








为什么知识库需要
Embedding Model?
通过询问 DeepSeek-R1 得到如下回答:
Embedding 模型的核心价值在于将非结构化文本转化为数值向量,解决语义理解与计算效率问题:
语义编码:通过向量空间捕捉上下文关联,区分多义词、同义词;如:
问题:用户搜索“苹果”,需区分“水果”还是“品牌”。
Embedding 作用:
-“苹果手机”的向量会接近“iPhone”“智能手机”;
-而“红苹果”的向量会接近“水果”“香蕉”“维生素”。
结果:搜索“苹果”时,优先展示手机或水果,取决于用户历史行为(如点击电子产品)。
高效检索:支持近似最近邻(ANN)算法,降低海量数据匹配复杂度;
场景:某电商平台有 1 亿商品描述,需实时匹配用户查询“适合露营的轻便帐篷”。
传统方法:关键词匹配“露营+轻便+帐篷”,可能漏掉“户外超薄遮阳篷”。
Embedding 方案:
-将查询和商品描述转为向量;
-使用 ANN 库(如 FAISS )在毫秒级返回
Top100 相关商品,覆盖语义相似但关键词不匹配的结果。
AI 基础设施:支撑 RAG 、多模态搜索、迁移学习等任务,替代传统关键词匹配与人工规则。
场景:客服机器人回答“如何清洁帐篷上的污渍?”
流程:用 BGE-M3 将问题编码为向量;
-从向量数据库检索《户外用品保养指南》中相关段落;
-将检索结果输入大模型(如DeepSeek-R1),生成步骤清晰的回答。
优势:避免大模型虚构答案,提升可信度。
与传统方式相比具备优势


为什么选择
bge-m3 Embedding 模型?
根据了解,BGE-M3 模型是当前领先的多语言 Embedding 模型,在 MIRACL、MKQA 等基准测试中排名第一,支持 100+ 语言,具备三大特性:
1.多语言性:覆盖 194 种语言训练,跨语言检索效果显著;
