






前言
自从2022年底ChatGPT横空出世引爆了大模型技术浪潮,时至今日已经一年有余,如何从技术侧向商业侧落地转化是一直以来业内普遍关注的问题。
从目前企业端观察到的情况来看,基于大模型的知识库是一个比较有潜力和价值的应用场景,能够帮助企业大幅提高知识的整合和应用效率。然而由于通用预训练大模型的训练数据主要来源于公开渠道,缺乏企业专业和私有知识,直接使用将难以支撑企业内部的专业知识问答。
通过重新训练或微调的方式可以实现知识扩充,但存在以下缺点:
-
需要的数据量大,训练代价高、周期长;
-
对于企业知识的快速更新无法及时响应;
-
对已有知识无法有效更新或删除;
-
大模型存在的“幻觉”问题。
而RAG(Retrieval-Augmented Generation,检索增强生成)技术,能够在一定程度上解决以上问题。RAG,顾名思义,即通过引入存储在外部数据库中的知识以增强大模型的问答能力。具体来说,大模型在回答问题或生成内容前,首先在外部数据库中进行检索,将相似度高的内容返回给大模型再进一步整理生成。这种模式能够提高输出的准确性和相关性,避免大模型产生“幻觉”生成事实不正确的内容。RAG与LLM的集成正被迅速应用于构建知识库、聊天机器人以及其他大模型应用中。
本文将简要介绍基于RAG与LLM的智能知识库的搭建过程,并展示一些开源的知识库项目。
一、搭建过程
主要可以分为以下几个步骤。
1. 数据收集
若企业已有知识管理系统,后续可直接与原系统进行对接并进行下一步处理;对于相当一部分目前没有建设知识管理系统的企业,那么首先要做的是收集企业内部的各种知识数据,包括各种格式的文档数据,以及表格、图片、音频、视频等多模态数据等,用于后续与大模型进行交互。
2. 数据处理
2.1 数据清洗与预处理
了解机器学习建模的读者可能听过“garbage in garbage out”这句经典,数据清洗与预处理将对后续模型性能起到关键作用。
以最常见的文本类数据为例,一般的数据清洗与预处理包括去噪声,去除特殊格式、特殊字符、停用词、标点符号,以及进行词干化或分词以减少词汇量等。
2.2 文本分块
在RAG方法中,将大型文档分割成“块”(chunk)进行存储,一方面将有助于提高检索效率,另一方面通过基于特定“块”的上下文检索方法还能够在一定程度上弥补检索精度的不足。由此可见,分块的结果将直接影响最终的应用效果,因此选择合适的分块方法至关重要。
目前常用的文本分块的方法主要有如下几种:
-
按字符数分割:根据设定分块的字符长度进行分割,这是最简单的分块方法,比较“傻瓜式”,对语义理解不足;
-
按段落分割:结合文档的层次分级结构进行分割,对文档解析的能力要求较高,分割效果优于按字符数切割;
-
按语义分割:需要结合模型能力对文档内容加以理解,并按语义进行分割和拼接,分割效果好,但是技术难度较大。
LangChain提供了很多文本分割工具,以下是一些示例:
-
RecursiveCharacterTextSplitter():按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。LangChain默认使用该方法。
-
CharacterTextSplitter():按字符来分割文本。
-
MarkdownHeaderTextSplitter():基于指定的标题来分割markdown 文件。
-
TokenTextSplitter():按token来分割文本。
从目前观察到已产品化的分割模块来看,主要使用的方法还是按字符数和段落进行分割。选择按字符数分割,用户可定义分割的字符串长度以及分块后字符串的重叠长度;选择按段落分割,需要结合OCR能力方可实现。
2.3 微调数据格式统一
大模型或embedding模型的微调并非必需,如需进行微调,那么用于微调的数据需按照模型和任务要求进行格式统一。
以下示例由ChatGPT生成,可以直观地感受一下其中的差异。如:
文本分类任务
-
输入格式: 通常是文本数据,可以是句子、段落或文档。
-
标签格式: 标签通常是类别标识,可以是单一类别或多类别。
-
样本格式示例:
Text Label
"This is a positive sentence." Positive
"Negative sentiment in this text." Negative
"Neutral statement here." Neutral
问答类任务
数据通常包括问题和相应的答案,当需要结合上下文信息理解问题语境时,通常还需要加上上下文信息,样本格式示例:
Context Question Answer
"The Eiffel Tower is located in Paris." "Where is the Eiffel Tower?" "Paris"
"There are nine planets in our solar system, including Earth."
