持续学习,有研究表明持续学习能让机器人从演示中持续学习,减少对大量数据的需求。2.持续学习:对具身智能体在动态环境中学习适应且保留先验知识很关键,在视觉语言导航中灾难性遗忘是挑战。新兴方法有重放机制(如弹性权重巩固、元学习)和记忆架构(如 Titans 神经长期记忆模块)。相关研究推动该领域发展,NeSyC 引入神经符号持续学习者处理开放领域复杂任务,Zheng 等人给出基于大语言模型的智能体终身学习路线图,强调感知、记忆和动作模块以增强适应性并减轻遗忘。3.神经常微分方程:具身人工智能任务(如倒液体)需连续动力学建模,离散方法存在挑战。神经常微分方程可实现连续状态演化,改进轨迹预测和控制,液体网络处理不规则输入实现实时适应,但需实证验证。4.评估指标:当前评估指标过于以目标为导向(如成功率、路径匹配长度)。提倡受人类任务执行启发的过程质量指标,如能源效率和流畅度。Jiang 等人的探索感知具身问答框架等基准,通过在任务评估中强调探索,能更全面评估具身人工智能性能。
结论
我们全面探讨具身人工智能,聚焦导航和操作任务。通过整合方法、模拟器、数据集和评估指标的进展,为具身人工智能社区提供结构化且详细的资源。分析强调基于物理的模拟器的关键作用,其能让智能体学习可微物理规则,通过精确物理建模和逼真渲染缩小仿真与现实差距。追溯导航和操作方法演变,突出向数据驱动的基础方法(如世界模型和视觉 - 语言 - 动作模型)转变,体现向多功能、数据丰富策略的趋势。通过分析模拟器特性和硬件要求,帮助研究人员选择符合计算约束和研究目标的工具。
参考
[1] A Survey of Robotic Navigation and Manipulation with Physics Simulators in the Era of Embodied AI
论文辅导计划

具身智能干货社区
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1500人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、VLA、VLN、具身大脑、具身小脑、大模型、视觉语言模型、强化学习、Diffusion Policy、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近30+学习路线、40+开源项目、近60+具身智能相关数据集。

全栈技术交流群
具身智能之心是国内首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、VLA、机械臂抓取、Diffusion Policy、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)。


















 1225
1225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









