



摘要
玉米作为全球广泛种植的重要农作物,在保障粮食安全和推动农业经济发展方面意义重大。然而,玉米病害严重威胁作物生长、影响产量,进而危及粮食供应。本文基于 YOLOv8 深度学习框架,利用 3852 张图片训练出可识别 4 种玉米叶片病害类型的模型,并借助 Python 与 PyQT5 开发了带 UI 界面的玉米叶片病害智能诊断与防治系统。该系统能够快速、精准地识别实时场景中的病害类型,还能提供科学防治建议,有助于农户及时防控病害,提升农业生产效率与可持续性。系统支持图片、批量图片、视频和摄像头检测,文中提供了完整 Python 代码与使用教程,代码资源文件获取方式详见文末。该系统有望为玉米病害防治提供有效技术支持,助力农业智能化发展。
功能介绍
-
病害识别:能够精准识别 4 种玉米叶片病害类型,即锈病、灰叶斑病、健康状态、枯叶病。
-
防治建议:针对不同的病害类型,系统支持用户自行添加对应的防治方法与建议,方便用户根据实际情况制定防治策略。
-
检测方式:支持通过图片、批量图片、视频以及摄像头进行检测,满足多种场景下对玉米叶片病害的检测需求。
-
界面展示:系统界面实时显示识别结果、置信度、用时等信息,方便用户及时了解检测情况 。
开发环境
-
后端: Python 3.9
-
前端: Pyqt5
-
数据集:网络搜集
-
算法:YOLOv8
-
开发平台:Pycharm + vscode
-
运行环境:Windows 10/11
界面展示
初始界面
检测结果
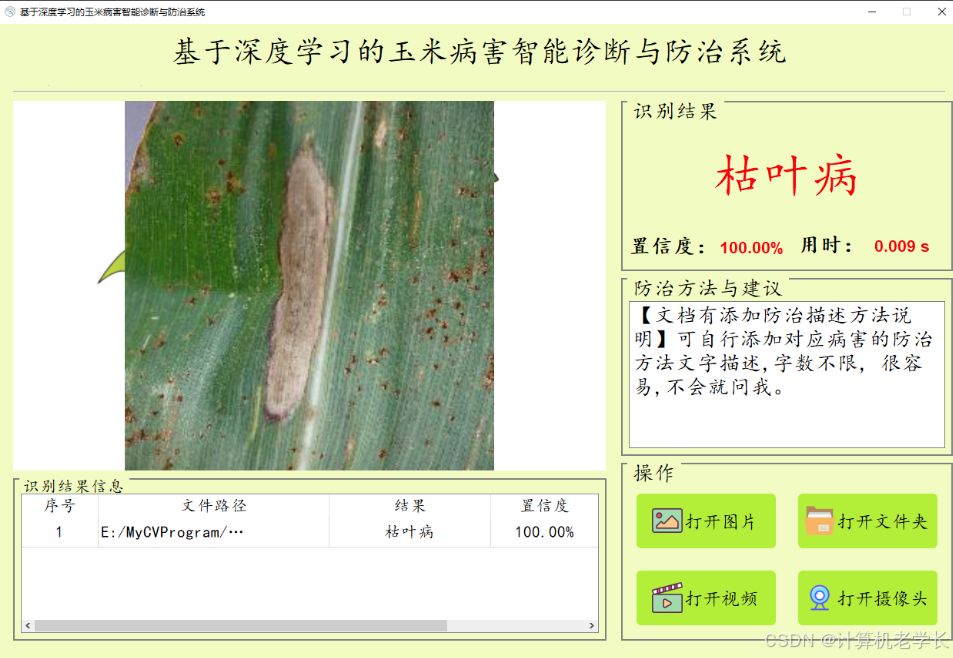
模型的训练、评估与推理
YOLOv8简介
在计算机视觉领域,物体识别至关重要且复杂,应用于安防、自动驾驶等多个方面。物体定位要在图像或视频里找到物体、分类并给出边界框和名称,主要有两阶段和一阶段这两种方法。
两阶段方法,比如 R - CNN 系列,先生成区域建议,再用分类器和回归器细化。单阶段方法像 SSD、YOLO 等,直接预测边界框和物体名称,速度快、更简单,但准确性和稳健性稍弱。
YOLO 是重要的单阶段检测算法,把输入图像分成单元格网络,预测边界框、确定性分数及类别概率来得出检测结果。它检测大中型物体速度快,但有定位粗糙、小物体检测效果差等问题。
自 YOLO 问世,出现了 YOLOv2 到 YOLOv7 等改进版本。它们融入锚框、多尺度预测等技术,提升了 YOLO 的精度、稳定性和效率。不过,在小物体、遮挡物体及复杂背景场景下仍有提升空间。
本文介绍的 YOLOv8,基于以往 YOLO 版本,融入新特性与改进,追求物体定位的高速度、高精度,同时保证稳定性和稳健性。
技术改进