"How many planets are there?" "Nine"
"William Shakespeare, a famous playwright, wrote 'Romeo and Juliet'."
"Who is the author of this play?" "William Shakespeare"
"Guacamole is a popular Mexican dish made with mashed avocados."
"What is the main ingredient?" "Avocado"
3. 建立向量索引
将文档分块以后,通常需要对每个分块建立索引用于后续的检索。
常见的建立索引的方法如下:
-
链式索引:通过链表结构对文本块进行顺序索引。
-
树索引:将文本块构建成具有层级的树状索引结构,检索时无需像链式索引一样按顺序查询。
-
关键词表索引:从文档块中提取关键词,构建关键词和文档块之间的多对多映射,检索时金鱼关键词对文档块进行筛选。
-
向量索引:将文本块映射成向量以后,通过相似度计算的方法进行查询。
其中,建立向量索引是当下最为流行的一种方法。首先,通过embedding模型将高维度的数据映射到低维空间生成向量表示,再对这些向量进行索引和搜索。
embedding模型需要根据任务的性质和输入数据的特点进行选择。以文本嵌入为例,早期的有Word2Vec、GloVe等模型,现在常用的有 Sentence Transformers、OpenAI的text-embedding-ada-002等。为了更好地匹配数据类型和任务性质,还需要对embedding模型进行微调处理。
为分块的文档生成向量表示后,通常采用相似度检索的方式进行查询,可以采用内积、欧式距离、余弦距离等方法,其中余弦距离最为常用。
在实际应用中,建立向量索引和查询存在以下需要考虑的问题,可能并不全面,提出来供大家讨论:
1、向量化以后的数据膨胀问题
2、大规模向量相似性检索的效率问题
4. 大模型选择与微调
