






LLaMA-Factory
如何高效地微调和部署大型语言模型(LLM)? LLaMA-Factory作为一个开源的微调框架,应运而生,为开发者提供了一个简便、高效的工具, 以便在现有的预训练模型基础上,快速适应特定任务需求,提升模型表现。 LLaMA-Factory作为一个功能 强大且高效的 大模型微调框架 ,通过其用户友好的界面和丰富的功能特性,为开发者提供了极大的便利。

LLaMA-Factory
一、LLaMA-Factory
什么是LLaMA-Factory? LLaMA-Factory,全称Large Language Model Factory,即大型语言模型工厂。它支持 多种预训练模型和微调算法 ,提供了一套完整的工具和接口,使得用户能够轻松地对 预训练的模型进行定制化的训练和调整,以适应特定的应用场景,如智能客服、语音识别、机器翻译 等。

LLaMA-Factory
-
支持的模型:LLaMA-Factory支持多种大型语言模型,包括但不限于LLaMA、BLOOM、Mistral、Baichuan、Qwen、ChatGLM等。
-
集成方法:包括(增量)预训练、指令监督微调、奖励模型训练、PPO训练、DPO训练和ORPO训练等多种方法。
-
运算精度与优化算法:提供32比特全参数微调、16比特冻结微调、16比特LoRA微调和基于AQLM/AWQ/GPTQ/LLM.int8的2/4/8比特QLoRA微调等多种精度选择,以及GaLore、DoRA、LongLoRA、LLaMA Pro、LoRA+、LoftQ和Agent微调等先进算法。
LLaMA-Factory
LLaMA-Factory提供了简洁明了的操作界面和丰富的文档支持,使得用户能够轻松上手并快速实现模型的微调与优化。 用户可以根据自己的需求选择不同的模型、算法和精度进行微调,以获得最佳的训练效果。

LLaMA-Factory
二、模型微调(Fine-Tuning)
如何使用LLaMA-Factory进行模型微调?使用LLaMA-Factory进行模型微调是一个涵盖从选择模型、数据加载、参数配置到训练、评估优化直至部署应用 的全面且高效的流程。
1. 选择模型:根据应用场景和需求选择合适的预训练模型。
-
设置语言: 进入WebUI后,可以切换到中文(zh)。
-
配置模型: 选择LLaMA3-8B-Chat模型。
-
配置微调方法: 微调方法则保持默认值lora,使用LoRA轻量化微调方法能极大程度地节约显存。

2. 加载数据:将准备好的数据集加载到LLaMA-Factory中。
- LLaMA-Factory项目内置了丰富的数据集,放在了
data目录下。同时也可以自己准备自定义数据集,将数据处理为框架特定的格式,放到指定的data目录下。

3. 配置参数:根据实际情况调整学习率、批次大小等训练参数。
-
学习率+梯度累积: 设置学习率为1e-4,梯度累积为2,有利于模型拟合。
-
计算类型: 如果是NVIDIA V100显卡,计算类型保持为fp16;如果使用了AMD A10系列显卡,可以更改计算类型为bf16。