-
注意力机制:运用 ECA、GAM 等,让模型更好聚焦图像关键信息,提升检测精度。
-
卷积层优化:采用可变形卷积、动态卷积,增强模型对不同形状和大小目标的适应能力。
-
主干网络改进:选用 MobileNetV4 等轻量化结构,减少计算量,加快检测速度。
-
特征融合模块:引入 BiFPN、AFPN 等,提高对多尺度目标的检测能力。
-
检测头改进:借助 RT - DETR 技术,改善不同尺寸目标的检测效果。
-
损失函数和 IoU 优化:改进损失函数与 IoU 计算方法,提升回归精度与检测性能。
-
NMS 和其他模块改进:优化非极大值抑制(NMS)等模块,提高检测准确性与效率。
-
轻量化设计:注重轻量化,采用 VanillaNet 等架构,适配资源受限设备。
-
多尺度检测能力:利用 SPD - Conv 技术,增强对小目标和多尺度目标的检测。
-
优化器改进:可能采用 Lion 等新优化器,提升训练效率与模型性能。
算法概述
YOLOv8 是 YOLO 系列目标检测模型的最新成果,基于以速度和性能著称的 YOLO9000 发展而来。YOLOv3 和 YOLOv4 的改进,推动了模型在复杂环境下检测速度与精度的提升。
网络体系结构
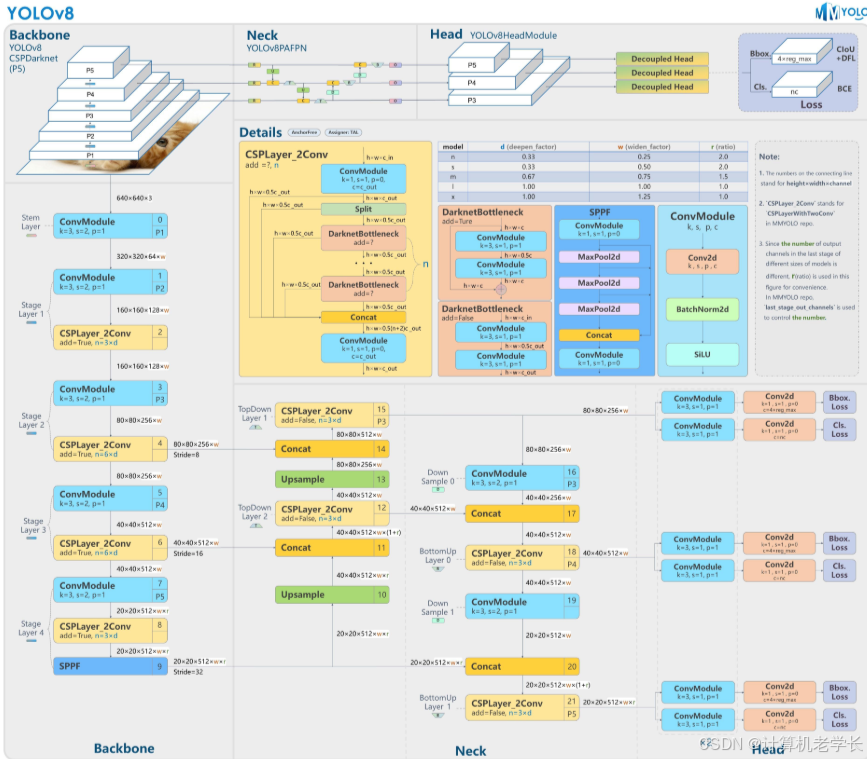
YOLOv8 主要由骨干网络和检测头构成。
-
骨干网:
-
基于 EfficientNet:源于以复合扩展思想设计的 EfficientNet,该架构通过平衡扩展网络宽度、深度和分辨率提升性能。以 EfficientNet - b0 为基础网络(29 层卷积神经网络,含挤压和激励模块的改进残差块),经复合缩放系数生成多种变体。YOLOv8 选用 EfficientNet - B4(71 层,1900 万个参数),能在速度与精度间平衡,提取多尺度特征。输入 512×512 像素图片,骨干网输出 5 个不同分辨率和维度特征图(P3 - P7,P3 分辨率最高),用于后续处理。
-
-
增强版 CSPDarknet:将 CSP 网络融入 Darknet 架构,每个阶段特征图分两部分,一部分经密集卷积块处理后与另一部分直接拼接,降低计算复杂度同时保持准确性,由多个含分割、密集块、过渡层和拼接操作的 CSP 块组成。
-
-
Neck:采用 PANet Neck 网络,在 FPN 基础上增加自底向上路径,涵盖自底向上特征提取、自顶向下语义特征传播及额外自底向上路径,改善网络层间信息流与特征融合。
-
检测头:
-
Anchor - Free 点检测 Head:区别于传统依赖预定义 Anchor 框的 YOLO 模型,简化架构、减少计算开销,加快推理,提升检测小型和密集物体能力。