2.多功能性:统一支持密集、稀疏、多向量三种检索模式;
3.多粒度性:支持最长 8192 tokens 输入,适配长短文本。其训练采用知识蒸馏与高效批处理技术,结合 1.2 亿文本对与合成数据优化性能。
并且腾讯云其他 AI 应用中该模型使用的也较为广泛。本次,Cloud Studio 在DeepSeek-R1 模板中内置了 BAAI/bge-m3。希望给知识库玩家带来更加准确的召回效果,让工具更加实用。
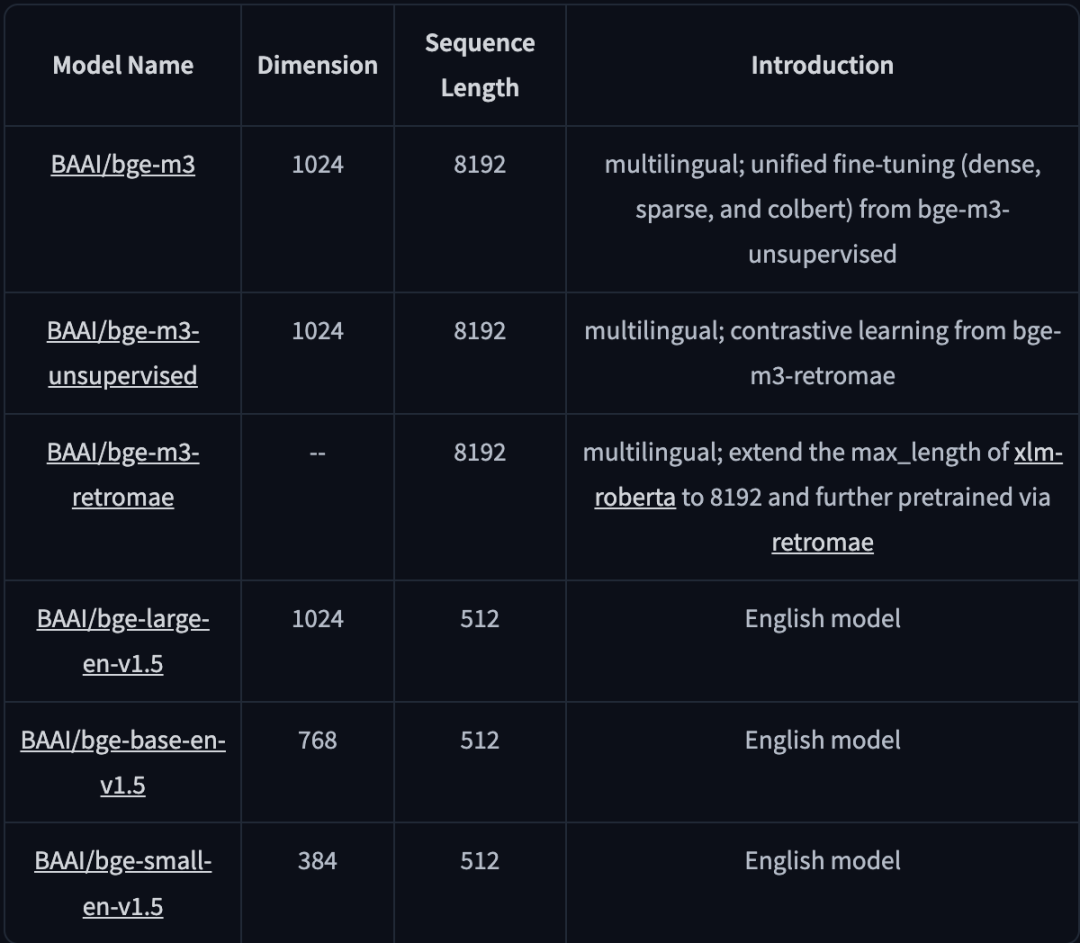

如何在
CloudStudio DeepSeek-R1 模板中设置 bge-m3
步骤一 :
进入 Cloud Studio DeepSeek CPU 模板,唤起内置 Open-WebUI 或 AnythingLLM 组件。进入网站:
https://ide.cloud.tencent.com/dashboard/
