






//
BatchRendererGroup
Description
A group of batches.
Represents a container for multiple batches that share the same culling method. See Also: OnPerformCulling
BatchRendererGroup is an experimental API originally designed for DOTS Hybrid Renderer use only. This API is under construction and several public methods will be deprecated. The goal is to improve the API to make it usable for more than just the DOTS Hybrid Renderer. The current API is going be replaced with a new API in 2022.1.
Constructors
| BatchRendererGroup | Creates a new BatchRendererGroup. |
Public Methods
| AddBatch | Adds a new batch to the group. |
| Dispose | Deletes a group. |
| EnableVisibleIndicesYArray | Enables or disables BatchCullingContext.visibleIndicesY. |
| GetBatchMatrices | Retrieves the matrices associated with one batch. |
| GetBatchMatrixArray | Retrieves an array of instanced vector properties for a given batch. |
| GetBatchScalarArray | Retrieves an array of instanced float properties for a given batch. |
| GetBatchScalarArrayInt | Retrieves an array of instanced int properties for a given batch. |
| GetBatchVectorArray | Retrieves an array of instanced vector properties for a given batch. |
| GetBatchVectorArrayInt | Retrieves an array of instanced int vector properties for a given batch. |
| GetNumBatches | Retrieves the number of batches added to the group. |
| RemoveBatch | Removes a batch from the group. Note: For performance reasons, the removal is done via emplace_back() which will simply replace the removed batch index with the last index in the array and will decrement the size. If you're holding your own array of batch indices, you'll have to either regenerate it or apply the same emplace_back() mechanism as RemoveBatch does. |
| SetBatchBounds | Sets the bounding box of the batch. |
| SetBatchFlags | Sets flag bits that enable special behavior for this Hybrid Renderer V2 batch. |
| SetBatchPropertyMetadata | Sets all Hybrid Renderer DOTS instancing metadata for this batch, and marks it as a Hybrid Renderer V2 batch. |
| SetInstancingData | Updates a batch. |
Delegates
| OnPerformCulling | Culling callback function. |
///
How should i work with BatchRendererGroup
-
using System;
-
using System.Collections.Generic;
-
using Unity.Burst;
-
using Unity.Collections;
-
using Unity.Jobs;
-
using Unity.Mathematics;
-
using UnityEngine;
-
using UnityEngine.Rendering;
-
public class BatchRenderer : MonoBehaviour
-
{
-
[SerializeField] private GameObject[] prefabs;
-
[SerializeField] private int split = 10;
-
private BatchRendererGroup _batchRendererGroup;
-
private JobHandle _jobDependency;
-
private List<int> _batchIndex;
-
private void OnEnable()
-
{
-
_batchRendererGroup = new BatchRendererGroup(CullingCallback);
-
_batchIndex = new List<int>(10);
-
foreach (var prefab in prefabs)
-
SetupBatch(prefab);
-
-
}
-
private static Mesh GetMesh(Component renderer)
-
{
-
if (renderer is MeshRenderer)
-
return renderer.GetComponent<MeshFilter>().sharedMesh;
-
-
var meshRenderer = renderer as SkinnedMeshRenderer;
-
if (meshRenderer != null)
-
return meshRenderer.sharedMesh;
-
throw new InvalidOperationException();
-
}
-
private void SetupBatch(GameObject prefab)
-
{
-
var materials = new List<Material>(10);
-
var renderers = prefab.GetComponentsInChildren<Renderer>();
-
foreach (var renderer in renderers)
-
{
-
renderer.GetSharedMaterials(materials);
-
-
var mesh = GetMesh(renderer);
-
foreach (var material in materials)
-
{
-
_batchIndex.Add(_batchRendererGroup.AddBatch(
-
mesh,
-
0,
-
material,
-
0,
-
ShadowCastingMode.Off,
-
false,
-
false,
-
new Bounds(Vector3.zero, Vector3.one * float.MaxValue),
-
split * split * split,
-
null,
-
gameObject));
-
}
-
}
-
}
-
private void OnDisable()
-
{
-
_batchIndex.Clear();
-
_batchRendererGroup.Dispose();
-
}
-
private void Update()
-
{
-
_jobDependency.Complete();
-
var jobHandlers = new NativeList<JobHandle>(_batchIndex.Count, Allocator.Temp);
-
foreach (var batchIndex in _batchIndex)
-
{
-
jobHandlers.Add(new UpdateMatrixJob
-
{
-