-
基于 NAS - FPN:一种自动生成特征金字塔网络的神经架构搜索方法,用强化学习找最优特征融合技术(含元素运算、池化和连接等操作)。YOLOv8 以 NAS - FPN - Cell(六层 256 通道子网)为检测头,融合 5 个骨干网特征图,输出 5 个同维度特征图(P3' - P7',P3' 比例尺最小),用于生成边界框预测。
-
预测与锚盒:类似 YOLOv3,为每个特征图预测 3 个边界框和置信度分数,每张图片共 15 个。预测边界框类概率并结合置信度得最终结果。使用 9 个经 k - means 聚类确定的锚盒提高精度,按尺度分配到不同特征图。
-
激活函数:使用 SiLU 替代 Leaky ReLU,改善梯度流动、增强特征表现力,降低计算复杂度、减少模型大小,利于边缘部署。
-
新功能和增强
-
增强后处理:改进非最大值抑制(NMS)算法,优化重叠边界框处理和检测选择,减少假阳性,提高检测精确度。
-
训练技术:
-
混合精度训练:结合 16 位和 32 位浮点运算,加快训练、减少内存使用,不影响模型精度,适合边缘设备。
-
超参数优化:自动调整超参数,通过多组实验选最优配置,节省时间,确保模型在不同任务和数据集表现良好。
-
-
新增损失函数:采用 Focal loss,聚焦困难样本,降低简单样本影响,通过调节因子和缩放因子,提高不平衡和噪声数据集检测召回率与精度,减少假阳性和假阴性。
-
新的数据增强方法:运用 Mixup,混合两张图像及其标签生成新数据,提升数据多样性和复杂性,减少过拟合,增强模型泛化能力,扩展至目标检测处理边界框和多类别。
-
新的评价指标:引入跨尺度平均精度 (APAS),衡量不同尺度物体检测精度,是标准平均精度 (AP) 扩展,考虑目标尺度变化,计算不同尺度范围 AP 并平均得最终分数,更全面反映算法在不同大小和形状物体上的性能。
-
其他:
-
C2f 构建块:增强特征提取与融合,提升模型捕获细节和复杂模式能力,提高检测准确性。
-
统一框架:为目标检测、实例分割和姿态估计等多种计算机视觉任务提供统一框架,适用于需多种分析的边缘应用。
-
导出选项:支持导出为 ONNX、CoreML 和 TensorRT 等多种格式,便于在不同平台和硬件加速器部署。
-
模型分析
本文将所提策略与过往 YOLO 变体及其他先进目标检测策略对比,借助 COCO、PASCAL VOC 和 WIDER FACE 等基准数据集,在不同度量标准和场景下评估该策略的性能与效能。
数据集
训练和测试 YOLOv8 模型使用了以下数据集:
-