点击任意 DeepSeek CPU 模板进入工作空间, 唤起 Open-WebUI 或 AnythingLLM, 即刻拥有完全属于个人的知识库。相对于本地搭建 RAG 知识库,体验门槛直线降低!
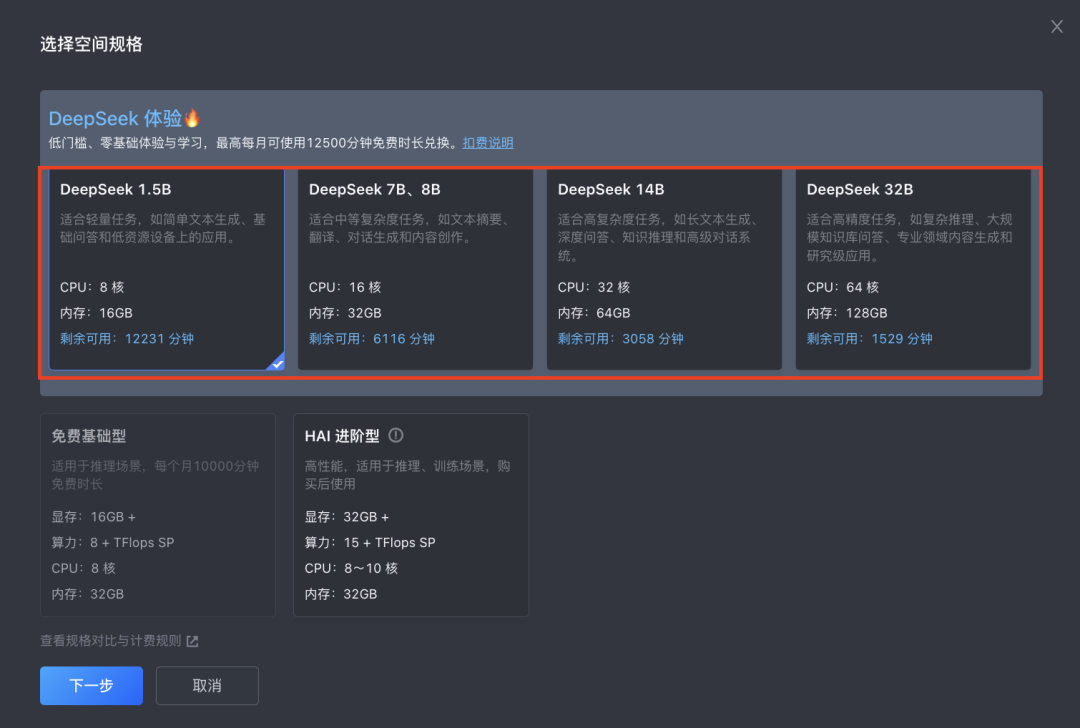
进入工作空间后,默认唤起 AnythingLLM (4001端口),点击图中 icon ,进入浏览器全屏模式
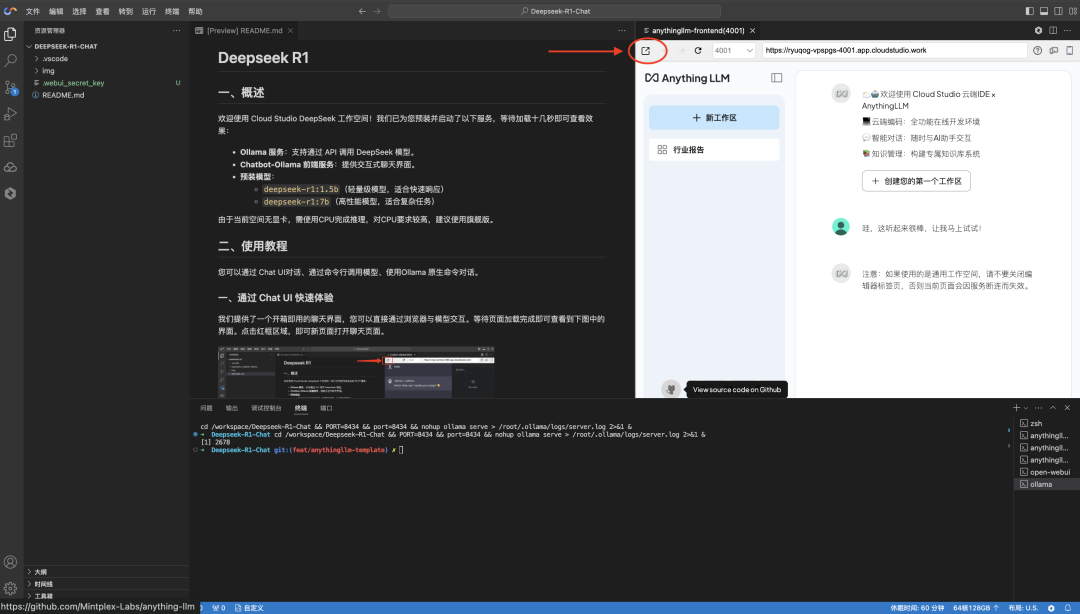
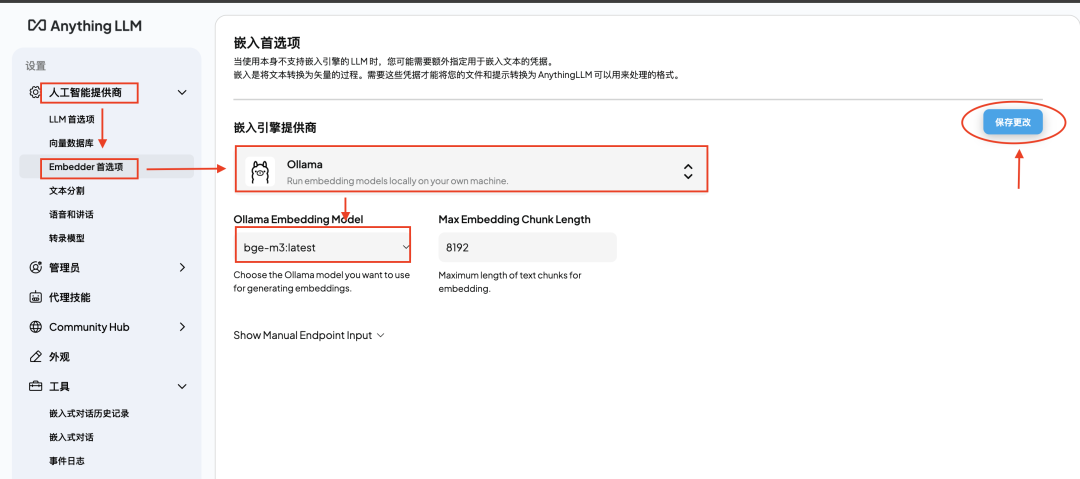
点击左下角【设置】
进入【人工智能提供商】-【Embedder首选项】,在【嵌入引擎提供商】处选择“Ollama”,随后在下方【Ollama Embedding Model】处选择“bge-m3:latest”。