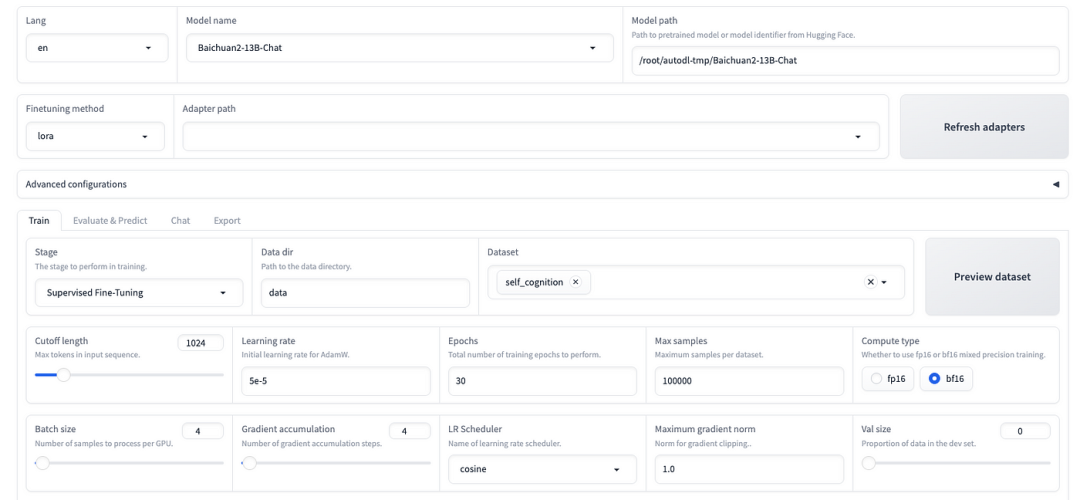
- LoRA参数设置: 设置LoRA+学习率比例为16,LoRA+被证明是比LoRA学习效果更好的算法。在LoRA作用模块中填写all,即将LoRA层挂载到模型的所有线性层上,提高拟合效果。
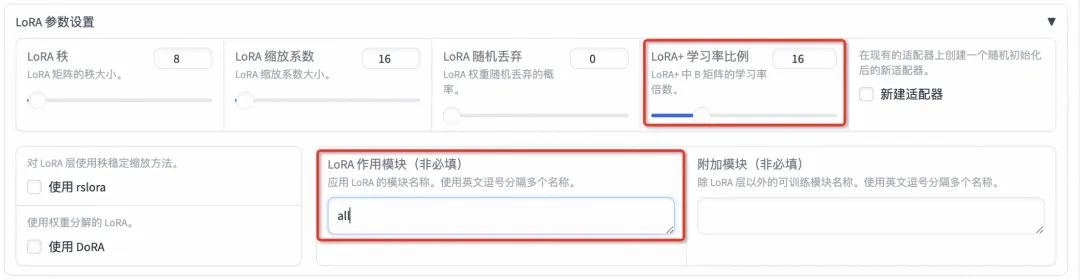
4. 开始训练:启动训练过程,并监控模型的训练进度和性能表现。
-
输出目录:将输出目录修改为train_llama3,训练后的LoRA权重将会保存在此目录中。
-
预览命令: 点击「预览命令」可展示所有已配置的参数,如果想通过代码运行微调,可以复制这段命令,在命令行运行。
-
开始: 点击「开始」启动模型微调。
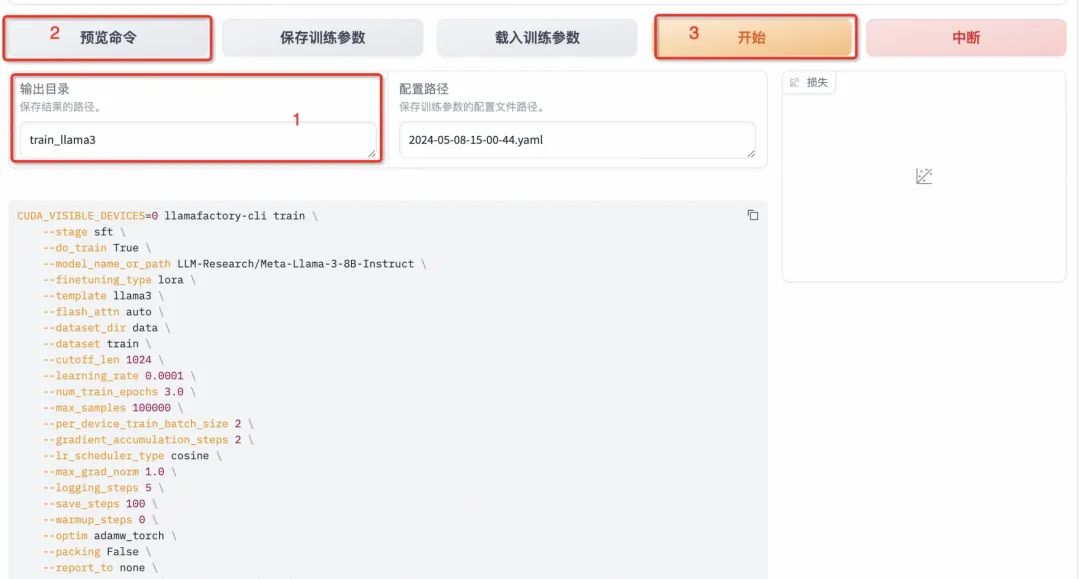
- 训练完毕: 启动微调后需要等待一段时间,待模型下载完毕后可在界面观察到训练进度和损失曲线。模型微调大约需要20分钟,显示“训练完毕”代表微调成功。
5. 评估与优化:使用LLaMA-Factory提供的评估工具对模型性能进行评估,并根据评估结果进行针对性的优化。
-
刷新适配器: 微调完成后,点击页面顶部的「刷新适配器」
-
适配器路径: 点击适配器路径,即可弹出刚刚训练完成的LoRA权重,点击选择下拉列表中的train_llama3选项,在模型启动时即可加载微调结果。

