







/
hash:音译哈希,意译散列,用于在规定大小的表中,快速插入和查找数据。
构造哈希表的几种方法:
1.直接定址法(取关键字的某个线性函数为哈希地址)
2.除留余数法(取关键值被某个不大于散列表长m的数p除后的所得的余数为散列地址)
3.平方取中法(关键字平方后,取中间一段数字)
4.折叠法
5.随机数法
6.数学分析法
常用方法是直接定址法和除留余数法
一般做的题目都是喜欢自己写哈希的,简单而且好控制因为题目要求。直接定址题目一般会给你方法的,在此讲余数法。
冲突处理
冲突处理分成大类和小类,大类为开散列方法( open hashing,也称为拉链法,separate chaining ) 和 闭散列方法( closed hashing,也称为开地址方法,open addressing )。
开散列我没写过,不提了,以后被坑可能会补。
闭散列最常用的两个:线性探测(Linear probing) 和 二次探测(Quadratic probing)。(英文苦逼注意下,沙雕博主看不懂二次和探测的英文,结果卡题卡半天啊。看下混个眼熟)
一、线性探测
key = Hash(key) + 1
key = Hash(key) + 2 以此类推。说明:hash(key)就是构造哈希的方法。
如果是余数法,而且是来回探测的话:
key =(Hash(key) + 1) % size
key =(Hash(key) - 2 + size) % size 以此类推
探测系数一直到size为止,那么也就是直到表满都放得下
二、二次探测
key = Hash(key) + 1*1
key = Hash(key) + 2*2 以此类推
如果是余数法,而且是来回探测的话:
key =(Hash(key) + 1*1) % size
key =(Hash(key) - 2*2 + size) % size 以此类推
探测系数一直到size为止,如果路上查到的key都有数据的话,那么这个数据无法放入(题目特殊要求按题目定)
命中计算
其实没什么难度,主要是被坑了不爽无能狂怒rua
按构表法和冲突处理法进行查找,没进行一次查找,查找次数+1,如果当前的查找那个位置是空的话,代表找不到,那么结束
如果冲突系数一直到size还没找到,那么超过size的那次判断也算作一次查找
//msize是表的容量
for(j=0;j<msize;j++) {
cnt++;
//没有找到或者找到了都算结束了
if(a[(x%msize + j*j) % msize] == 0) break;
if(a[(x%msize + j*j) % msize] == x) break;
}
//冲突处理完的这个判断,也算一次查找
if(j == msize) cnt++;
//除以总数,算平均值
printf("%.1lf\n",cnt*1.0/m);
其实这个命中率并没有什么明确的规定,在此提出只是表示 “啊,这么狗的命中率也有啊” 的感想。刷题时(不管是比赛还是测试),都要随机应变,依靠样例去猜出题人的想法,今天可能出界+1,明天就可能没查到不算一次查询。
//
构造哈希表之二次探测法
HashTable-散列表/哈希表
是根据关键字(key)而直接访问在内存存储位置的数据结构。
它通过一个关键值的函数将所需的数据映射到表中的位置来访问数据,这个映射函数叫做散列(哈希)函数,存放记录的数组叫做散列表。
构造哈希表的几种方法
1.直接定址法(取关键字的某个线性函数为哈希地址)
2.除留余数法(取关键值被某个不大于散列表长m的数p除后的所得的余数为散列地址)
3.平方取中法
4.折叠法
5.随机数法
6.数学分析法
常用方法是 直接定址法和 除留余数法
哈希冲突/哈希碰撞
不同的Key值经过哈希函数Hash(Key)处理以后可能产生相同的值哈希地址,我们称这种情况为哈希冲突。任意的散列函数都不能避免产生冲突。
处理哈希碰撞的方法
若key1,key2,key3产生哈希冲突(key1,key2,key3值不相同,映射的哈希地址同为key),用以下方法确定它们的地址
1.闭散列法
1)线性探测
若当前key与原来key产生相同的哈希地址,则当前key存在该地址之后没有存任何元素的地址中
key1:hash(key)+0
key2:hash(key)+1
key3:hash(key)+2
例如:

2)二次探测
若当前key与原来key产生相同的哈希地址,则当前key存在该地址后偏移量为(1,2,3...)的二次方地址处
key1:hash(key)+0
key2:hash(key)+1^2
key3:hash(key)+2^2
例如:

2.开链法(哈希桶)
哈希表中保存包含每个key值的节点,每个节点有一个_next的指针,指向产生哈希冲突的key的节点
例如:

