






在人工智能技术飞速发展的今天,大型语言模型(LLM)已经成为推动技术进步的核心力量。国内很多公司也纷纷入局,推出了各类大模型,比如 DeepSeek 大模型。
如今,像 DeepSeek 、ChatGPT 这样的 LLM 已经展现出令人惊叹的能力:从流畅自然的对话,到复杂的代码(视频)生成,这些模型正在重塑人机交互的方式,重塑数字化生产力。然而,大多数开发者只是在用 API 调用这些模型,对于它们的内部工作机制却知之甚少。
这时,Sebastian Raschka 所著的《从零构建大模型》恰好填补了这一空白。不同于市面上多数只教“怎么用”的书,这本书不满足于教读者使用现成的大模型,而是深入本质,带领读者从零开始构建自己的语言模型,真正手把手教你“搓”一个大模型(当然,我们“手搓”的不是 DeepSeek 这种超大模型)。

五一假期我刚读完!今天,就和大家聊聊这本大神之作——《从零构建大模型》。目前这本书已经在各大平台上架!
这本《从零构建大模型》已整理并打包好PDF了

目录结构
先带大家看一下本书的整体内容:

全书共分为 7 个章节,内容结构循序渐进。作者通过这 7 个精心设计的章节,从理论到实践,系统性地引导读者逐步构建自己的大语言模型。整个知识体系脉络清晰,既有技术深度,又有实战指导。
理论与实践
按照作者的思路,学习这本书可以分为三个大的阶段:
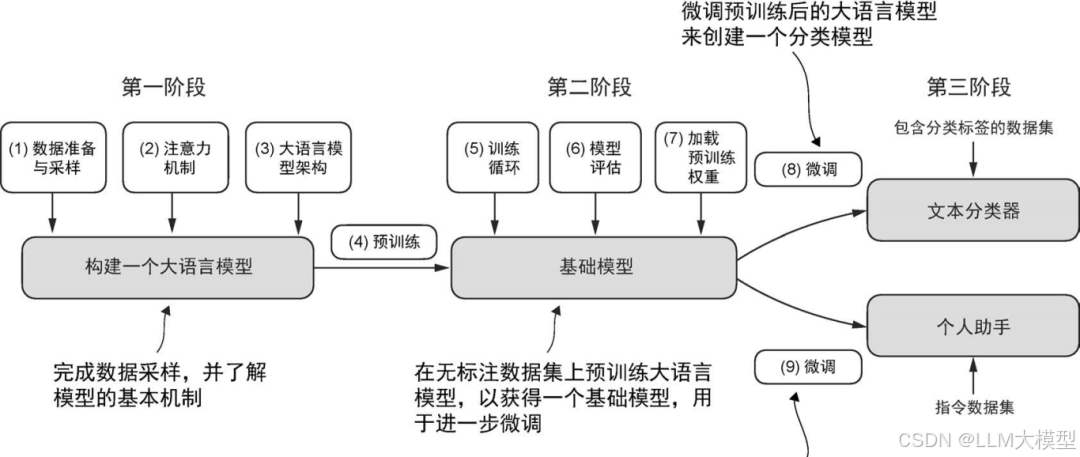
如果从各个章节的内容上来了解本书,根据本人的学习,我总结为以下内容:
第 1 章:理解大语言模型——基础
