






本地知识库的潜力与挑战:部署容易,用好^有点难。
常见问题:“睁眼瞎”、“幻觉”、“回答不准确”背后的原因。
本文目标:有必要了解一点点点的RAG检索增强生成的基本流程和原理,帮助解决实际应用中的困惑。
友好的AnythingLLM 1.7.x 默认配置并采用调用API的方式时,几乎不需要改任何参数。
但当遇到“睁眼瞎”或“幻觉”或“回答的不好”的时候,我们需要了解一点点RAG检索增强生成的基本流程和原理,来解答我们初学者(应用者)的困惑。
在经历了AnythingLLM构建的本地知识库**“一些场景处理的非常棒”和“一些问题根本做不好”的探索后,精益新生小A带着好奇和疑问,继续学习和探索,打开了RAG的一扇窗**(不敢说推开了一扇门……太太太复杂了)
本文继续带着问题和疑问了解和探索:
目的:
了解为什么本地知识库问答会出现**“睁眼瞎”和“一本正经的胡说八道”,使我们一般用户能够“问对问题”**,不至于纠结一些“小”问题点,在当前的“RAG框架能力”下,更好的使用。
注:不排除也非常期待2025年可以有“更聪明的、兼顾长短大小的、一招鲜吃遍天的RAG技术突破”
极简原理(理解版)
当我们用大模型进行一般性提问时,大模型问答(LLM-AIGC)是这样的;
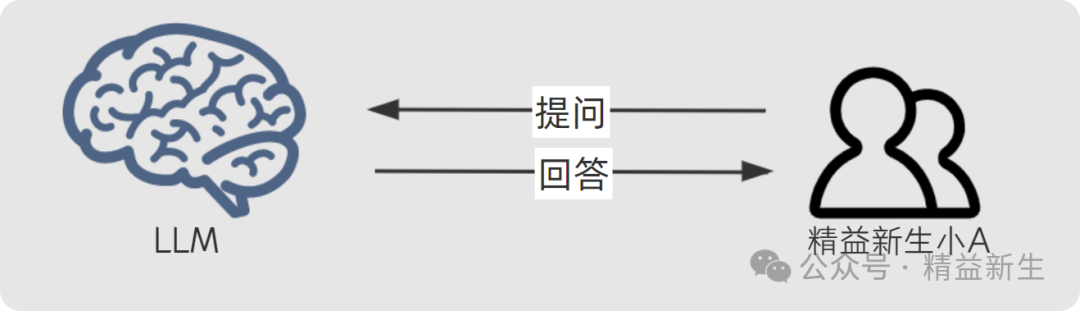
当我们要结合自己的知识材料,进行所谓“本地知识库检索增强生成RAG”是这样的:

RAG检索增强生成独特之处,就在与对本地知识的**“学一下”和“找一找”**。
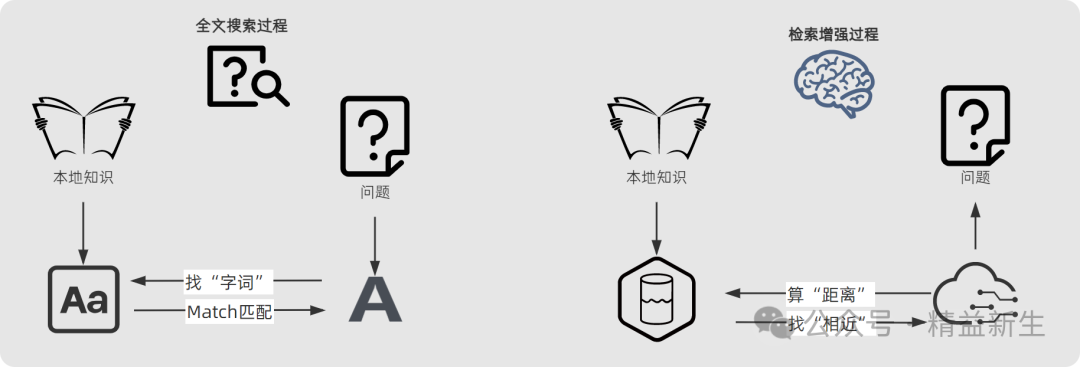
那RAG检索增强的“学一下”和“找一找”和最直接的全文搜索查找有何不同呢?
