







使用yolo11进行车辆检测与追踪
😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁
配套视频地址:手把手教你使用YOLO11实现车辆检测与追踪系统_哔哩哔哩_bilibili
手把手教你使用YOLO11训练自己的检测追踪数据集
😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁
Ultralytics与2024年10月1日发布了yolo11,根据官方的说明,yolo11带来了更高的精度和更快的速度,并且同样支持分类、检测、分割、关键点检测等一系列任务。所以本期,我们以车辆检测、追踪和计数为主题,使用yolo11训练一个精度足够好的车辆检测模型,之后使用BoT-SORT和ByteTrack完成追踪和计数的任务。
原理解析
计算机视觉是一个快速发展的领域,它使机器能够解释和理解视觉数据。该领域的一个关键方面是目标检测[2],它涉及到图像或视频流[3]中目标的精确识别和定位。近年来,应对这一挑战的算法方法取得了显著进展。2015年,Redmon等人引入了You Only Look Once (YOLO)算法,这是目标检测领域的一个关键突破。这种创新的方法,顾名思义,在一次通道中处理整个图像,以检测物体及其位置。YOLO的方法与传统的两阶段检测过程不同,它将目标检测作为一个回归问题。它采用单个卷积神经网络同时预测整个图像的边界框和分类概率,与更复杂的传统方法相比,简化了检测流程。
下表说明了YOLO模型从初始到最新版本的发展过程。每次迭代都在目标检测能力、计算效率和处理各种CV任务的通用性方面带来了重大改进。
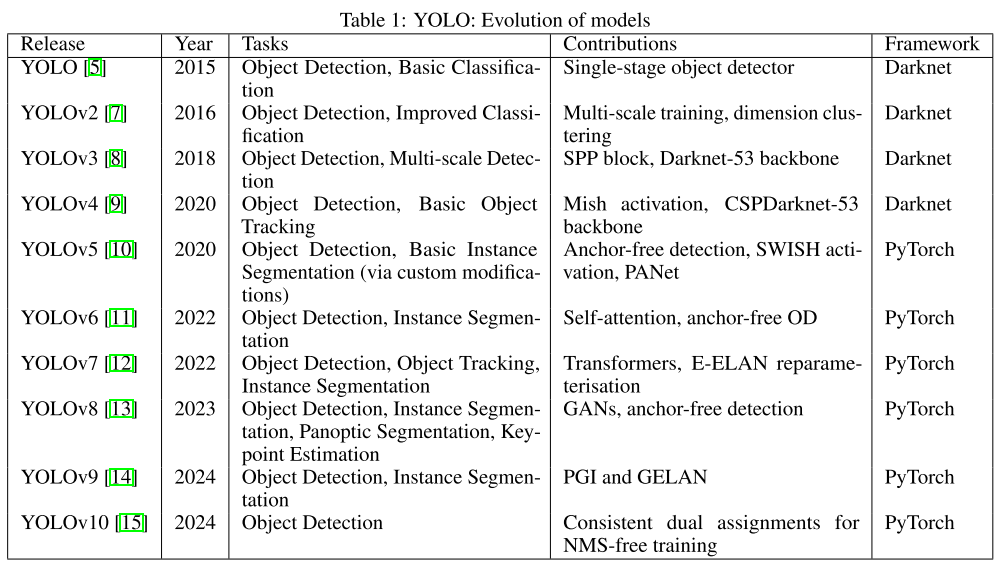
这种演变展示了目标检测技术的快速进步,每个版本都引入了新的功能并扩展了支持任务的范围。从最初的YOLO开创性的单阶段检测到YOLOv10的无nms训练,该系列一直在推动实时目标检测的界限。
最新的迭代版本YOLO11在此基础上进一步增强了特征提取、效率和多任务功能。我们随后的分析将深入研究YOLO11的架构创新,包括其改进的骨干和颈部结构,以及其在各种计算机视觉任务(如对象检测,实例分割和姿态估计)中的性能。
yolo11
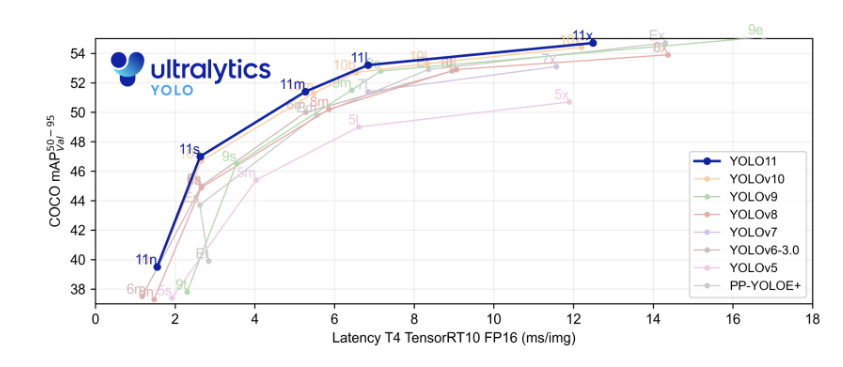
yolo系列已经在业界可谓是家喻户晓了,下面是yolo11放出的性能测试图,其中这种图的横轴为模型的速度,一般情况下模型的速度是通过调整卷积的深度和宽度来进行修改的,纵轴则表示模型的精度,可以看到在同样的速度下,11表现出更高的精度。
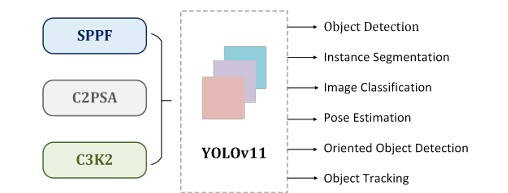
YOLO架构的核心由三个基本组件组成。首先,主干作为主要特征提取器,利用卷积神经网络将原始图像数据转换成多尺度特征图。其次,颈部组件作为中间处理阶段,使用专门的层来聚合和增强不同尺度的特征表示。第三,头部分量作为预测机制,根据精细化的特征映射生成目标定位和分类的最终输出。基于这个已建立的体系结构,YOLO11扩展并增强了YOLOv8奠定的基础,引入了体系结构创新和参数优化,以实现如图1所示的卓越检测性能。下面是yolo11模型所能支持的任务,目标检测、实例分割、物体分类、姿态估计、旋转目标检测和目标追踪他都可以,如果你想要选择一个深度学习算法来进行入门,那么yolo11将会是你绝佳的选择。
为了能够让大家对yolo11网络有比较清晰的理解,下面我将会对yolo11的结构进行拆解。
首先是yolo11的网络结构整体预览,其中backbone的部分主要负责基础的特征提取、neck的部分负责特征的融合,head的部分负责解码,让你的网络可以适配不同的计算机视觉的任务。
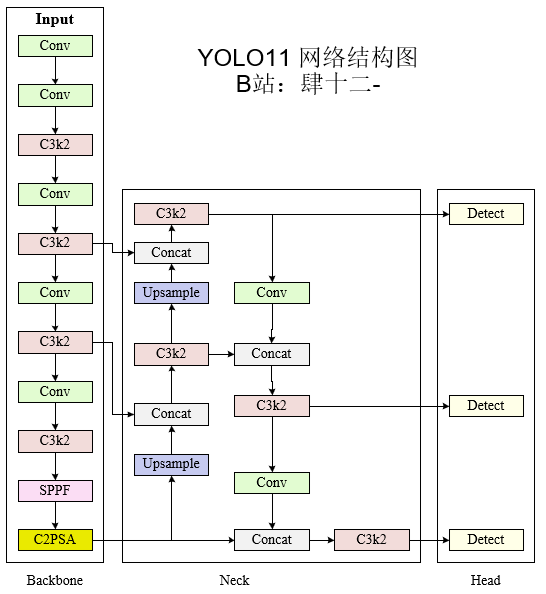
-
主干网络(BackBone)
-
Conv
卷积模块是一个常规的卷积模块,在yolo中使用的非常多,可以设计卷积的大小和步长,代码的详细实现如下:
class Conv(nn.Module): """Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation).""" default_act = nn.SiLU() # default activation def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True): """Initialize Conv layer with given arguments including activation.""" super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() def forward(self, x): """Apply convolution, batch normalization and activation to input tensor.""" return self.act(self.bn(self.conv(x))) def forward_fuse(self, x): """Perform transposed convolution of 2D data.""" return self.act(self.conv(x)) -