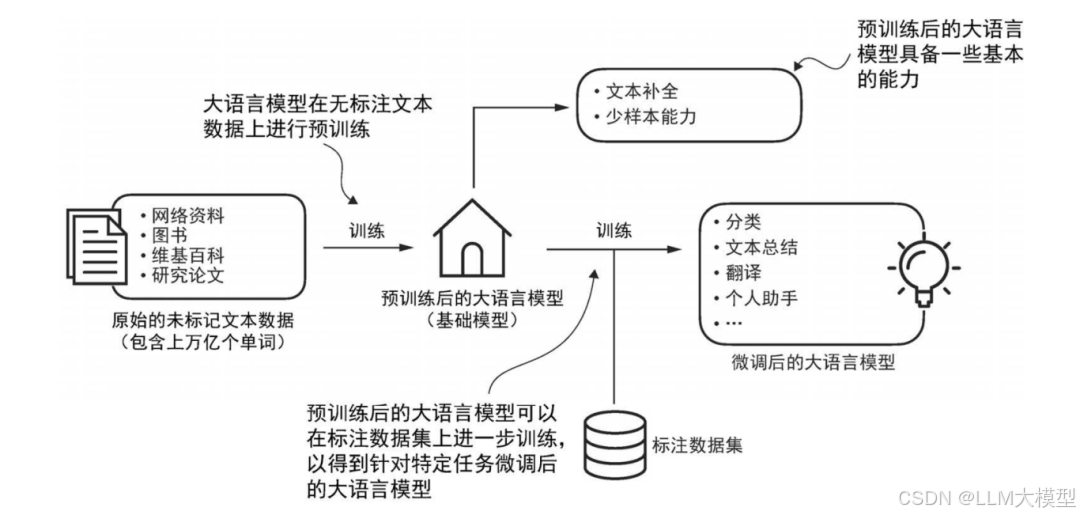
本章奠定了全书的理论基础。不同于一些技术书一上来就写“怎么实现”,作者首先从宏观角度梳理了语言模型的发展历程:从早期的统计语言模型到 Transformer 带来的革命性突破。这种历史脉络的介绍,能帮助读者理解每一代技术解决的核心问题及其局限性,建立对技术演进的整体认识。
比如对预训练技术,作者用一张图就详细讲清了原理:
第 2 章:处理文本数据 —— 模型的“原材料”
高质量的数据处理是训练大模型的前提条件。本章重点讲解了Byte Pair Encoding(BPE)算法——这也是 GPT 系列模型采用的主流 token 化方法。作者通过逐步拆解 BPE 的工作流程,用深入浅出的方式帮助读者理解这个看似简单、实则极其强大的算法。
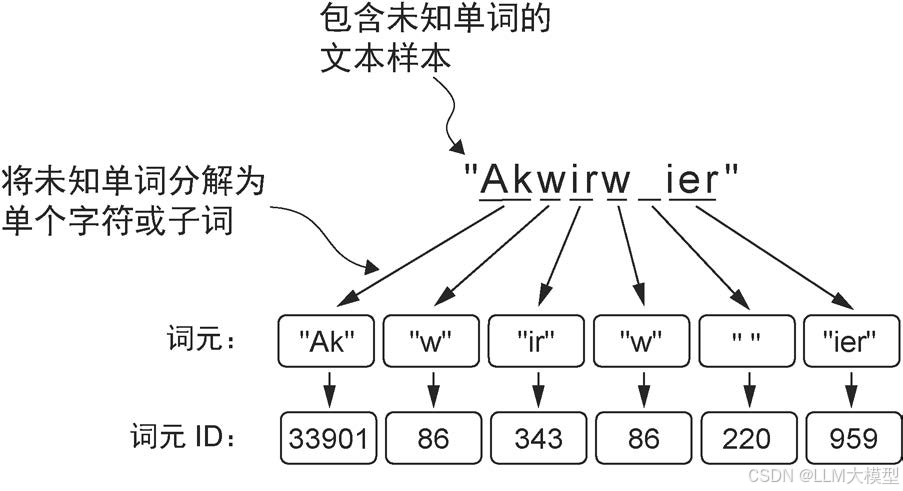
BPE 分词器会将未知单词分解为子词和单个字符。如此一来,BPE 分词器便可以解析 任何单词,而无须使用特殊词元(如<|unk|>)来替换未知单词
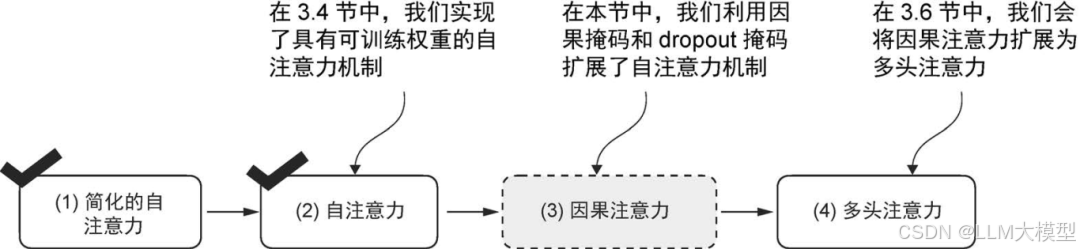
第 3 章:编码注意力机制 —— 核心 Transformer
自注意力机制是当今大模型的核心技术。作者采用独特的“三步教学法”:先讲解基本的注意力概念,再引入缩放点积注意力,最后扩展到多头注意力。这样的分层讲解,让复杂的概念也能慢慢消化、逐步掌握。
第 4 章:从头实现 GPT 模型进行文本生成 —— 理论与实践的结合
