






前言
在人工智能的浩瀚星空中,大型语言模型(Large Language Model,简称LLM)无疑是一颗璀璨的明星。这些模型以其卓越的自然语言处理(NLP)能力,正逐步改变我们与机器的交互方式,并在智能问答、文本生成等多个领域展现出巨大的应用潜力。本文将带您走进LLM大模型的世界,探索其背后的预训练、微调技术以及产品化落地的奥秘。
一、LLM大模型的预训练技术
预训练:奠定基石
在预训练阶段,LLM大模型被暴露在数以亿计的无标签数据之中,这些数据包括但不限于网页文本、学术论文、书籍、新闻报道、社交媒体内容等,覆盖了人类语言的广泛领域和多样风格。通过无监督学习的方式,模型能够自动地从这些数据中提炼出词汇的深层语义、句子的复杂语法结构、文本的内在逻辑以及跨文本的通用知识和上下文依赖关系。这一过程不仅增强了模型的语言表征能力,还为其后续在各种具体任务中的表现奠定了坚实的基础。《大模型报告专题:清华大学2023从千亿模型到ChatGPT的一点思考》汇总了近五年的大模型预训练进程,如下图所示。
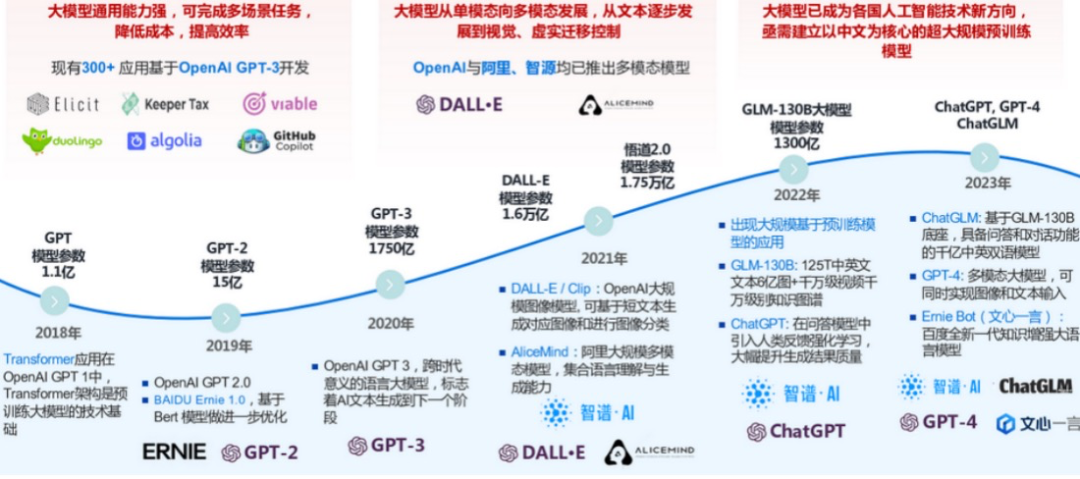
预训练的实例应用
GLM-130B:语言知识的浩瀚海洋
GLM-130B预训练过程堪称是一次对语言知识的全面探索和积累。通过处理超过125T的中英文文本数据,GLM-130B不仅掌握了丰富的词汇和语法知识,还融入了图像、视频等多模态信息,构建了千万级别的知识图谱。这一壮举不仅展示了模型在语言处理方面的深厚功底,也预示了未来多模态融合趋势下AI应用的新方向。
OpenAI的GPT系列:从量变到质变的飞跃
每一代GPT模型的推出,都伴随着预训练数据集规模的扩大、模型架构的优化以及训练算法的改进。这些努力使得GPT系列模型在文本生成、对话系统、问答系统等任务中的表现不断突破,实现了从量变到质变的飞跃。特别是GPT-4,其强大的上下文理解能力、逻辑推理能力以及跨领域知识整合能力,更是让业界对LLM大模型的未来充满了无限遐想。
二、LLM大模型的微调技术
微调:定制化的艺术
虽然预训练为LLM大模型打下了坚实的基础,但要让它们真正适应特定任务,还需要进行微调。其与预训练的关系如下图所示。微调过程涉及对模型权重的微小调整,使其能够更好地适应特定领域的数据集,从而提升在特定NLP任务上的表现,如情感分析、命名实体识别、文本分类等。为了解决大模型训练和部署的高成本问题,研究人员提出了参数高效微调(PEFT)的方法。PEFT通过调整少量参数或添加小型模块,即可实现对模型的定制化,从而在保持模型性能的同时,大大降低计算成本。
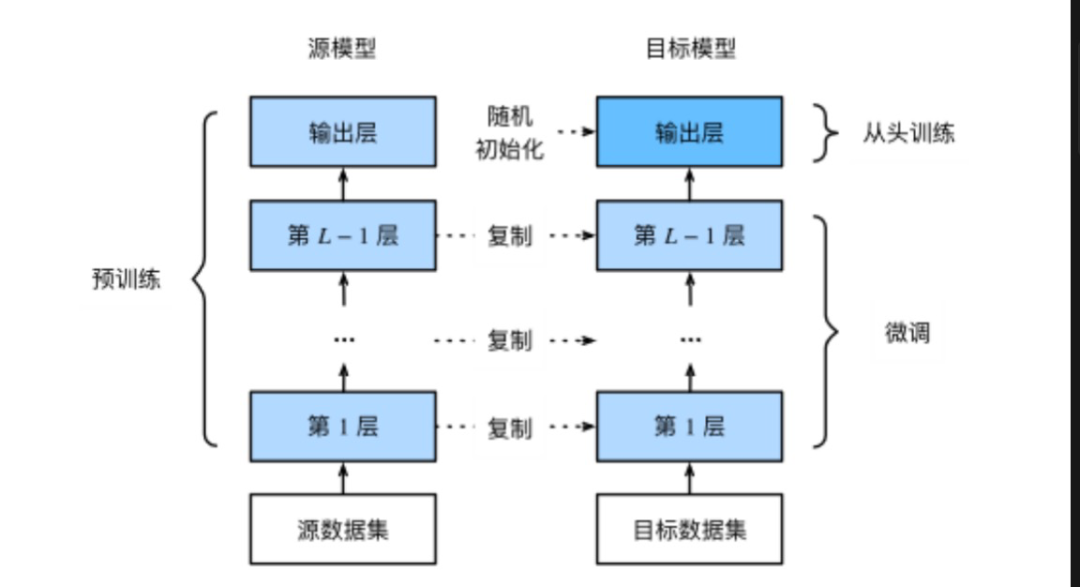
常见的PEFT方法扩展
Additive PEFT(如Adapter方法):在模型的不同层之间插入轻量级适配器(Adapter),这些适配器包含可训练的参数,用于捕获特定任务的信息。通过训练这些适配器,模型可以在不改变预训练参数的情况下,适应新的任务需求。
Selective PEFT(如Diff Pruning方法):该方法通过选择性剪枝技术,去除对特定任务影响较小的参数,同时保留或增强对任务关键的特征表示。这种方法能够在保持模型性能的同时,显著减少模型大小和计算复杂度。