据我的理解,全文搜索和增强检索**“路径不同”,前者是通过直接的“找字词、对对碰”**的方式查找并匹配,后者是通过 **“算距离-找相近”**的方式“学习并检索”。

更详细的说,是“访问对象不同”,一个是“字符”,一个是“数据”,更准确的说是“向量数据”。
大预言模型的**“学一下、理解一下”**的神奇魔法之一可能就在这里了:人脑理解文字,电脑擅长计算“数据”,用向量化链接人脑的文字及语义及计算机理解的“数据最小、距离最近”……
更进一步的问题:RAG是如何把本地知识的文字,向量化成大预言模型可以检索的“向量”呢?完整过程是这样的:
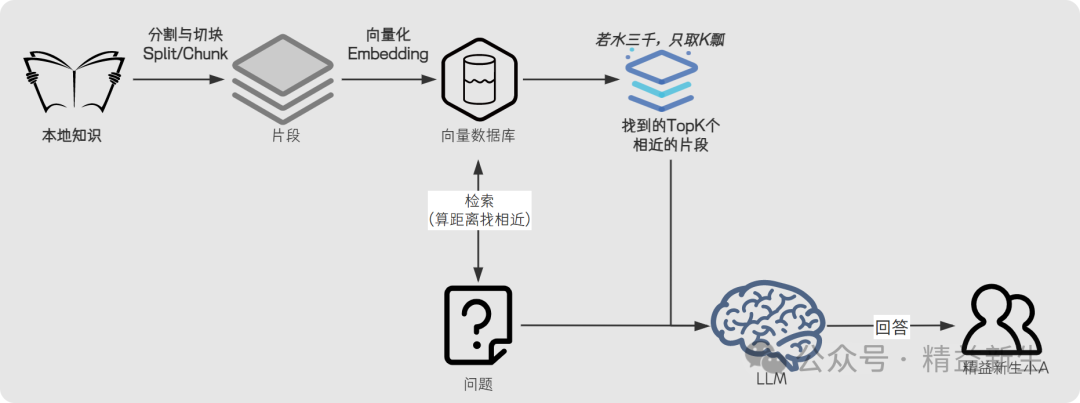
这就是进一步理解,AnythingLLM答疑回复的:
LLMs are not calculators and also you are asking for full context comprehension in a RAG system. RAG, by its very nature is pieces of relevant content. Not the entire text