这一章是全书的“核心实践章节”。作者把前几章学到的“零件”拼装成一个完整的 GPT 模型。通过设计一个小参数量的“微型 GPT”,作者带领读者完整体验 GPT 模型的实现过程,从前馈网络到最终实现文本生成。学习完这一章后,我对如何搭建一个能生成连贯文本的模型已经有了较清晰的理解。
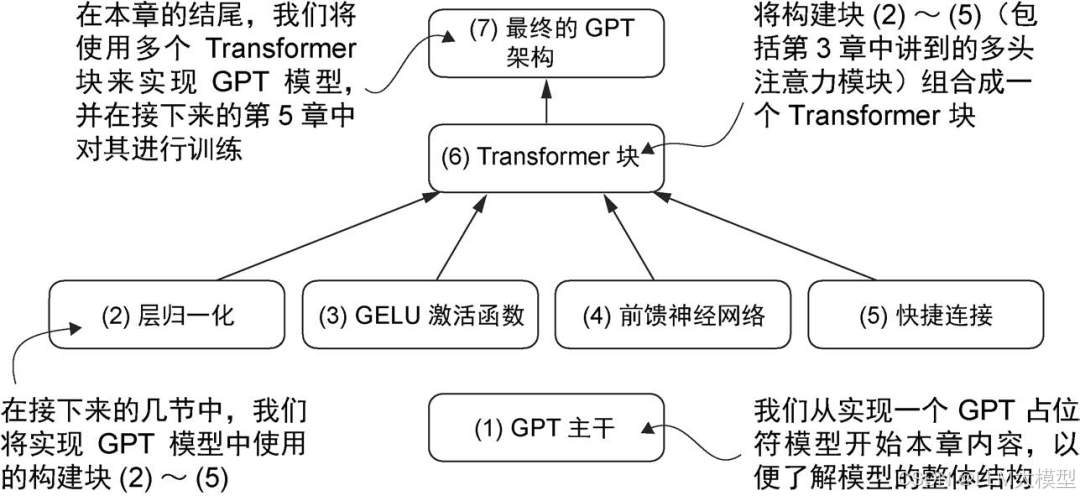
我们编写GPT架构的步骤是:首先从GPT主干入手,创建一个占位符架构;然后实现各 个核心组件;最后将它们组装成 Transformer 块,形成完整的 GPT 架构
第 5 章:在无标签数据上进行预训练 —— 释放大模型潜力
自监督学习是当前大模型发展的重要方向。它能让模型从海量文本中自动“提取知识”,在处理互联网海量数据时极具优势。本章详细介绍了如何利用无标签数据进行自监督预训练,帮助模型积累“通用能力”。
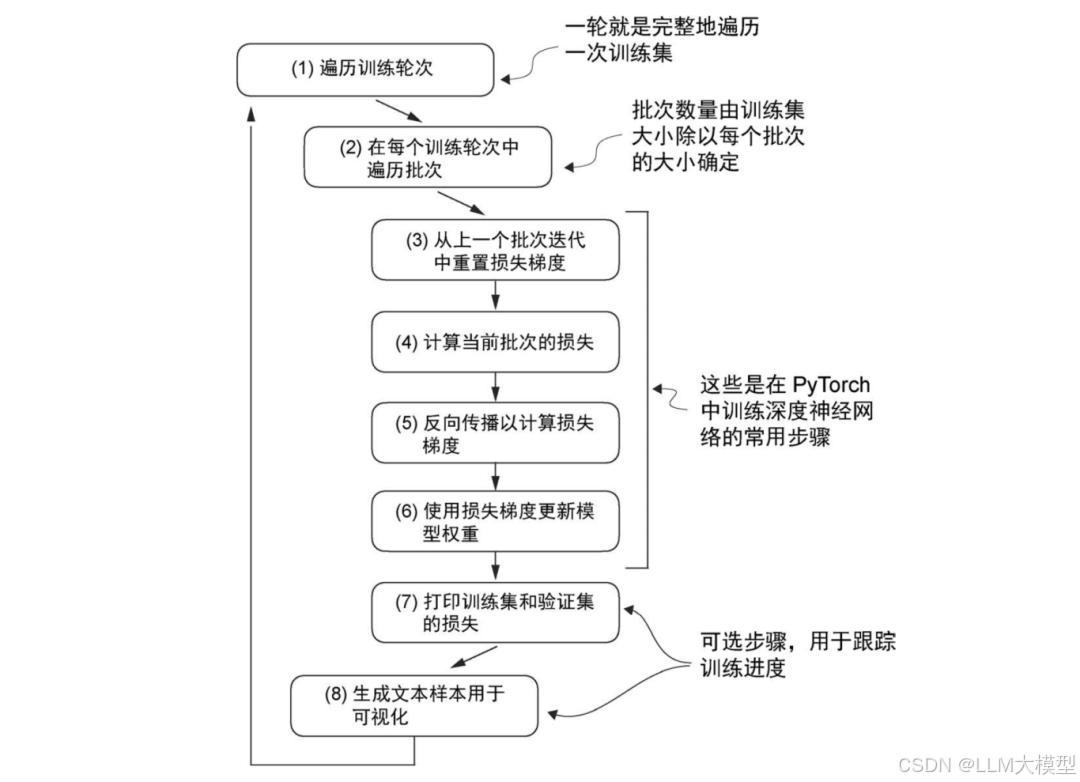
在 PyTorch 中训练深度神经网络的典型训练循环包括多个步骤,涉及对训练集中的批次 进行多轮迭代。
第 6 章:针对分类的微调——落地应用
微调是把预训练模型“适配”到具体应用场景的重要步骤。不同于直接使用预训练模型,微调能显著提升模型在特定任务(如情感分析、主题分类)上的效果。
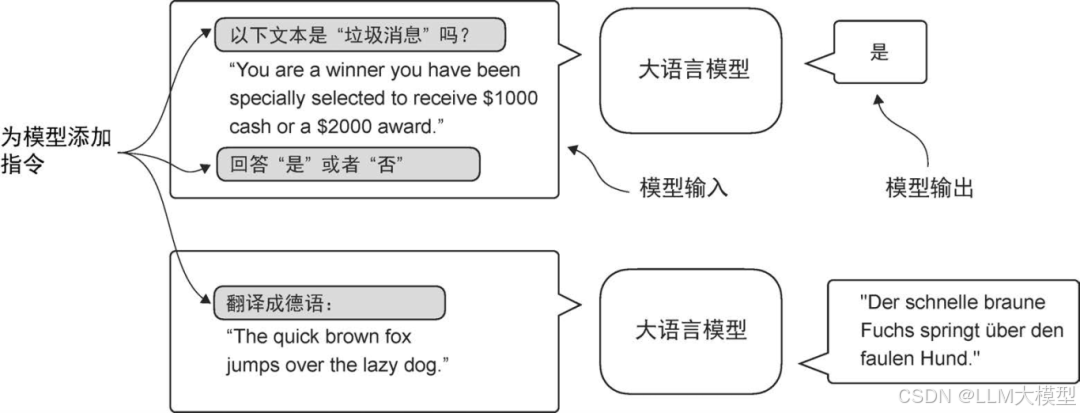
第 7 章:通过微调遵循人类指令——贴合人类意图