C3k2
C3k2块被放置在头部的几个通道中,用于处理不同深度的多尺度特征。他的优势有两个方面。一个方面是这个模块提供了更快的处理:与单个大卷积相比,使用两个较小的卷积可以减少计算开销,从而更快地提取特征。另一个方面是这个模块提供了更好的参数效率: C3k2是CSP瓶颈的一个更紧凑的版本,使架构在可训练参数的数量方面更高效。
C3k2模块主要是为了增加特征的多样性,其中这块模块是由C3k模块演变而来。它通过允许自定义内核大小提供了增强的灵活性。C3k的适应性对于从图像中提取更详细的特征特别有用,有助于提高检测精度。C3k模块的示意图如下。
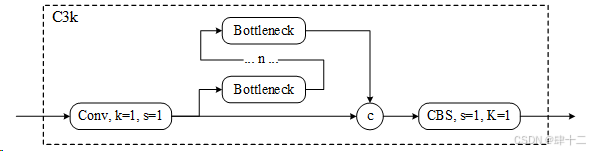
class C3k(C3): """C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks.""" def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3): """Initializes the C3k module with specified channels, number of layers, and configurations.""" super().__init__(c1, c2, n, shortcut, g, e) c_ = int(c2 * e) # hidden channels # self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n))) self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))如果将c3k中的n设置为2,则此时的模块即为C3K2模块,网络结构图如下所示。
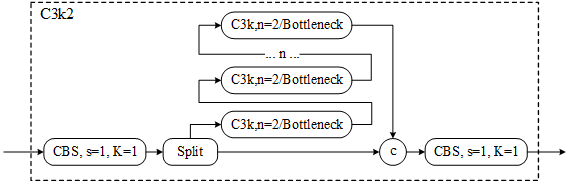
该网络的实现代码如下。
class C3k2(C2f): """Faster Implementation of CSP Bottleneck with 2 convolutions.""" def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True): """Initializes the C3k2 module, a faster CSP Bottleneck with 2 convolutions and optional C3k blocks.""" super().__init__(c1, c2, n, shortcut, g, e) self.m = nn.ModuleList( C3k(self.c, self.c, 2, shortcut, g) if c3k else Bottleneck(self.c, self.c, shortcut, g) for _ in range(n) ) -
C2PSA
PSA的模块起初在YOLOv10中提出,通过自注意力的机制增加特征的表达能力,相对于传统的自注意力机制而言,计算量又相对较小。网络的结构图如下所示,其中图中的mhsa表示的是多头自注意力机制,FFN表示前馈神经网络。
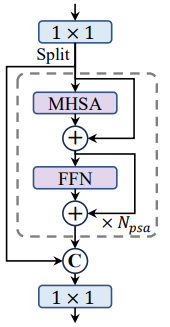
在这个基础上添加给原先的C2模块上添加一个PSA的旁路则构成了C2PSA的模块,该模块的示意图如下。
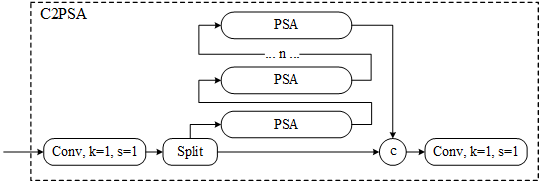
网络实现如下:
class C2PSA(nn.Module): """ C2PSA module with attention mechanism for enhanced feature extraction and processing. This module implements a convolutional block with attention mechanisms to enhance feature extraction and processing capabilities. It includes a series of PSABlock modules for self-attention and feed-forward operations. Attributes: c (int): Number of hidden channels. cv1 (Conv): 1x1 convolution layer to reduce the number of input channels to 2*c. cv2 (Conv): 1x1 convolution layer to reduce the number of output channels