Reparameterized PEFT(如LoRA方法):LoRA(Low-Rank Adaptation)方法通过在模型参数上添加低秩矩阵来实现微调。这些低秩矩阵包含了任务特定的信息,并且由于它们的秩较低,因此所需的参数数量远远少于直接微调整个模型。这种方法既保持了模型的性能,又降低了存储和计算成本。
Hybrid PEFT(如UniPELT方法):结合多种PEFT方法的优势,构建出更加灵活高效的微调策略。例如,UniPELT方法可以根据任务需求自动选择最合适的PEFT方法,并动态调整模型结构,以实现最佳的性能和效率平衡。
微调的典型实例
GPT Code系列:在编程领域,通过针对编程任务进行微调,GPT Code系列模型能够生成既符合语法规则又具有逻辑性的代码片段。这不仅提高了软件开发的效率,还促进了自动化编程技术的发展。
GPT Text系列:在文本创作领域,GPT Text系列模型经过微调后,能够胜任文学创作、新闻撰写等多种文本生成任务。它们能够生成流畅、富有创意的文本内容,为内容创作者提供强有力的支持。
ChatGLM-6B:在对话系统领域,ChatGLM-6B等模型通过针对对话任务进行微调,实现了在多轮对话中准确理解用户意图并给出恰当回应的能力。这不仅提升了用户体验,还推动了智能客服、智能家居等应用场景的发展。
三、LLM大模型的产品化落地
智能问答
智能问答系统是LLM大模型最直观的应用之一。通过预训练和微调,这些模型能够准确理解用户问题,并从海量数据中检索相关信息,给出准确的答案。无论是搜索引擎中的智能回答,还是智能家居中的语音助手,都能看到LLM大模型的身影。
文本生成
在文本生成领域,LLM大模型同样展现出了非凡的能力。无论是新闻报道、小说创作,还是广告文案、社交媒体内容,这些模型都能根据输入的关键词或主题,自动生成符合要求的文本。这不仅大大提高了内容创作的效率,还使得创作过程更加个性化和多样化。
端侧部署
随着技术的不断进步,LLM大模型正逐渐从云端走向端侧。这意味着用户可以在手机、平板等移动设备上直接使用这些模型,享受更加便捷和智能的服务。例如,Google推出的Gecko模型可以在旗舰手机上离线运行,为用户提供实时的自然语言交互体验。
四、LLM领域的前沿技术研究
跨技术综合应用
当前,LLM领域的研究正逐渐从单一技术的应用向跨技术综合应用转变。数据挖掘、自然语言处理、机器学习和知识图谱等技术的有机结合,将进一步提升LLM大模型在处理复杂任务时的能力和效率。
多模态学习
除了文本处理外,LLM大模型还在积极探索图像、音频等多模态数据的处理和应用。通过将自然语言处理与计算机视觉、语音识别等技术相结合,这些模型将在更多领域发挥重要作用。
可解释性与隐私保护
随着LLM大模型在各个领域的应用日益广泛,如何提高模型的可解释性和加强隐私保护成为新的研究热点。研究人员正在探索如何通过算法优化和数据加密等手段,确保模型在提供优质服务的同时,保护用户的隐私和数据安全。
结语
LLM大模型作为人工智能领域的重要成果之一,正在不断推动着自然语言处理技术的发展和应用。通过预训练和微调技术的不断优化和完善,这些模型将在更多领域展现出其强大的能力。同时,随着端侧部署和跨技术综合应用的不断推进,LLM大模型的产品化落地也将迎来更加广阔的市场前景。未来已来,让我们共同期待LLM大模型带来的更多惊喜和可能。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