Matrices = _batchRendererGroup.GetBatchMatrices(batchIndex),
-
Time = Time.time,
-
Split = split
-
}.Schedule(split * split * split, 16));
-
}
-
_jobDependency = JobHandle.CombineDependencies(jobHandlers);
-
jobHandlers.Dispose();
-
}
-
private JobHandle CullingCallback(BatchRendererGroup rendererGroup, BatchCullingContext cullingContext)
-
{
-
_jobDependency.Complete();
-
for (var batchIndex=0; batchIndex<cullingContext.batchVisibility.Length ; ++batchIndex)
-
{
-
var batchVisibility = cullingContext.batchVisibility[batchIndex];
-
for (var i = 0; i < batchVisibility.instancesCount; ++i)
-
{
-
cullingContext.visibleIndices[batchVisibility.offset + i] = batchVisibility.offset + i;
-
}
-
batchVisibility.visibleCount = batchVisibility.instancesCount;
-
cullingContext.batchVisibility[batchIndex] = batchVisibility;
-
}
-
return default;
-
}
-
[BurstCompile]
-
private struct UpdateMatrixJob : IJobParallelFor
-
{
-
public NativeArray<Matrix4x4> Matrices;
-
public float Time;
-
public float Split;
-
public void Execute(int index)
-
{
-
var id = new Vector3(index / Split / Split, index / Split % Split, index % Split);
-
Matrices[index] = Matrix4x4.TRS(id * 10,
-
quaternion.EulerXYZ(id + Vector3.one * Time),
-
Vector3.one);
-
}
-
}
-
}
Found your thread while searching for information on the BatchRendererGroup (there's so little information out there). I used your code as a base for mine, and after struggling for a while I think I finally got it working and I think I found your issue as well. Your culling is setting the incorrect index.
You're setting it like this:
cullingContext.visibleIndices[batchVisibility.offset + i] = batchVisibility.offset + i;
But it seems like the value that should be set is a local index for the batch. You shouldn't include batchVisibility.offset in the value set. It should be like this:
cullingContext.visibleIndices[batchVisibility.offset + i] = i;
My editor kept crashing and rendering in a strange manner before I found this out. I think there are no safety checks for incorrect indices, so the rendering was passed random memory that was out of bounds of the batch matrices.
I would advice against using BatchRendererGroup API. It's a very low level API that requires deep understanding of Unity shader system internals for correct use. More info here: https://docs.unity3d.com/Packages/c...rid@0.11/manual/batch-renderer-group-api.html
We are planning to heavily refactor the BatchRendererGroup API. Make it more user friendly and documented. This will however break backwards compatibility with the old API version. I would suggest waiting until we have landed this properly supported API version.
现在手游是越做越大,大世界似乎已经成为MMO游戏的基本配置了。然而,大世界需要解决的东西非常多,网上的资料也比较少,像Houdini这样制作大地形工作流这类的资料都非常少。前两年在知乎上写的那两篇大地形渲染的文章最近居然浏览量上涨,但是其实那些技术以及过时了,Unity近两年更新了很多很好用的功能。关于大地形这块的东西太多了,我只能挑些细枝末节的,网上资料比较少的东西写写。正好最近被关在家里,有时间研究一些东西。
好了,言归正传,今天研究的东西是这个BatchRendererGroup,这个在网上搜的话,基本就只有一篇Momo大神些的ECS渲染Sprite的资料,外网也多是跟ECS相关的东西,没人详细介绍这个是干什么的。由于使用ECS需要走ECS的BuildPipeLine,这点限制太大了,一个是牵扯到热更新问题,另一个是每个公司可能有自己的BuildPipeLine,这几乎是个致命性问题,其实BatchRendererGroup可以用在正常的Model,只要你的项目是URP的,就能正确使用。
那么使用这个的应用场景又是什么呢?在超大世界的概念火了之后,场景中的物体可能多得无法想象,有几十万个,加上草,植被这些可能甚至有上百万个,光是gameObject的资源占用就多得无法想象,在Unity支持GPUInstance和SRP Batch后,渲染批次倒是可以减少,不成问题,但是Cull一次,性能慢得你无法想象。那么,今天这个BatchRendererGroup就完美解决了这一问题,并且还带来了多线程做Cull和LOD的好处。
BatchRendererGroup使用非常简单,构造,AddBatch,GetBatchMatrices,就这三个接口就够了。
我们先来看构造函数。

这个构造函数,是传入一个Cull函数,这个Cull函数我们后面讲,大部分功能都在里边。
然后看看AddBatch,AddBatch的参数很多,大家可以参考Unity的文档。
大部分参数都是一目了然,我主要说几个需要注意的参数,一个是Bounds,这个的意思是用来控制这个Batch的显示和隐藏,他会跟相机做Cull运算,一般我们取你所有BoundingBox的合集。还有一个会填入MaterialPropertyBlock,这个可以用来做GPUInstance,传入Block变量在Shader中使用。
这里有个int返回值,这个相当于一把钥匙,标记当前Batch在BatchGroup的Index。
我们需要使用这个Index来用我们的第三个接口GetBatchMatrices,这个会获取矩阵列表,标记Mesh的Transform信息,我们需要往里填入矩阵。
接下来我们大部分工作都是在Cull里边进行了。
Cull的方法定义是这样的
JobHandle OnPerformCulling(BatchRendererGroup rendererGroup, BatchCullingContext cullingContext)
两个参数,BatchRendererGroup,这个就是你构造的那个Group,这个是用来区分可能你同一个Cull函数会生成多个Group,第二个BatchCullingContext,这个是你需要填入的Cull结果。BatchCullingContext有四个变量
//
// 摘要:
// Planes to cull against.