to c. m (nn.Sequential): Sequential container of PSABlock modules for attention and feed-forward operations. Methods: forward: Performs a forward pass through the C2PSA module, applying attention and feed-forward operations. Notes: This module essentially is the same as PSA module, but refactored to allow stacking more PSABlock modules. Examples: >>> c2psa = C2PSA(c1=256, c2=256, n=3, e=0.5) >>> input_tensor = torch.randn(1, 256, 64, 64) >>> output_tensor = c2psa(input_tensor) """ def __init__(self, c1, c2, n=1, e=0.5): """Initializes the C2PSA module with specified input/output channels, number of layers, and expansion ratio.""" super().__init__() assert c1 == c2 self.c = int(c1 * e) self.cv1 = Conv(c1, 2 * self.c, 1, 1) self.cv2 = Conv(2 * self.c, c1, 1) self.m = nn.Sequential(*(PSABlock(self.c, attn_ratio=0.5, num_heads=self.c // 64) for _ in range(n))) def forward(self, x): """Processes the input tensor 'x' through a series of PSA blocks and returns the transformed tensor.""" a, b = self.cv1(x).split((self.c, self.c), dim=1) b = self.m(b) return self.cv2(torch.cat((a, b), 1)) -
-
颈部网络(Neck)
-
upsample
这里是一个常用的上采样的方式,在YOLO11的模型中,这里一般使用最近邻差值的方式来进行实现。在
torch(PyTorch)中,upsample操作是用于对张量(通常是图像或特征图)进行上采样(增大尺寸)的操作。上采样的主要目的是增加特征图的空间分辨率,在深度学习中通常用于**卷积神经网络(CNN)**中生成高分辨率的特征图,特别是在任务如目标检测、语义分割和生成对抗网络(GANs)中。PyTorch 中的
torch.nn.functional.upsample在较早版本提供了上采样功能,但在新的版本中推荐使用torch.nn.functional.interpolate,功能相同,但更加灵活和标准化。主要参数如下:
torch.nn.functional.interpolate函数用于上采样,支持不同的插值方法,常用的参数如下:torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)-
input:输入的张量,通常是 4D 的张量,形状为(batch_size, channels, height, width)。 -
size:输出的目标尺寸,可以是整型的高度和宽度(如(height, width)),表示希望将特征图调整到的具体尺寸。 -
scale_factor:上采样的缩放因子。例如,scale_factor=2表示特征图的高度和宽度都扩大 2 倍。如果设置了scale_factor,则不需要再设置size。 -
mode:插值的方式,有多种可选插值算法:
'nearest':最近邻插值(默认)。直接复制最近的像素值,计算简单,速度快,但生成图像可能比较粗糙。'linear':双线性插值,适用于 3D 输入(即 1D 特征图)。'bilinear':双线性插值,适用于 4D 输入(即 2D 特征图)。'trilinear':三线性插值,适用于 5D 输入(即 3D 特征图)。'bicubic':双三次插值,计算更复杂,但生成的图像更平滑。
-
align_corners:在使用双线性、三线性等插值时决定是否对齐角点。如果为True,输入和输出特征图的角点会对齐,通常会使插值结果更加精确。
-
-
Concat
在YOLO(You Only Look Once)目标检测网络中,