构建哈希表(二次探测法)
支持key值为字符串
<pre name="code" class="cpp">//HashTable.h
#pragma once
#include<iostream>
#include <string>
using namespace std;
enum State
{
EMPTY,//空
EXITS,//存在
DELETE//已删除
};
template<class K, class V>
struct HashTableNode
{
K _key;
V _value;
};
template<class K>
struct _HashFunc
{
size_t operator()(const K& key,const size_t& capacity)//哈希函数,仿函数
{
return key / capacity;
}
};
template<>
struct _HashFunc<string>//模板特化
{
private:
unsigned int _BKDRHash(const char *str)//key为字符串时哈希函数
{
unsigned int seed = 131; // 31 131 1313 13131 131313 etc..
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
public:
size_t operator()(const string& key,const size_t& capacity)//仿函数
{
return _BKDRHash(key.c_str()) % capacity;
}
};
template<class K, class V,class HashFunc=_HashFunc<K>>
class HashTable
{
typedef HashTableNode<K, V> Node;
public:
HashTable(size_t capacity = 10)
:_tables(new Node[capacity])
, _states(new State[capacity])
, _size(0)
, _capacity(capacity)
{}
~HashTable()
{
if (_tables != NULL)
{
delete[] _tables;
delete[] _states;
}
}
HashTable(const HashTable<K, V>& ht)
{
HashTable<K, V> tmp(ht._capacity);
for (size_t i = 0; i < ht._capacity; i++)
{
tmp.Insert(ht._tables[i]._key, ht._tables[i]._value);
}
this->Swap(tmp);
}
HashTable& operator=(HashTable<K, V> ht)
{
this->Swap();
return *this;
}
bool Insert(const K& key, const V& value)
{
_CheckCapacity();
size_t index = HashFunc()(key, _capacity);
size_t i = 1;
while (_states[index] == EXITS)//二次探测
{
if (_tables[index]._key == key)
{
return false;
}
index = index + 2 * i - 1;
index %= _capacity;
++i;
}
_tables[index]._key = key;
_tables[index]._value = value;
_states[index] = EXITS;
++_size;
return true;
}
bool Find(const K& key)
{
size_t index = HashFunc()(key, _capacity);
size_t start = index;
size_t i = 1;
while (_states[index] != EMPTY)//根据二次探测法查找
{
if (_tables[index]._key == key)
{
if (_states[index] != DELETE)
return true;
else
return false;
}
index = index + 2 * i - 1;
index %= _capacity;
if (start == index)
return false;
}
return false;
}
bool Remove(const K& key)
{
size_t index = HashFunc()(key, _capacity);
size_t start = index;
size_t i = 1;
while (_states[index] != EMPTY)//根据二次探测法删除
{
if (_tables[index]._key == key)
{
if (_states[index] != DELETE)
{
_states[index] = DELETE;
_size--;
return true;
}
else
return false;
}
index = index + 2 * i - 1;
index %= _capacity;
if (start == index)
return false;
}
return false;
}
void Print()
{
for (size_t i = 0; i < _capacity; i++)
{
//printf("%d-[%s:%s] \n", _states[i], _tables[i]._key, _tables[i]._value);
cout << _states[i] << " " << _tables[i]._key << " " << _tables[i]._value<<endl;
}
}
private:
void Swap(HashTable<K, V>& tmp)
{
swap(_tables, tmp._tables);
swap(_states, tmp._states);
swap(_size, tmp._size);
swap(_capacity, tmp._capacity);
}
void _CheckCapacity()//增容
{
if (_size * 10 / _capacity == 6)
{
HashTable<K, V> tmp(_capacity * 2);
for (size_t i = 0; i < _capacity; i++)
{
if (_states[i] == EXITS)
tmp.Insert(_tables[i]._key, _tables[i]._value);
}
this->Swap(tmp);
}
}
private:
Node* _tables;//哈希表
State* _states;//状态表
size_t _size;
size_t _capacity;
};
</pre><pre code_snippet_id="1711228" snippet_file_name="blog_20160608_3_3809584" name="code" class="cpp">//test.cpp
#include<iostream>
#include "HashTable.h"
void testInt()
{
HashTable<int, int> table(10);
table.Insert(89, 89);
table.Insert(18, 18);
table.Insert(49, 49);
table.Insert(58, 58);
table.Insert(9, 9);
//table.Insert(45, 45);
//table.Insert(2, 2);
table.Print();
HashTable<int, int> table1(table);
table1.Print();
bool ret = table.Find(9);
cout << endl << ret << endl;
table.Remove(9);
table.Print();
}
void TestString()
{
HashTable<string, string> table(10);
table.Insert("dict", "字典");
table.Insert("hash", "哈希");
table.Insert("function", "函数");
table.Insert("abcd", "函数");
table.Insert("dcba", "函数");
table.Print();
bool ret = table.Find("function");
cout << endl << ret << endl;
table.Remove("hash");
table.Print();
}
int main()
{
//testInt();
TestString();
getchar();
return 0;
}
测试结果:
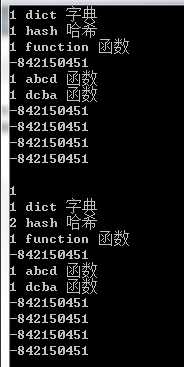
/