public readonly NativeArray<Plane> cullingPlanes;
//
// 摘要:
// See Also: LODParameters.
public readonly LODParameters lodParameters;
//
// 摘要:
// Visibility information for the batch.
public NativeArray<BatchVisibility> batchVisibility;
//
// 摘要:
// Array of visible indices for all the batches in the group.
public NativeArray<int> visibleIndices;前两个只读的变量是给我们的信息,第一个是相机的六个面,第二个是LOD参数,里边也是相机的参数,诸如正交还是透视,FOV这些。
下面两个参数是我们需要填入的Cull结果。
上面的是标记可视物体总数以及一些只读的信息,下面这个是可视物体的Index,标记第几个是可视的。
最关键的地方是这个可以返回一个JobHandle,也就是说可以利用Unity的JobSystem。
有了上面的理论基础,我们开始着手解决我们的问题。
以植被为例,思路是这样的:
我们把所有的植被信息,包括植被的平移,旋转,缩放,颜色(或其他GPUInstance的变量)Mesh,LodMesh,Lod信息,材质等等,保存成Asset,在游戏运行时,这部分GameObject就可以删掉了。
我们拿到Asset后开始构造RenderBatchGroup,通过Asset里的GPUInstance变量构建Block给Shader使用,然后将LodMesh和Mesh分别使用AddBatch添加,通过平移,旋转,缩放,构建矩阵填入Batch,剩下的工作就是在Cull多线程执行Cull工作了。Cull的原理也比较简单,一个是LOD决定显示哪一级,一个是视椎体裁剪。
基本就两个批次,当然这里得用强大的URP (SRP)Batch和GPUInstance配合使用。
namespace YY
{
using System;
using System.Collections.Generic;
using Unity.Burst;
using Unity.Collections;
using Unity.Jobs;
using Unity.Mathematics;
using Unity.Rendering;
using UnityEngine;
using UnityEngine.Jobs;
using UnityEngine.Rendering;
/// <summary>
/// The test script for batch render.
/// </summary>
public sealed class BatchRender : MonoBehaviour
{
[SerializeField]
private Mesh mesh;
[SerializeField]
private Mesh lowMesh;
[SerializeField]
private float lodDis;
[SerializeField]
private Material material;
public bool log = false;
private BatchRendererGroup batchRendererGroup;
NativeArray<CullData> cullData;
private void Awake()
{
batchRendererGroup = new BatchRendererGroup(this.OnPerformCulling);
cullData = new NativeArray<CullData>(25000, Allocator.Persistent);
for (int j = 0; j < 50; j++)
{
var pos = new float3[50];
var rot = new quaternion[50];
var scale = new float3[50];
for (int i = 0; i < 50; i++)
{
pos[i] = new float3(i * 2, 0, j*2);
rot[i] = quaternion.identity;
scale[i] = new float3(1.0f, 1.0f, 1.0f);
}
this.AddBatch(100*j, 50, pos, rot, scale);
}
}
public void AddBatch(int offset,int count,float3[] pos, quaternion[] rot, float3[] scale)
{
AABB localBond;
localBond.Center = this.mesh.bounds.center;
localBond.Extents = this.mesh.bounds.extents;
MaterialPropertyBlock block = new MaterialPropertyBlock();
var colors = new List<Vector4>();
for(int i=0;i<count;i++)
{
colors.Add(new Vector4(UnityEngine.Random.Range(0f,1f), UnityEngine.Random.Range(0f, 1f), UnityEngine.Random.Range(0f, 1f), UnityEngine.Random.Range(0f, 1f)));
}
block.SetVectorArray("_BaseColor", colors);
var batchIndex = this.batchRendererGroup.AddBatch(
this.mesh,
0,
this.material,
0,
ShadowCastingMode.On,
true,
false,
new Bounds(Vector3.zero, 1000 * Vector3.one),
count,
block,
null);
var matrices = this.batchRendererGroup.GetBatchMatrices(batchIndex);
for (int i=0;i< count; i++)
{
matrices[i] = float4x4.TRS(pos[i], rot[i], scale[i]);
var aabb = AABB.Transform(matrices[i], localBond);
cullData[offset + i] = new CullData()
{
bound = aabb,
position = pos[i],
minDistance = 0,
maxDistance = lodDis,
};
}
for (int i = 0; i < count; i++)
{
colors[i] = new Vector4(UnityEngine.Random.Range(0f, 1f), UnityEngine.Random.Range(0f, 1f), UnityEngine.Random.Range(0f, 1f), UnityEngine.Random.Range(0f, 1f));
}
block.SetVectorArray("_BaseColor", colors);
batchIndex = this.batchRendererGroup.AddBatch(
this.lowMesh,
0,
this.material,
0,
ShadowCastingMode.On,
true,
false,