目前已经开源的大模型项目有很多,如何选择适合的大模型,可结合任务类型、算力水平等因素综合考虑。
如果基础预训练大模型无法满足在特定任务上的应用要求,还需要对模型进行微调。目前常用的高效微调方法主要有LoRA、P- Tuning、Prompt Tuning等,能够以较低的数据量,以及算力和时间的投入取得较好的微调效果。
完成大模型微调以后,可以结合任务要求选择适合的公开数据集进行测评,以验证微调效果。
二、开源知识库项目
1. FastGPT
FastGPT是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。项目地址:https://github.com/labring/FastGPT。
功能架构图如下。可以看到,FastGPT可接入多种LLM,将存入知识库的知识处理为QA对或问题的形式,向量化后存入数据库。对话时将提问内容向量化,在数据库中进行向量相似性搜索,将搜索到的内容发送给LLM进行输出。
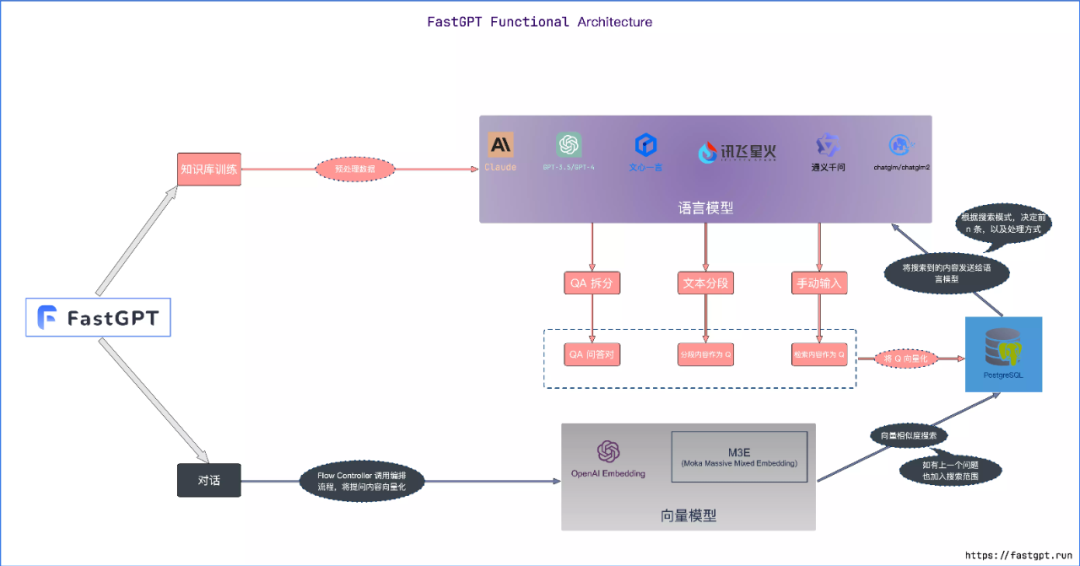
应用FastGPT时,首先要创建一个知识库,在知识库中上传文档后自动生成QA对或分块,然后再创建一个对话式的应用并与创建的知识库相关联,这样大模型在回答时就能够应用到我们创建的知识库中的知识。
2. Anything LLM
Anything LLM是一个开源的企业智能知识库解决方案,能够通过聊天的形式,快速地获取曾经喂给它的任何信息。
目前可以通过https://useanything.com/免费试用。
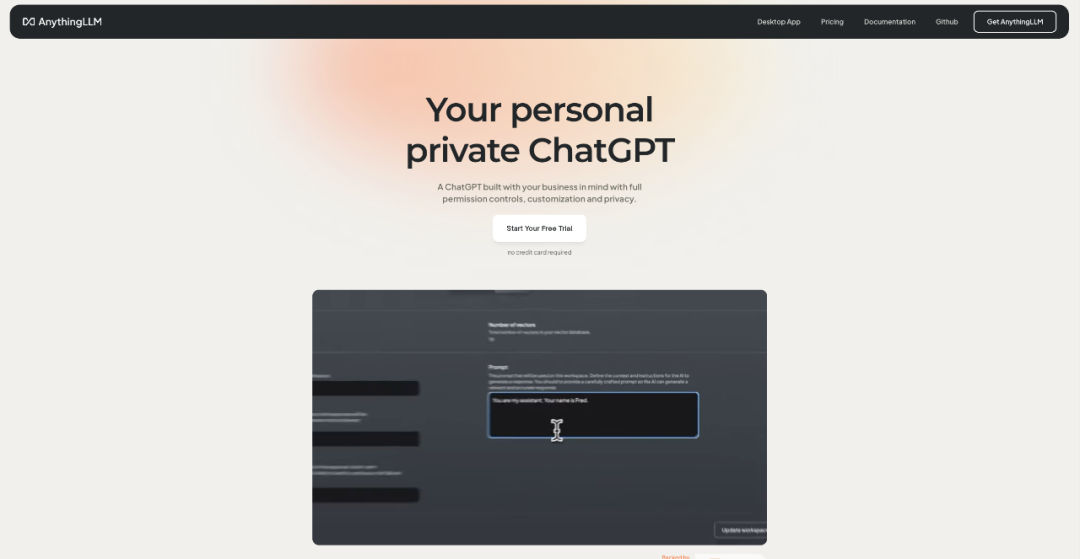
使用步骤
-
选择使用的大模型:目前提供OpenAI,Azure OpenAI和Anthropic Claude 2三种大模型可供选择,后续的版本中将允许用户使用自己的大模型;
-
选择向量数据库:目前提供Chroma、Pinecone、Qdrant、Weaviate和LanceDB,默认使用LanceDB;
-
