







 文章讲述了如何使用知识图谱和异常检测算法改善PostgreSQL的复杂运维问题,通过实验性案例展示了D-SMART在智能诊断中的应用,包括从异常发现到问题收敛的过程,以及2.0版本在性能和分析能力上的改进。
文章讲述了如何使用知识图谱和异常检测算法改善PostgreSQL的复杂运维问题,通过实验性案例展示了D-SMART在智能诊断中的应用,包括从异常发现到问题收敛的过程,以及2.0版本在性能和分析能力上的改进。
PostgreSQL数据库是近年来热度上升最快的关系型数据库之一,近年来大量国内企业都在把系统向PostgreSQL上迁移。目前热度较高的国产数据库中也有一大半的厂商选择了PostgreSQL开源项目作为数据库产品的研发基础。不过PostgreSQL的运维一直是个难点,与Mysql相比,PostgreSQL过于复杂,运维难度远大于Mysql。而与Mysql相比,熟悉PostgreSQL运维与优化的DBA数量又远远不及。再加上开源数据库的文档资料相比Oracle等商用数据库来说更是差距甚大,如何做好PostgreSQL数据库的运维就成为很多企业面临的大问题。
在2020年的第十届中国PG用户大会上,我分享了一个主题-《基于知识图谱的PostgreSQL深度分析》,当时正好是基于PG的知识图谱1.0刚刚具备雏形的时候,正在实验性的用于D-SMART产品中,对PG等数据库进行辅助诊断。
在那个分享里,我介绍了利用团队梳理的知识库和异常检测算法进行PG数据库异常的自动诊断的一些尝试。
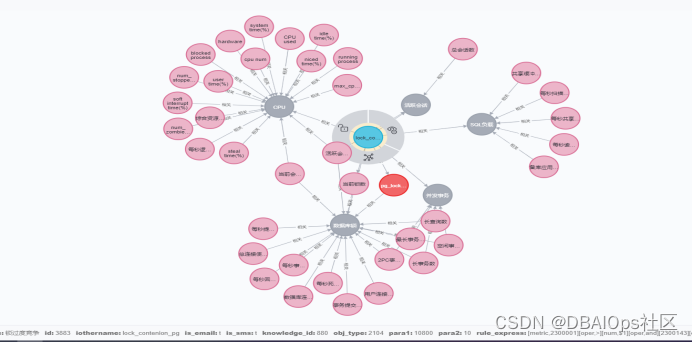
当时我们采用在生产系统中采样,并进行专家标注的方法构建分析中最为核心的异常检测算法,结合知识图谱定义的诊断路径,找出与某个故障现象相关的指标集,然后通过异常检测发现其中存在问题的子集,最后通过收敛算法,找到问题的根因。
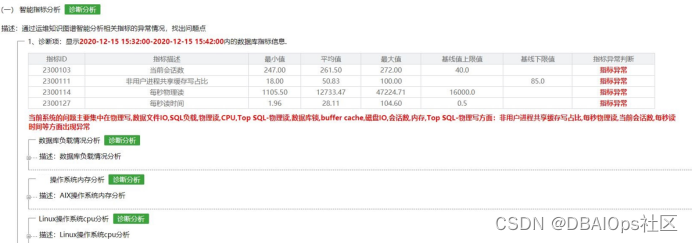
在那个演讲中,我举了一个实际的案例,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1937
1937

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