最后一章讨论了如何让大模型的行为更符合人类意图。本章介绍了 Instruction Fine-tuning(指令微调)的基本概念,即用“指令-正确响应”对的数据进一步调整模型。作者还通过实验分析了“单轮指令”和“多轮对话微调”的不同效果,为未来实际应用奠定基础。
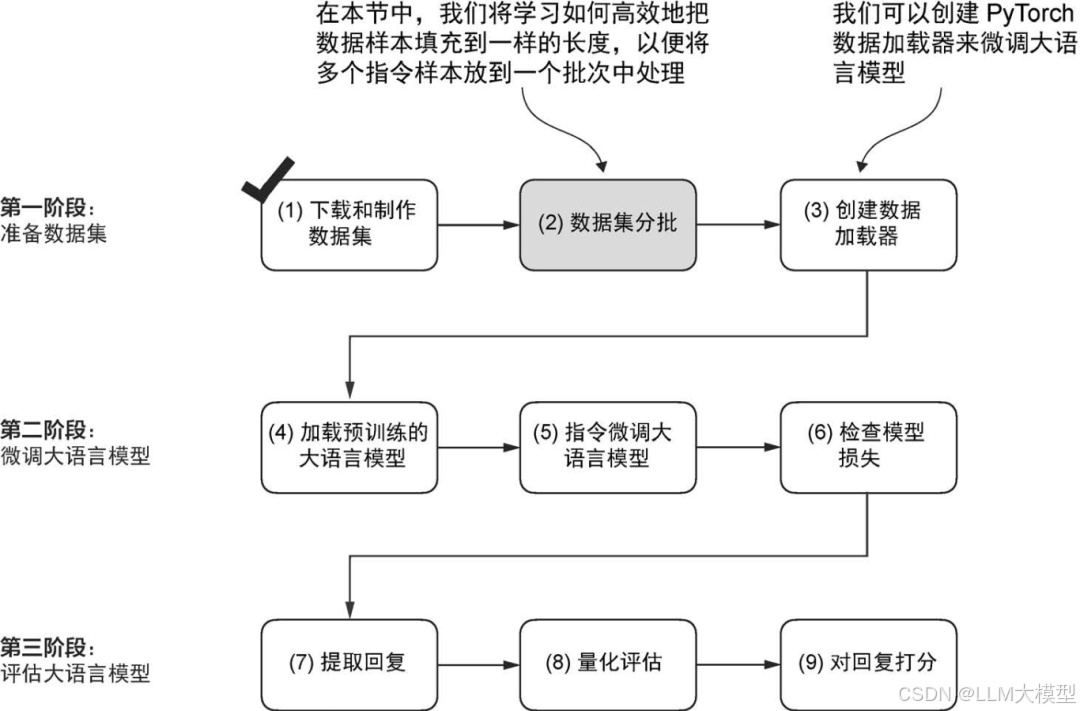
对大语言模型进行指令微调的三个阶段过程
综上来看,这本书的“含金量”是不是已经让你感受到它的强大?
本书特点
章节赏析我这里就不赘述了,接下来我从个人角度聊聊这本书的几个特点,方便大家作为参考:
1内容详实、结构科学
一本值得反复学习和翻阅的技术书,关键就在于内容的“耐看”。本书贯穿“解释-实现-实验”循环,每个概念先有理论解释,再有代码实现,再有实验效果。这样的螺旋式结构大大提升了学习效率,让人忍不住一遍遍翻看、动手实践。
2代码质量高、风格优秀
书中的代码非常注重可读性和可扩展性,避免了那种“聪明但晦涩”的代码风格。比如第 2 章的文本分词器,代码不仅清晰易懂,而且代码风格值得学习:

3作者背景强、经验丰富

作者塞巴斯蒂安·拉施卡(Sebastian Raschka)是威斯康星大学麦迪逊分校的统计学副教授,专注于机器学习与深度学习研究,拥有密歇根州立大学博士学位,在计算生物学领域有多项成果。他还被 Analytics Vidhya 评为 GitHub 上最具影响力的数据科学家之一。你可能知道,他还是《大模型技术30讲》、《Python 机器学习》《Machine Learning with PyTorch and Scikit-Learn》的作者。