concat(连接)操作是用于将来自不同层的特征图拼接起来的操作。其作用是融合不同尺度的特征信息,以便网络能够在多个尺度上更好地进行目标检测。调整好尺寸后,沿着通道维度将特征图进行拼接。假设我们有两个特征图,分别具有形状 (H, W, C1) 和 (H, W, C2),拼接后得到的特征图形状将是 (H, W, C1+C2),即通道数增加了。一般情况下,在进行concat操作之后会再进行一次卷积的操作,通过卷积的操作可以将通道数调整到理想的大小。该操作的实现如下。class Concat(nn.Module): """Concatenate a list of tensors along dimension.""" def __init__(self, dimension=1): """Concatenates a list of tensors along a specified dimension.""" super().__init__() self.d = dimension def forward(self, x): """Forward pass for the YOLOv8 mask Proto module.""" return torch.cat(x, self.d)
-
-
头部(Head)
YOLOv11的Head负责生成目标检测和分类方面的最终预测。它处理从颈部传递的特征映射,最终输出图像内对象的边界框和类标签。一般负责将特征进行映射到你对应的任务上,如果是检测任务,对应的就是4个边界框的值以及1个置信度的值和一个物体类别的值。如下所示。
# Ultralytics YOLO 🚀, AGPL-3.0 license """Model head modules.""" import copy import math import torch import torch.nn as nn from torch.nn.init import constant_, xavier_uniform_ from ultralytics.utils.tal import TORCH_1_10, dist2bbox, dist2rbox, make_anchors from .block import DFL, BNContrastiveHead, ContrastiveHead, Proto from .conv import Conv, DWConv from .transformer import MLP, DeformableTransformerDecoder, DeformableTransformerDecoderLayer from .utils import bias_init_with_prob, linear_init __all__ = "Detect", "Segment", "Pose", "Classify", "OBB", "RTDETRDecoder", "v10Detect"
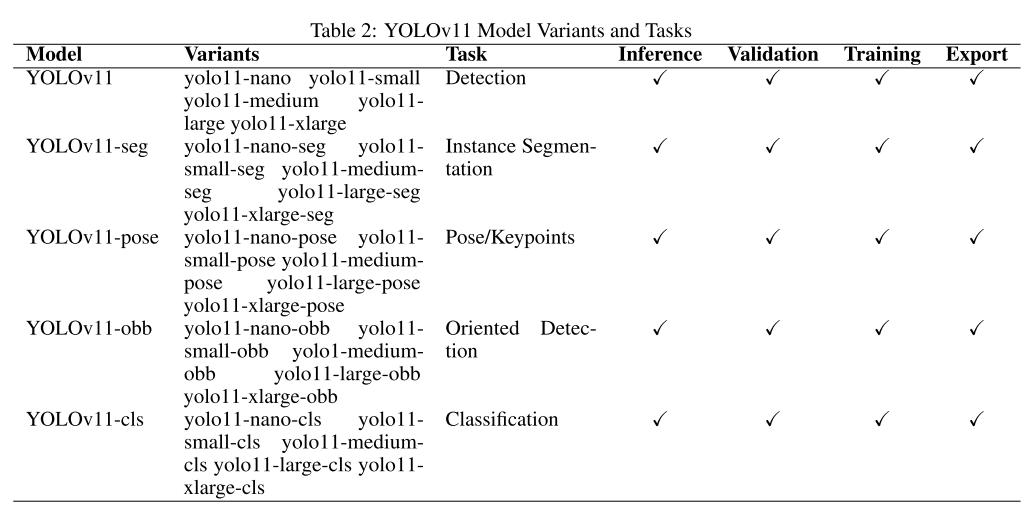
基于上面的设计,yolo11衍生出了多种变种,如下表所示。他们可以支持不同的任务和不同的模型大小,在本次的教学中,我们主要围绕检测进行讲解,后续的过程中,还会对分割、姿态估计等任务进行讲解。
YOLOv11代表了CV领域的重大进步,提供了增强性能和多功能性的引人注目的组合。YOLO架构的最新迭代在精度和处理速度方面有了显著的改进,同时减少了所需参数的数量。这样的优化使得YOLOv11特别适合广泛的应用程序,从边缘计算到基于云的分析。该模型对各种任务的适应性,包括对象检测、实例分割和姿态估计,使其成为各种行业(如情感检测、医疗保健和各种其他行业)的有价值的工具。它的无缝集成能力和提高的效率使其成为寻求实施或升级其CV系统的企业的一个有吸引力的选择。总之,YOLOv11增强的特征提取、优化的性能和广泛的任务支持使其成为解决研究和实际应用中复杂视觉识别挑战的强大解决方案。
目标追踪
上面介绍完了基本的检测任务,接下来我们介绍一下追踪这个任务。注意,追踪这个任务一定是基于动态的任务去做的,对于追踪任务而言,主要是在一个连续的帧里面去找相同的连续的一个或者多个目标,传统的算法会通过光流、或者滤波来对目标进行估计,现在常用的方式基本都是基于检测去做的,也就是通过检测先找到目标,然后计算目标和前面几个序列的相似度决定是否是同一个目标。
目标追踪(Object Tracking)是一种计算机视觉技术,用于在视频序列中识别并持续跟踪特定目标。与目标检测不同,目标追踪关注的是在连续的视频帧中找到同一目标的位置和状态。它在自动驾驶、监控、运动分析等领域有广泛应用。
目标追踪的类型
- 单目标追踪(Single Object Tracking,SOT):在整个视频序列中只追踪一个目标。
- 多目标追踪(Multiple Object Tracking,MOT):同时追踪多个目标。
- 多目标、多实例追踪(Multiple Instance Tracking,MIT):同时追踪多个同类目标,比如不同的人或不同的车辆。
常见的目标追踪方法
- 光流法:基于相邻帧中的像素移动估计目标的位置,适合实时性要求高的应用。
- 相关滤波方法:使用相关滤波器来识别目标的区域,适合快速的单目标追踪。