选择完毕后点击【保存更改】
步骤二:
创建【工作区】即可开始进一步构建知识库进行对话。这里重复介绍一下如何创建和设置知识库进行对话。
上传文档
在聊天界面中,用户可以创建多个工作区。每个工作区可以独立管理文档和 LLM 设置,并支持多个会话(Thread),每个会话的上下文也是独立的。
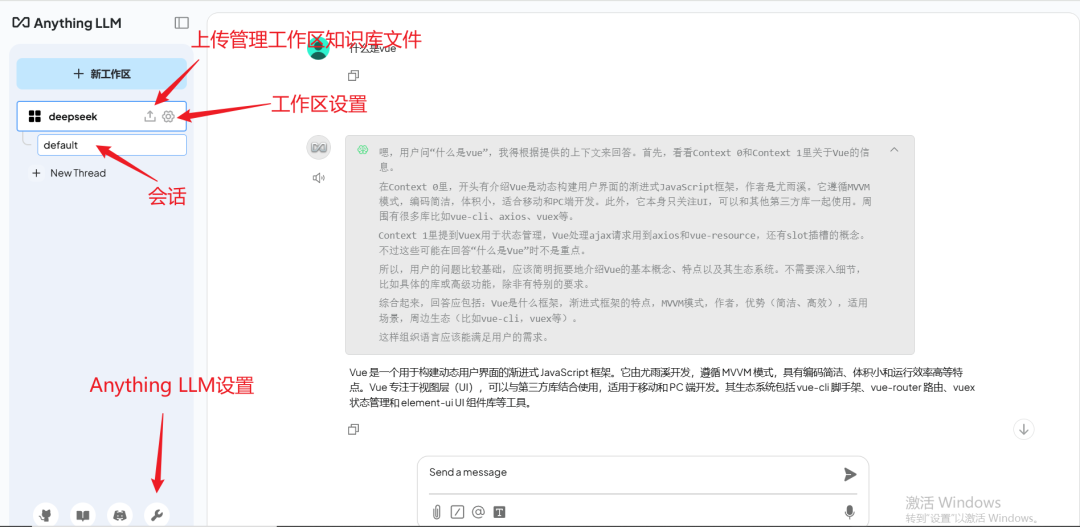
点击上传图标,可以管理当前工作区的知识库。以本地文档上传为例,用户可以管理已上传的文档,并通过下方的上传按钮或拖拽方式上传新文档。
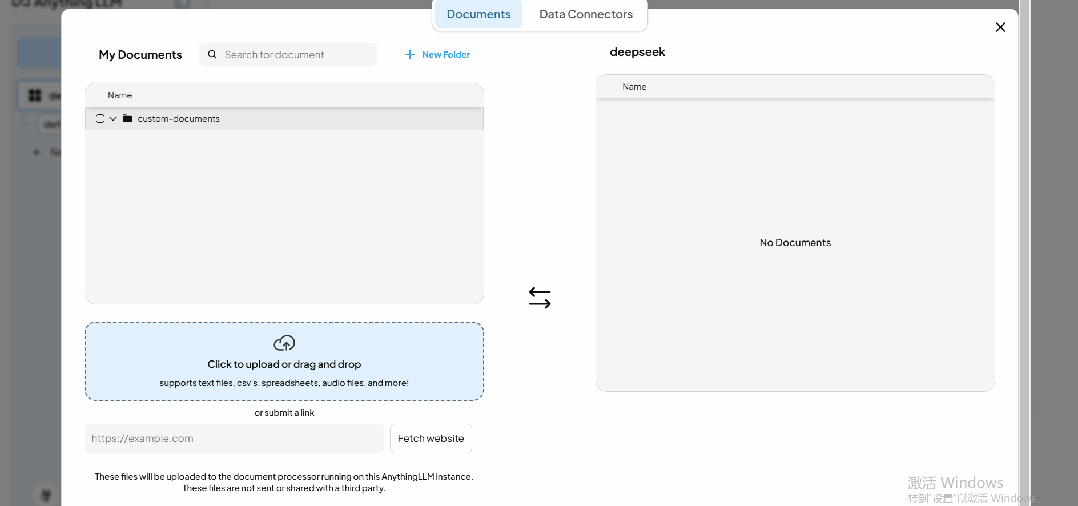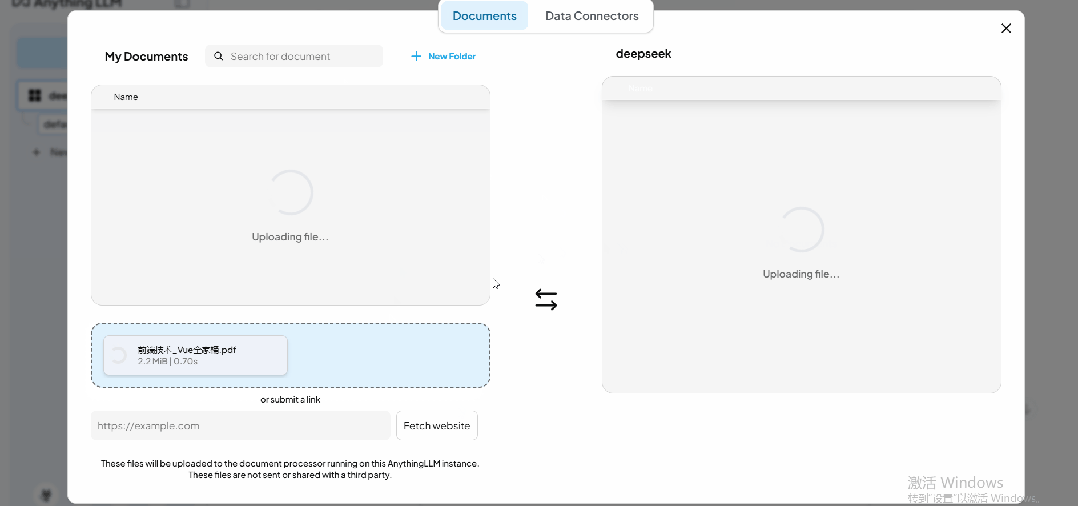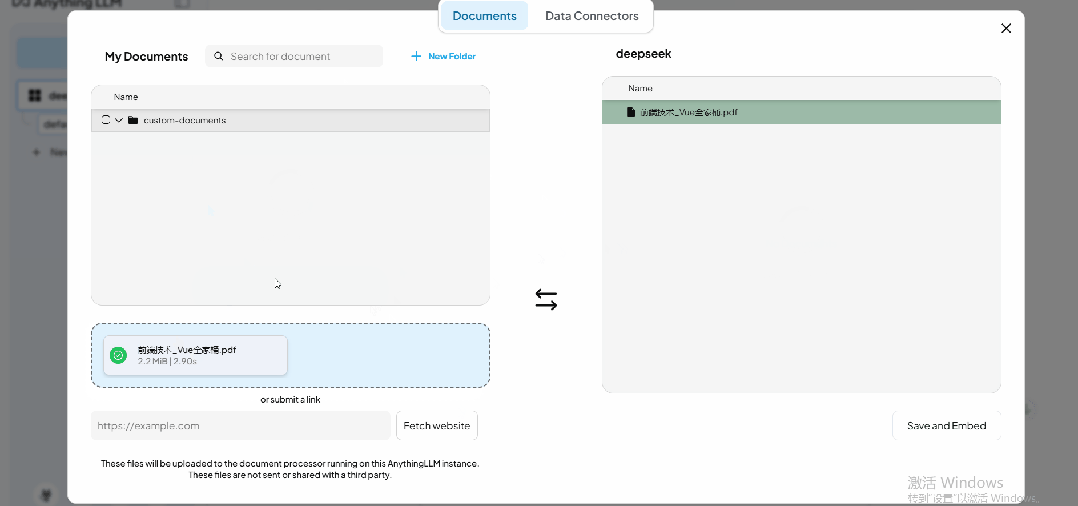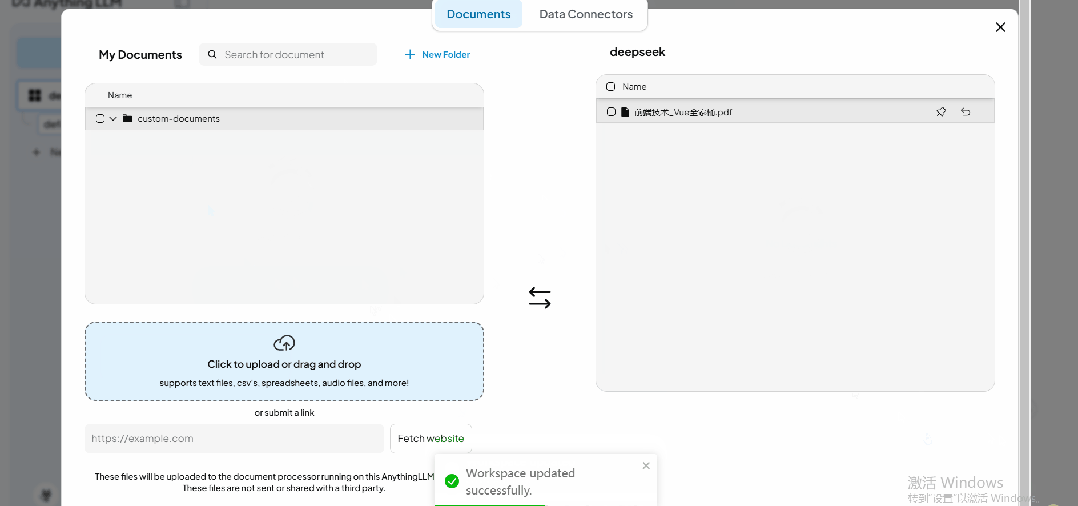