构造哈希表之开链法(哈希桶)
描述一下哈希桶的基本原理:
哈希表中保存包含每个key值的节点,每个节点有一个_next的指针,指向产生哈希冲突的key的节点
#pragma once
#include<iostream>
#include<vector>
#include<string>
using namespace std;
template<class K>
struct _HashFunc
{
size_t operator()(const K& key,size_t capacity)
{
return key%capacity;
}
};
template<>
struct _HashFunc<string>//string类特化
{
static size_t _BKDRHash(const char * str)
{
unsigned int seed = 131; // 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
size_t operator()(const string& key, size_t capacity)
{
return _BKDRHash(key.c_str()) % capacity;
}
};
template<class K,class V>
struct HashTableNode
{
HashTableNode(const K& key, const V& value)
:_key(key)
, _value(value)
,_next(NULL)
{}
K _key;
V _value;
HashTableNode<K,V>* _next;
};
const int _PrimeSize = 28;
const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};//素数表,将哈希表容量控制为素数,使用素数做除数可以减少哈希冲突
template<class K, class V, class HashFunc = _HashFunc<K> >
class HashTable
{
public:
typedef HashTableNode<K, V> Node;
HashTable(const HashTable<K,V>& ht)
:_size(0)
{
_tables.resize(ht._tables.size());
for (size_t i = 0; i < ht._tables.size(); i++)
{
Node* cur = ht._tables[i];
while (cur)
{
Insert(cur->_key, cur->_value);
cur = cur->_next;
_size++;
}
}
}
HashTable& operator=(HashTable<K, V> ht)
{
swap(_tables, ht._tables);
return *this;
}
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* del = cur;
cur = cur->_next;
delete del;
}
}
}
HashTable(const size_t& capacity)
:_size(0)
{
_tables.resize(_GetCapacity(0));
}
bool Insert(const K& key,const V& value)
{
_CheckCapacity();
size_t index = HashFunc()(key,_tables.size());
Node* cur = _tables[index];
while (cur)
{
if (cur->_key == key)
return false;
cur = cur->_next;
}
Node* NewNode = new Node(key, value);
NewNode->_next = _tables[index];
_tables[index] = NewNode;
_size++;
}
Node* Find(const K& key)
{
size_t index = HashFunc()(key, _tables.size());
Node* cur = _tables[index];
while (cur)
{
if (cur->_key == key)
return cur;
cur = cur->_next;
}
return NULL;
}
bool Remove(const K& key)
{
size_t index = HashFunc()(key, _tables.size());
Node* cur = _tables[index];
if (cur == NULL)
return false;
if (cur->_key == key && cur)
{
_tables[index] = cur->_next;
delete cur;
cur = NULL;
return true;
}
Node* prev = NULL;
while (cur)
{
prev = cur;
cur = cur->_next;
if (cur->_key == key)
{
prev->_next = cur->_next;
delete cur;
return true;
}
}
return false;
}
void Print()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
cout << cur->_key << ":" << cur->_value << "->";
cur = cur->_next;
}
cout << "NULL" << endl;
}
}
private:
void _CheckCapacity()
{
if (_size == _tables.size())
{
size_t capacity = _GetCapacity(_size);
vector<Node*> tab;
tab.resize(capacity);
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* tmp = cur;
cur = cur->_next;
size_t index = HashFunc()(tmp->_key, tab.size());
tmp->_next = tab[index];
tab[index] = tmp;
}
_tables[i] = NULL;
}
_tables.swap(tab);
}
}
size_t _GetCapacity(const size_t& capacity)
{
for (size_t i = 0; i<_PrimeSize; i++)
{
if (capacity < _PrimeList[i])
return _PrimeList[i];
}
}
private:
vector<Node*> _tables;
size_t _size;
};
#include"HashTableBucket.h"
void TestInt()
{
HashTable<int, int> tab(10);
tab.Insert(51,51);
tab.Insert(105,105);
tab.Insert(52,52);
tab.Insert(3,3);
tab.Insert(55,55);
tab.Insert(2,2);
tab.Insert(106,106);
tab.Insert(53,53);
tab.Insert(0,0);
/*for (int i = 0; i < 53; i++)
{
tab.Insert(i,i);
}
tab.Insert(54,54);*/
tab.Print();
//HashTable<int, int> ht(tab);
HashTable<int, int> ht(tab);
ht = tab;
/*HashTableNode<int,int>* node=tab.Find(54);
cout << node->_key << " " << node->_value << endl;*/
cout << ":------------" << endl;
/*tab.Remove(0);
tab.Print();*/
ht.Print();
}
void TestString()
{
HashTable<string, string> ht(0);
ht.Insert("hhh","jjjj");
ht.Insert("het", "haxi");
ht.Insert("kk", "kkkk");
HashTableNode<string, string>* node=ht.Find("het");
ht.Print();
cout << node->_key<< node->_value << endl;
}
int main()
{
//TestInt();
TestString();
getchar();
return 0;
}
/















 4448
4448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