new Bounds(Vector3.zero, 1000 * Vector3.one),
count,
block,
null);
matrices = this.batchRendererGroup.GetBatchMatrices(batchIndex);
for (int i = 0; i < count; i++)
{
matrices[i] = float4x4.TRS(pos[i], rot[i], scale[i]);
var aabb = AABB.Transform(matrices[i], localBond);
cullData[offset + count + i] = new CullData()
{
bound = aabb,
position = pos[i],
minDistance = lodDis,
maxDistance = 10000,
};
}
}
private void OnDestroy()
{
if (this.batchRendererGroup != null)
{
cullingDependency.Complete();
this.batchRendererGroup.Dispose();
this.batchRendererGroup = null;
cullData.Dispose();
}
}
JobHandle cullingDependency;
private JobHandle OnPerformCulling(
BatchRendererGroup rendererGroup,
BatchCullingContext cullingContext)
{
var planes = FrustumCullPlanes.BuildSOAPlanePackets(cullingContext.cullingPlanes, Allocator.TempJob);
var lodParams = LODGroupExtensions.CalculateLODParams(cullingContext.lodParameters);
var cull = new MyCullJob()
{
Planes = planes,
LODParams = lodParams,
IndexList = cullingContext.visibleIndices,
Batches = cullingContext.batchVisibility,
CullDatas = cullData,
};
var handle = cull.Schedule(100, 32, cullingDependency);
cullingDependency = JobHandle.CombineDependencies(handle, cullingDependency);
return handle;
}
struct CullData
{
public AABB bound;
public float3 position;
public float minDistance;
public float maxDistance;
}
[BurstCompile]
struct MyCullJob : IJobParallelFor
{
[ReadOnly] public LODGroupExtensions.LODParams LODParams;
[DeallocateOnJobCompletion] [ReadOnly] public NativeArray<FrustumCullPlanes.PlanePacket4> Planes;
[NativeDisableParallelForRestriction] [ReadOnly] public NativeArray<CullData> CullDatas;
[NativeDisableParallelForRestriction] public NativeArray<BatchVisibility> Batches;
[NativeDisableParallelForRestriction] public NativeArray<int> IndexList;
public void Execute(int index)
{
var bv = Batches[index];
var visibleInstancesIndex = 0;
var isOrtho = LODParams.isOrtho;
var DistanceScale = LODParams.distanceScale;
for (int j = 0; j < bv.instancesCount; ++j)
{
var cullData = CullDatas[index* 50 + j];
var rootLodDistance = math.select(DistanceScale * math.length(LODParams.cameraPos - cullData.position), DistanceScale, isOrtho);
var rootLodIntersect = (rootLodDistance < cullData.maxDistance) && (rootLodDistance >= cullData.minDistance);
if (rootLodIntersect)
{
var chunkIn = FrustumCullPlanes.Intersect2NoPartial(Planes, cullData.bound);
if (chunkIn != FrustumCullPlanes.IntersectResult.Out)
{
IndexList[bv.offset + visibleInstancesIndex] = j;
visibleInstancesIndex++;
}
}
}
bv.visibleCount = visibleInstancesIndex;
Batches[index] = bv;
}
}
}
}///
The goal of this post is to look at the new BatchRendererGroup API (BRG) and implement the minimal BRG example, so it is easier to understand how to work with it. Then gradually add more complex functionality. In the end, we would have this boids simulation rendered using BRG:
1. Simple Example
As a starting point, we can use the example provided by Unity Technologies. Firstly, I decided to strip it down to the bare minimum in order to better control and debug how everything is stored in the memory so BRG API can process it. So I removed the custom struct PackedMatrix from Unity’s sample, as well as color to simplify the data buffer, here you can check the diff how I simplified it. Also, you can copy-paste the entire file from the gist SimpleBRGExample.cs.