COCO:这是用于对象检测、分割及图像字幕的大规模数据集,包含 80 个类别和超 20 万张图像,其中 11.8 万张用于训练,5000 张用于验证,40500 张用于测试。该数据集极具挑战性且丰富多样,涵盖广泛的物体大小、形状及类别。因其在目标检测领域的高知名度与广泛应用,成为评估方法的主要数据集。
-
PASCAL VOC:经典的对象检测与分类数据集,有 20 个类别和超 1.1 万张图像,5000 张用于训练和验证,6000 张用于测试。它相对简单且均衡,涵盖常见对象类别,难度适中。作为成熟且广泛使用的目标检测数据集,可作为与其他策略对比的补充数据集。
-
WIDER FACE:大规模人脸检测数据集,含超 3.2 万张图像和 39.3 万张人脸,12800 张用于训练,3200 张用于验证,16000 张用于测试。该数据集颇具挑战性与复杂性,涵盖各种面部尺度、姿势、表情、遮挡及光照情况。用于展示方法在人脸检测这一重要实际任务中的性能。
指标
通过以下指标衡量 YOLOv8 模型的性能与效率:
-
跨尺度平均精度 (APAS):用于衡量不同尺度物体的检测精度,是标准平均精度 (AP) 的扩展。APAS 考虑物体尺度变化,计算小、中、大不同尺度范围的 AP,再对这些 AP 求平均得出最终分数,能全面反映算法在不同物体大小和形状下的性能。作为 COCO 数据集的官方指标,是评估 COCO 数据集上策略的常用指标。
-
平均精度 (Mean Average Precision, mAP):衡量不同类别物体检测的平均精度,通过对每个对象类的 AP 求平均得到最终分数。它简单且应用广泛,能反映算法在不同对象类别上的性能。作为 PASCAL VOC 数据集的官方指标,用于在该数据集上与其他方法对比的补充度量。
-
平均 IoU (AIoU):衡量边界框预测的平均质量,计算方法是对每个边界框预测的交并比 (Intersection over Union, IoU) 分数取平均得出最终分数。IoU 用于衡量预测边界框与真实边界框的重叠程度,范围从 0 到 1,0 表示无重叠,1 表示完全重叠。AIoU 能反映算法在目标定位方面的性能,是 WIDER FACE 数据集的官方度量,用于评估该数据集上的方法。
-
帧数每秒 (FPS):衡量目标定位算法速度,通过算法处理的帧数除以总耗时得出最终分数。在目标检测尤其是实时应用中,FPS 是反映算法有效性和通用性的重要实用指标,用于衡量所有数据集上方法的速度并与其他方法对比。
Coco 数据集上的结果