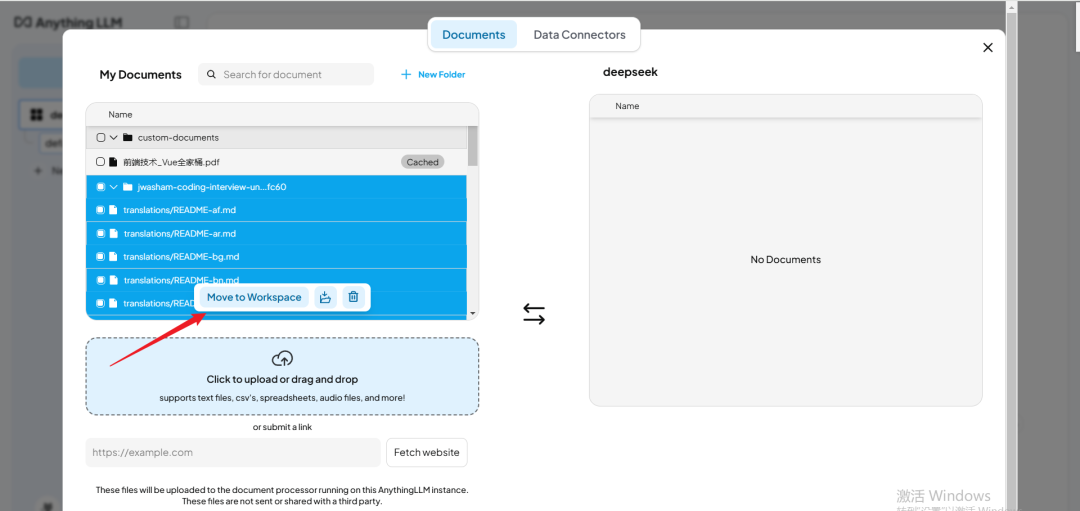
导入完成后,用户可以在 【Documents】 界面选中文件,并点击 【Move to Workspace】 将其添加到工作区。
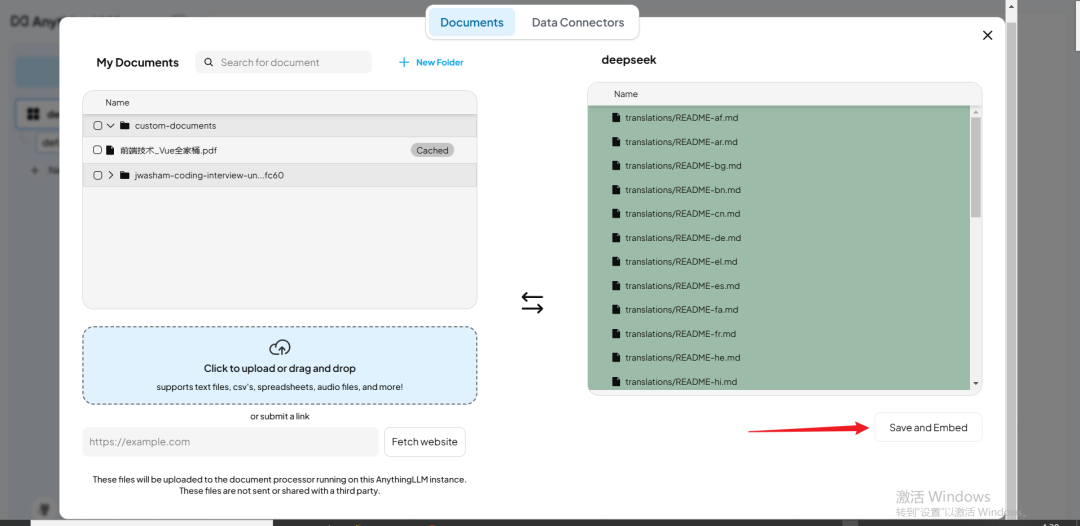
添加到工作区后,点击 【Save and Embeded】,将文档内容转换为向量检索所需的嵌入数据结构。
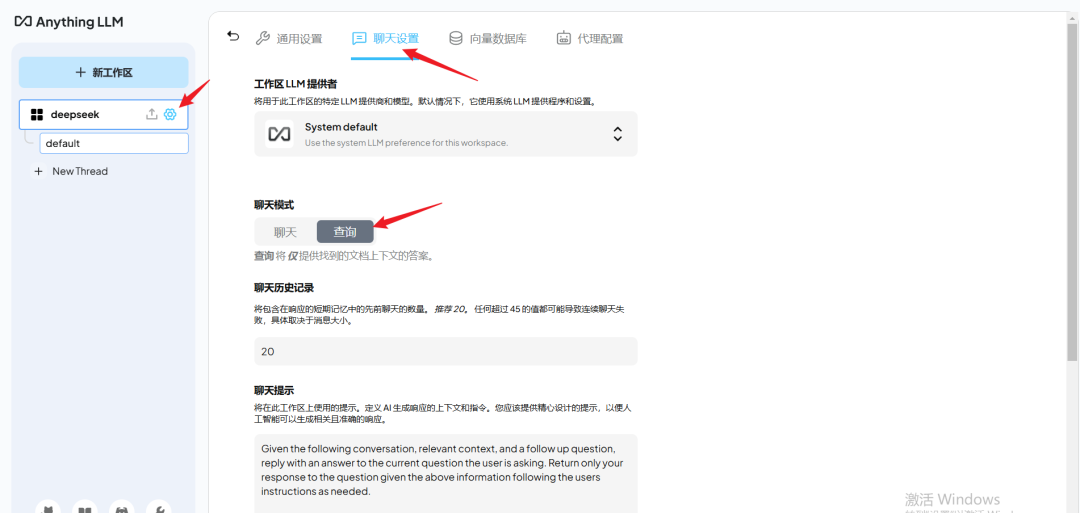
聊天模式
将文档添加到工作区后,用户可以通过设置聊天模式调整 DeepSeek-R1 的回复方式,在【工作区LLM提供者】处可选用 DeepSeek-R1模型类型,比如 7b 。
聊天模式:聊天 将提供 LLM 的一般知识 和 找到的文档上下文的答案。
查询模式:查询将仅提供找到的文档上下文的答案。