Unity’s example uses PackedMatrix to pack data, I used float3x4 to represent data in my example. An important point to know is how BRG expects data to be sequenced. PackedMatrix as well as float3x4 stores data in the following order (“c” means column):
|
|
Another important thing to know is how to calculate GPU addresses of our arrays inside GraphicsBuffer.
The first 64 bytes are zeroes, so loads from address 0 return zeroes. This is a BatchRendererGroup convention.
Then 32 uninitialized bytes to make working with GraphicsBuffer.SetData easier, otherwise unnecessary. In the boids example we will get back to this and see that we can write data right at address 64, omitting uninitialized area.
After that, there is the first array float3x4[] _objectToWorld, since there is only one instance in this array then its size is (sizeof(float) * 3 * 4) = 48 bytes.
And another float3x4[] _worldToObject in the end.
So each array goes one after another. If we had to render 2 meshes, then the size of _objectToWorld will be 48 * 2, therefore GPU address of _worldToObject would be offset further by additional 48 bytes for each additional instance.
These addresses are used to SetData and for MetadataValue.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
Calculated addresses are divided by the size of a 3×4 matrix. I think it is done that way because if decompiled inside SetData we can see that they use Marshal.SizeOf(data.GetType().GetElementType()), which is used in the external call to multiply the passed address and then used as an offset in GraphicsBuffer. So that’s why we need to divide it on our side.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
So these 2 matrices are the minimum data needed to render a mesh properly.

Without inverse matrix, the mesh would be rendered, but without any color or lighting applied.
Apart from these points, there are not so many changes to Unity’s example. OnPerformCulling is grabbed completely unchanged. Again you can grab the source code to play around with the minimal sample here: SimpleBRGExample.cs
2. Simple Movement
Now let’s add movement to the rendered mesh. We need some more serialized fields to control the movement via the inspector:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
And recalculate the position every frame using the cosine function and adding it to the current position to create a simple wobbly movement with the mesh. Then just call _instanceData.SetData to update the data in GraphicsBuffer with arrays containing the new position and it’s inverse the same way as in the Start():
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
3. Multiple objects
Let’s further increase the example’s complexity and render more than one object on the screen. Add a new serialized field to control the amount of objects and update initialization to generate that amount of matrices, as well as calculate correctly the address of the _worldToObject array with a new offset based on the amount of matrices inside _objectToWorld array:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
|
And of course, we need to adjust UpdatePositions method to use an indexer instead of 0:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
Let’s also modify spawn positions, so we can actually see a big amount of meshes on the screen at the same time by using a handy Random.onUnitSphere property and a _radius field. This will give us all meshes being uniformly spread around the sphere.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
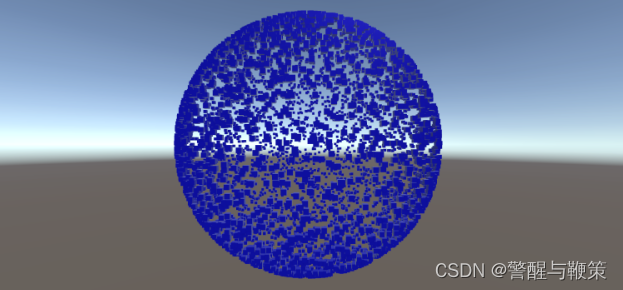
Here you can grab the full source code of the modified simple example: SimpleBRGExample.cs @GitHub
Now let’s move on to the more practical example.
4. Boids
4.1 Render Boids
As calculating boids movement is not the topic of this post, I used this boids repository by ThousandAnt. It uses the Job System + Burst. What is more, it provides boids examples made with GameObjects and Instancing, which comes quite handy to compare both variants with BRG. However, for me this boids solution turned out to be kinda fragile, as even little performance dips or interaction with the editor breaks the _centerFlock pointer, leaves it as (NaN, NaN, NaN) and boids stop working. So in the editor I was able to test only up to 2k objects and 1k in deep profiling. I was mostly writing my code while testing with 2 instances for easier debugging, so when I had found out about this issue, I was too lazy to find a new boids lib and redo BRG variant again. Anyway, it was enough to make a conclusion, so let’s go ahead.