LLM是不是计算器,而且您在RAG系统中要求_全文(完整的上下文)理解。RAG,就其本质而言,是相关内容的_片段,不是整个文本.
那有没有一种,即可以全文搜索,又可以增强检索的 “改进型RAG”呢,好像有,我问过DeepSeek了,好像叫**“混合增强检索”**(尴尬的笑)……
AnythingLLM中的几个关键参数和配置
其实,带着“文本截断”一个问题,就把整个“RAG管道”理解了一遍。

-
LLM脑容量=上下文大小,单位Tokens.
结合这个流程,基本可以看到:
1 分块处理
-
分块是为了向量化,在分块和向量编码的环节,要基本确保:分块大小 ≤ embedding模型极限
-
在确保分块大小 ≤ embedding模型极限的前提下:
-
分块太大:细节抓不住;
-
分块太小:切的太碎,上下文连贯不好。
-
问了一众大佬,没有给具体设定参数的,但精益新生小A试过以下几个参数:
-
256
-
512
-
1000
-
2000
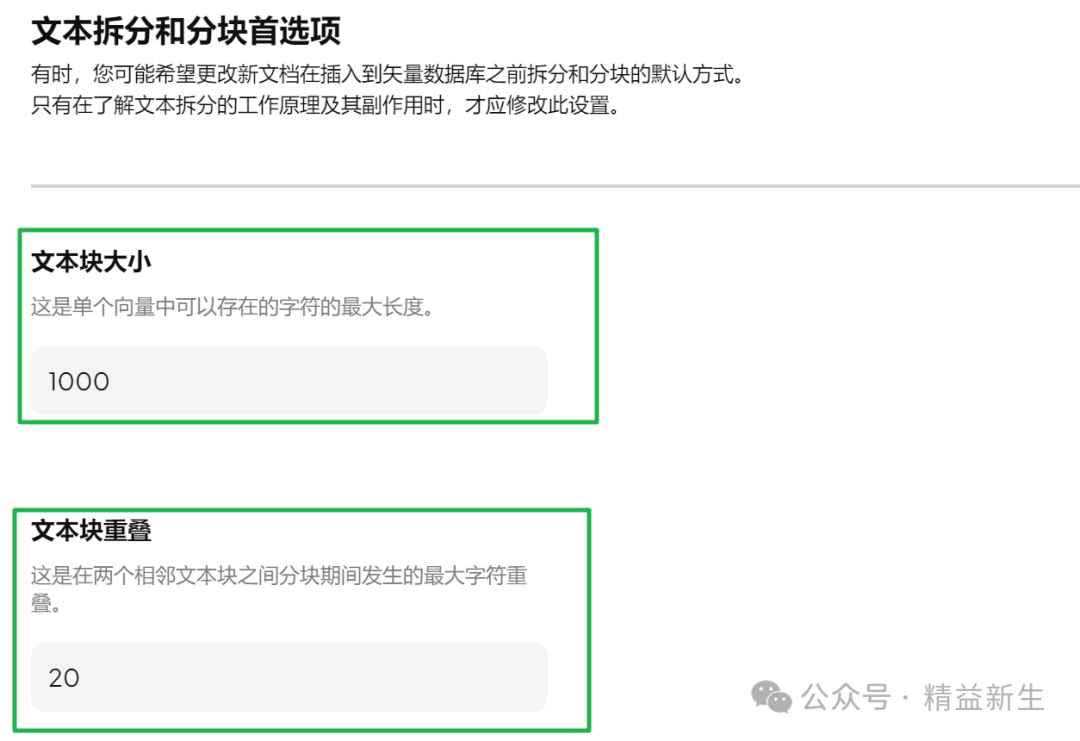
在AnythingLLM中,设置该参数在设置-文本分割-文本拆分和分块设置:
那下个问题:哪里可以查Embedding模型的能力大小?
2 Embedding 嵌入向量模型
在Ollama Models中可以搜索到向量模型,
以nomic-embed-text 为例,点开这个“model”里面是模型参数:
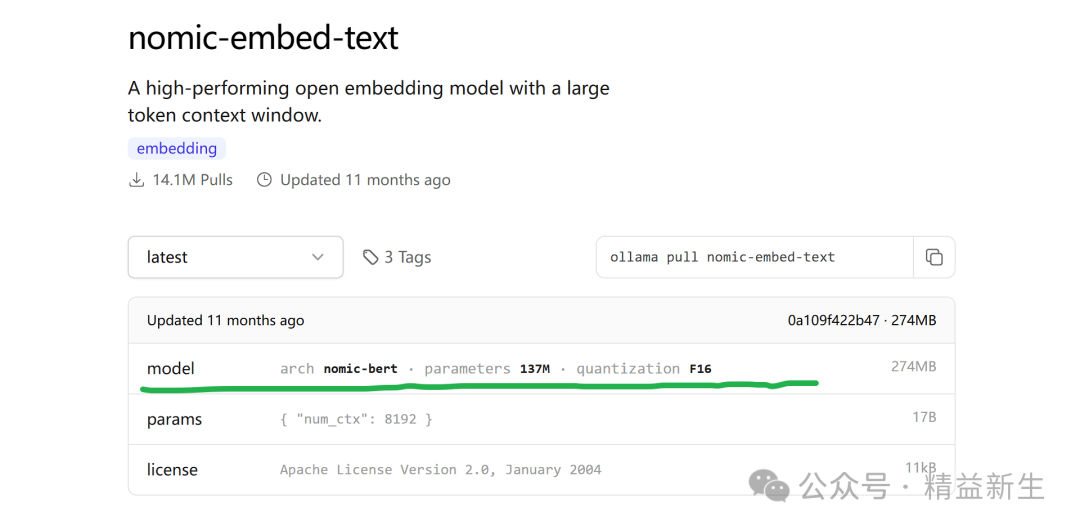
找到 context_length 就是了。
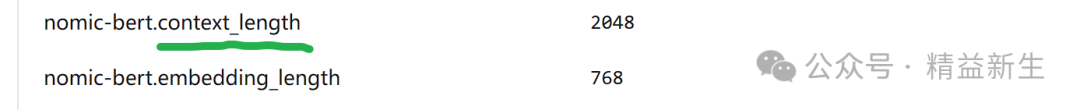
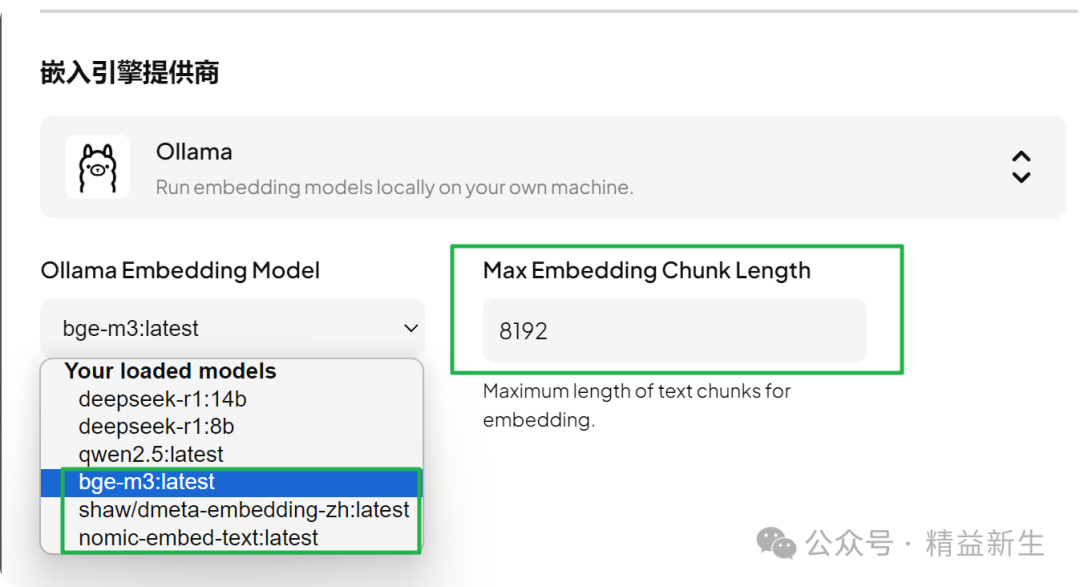
在AnythingLLM中,设置该参数在设置-Embedder嵌入首选项-选择模型-设置Max Embedding Chunk Length:
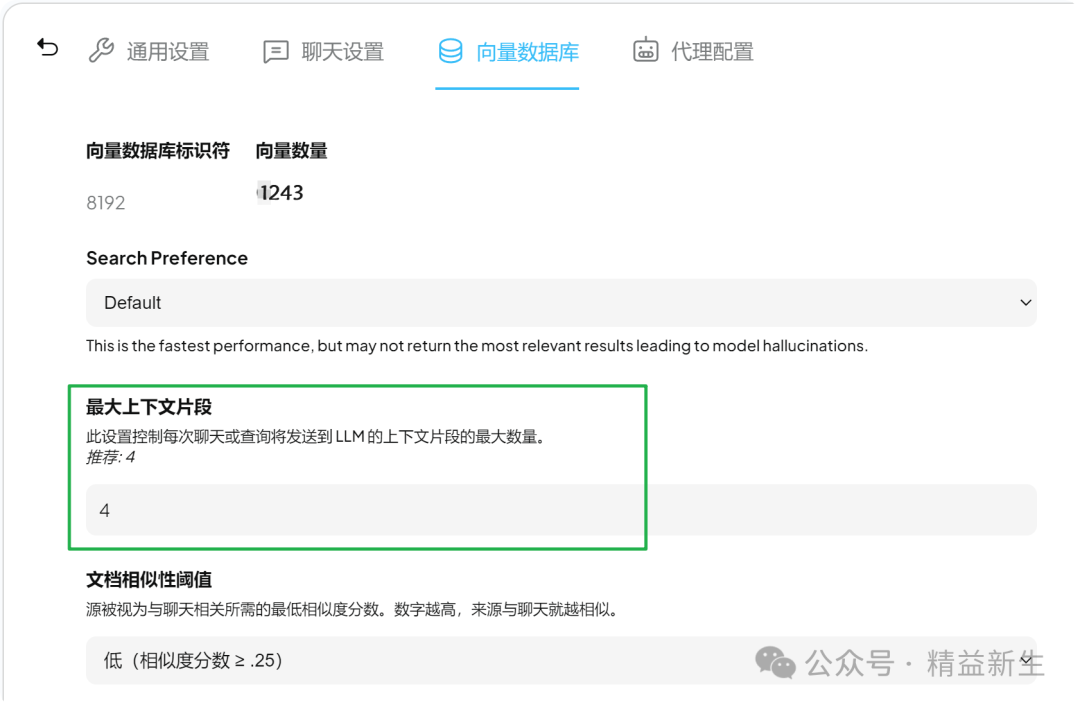
3 TopK检索召回:
TopK,即每次检索从所有的向量片段中返回多少个与Query最相似的片段,在AnythingLLM中,该值是基于工作区设置的,在工作区-点齿轮-向量数据库-可以看到默认和推荐的值是4.