在聊天窗口中,用户可以直接提问。deepseek-r1 会基于文档内容生成答案,并标注答案来源。
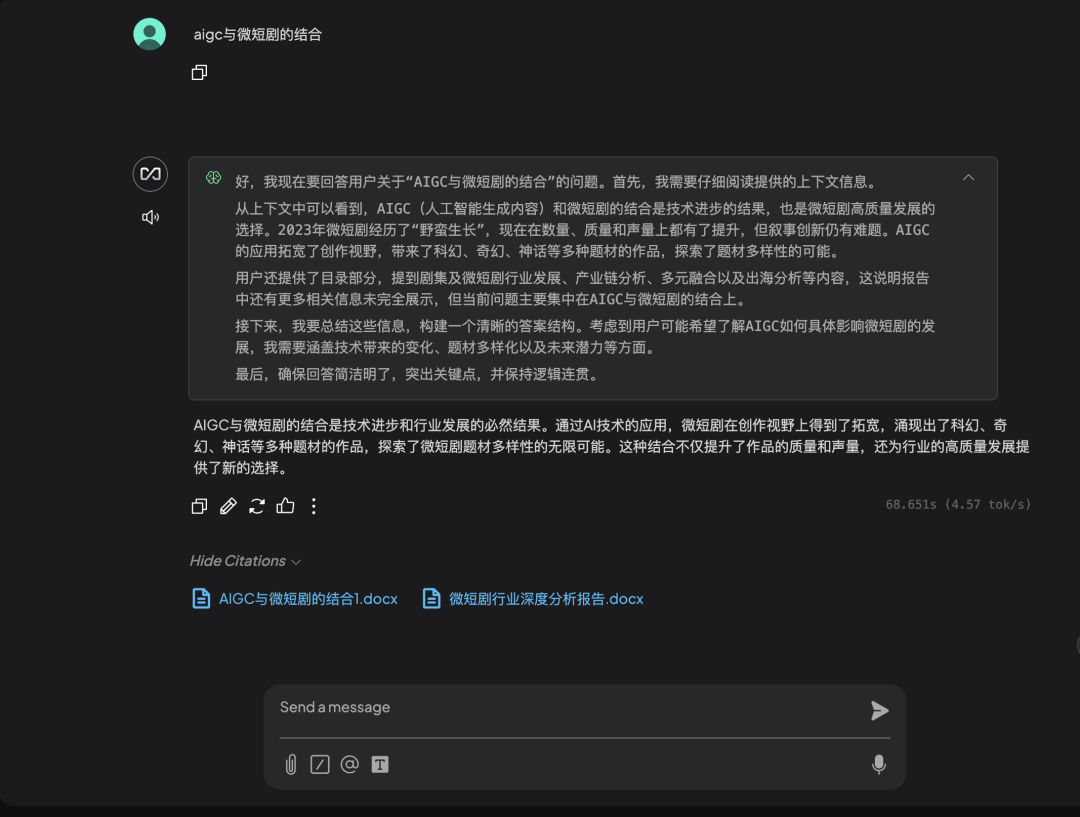
最后,我们来看看效果。
以 AnythingLLM 为例,在传入《微短剧行业深度分析报告》、与《 AIGC 与微短剧的结合》两份资料后,模型通过识别后者给出了相应的总结。

加入 Cloud Studio 自媒体特权计划
我们推出针对为 Cloud Studio 宣传的自媒体特权计划,招募长期合作的内容创作者,创作者将永久被授予 20000 分钟/月的基础版 GPU 使用配额。
20000分钟(333小时) 8+TFlops 算力、16GB+显存 的使用配额!什么概念!
可以系统化地利用 DeepSeek R1 模型实现从模型优化到实际落地的完整闭环。可生成数十万 10 万条营销文案、可提供稳定的高并发实时 API 服务。
心动吗?
还等啥呢?!
快来体验吧!!
参与方式
扫码联系工作人员进行登记初审:

入选标准
- 拥有自媒体账号,且输出稳定
- 过往具备 Cloud Studio 相关分享经验,且具备干货内容
- 长期使用 Cloud Studio 进行工作、学习
希望创作者
1. 在 ide.cloud.tencent.com 平台上使用 DeepSeek 相关模板
2. 将实践经验以视频或文章的方式发布到任意媒体渠道(包括但不限于B站、抖音、小红书、个人博客等)。实践内容包含但不限于模型推理、创建知识库、构建个人应用等。每月至少分享两次。
注意:我们鼓励原创和真实,请不要抄袭、搬运他人内容。

















 263
263

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