As I was investigating other examples provided by Unity in parallel, the boids renderer is based on another code from Unity’s graphics repository. And this is great because we can see here different approaches of packing data for BRG.
A simple example uses PackedMatrix or float3x4 to represent data. And the boids example uses just a NativeArray<Vector4>. So don’t forget how data should be stored by columns as discussed in Part 1.
It is a very important point to know how sequentially your data should be packed, nevertheless, it is float, float4, float3x4, or any other type you decided to use.
You can check the full initial version of BatchRenderGroupBoidsRunner.cs @gist.github.com or let’s break it down right here.
My class extends Runner provided by boids repo and contains settings for boids simulation. We also need to declare the following private fields:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
Then we have to init BRG, as well as boids in the Start method. The BRG init is similar to the one provided in the simple example, with a small difference. Here we use a single NativeArray<Vector4> _dataBuffer instead of separate arrays with _worldToObject and _objectToWorld matrices. The boids init is taken from examples provided in the boids repo.
To increase readability it is better to extract these 2 inits into separate methods.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
|
In Update we complete the previously scheduled job, update _dataBuffer and GraphicsBuffer, and schedule new jobs to simulate boids.
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
4.2 BRG vs GameObjects
Firstly, let’s compare BRG boids to GameObjects implementation, which is available in the ThousandAnt repo. This example is great as boids calculation is jobified using IJobParallelFor, as well as TransformAccessArray is used, which significantly improves performance of updating a bunch of transforms. I used 2000 instances for this test.
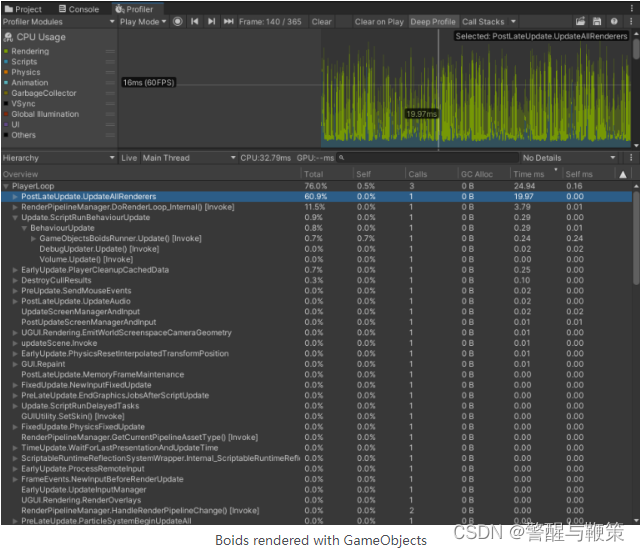
BRG here is the clear winner. Not only does it render faster, but it also doesn’t have the problem of a big amount of transforms that are recalculated every frame in PostLateUpdate.UpdateAllRenderers, which is jobified internally, but still slow when every transform is changing every frame, even though all game objects are created in the root of the scene, so they are processed in the most optimal way (I have mentioned this point in another blog post with awesome performance tips by engineers from Unity).
Rendering of GameObjects is also slower, while Update of all these transforms positions is lightning fast because TransformAccessArray and jobs are used here. Update() of BRG runner is a lot slower though: 3.67ms vs 0.24ms for GameObjects implementation. But we will get to it later running deep profiler.