- 深度学习方法:包括 Siamese Network 等,利用卷积神经网络学习目标特征,追踪精度高但计算资源消耗大。
- 检测-追踪方法(Detection-Based Tracking):结合检测和追踪,通过目标检测器找到目标位置,再利用卡尔曼滤波器或匈牙利算法等方法对检测结果进行关联。
简单的目标追踪示例
假设我们使用 OpenCV 中的 cv2.TrackerKCF_create() 来实现一个简单的单目标追踪,这是基于相关滤波的快速追踪方法。假设我们要追踪视频中的一个球体。
import cv2
# 初始化视频捕获对象,读取视频文件或摄像头
video = cv2.VideoCapture("video.mp4") # 或者用0表示摄像头
# 读取第一帧
ret, frame = video.read()
# 手动选取追踪区域(在第一帧中选择目标)
bbox = cv2.selectROI("Frame", frame, fromCenter=False, showCrosshair=True)
# 初始化KCF追踪器
tracker = cv2.TrackerKCF_create()
tracker.init(frame, bbox)
while True:
ret, frame = video.read()
if not ret:
break
# 更新追踪器,返回新的边界框
ret, bbox = tracker.update(frame)
if ret:
# 如果追踪成功,绘制边界框
(x, y, w, h) = [int(v) for v in bbox]
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.putText(frame, "Tracking", (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 255, 0), 2)
else:
# 如果追踪失败
cv2.putText(frame, "Lost", (50, 80), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
# 显示帧
cv2.imshow("Tracking", frame)
# 按 'q' 键退出
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# 释放资源
video.release()
cv2.destroyAllWindows()
示例解释
- 初始化视频捕获:使用
cv2.VideoCapture()读取视频或启动摄像头。 - 选择追踪目标:使用
cv2.selectROI()在第一帧手动选定追踪区域。 - 初始化追踪器:
cv2.TrackerKCF_create()创建 KCF 追踪器,并通过tracker.init()初始化追踪目标。 - 更新追踪器:在每一帧中,通过
tracker.update()获取目标的新位置并在图像上绘制边界框。 - 终止条件:按 ‘q’ 键退出循环,释放资源。
运行结果
这段代码会在视频的第一帧中手动选择目标,并在后续帧中自动追踪目标的位置,实时显示追踪效果。如果追踪失败,会显示“Lost”。
ByteTrack
ByteTrack 是 2021 年由中国科学院自动化研究所提出的一种多目标跟踪(MOT, Multi-Object Tracking)算法。它基于 YOLO 系列检测器的输出结果,通过对高置信度和低置信度检测结果的联合处理,显著提升了跟踪性能。相比之前的追踪算法(如 SORT、DeepSORT),ByteTrack 在精度和效率上都达到了更好的平衡。
一、ByteTrack 背景与挑战
多目标跟踪任务的目标是在视频序列中同时跟踪多个目标,并为每个目标分配唯一的 ID。这个过程通常包括两个步骤:
- 目标检测:检测视频帧中的所有目标。
- 数据关联:将新检测到的目标与现有轨迹匹配。
然而,由于检测器通常会输出低置信度(Low Confidence)的检测结果,这些结果在经典的多目标跟踪算法中往往被忽略掉,导致潜在目标的丢失。ByteTrack 旨在解决这个问题,通过处理所有的检测结果(包括低置信度的检测),提高跟踪的鲁棒性和准确性。
二、ByteTrack 的核心思想
ByteTrack 的创新之处在于利用了所有置信度的检测结果进行数据关联,而不仅仅是高置信度的检测结果。这使得即便检测器输出的置信度较低,目标也不会轻易被丢弃,从而减少了轨迹的中断。
具体来说,ByteTrack 将检测器输出的检测框按照置信度阈值划分为高置信度检测框(High Confidence Detections)和低置信度检测框(Low Confidence Detections),并分别处理:
- 第一阶段:首先对高置信度检测框进行数据关联,以确保最可靠的目标匹配。
- 第二阶段:然后,对尚未匹配的轨迹使用低置信度检测框进行数据关联,以填补潜在的轨迹间隙。
通过这种两阶段的处理,ByteTrack 能够更好地保持目标的连续轨迹,显著减少 ID Switch 和目标丢失的问题。