在 COCO 数据集的官方 train2017、val2017 和 test - dev2017 分割上训练和测试 YOLOv8 模型。依据官方评估协议,使用 APAS 指标评估方法,并通过单个 NVIDIA RTX 3090 GPU,以 FPS 指标衡量方法在 COCO 数据集上的速度。
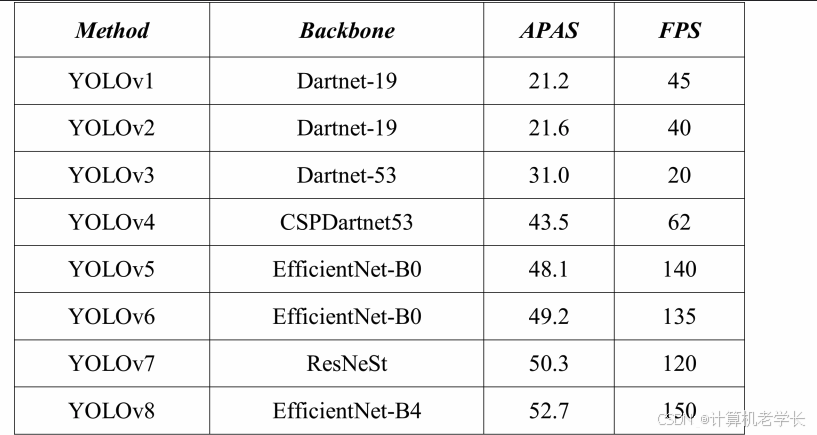
结果显示,YOLOv8 模型在所有方法中表现最佳,APAS 得分达 52.7,相比之前最佳方法 YOLOv7 提高 2.4 分;同时速度也最优,FPS 为 150,比之前最佳方法 YOLOv5 快 10 帧。这表明 YOLOv8 模型在 COCO 数据集上实现了目标检测速度与精度的最佳平衡,在这两个指标上均超越现有方法。
数据集准备与训练
数据准备
通过网络上搜集关于水稻害虫的各类图片,并使用LabelMe标注工具对每张图片中的目标边框(Bounding Box)及类别进行标注。一共包含1248张图片,其中训练集包含1060张图片,验证集包含188张图片,部分图像及标注如下图所示。


模型训练
图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入Data目录下。
同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
train: E:\MyCVProgram\RiceInsectDetection\datasets\RiceInsectData\train
val: E:\MyCVProgram\RiceInsectDetection\datasets\RiceInsectData\val
nc: 14
names: ['rice leaf roller', 'rice leaf caterpillar', 'paddy stem maggot', 'asiatic rice borer', 'yellow rice borer', 'rice gall midge', 'Rice Stemfly', 'brown plant hopper', 'white backed plant hopper', 'small brown plant hopper', 'rice water weevil', 'rice leafhopper', 'grain spreader thrips', 'rice shell pest']
注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
# 加载模型
model = YOLO("yolov8n.pt") # 加载预训练模型
# Use the model
if __name__ == '__main__':