4.3 BRG vs Instancing
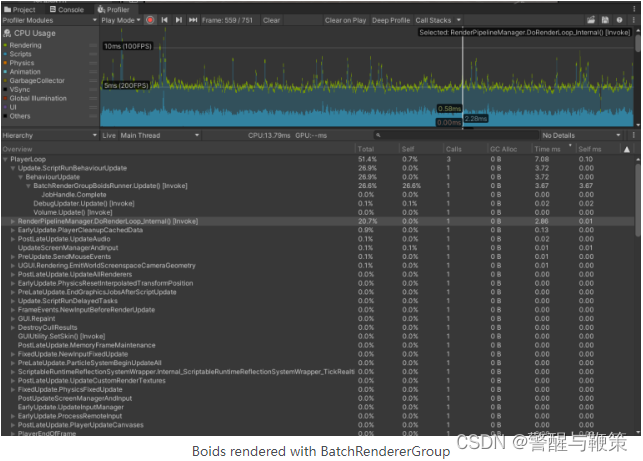
Now let’s compare BRG to Instancing, provided by the boids lib author. Again I am using 2000 instances for this test.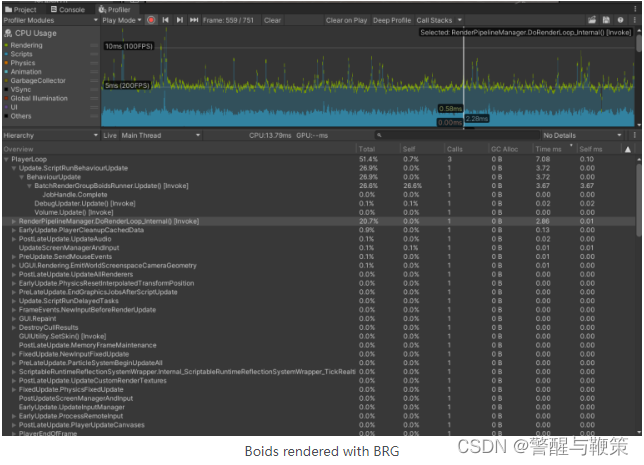
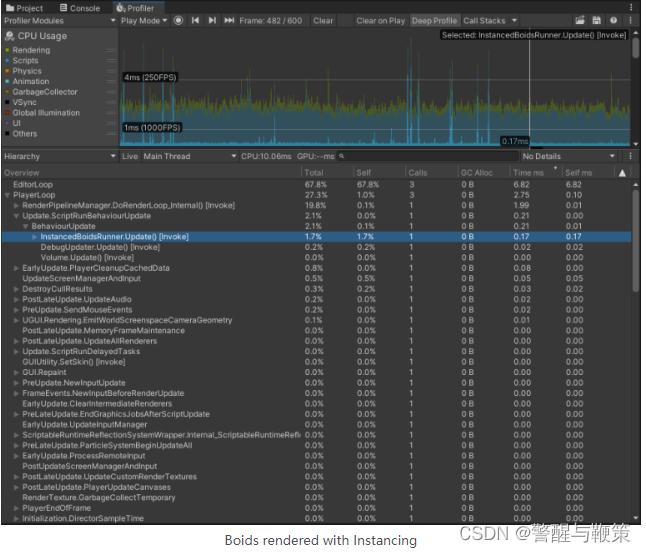
PlayerLoop with Instancing implementation takes around 2-3ms every frame. BRG with its ~7ms looks a lot slower, but why? Time to use deep profiling. Due to the issue with the boids algorithm, I am limiting the instance count to 1000, otherwise the algorithm is too unstable.
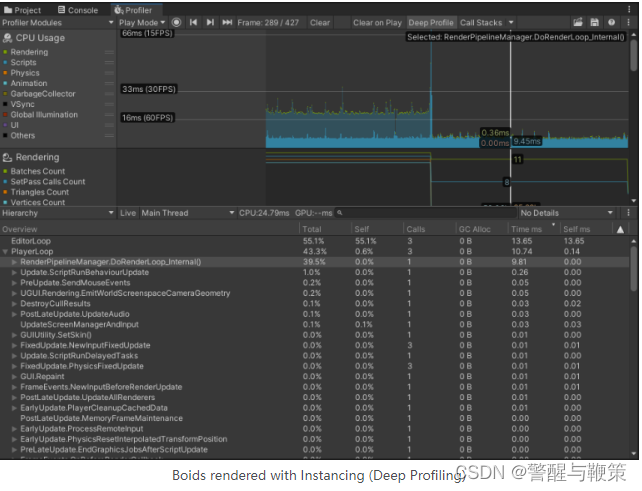
Boids rendered with BatchRendererGroup (Deep Profiling)
Rendering in DoRenderLoop_internal is on par for both variants, but Update() of BatchRendererGroupBoidsRunner is significantly slower.
No wonder looking at those numbers inside the UpdatePositions methods. The reason for this is the slow sequential update of _dataBuffer, calculating inverse for each matrix, and creating a ton of Vector4s. All of that is done in the main thread.
It can be optimized by moving update to the job system. To do this we need to remove completely Update methods from BatchRendererGroupBoidsRunner.
And create a new job that copies data from matrices to _dataBuffer:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
Make sure to add [NativeDisableParallelForRestriction] attribute, because the job safety system will prevent you from writing to arbitrary indices from within the job’s kernel, but we need to update 3 neighboring entries, as well as an inverse matrix. This attribute allows disabling this check by basically saying that you guarantee there will be no race condition.
And of course, we need to schedule the new job and update GraphicsBuffer when the data is ready:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
|
Let’s profile the optimized version to check if the optimization was useful.