在一些其他平台的配置中,有一个推荐区间,比如3-20.
是不是找到的片段越多就越好呢?不是的:
-
TopK 值过大,会增加计算成本、引入噪声干扰、稀释关键信息
-
TopK过小,信息不完整,性能受限。
对于一些常见的问题,5-10 个片段可能就足以提供足够的信息来生成一个较为准确和完整的回答。
这里,就回应上一篇文章中提到的误区:
- RAG是“若水三千,只取K瓢”,尽量不要让RAG干依赖于完整知识文档才能做对的事儿,比如“数字数”。
4 LLM 大模型首选项
LLM提供商,在AnythingLLM中可以任意设置,既可以调用API,也可以调用本地部署的。
在部署本地LLM后,Max Tokens依然要根据模型本身的能力上限来设置。例如:
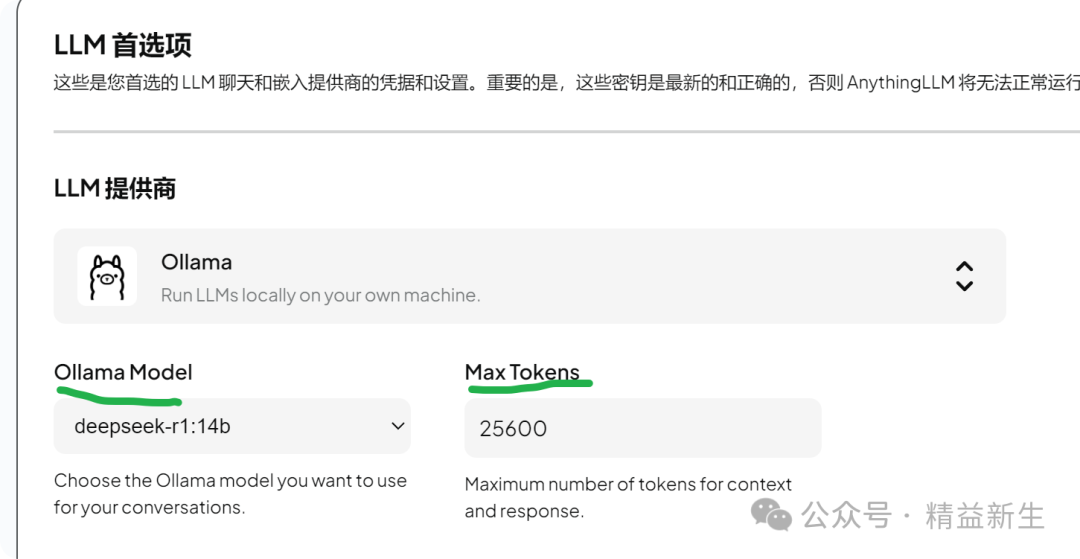
如何查看所部署模型的具体Max Context Tokens 呢?