-
评估模型: 选择「Evaluate&Predict」栏,在数据集下拉列表中选择「eval」(验证集)评估模型。
-
输出目录: 更改输出目录为
eval_llama3,模型评估结果将会保存在该目录中。 -
开始评估: 最后点击开始按钮启动模型评估。

-
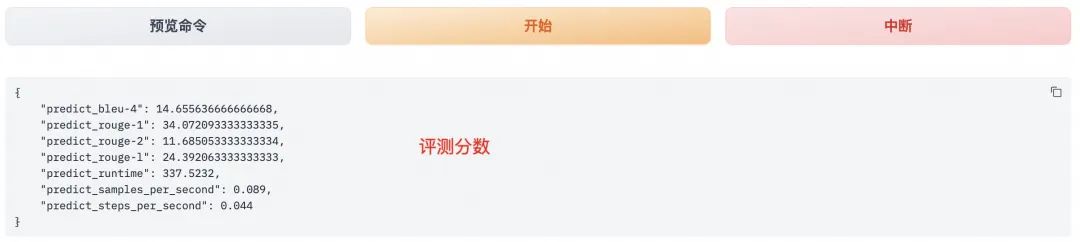
评估分数: 模型评估大约需要5分钟左右,评估完成后会在界面上显示验证集的分数。
-
ROUGE分数: 其中ROUGE分数衡量了模型输出答案(predict)和验证集中标准答案(label)的相似度,ROUGE分数越高代表模型学习得更好。
6. 部署应用:将训练好的模型部署到实际应用场景中,实现其功能和价值。
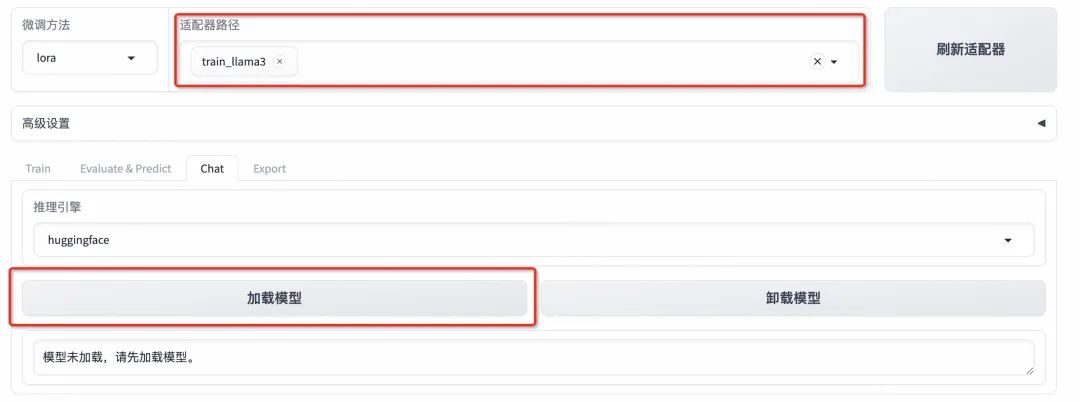
- **加载模型:**选择「Chat」栏,确保适配器路径是
train_llama3,点击「加载模型」即可在Web UI中和微调模型进行对话。
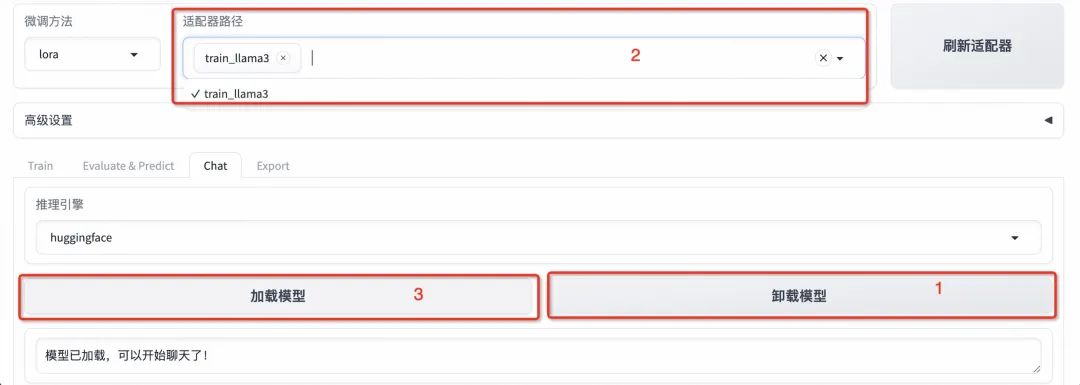
- 卸载模型: 点击「卸载模型」,点击“×”号取消适配器路径,再次点击「加载模型」,即可与微调前的原始模型聊天。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