三、ByteTrack 的算法流程
以下是 ByteTrack 的核心算法流程:
-
目标检测:使用目标检测器(如 YOLOv5 或 YOLOv7)检测当前帧中的所有目标。
-
高置信度数据关联:
- 对检测框按置信度阈值进行划分,得到高置信度检测框集合。
- 使用匈牙利算法和IoU 匹配,将高置信度检测框与现有轨迹关联。
注:在多目标跟踪(MOT, Multi-Object Tracking)任务中,匈牙利算法被广泛用于数据关联阶段。其主要应用场景是将检测器在当前帧中的目标检测结果与前一帧中已有的**轨迹(轨道)**进行关联,从而实现对多个目标的连续跟踪。
-
低置信度数据关联:
- 对第一阶段未能匹配的轨迹,使用低置信度检测框再次尝试匹配。
- 使用相同的匈牙利算法和 IoU 匹配方法进行关联。
-
轨迹更新:
- 更新匹配上的轨迹,并对未匹配的轨迹进行管理(如删除过长时间未更新的轨迹)。
这种分步处理方式使得 ByteTrack 在保证高准确度的同时,也能够跟踪到低置信度目标,从而提高整体跟踪性能。
四、ByteTrack 的优势
- 高精度和高召回率:
- 通过引入低置信度检测结果,减少了目标的丢失,提高了整体的检测和跟踪精度。
- 高效的计算:
- ByteTrack 在速度和精度上取得了良好的平衡,能够以接近实时的速度处理视频序列。
- 鲁棒性强:
- 由于同时考虑了高置信度和低置信度的目标检测,ByteTrack 对检测器的置信度波动不敏感。
五、ByteTrack 的实验结果
在多个公开的数据集上(如 MOT16、MOT17 和 MOT20),ByteTrack 的表现优于当前最先进的跟踪算法,如 FairMOT、JDE、DeepSORT 等。其显著提升了 MOTA(多目标跟踪准确度)指标,并显著减少了 ID Switch 的数量。
- MOTA:+6.5% 的提升
- ID Switch:减少 40%
- 实时处理:在基于 YOLOv5 的检测器上,达到了 30+ FPS 的速度。
六、ByteTrack 的应用场景
ByteTrack 可广泛应用于各类多目标跟踪场景,如:
- 智能交通监控:如行人和车辆的跟踪。
- 无人驾驶:用于识别和跟踪道路上的行人、车辆和障碍物。
- 安防监控:检测和跟踪监控视频中的可疑目标。
- 体育分析:追踪运动员的动作轨迹以进行战术分析。
ByteTrack 的提出使得多目标跟踪在复杂场景下取得了显著的性能提升。其基于置信度划分的双阶段数据关联策略,兼顾了高效性与高精度,为实际应用提供了强有力的支持。通过将 ByteTrack 应用于各种场景,开发者可以轻松构建实时、多目标的跟踪系统,大幅提高检测与跟踪的综合效果。
BoT-SORT
BoT-SORT(Boosted SORT with Stronger ReID)是一种改进的多目标跟踪(MOT, Multi-Object Tracking)算法,由德国亚琛工业大学(RWTH Aachen University)和英国谢菲尔德大学的研究团队于 2022 年提出。该算法在经典的 SORT(Simple Online and Realtime Tracking)基础上引入了更强大的Re-ID 模块和数据关联策略,从而在多目标跟踪任务中取得了显著的性能提升。
一、BoT-SORT 的背景与动机
多目标跟踪的关键任务是在视频序列中同时跟踪多个目标对象,并为每个目标分配唯一的 ID。现有算法,如 SORT 和 DeepSORT,主要依赖于卡尔曼滤波和匈牙利算法进行目标匹配。然而,它们在处理快速移动的目标、目标重叠和遮挡时表现不佳,容易产生 ID Switch 和目标丢失的问题。
BoT-SORT 通过以下策略提升多目标跟踪的效果:
- 改进数据关联:将检测结果与轨迹进行更鲁棒的匹配。
- 更强的 Re-ID 模块:利用更强的特征提取器来减少 ID Switch。
- 优化轨迹管理:通过多层次的匹配策略更好地处理遮挡和丢失目标的问题。
二、BoT-SORT 的核心思想
BoT-SORT 主要从三个方面对原始 SORT 进行了改进:
-
引入更强的 Re-ID 特征提取器:
- BoT-SORT 使用了一种基于 CNN 的 Re-ID 模块,用于提取目标的外观特征。相比 DeepSORT 中较弱的 Re-ID 模块,BoT-SORT 采用了更强的**BoT(Bag of Tricks)**特征提取器,从而提高了对目标外观的区分能力。
- 通过在检测框裁剪后的图像上提取高分辨率特征,减少了因目标重叠和遮挡导致的 ID Switch。
-
两阶段的数据关联策略:
- 第一阶段:基于运动信息(IoU 匹配)进行数据关联。使用卡尔曼滤波器预测轨迹位置,通过 IoU 匹配算法将检测框与轨迹进行关联。
- 第二阶段:在未匹配的轨迹和检测框之间使用Re-ID 特征进行关联。BoT-SORT 通过余弦距离衡量 Re-ID 特征相似度,进一步关联未匹配的目标,从而减少轨迹丢失。
-
轨迹管理优化:
- 引入了轨迹生命周期管理策略,对长时间未匹配的轨迹进行清理,从而减少假阳性。