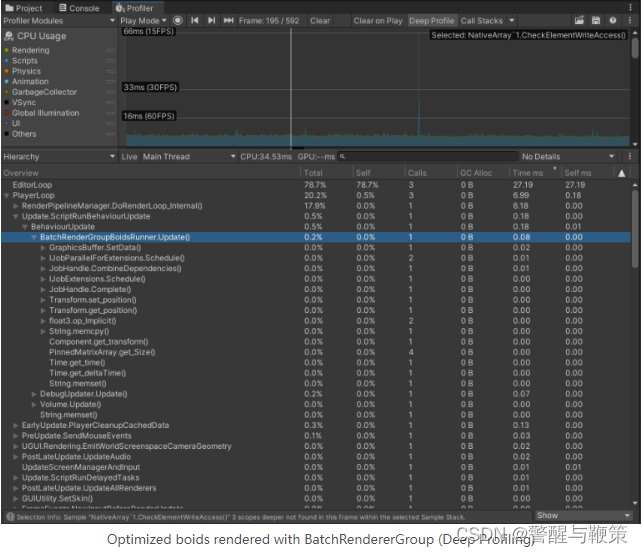
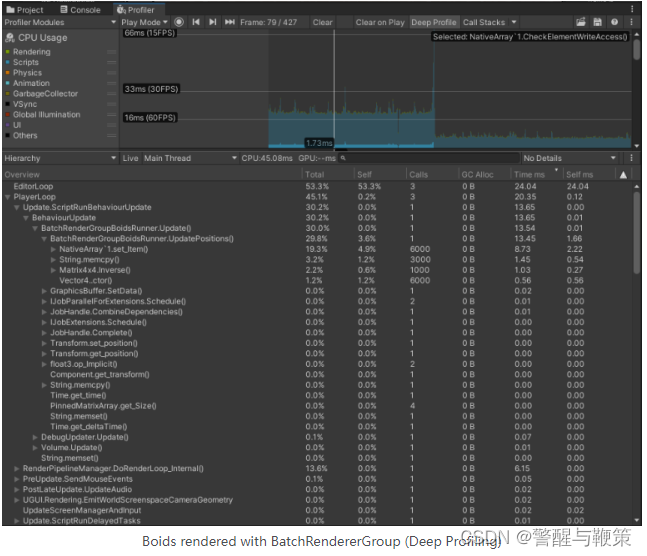
Optimized boids rendered with BatchRendererGroup (Deep Profiling)
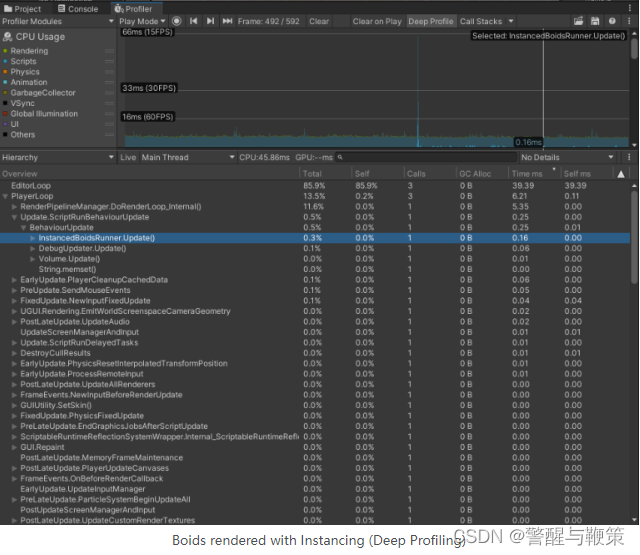
Boids rendered with Instancing (Deep Profiling)
Well, it was a good optimization attempt indeed.
After Update is optimized by moving _dataBuffer update to a parallel job, we got similar performance here. On average Instanced variant runs just a little bit faster, but in deep profiling of 1k objects we can see that Graphics.DrawMeshInstanced() takes more time than the whole Update of the BRG variant. However, BRG loses a bit in DoRenderLoop_internal. The final version is available here: Boids BRG @Github. And of course, you can get the whole project on GitHub too: GitHub - AlexMerzlikin/Unity-BatchRendererGroup-Boids: A sample project for the blog post @ https://gamedev.center.
Conclusion
The example with a single mesh and a single material shows great performance on par with instancing. I would like to compare performance on a mobile device too, as well as try to use BRG for a more complex scene with different meshes and materials, and use Burst and Job System to implement culling and draw command output, but that’s gonna be another blog post, as this one is kinda big already.
And it definitely took so much time to prepare. So while I am working on the next post you can give my telegram channel a follow where I post stuff I find interesting on a daily basis.
///
/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