# Use the model
results = model.train(data='datasets/RiceInsectData/data.yaml', epochs=250, batch=4) # 训练模型
# 将模型转为onnx格式
# success = model.export(format='onnx')
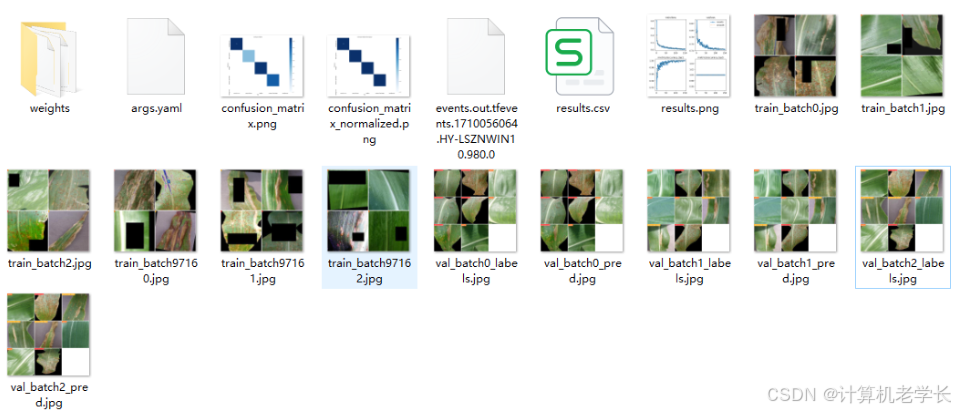
训练结果
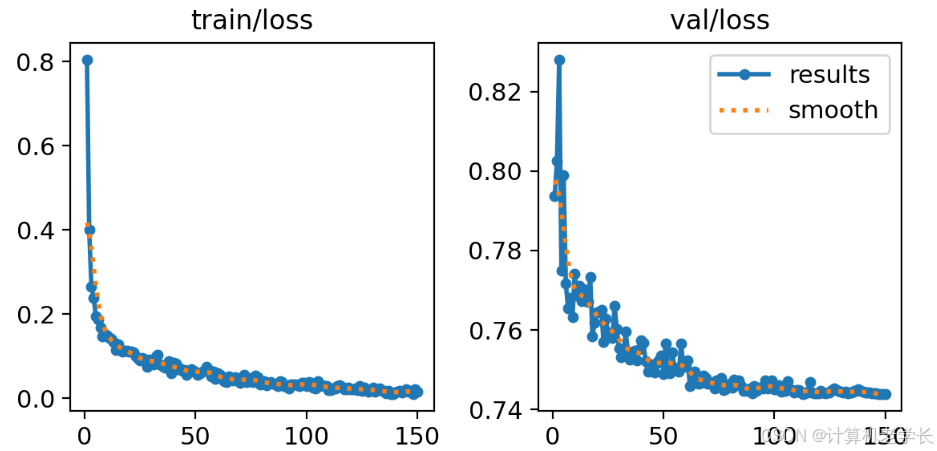
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss),在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:
损失函数
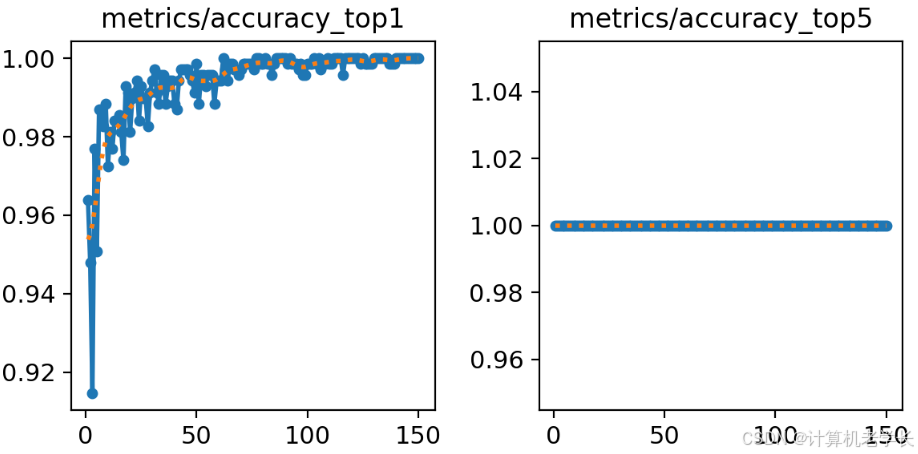
通过图片准确率曲线图我们可以发现,该模型在验证集的准确率约为0.99,结果还是很不错的。
模型推理
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/train/weights目录下。我们可以使用该文件进行后续的推理检测。
图片检测代码如下:
#coding:utf-8
from ultralytics import YOLO
import cv2
# 所需加载的模型目录
path = 'models/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/RS_Rust 1598.JPG"
# 加载模型
model = YOLO(path, task='classify')
# 检测图片
results = model(img_path)
print(results)
res = results[0].plot()
# res = cv2.resize(res,dsize=None,fx=0.3,fy=0.3,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)
执行上述代码后,会将执行的结果直接标注在图片上,结果如下:

开源代码
链接: https://pan.baidu.com/s/1-3maTK6vTHw-v_HZ8swqpw?pwd=yi4b
提取码: yi4b


















 1564
1564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