- 通过动态调整置信度阈值,提高了检测和关联的灵活性,特别是在高密度场景下的表现。
三、BoT-SORT 的算法流程
BoT-SORT 的整体算法流程如下:
-
目标检测:
- 使用目标检测器(如 YOLOv7、YOLOv8 或其他高性能检测器)检测当前帧中的所有目标,生成检测框及其置信度得分。
-
轨迹预测:
- 对现有轨迹使用卡尔曼滤波进行状态预测,得到预测位置。
-
第一阶段数据关联(基于 IoU 匹配):
- 通过 IoU 匹配算法,将检测框与预测轨迹进行关联。
- 使用匈牙利算法优化匹配结果。
-
第二阶段数据关联(基于 Re-ID 匹配):
- 对第一阶段未匹配的轨迹和检测框,计算 Re-ID 特征的余弦相似度。
- 使用匈牙利算法进行匹配,确保难以区分的目标也能被正确关联。
-
轨迹更新与管理:
- 更新匹配上的轨迹,对未匹配的检测框创建新轨迹。
- 清理长时间未更新的轨迹,减少错误关联。
四、BoT-SORT 的优势
-
更高的跟踪精度:
- 通过更强的 Re-ID 模块减少 ID Switch,特别是在目标遮挡或密集场景中表现更优。
-
鲁棒的多阶段匹配:
- 两阶段数据关联策略有效减少了丢失目标和误匹配的问题。
-
灵活的轨迹管理:
- 动态调整置信度阈值,提高了高密度场景下的目标追踪效果。
五、BoT-SORT 的实验结果
BoT-SORT 在多个公开的数据集(如 MOT17、MOT20)上的测试结果表明,它显著提升了跟踪性能:
- MOTA(多目标跟踪准确度):比现有方法提升 5.3%。
- ID Switch:减少 30%-50%。
- HOTA(Higher Order Tracking Accuracy):取得了高分,表明在 ID 保持和跟踪准确性上的显著提升。
与 ByteTrack 相比,BoT-SORT 在 Re-ID 特征的利用上更为突出,使其在密集目标场景中有更好的表现。
六、BoT-SORT 的应用场景
BoT-SORT 可广泛应用于以下领域:
- 智能交通:行人和车辆的跟踪,以实现智能交通流量管理和分析。
- 视频监控:在拥挤人群中跟踪嫌疑人,提高公共安全。
- 无人驾驶:跟踪行人、骑车人和车辆,辅助自动驾驶决策。
- 体育分析:跟踪运动员的动态,以进行战术分析和动作评估。
七、总结
BoT-SORT 通过引入更强大的 Re-ID 特征提取和多阶段数据关联策略,解决了传统多目标跟踪方法在复杂场景下的诸多不足。其在多个数据集上的表现表明,该算法在提高跟踪精度和减少 ID Switch 方面具有显著优势。BoT-SORT 通过在 Re-ID 特征提取和数据关联策略上的改进,使得多目标跟踪在复杂环境中的应用更加广泛和高效。
项目实战
有了上面的内容,我们就可以使用车辆的数据集来开发一个基于多目标的车辆检测和追踪系统,下面的内容我将会按照环境配置,模型训练和测试以及图形化界面封装几个阶段进行展开。
首先,开始之前,您需要从本博客上面的商品链接或者是B站置顶评论中的商品链接中获取本项目,项目中包含了已经提前处理好的数据集,模型训练预测的代码、训练好的车辆模型以及封装好的图形化界面。
环境配置前的准备工作
-
安装miniconda
推荐大家使用清华镜像下载的miniconda,实测非常稳定,记得安装的时候所有的对号都要选择上。
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py39_4.9.2-Windows-x86_64.exe
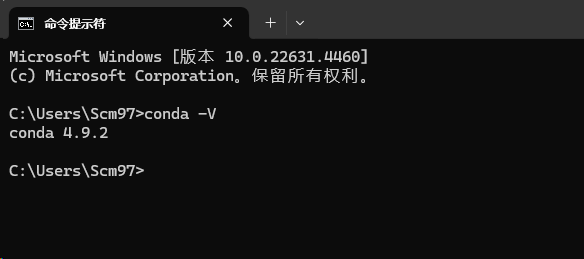
现在完成之后,直接命令行打开输入conda -V的指令观察是否能正确输出conda的版本号,如果可以,则说明没有问题。
另外,为了增加后面镜像下载的速度,推荐大家配置国内的镜像。
请执行下面的指令进行镜像的配置。
conda config --remove-key channels conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/ conda config --set show_channel_urls yes pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple pip config set global.index-url https://mirror.baidu.com/pypi/simple -
安装社区版本的pycharm
这里推荐大家安装社区版本的,社区版本的功能已经非常强大,并且完全免费。
下载的地址在这里:Other Versions - PyCharm
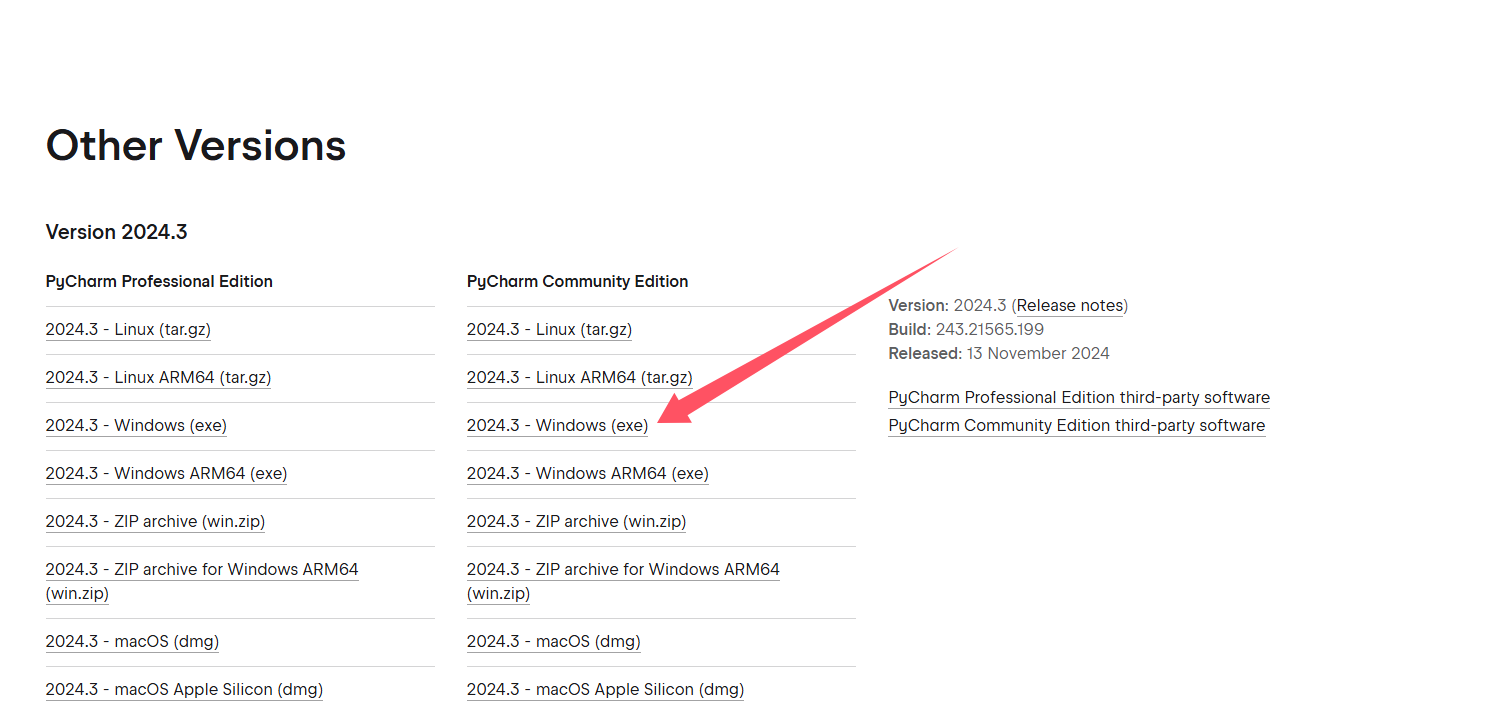
下载之后直接安装即可。
-
安装vs编译工具
后期在进行一些库的安装的过程中,可能出出现下面的错误。