可定制界面和使用方式:用户可自定义logo;支持个人使用or团队使用,进行相关配置即可;
-
创建workspace:用于上传与LLM对话时需要用到的文档;上传的文档可以在多个workspace中进行复用。在workspace中可定义“temperature”这个参数,它主要影响LLM回答的随机性和创造性;此外,可以配置展示历史对话的个数,以及自定义对话的prompt。
-
进行对话:对话时大模型能够根据上传的文档进行回答,并展示引用的文档以及具体段落,确保回答可信可溯源。
3. LangChain-Chatchat
LangChain-Chatchat(原LangChain-ChatGLM),基于ChatGLM等大模型与LangChain等应用框架实现,是一款开源、可离线部署的RAG大模型知识库项目,能够解决数据安全保护、私域化部署的企业痛点。
实现原理如下图所示。过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
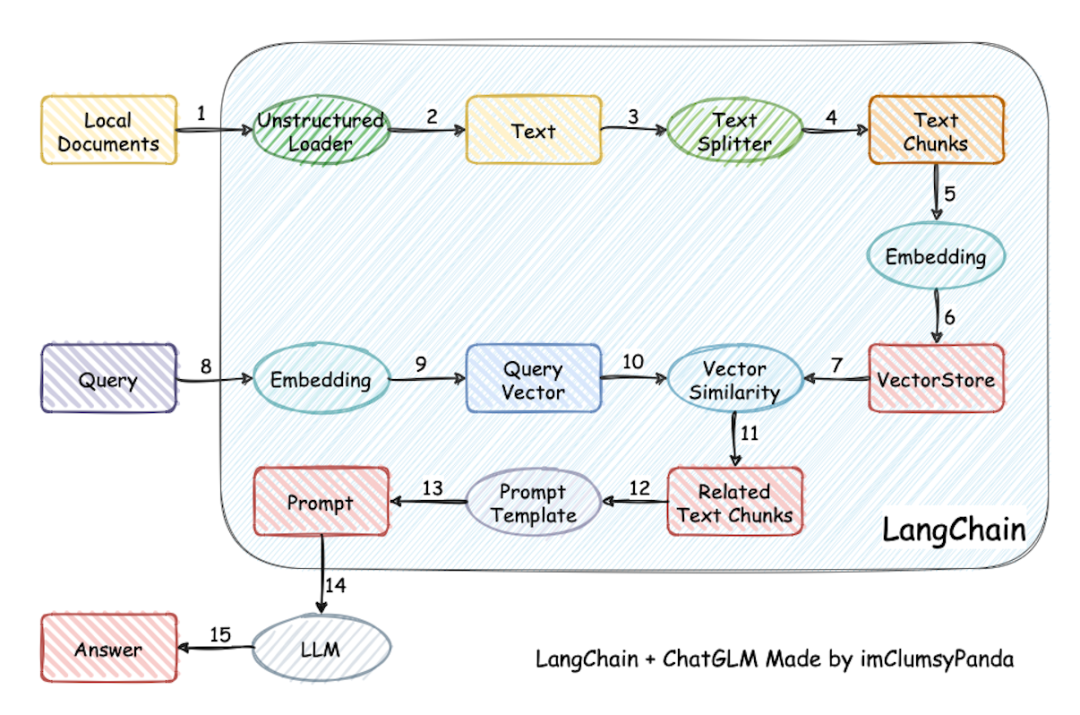
在最佳实践中推荐的模型组合如下,用户也可以根据需要自由选择,目前项目支持的大模型、向量数据库、开源embedding模型等非常丰富,可通过官方wiki进行查看。
LLM: Chatglm2-6b
Embedding Models: m3e-base
TextSplitter: ChineseRecursiveTextSplitter
Kb_dataset: faiss
结语
基于RAG与LLM的知识库作为目前最有潜力的企业端大模型应用之一,从技术角度可以看到,建设方案已经完备;从业务角度,最终的应用效果和业务价值还需要观察,并通过业务侧的反馈不断地促进建设方案的进一步优化,比如增加对多模态知识的处理能力等。让我们共同期待这类应用普及那一天的到来。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