依然是通过Ollama网站-模型搜索-查看models参数:
例如:DeepSeek-R1-Distill-Qwen-14B qwen2.context_length =131072, 即传说的128K。

减少“幻觉”的设定技巧
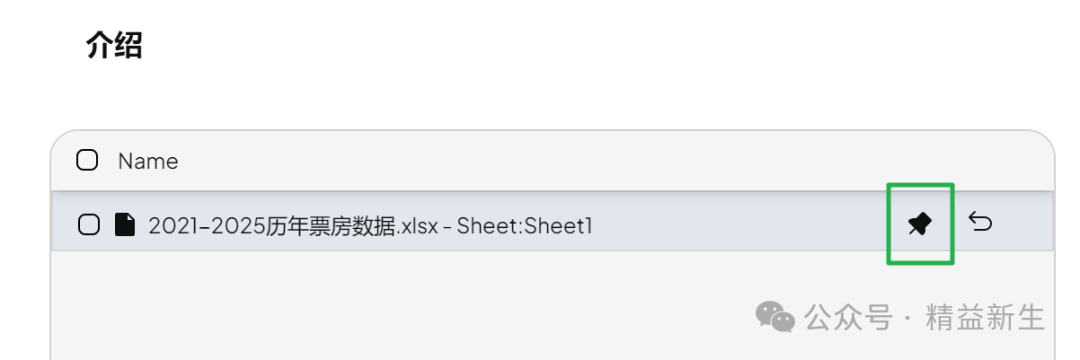
使用AnythingLLM后,技巧有3个:
-
文档Save& Embed后,点击“pin”。
-
在工作区-小齿轮-聊天设置中,切换“聊天”为“查询”

-
在对话的问题中:仍然加上“请严格根据上下文回答……或,请部分适当引用原文回答”。
总结
作为使用者,非RAG开发从业者,了解了基本的“本地知识库RAG检索增强生成”的流程和原理,可以更好的面对“能”与“不能”。

下面是一张经典的网络公开搜索获得的原理图,供大家参考学习。
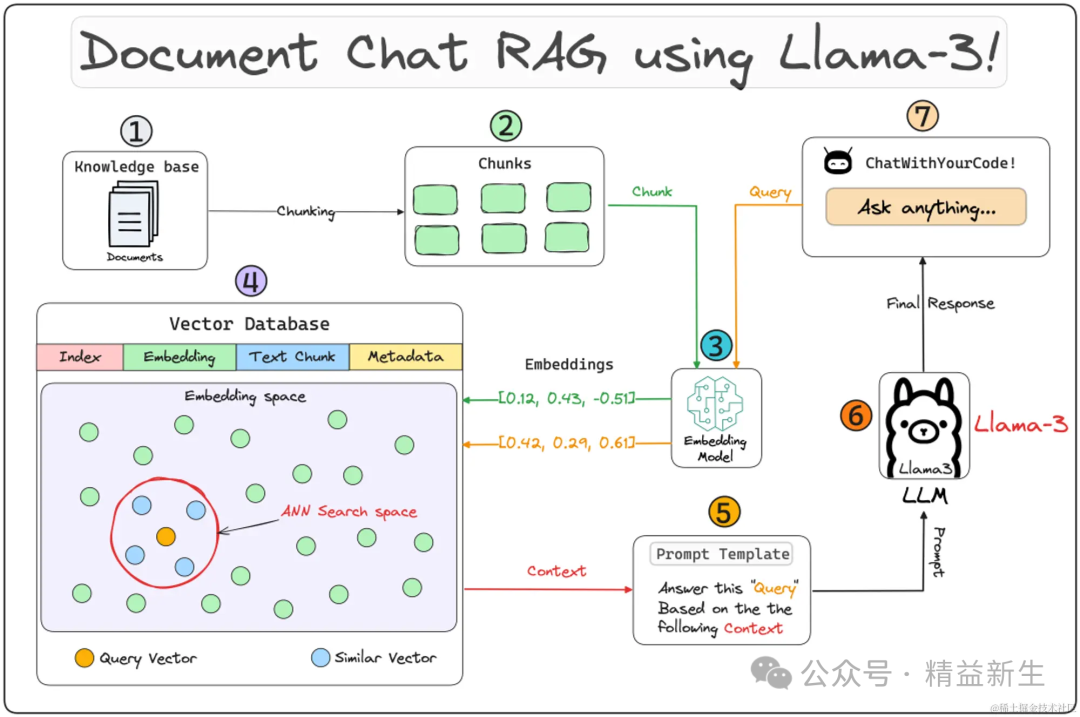
AnythingLLM你用的还爽吗?还遇到其他什么问题呢?你有更好的本地知识库方案吗?
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