error: Microsoft Visual C++ 14.0 is required. Get it with "Build Tools for Visual Studio": https://visualstudio.microsoft.com/downloads/ Tools":出现这样的错误表示你的代码缺乏c++的编译工具,因为部分库的底层实现逻辑是通过C++来进行完成的,所以为了避免出现这样的错误,在前期的准备中,我们需要从官网下载对应的库进行安装:Microsoft C++ 生成工具 - Visual Studio。
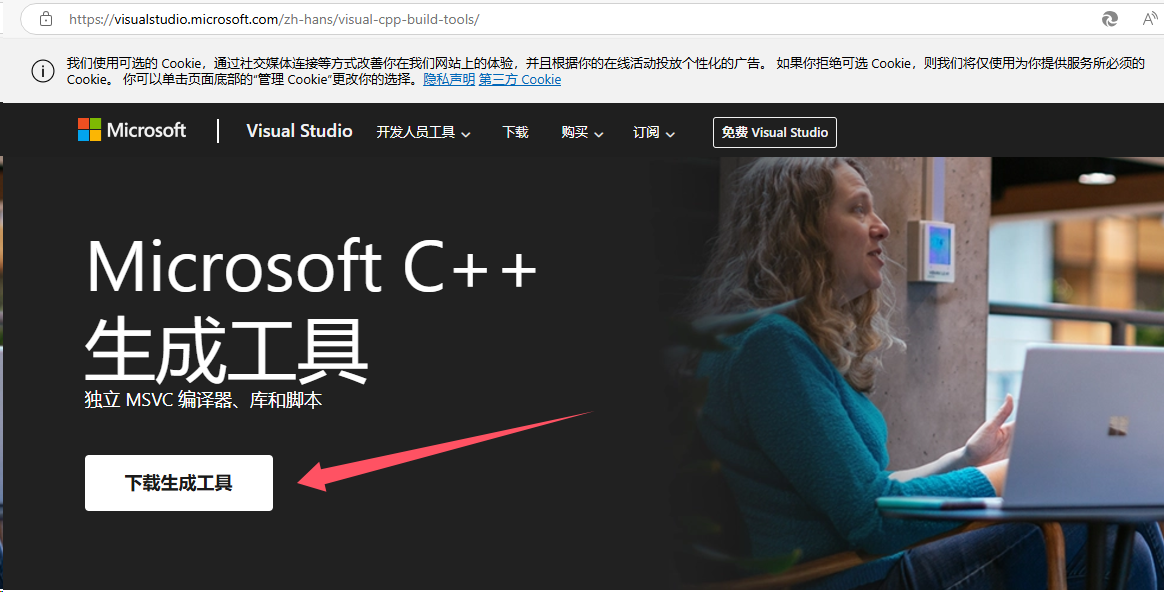
下载之后双击进行安装,你需要从列表中选择下面的部分,注意,这里的安装位置默认在c盘,如果你的c盘没有足够的空间,你一定要给他移动他其他的盘中。
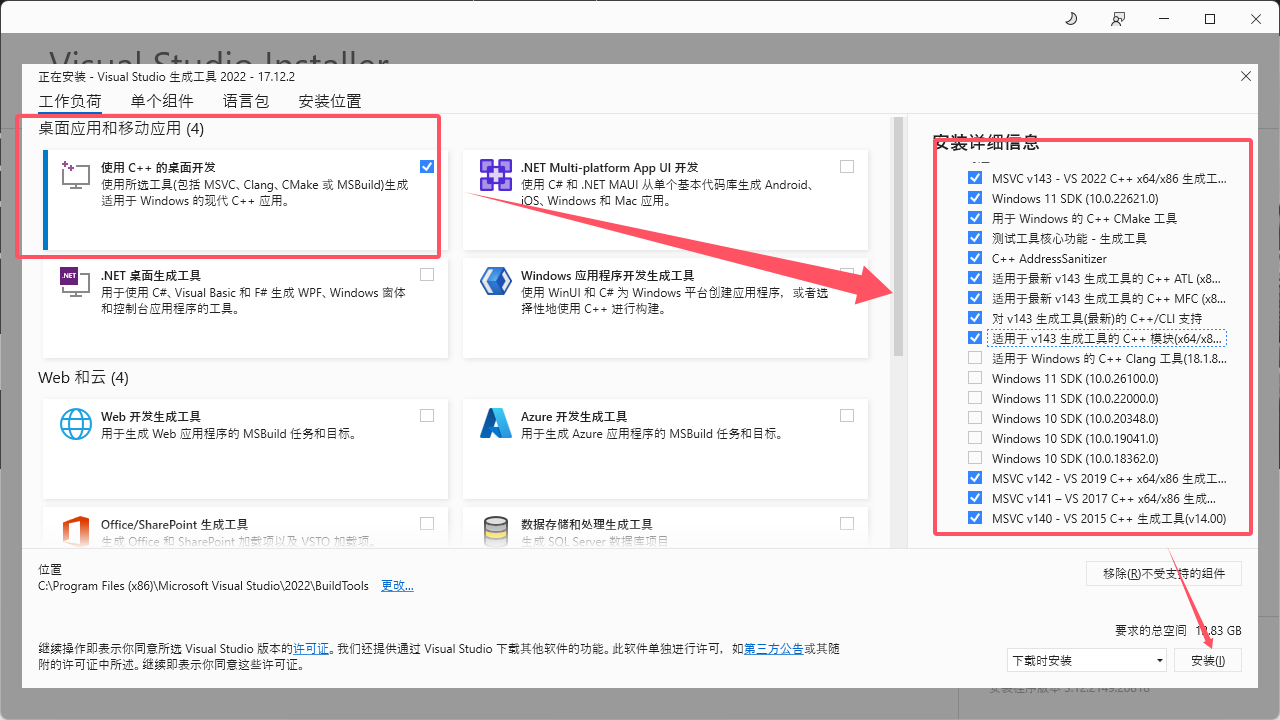
安装完成之后重启你的电脑即可。
-
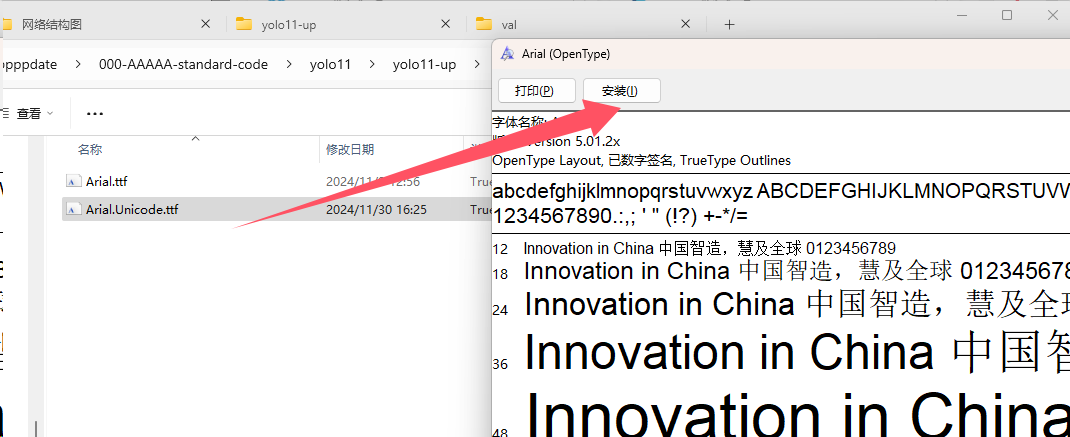
装字体文件
另外,很多小伙伴在跑yolo的时候,会提示字体文件缺失,虽然程序设置了自动下载,但是因为国内的下载速度比较慢,所以大家还是提前进行安装,字体文件已经提前准备在了代码包中,大家从字体文件的目录打开,双击进行安装即可。
环境配置
首先将项目进行解压,注意解压的时候请解压在英文的路径下面,中文的路径可能会导致opencv读取出现问题,为了避免不必要的麻烦,请大家将内容解压在英文的路径下面。
-
新建虚拟环境以及激活虚拟环境
conda create -n yolo11 python==3.8.5 conda activate yolo11 -
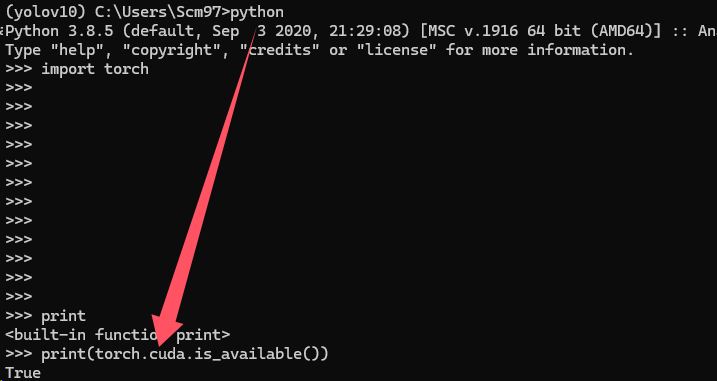
安装torch并测试torch
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本 conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30系列以上显卡gpu版本pytorch安装指令 conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可如果你是安装的GPU版本的torch,则需要对GPU进行测试,如果正确输出true则表示没有问题。
-
安装项目所需要的其他依赖库
之后我们来到项目的目录下面启动cmd
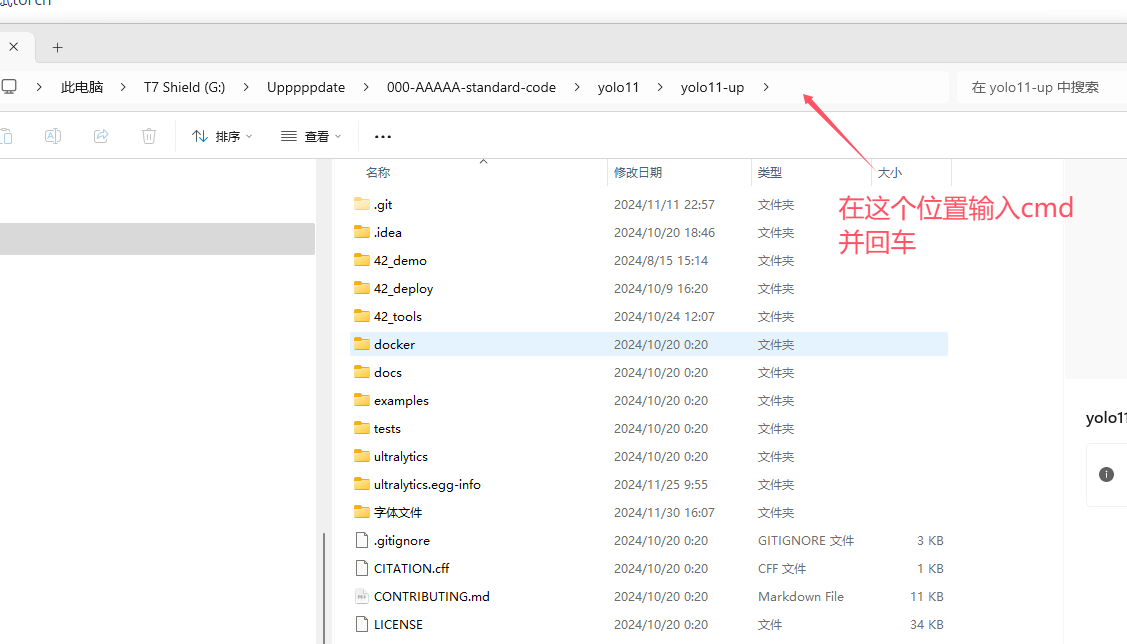
在项目目录下执行下列命令即可。
pip install -v -e .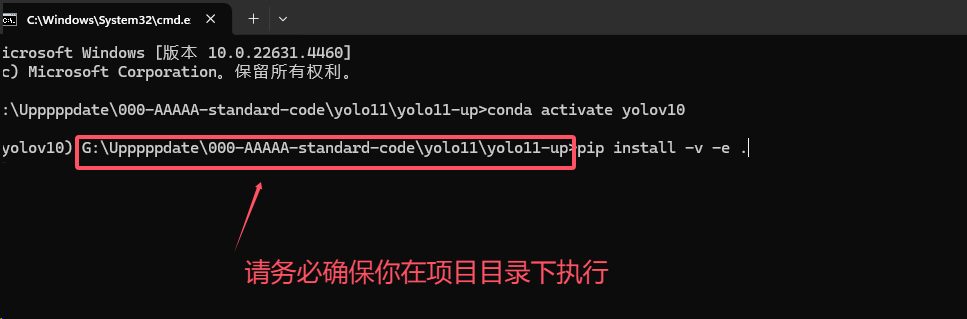
出现成功安装的字样则表示你的安装没有问题。

一般情况下为了防止一些库的版本过于新,你还可以手动降低一下版本。
pip install pillow==8.4.0 pip install numpy==1.23.1
执行完毕上面三个步骤之后,你可以使用pycharm打开然后进行demo的测试,注意使用pycharm打开的时候请务必保证你在右下方已经激活了对应的虚拟环境。
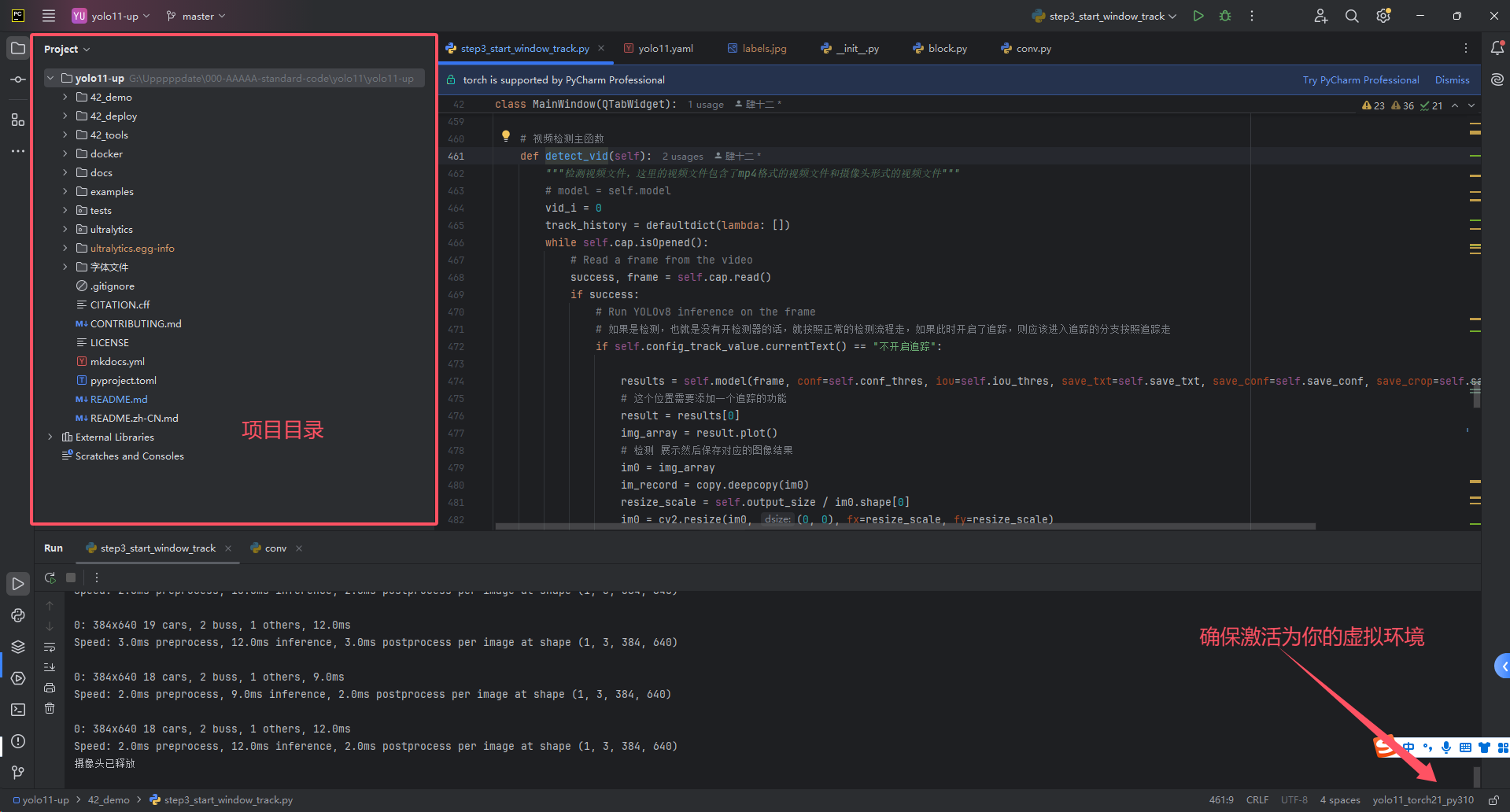
模型训练的测试
模型训练之前请准备好自己yolo格式的数据集,如果对数据集的标注和准备存在问题,请看这期博客:使用Labelimg制作自己的YOLO数据集_labelimg标注yolo-CSDN博客
首先请在下列位置修改成你本地的数据集。
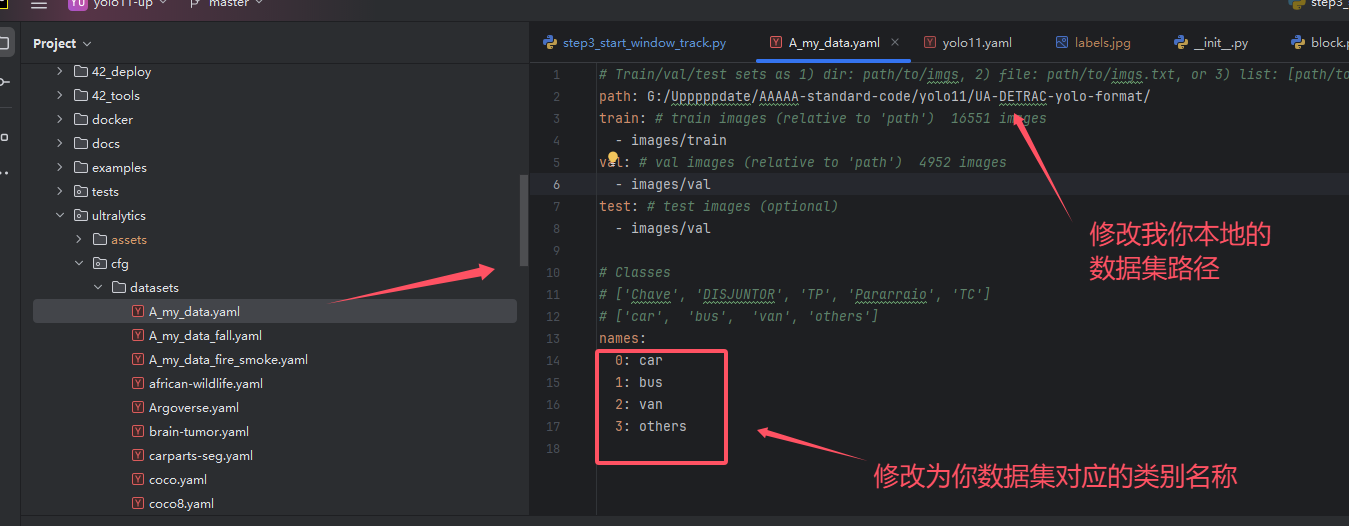
修改之后找到我们的一键训练脚本。
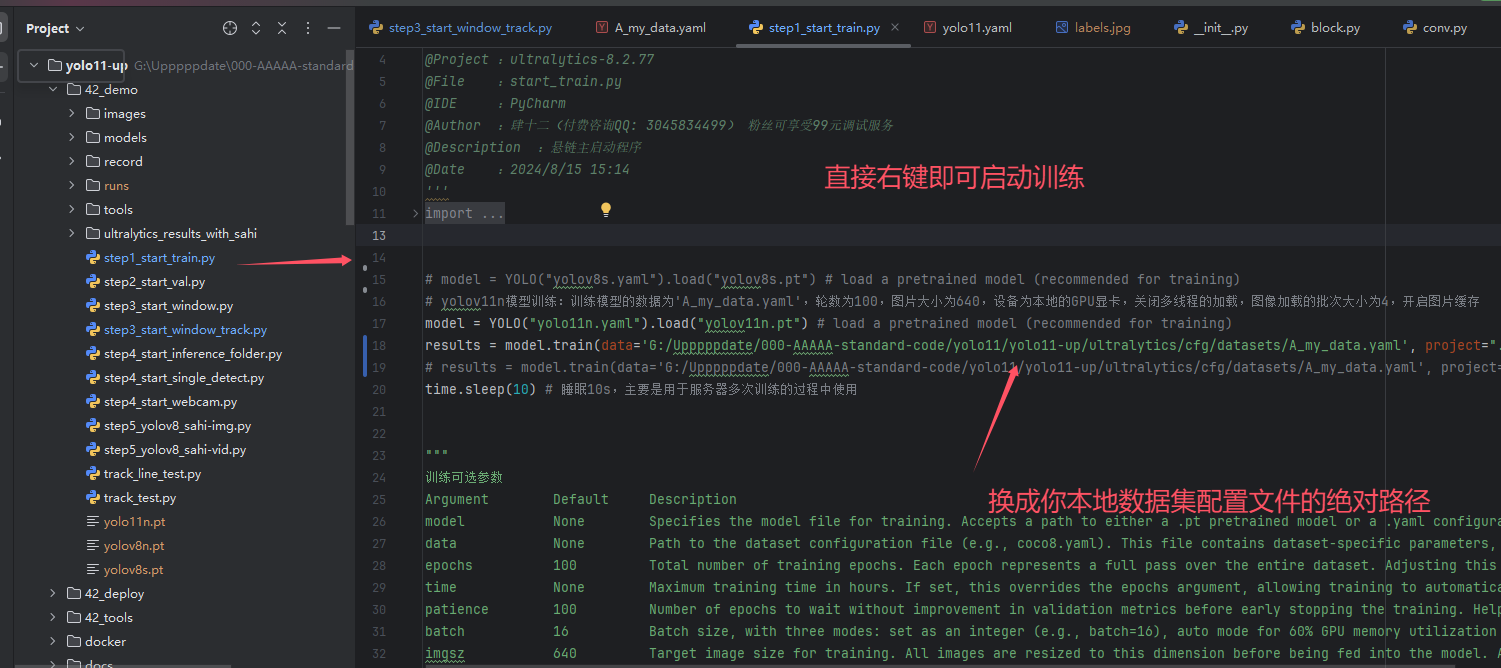
训练之后的结果将会保存在runs目录下面。
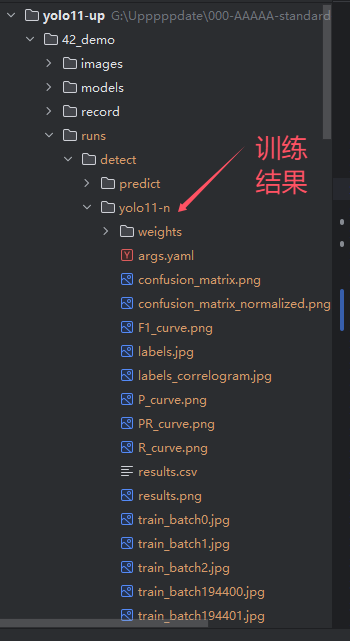
对训练结果的解读可以看这个位置:YOLO11模型指标解读-mAP、Precision、Recall_precision、recall、map-CSDN博客
PySide6集成封装
其中这个py文件是图形化界面集成的位置,这里使用pyside6进行开发。
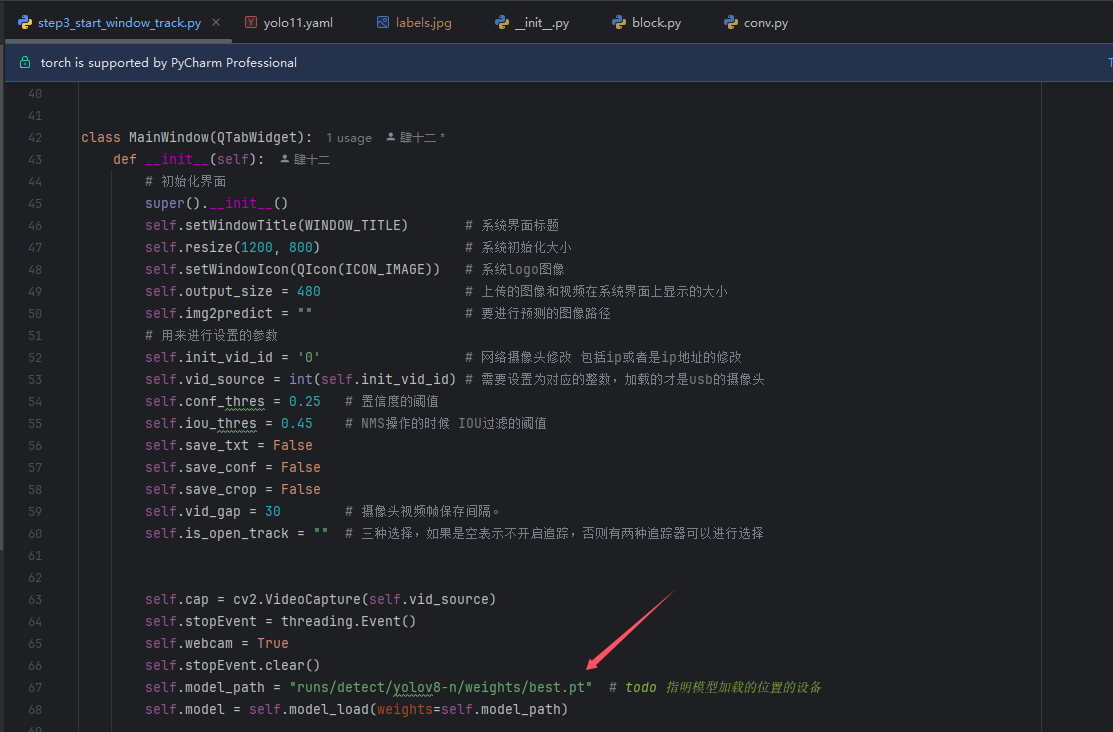
如果你是训练为自己的数据集,则需要将你自己训练好的模型路径在代码中进行切换,切换的位置如下。
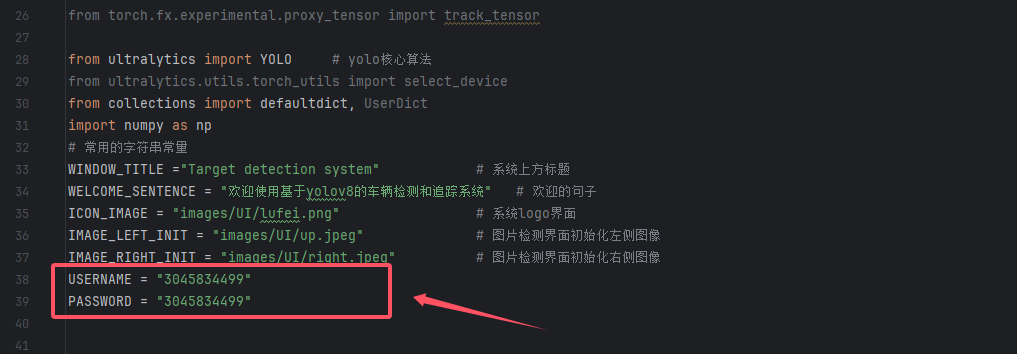
之后你就可以直接进行启动了,由于我这边设置了启动的账号密码,如果你需要修改,则只需要在代码的这个位置进行修改即可。
输入账号密码进行登录。
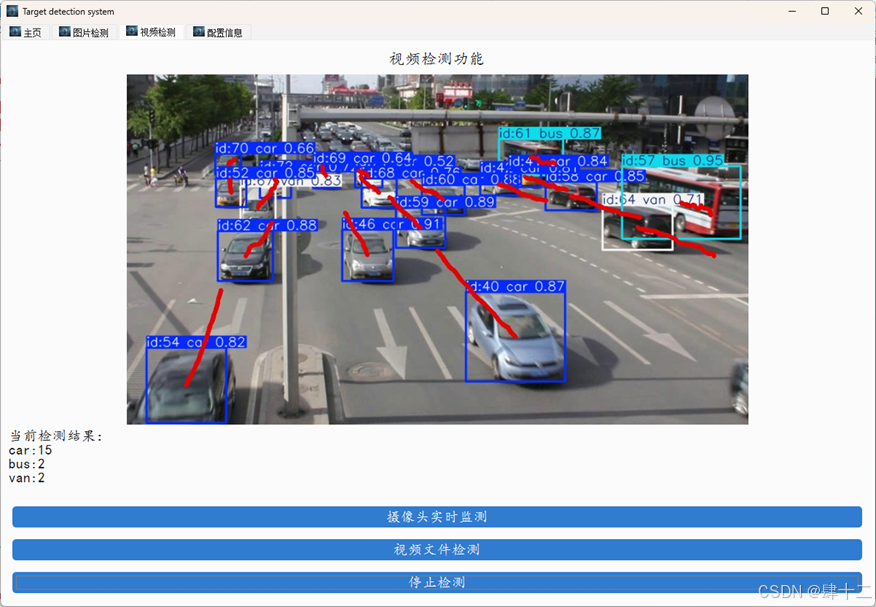
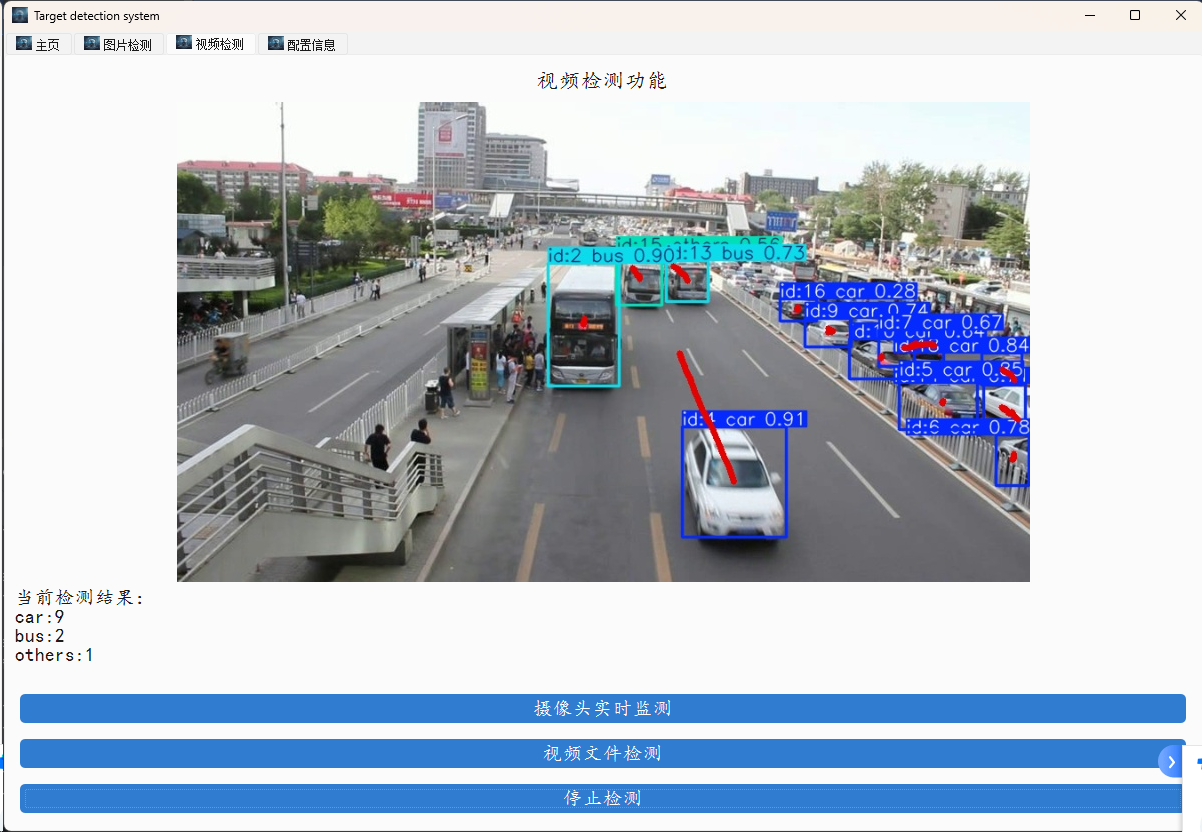
登录之后进行主界面进行测试即可。
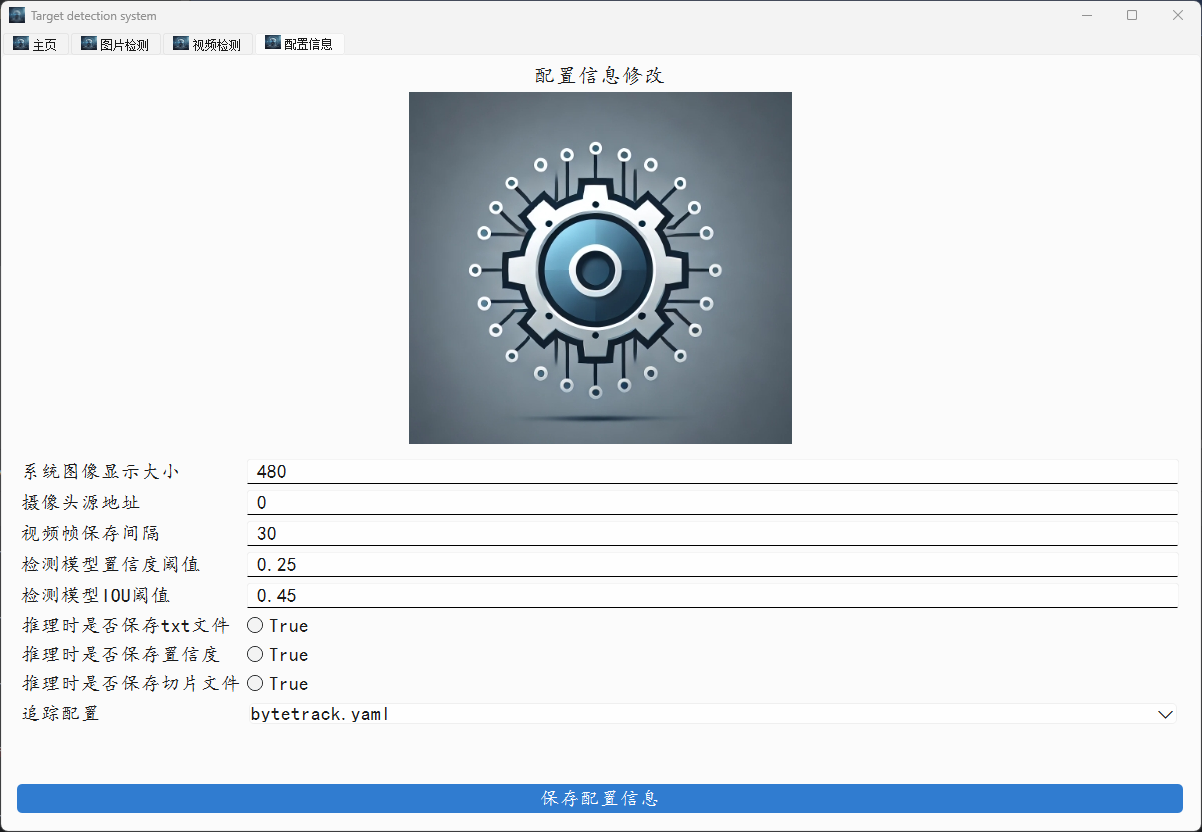
同样的,你也可以在配置界面对配置进行进行修改,注意,修改之后请一定要记得保存。


















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