总的来说,这本书最大的特点是它的“循序渐进”和“手把手教学”。从基础概念到完整实现,从数据处理到模型微调,每个阶段都有详细讲解、示意图、代码示例。特别值得一提的是:书中构建的模型可以在普通消费级设备上运行,极大降低了学习门槛,让更多开发者有机会完整体验一次“大模型”开发的全流程。
适用读者
本书深入剖析了大语言模型的技术特点,面向有志于学习大模型开发的读者,主要适合以下几类人群:
1 AI / 机器学习初学者
非常适合希望从零开始学习大模型技术的初学者,尤其是没有深度学习背景、但具备一定 Python 编程基础的学习者。作者提供了可运行的代码和清晰的示意图,非常友好。
2希望深入理解 LLM 原理的开发者
适合已经有一定机器学习基础、希望深入了解文本处理流程、Transformer 架构、注意力机制、预训练与微调等技术的开发者。通过 PyTorch 从底层实现,而不是直接用高级库,适合想掌握“底层原理”的人。
3实战型工程师
从事文本或大模型相关工作的工程师,也很适合阅读本书。书中包含 ChatGLM、BERT、GPT 等模型的部署、微调等实践内容,可以快速迁移到自己的业务中,具有很高的参考价值。
4LLM 兴趣爱好者
对 LLM 理论感兴趣的研究者,也很适合本书。书中涵盖从数据预处理到模型优化的完整流程,还涉及强化学习、多模态模型等进阶话题,特别适合想“从零开始”构建、优化、应用大模型的读者。
这本《从零构建大模型》已整理并打包好PDF了

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









