






前言
表面粗糙度对大部分参与滑动接触的表面而言是非常重要的。因为磨损的原始速率及持续的性质等因素高度依赖这一特性。这些表面一般是承重面,而且需标识粗糙度已确保预计用途的适用性。
许多零部件需要具有特定的表面加工结果,以便达成所要求的功能。例如烤漆前的汽车车体或曲轴或凸轮轴上的颈轴承。我们先了解一下什么是表面粗糙度。

1 什么是表面粗糙度
表面粗糙度(Surface Roughness)就是我们日常测量中所说的面粗糙度,可以理解为在加工产品过程中细小间距和微小峰谷的不平整度。
通常被定义为两个波峰值或者两个波谷指之间的微小距离(波距),在一般情况下波距都在1mm以内或者更小,也可定义为微观轮廓的测量,俗称微观误差值。

综上所说,大家可能已经有了一个关于粗糙度笼统的概念,那么下记内容是更详细的进行了分析。我们一般评价粗糙度会有基准线,基准线以上最高点我们叫波峰点,基准线以下最低点叫波谷点,那么波峰和波谷之间的高度我们用Z来表示,加工产品的微观纹理的间距我们用S来表示。
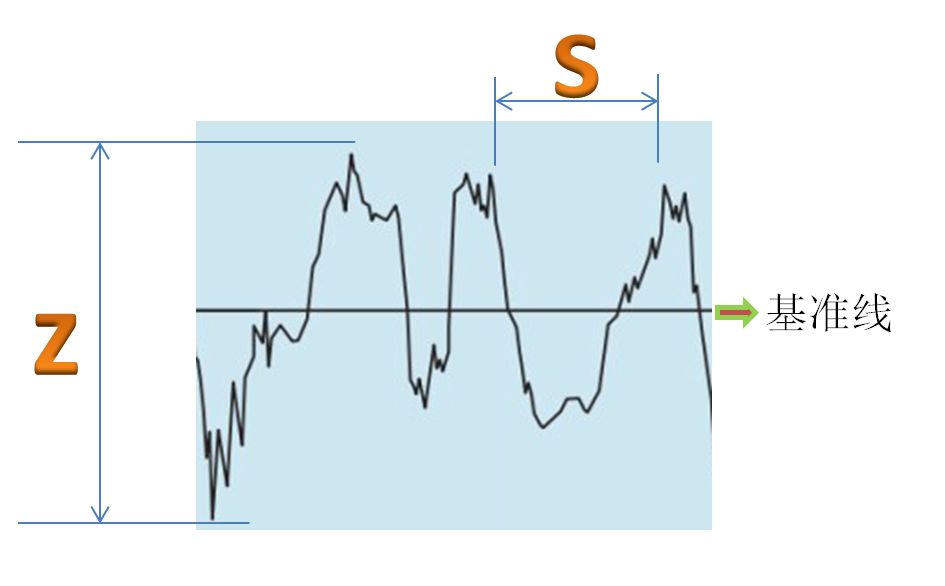
通常情况下S值的大小在国家检定标准里给了相关的定义:
S<1mm 定义为表面粗糙度
S<1mm 定义为表面粗糙度
1≤S≤10mm 定义为表面波纹度
中国国家计量检定标准中规定:通常情况下用VDI3400、Ra,、Rmax这三个参数来评价检定表面粗糙度,计量单位通常用μm表示。
评价参数的关系
Ra定义为曲线平均算术偏差(平均粗糙度),Rz的定义为不平度平均高度,Ry定义为最大高度。微观轮廓的最大高度差Ry在其他也使用Rmax来表示。
Ra、Rmax的具体关系还请参考下面的表格:
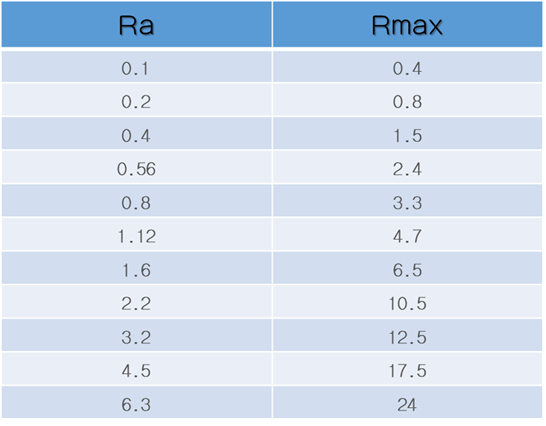
表:Ra,Rmax参数对比(um)
2 表面粗糙度是如何形成的
表面粗糙度的形成是由工件的加工过程引起的。而加工的方法、工件的材料,工艺过程都是影像表面粗糙度的因素。例如:放电加工时被加工零件表面出现放电凹凸点。
加工工艺和零件材质有所不同,被加工零件表面留下的微观痕迹也有各种差别,比如(疏密,深浅,形状变化等)。
3 表面粗糙度对工件的影响
工件的耐磨性、配合稳定性、疲劳强度、耐腐蚀性、密封性、接触刚度、测量精度……镀涂层、导热性和接触电阻、反射能力和辐射性能、液体和气体流动的阻力、导体表面电流的流通等都会有不同程度的影响。

4 表面粗糙度的评价依据
取样长度
各参数的单位长度,取样长度是评价表面粗糙度规定一段基准线的长度。
在ISO1997标准下一般使用0.08mm,0.25mm,0.8mm,2.5mm,8mm为基准长度。
评价长度
由N个基准长度所构成。零部件表面各部分的表面粗糙度,在一个基准长度上无法真实的体现出粗糙度真实参数,而是需要取N个取样长度来评定表面粗糙度。在ISO1997标准下评定长度一般为N等于5。
基准线
基准线是评定粗糙度参数的轮廓中线。一般有最小二乘法中线和轮廓算术平均中线。
【最小二乘法中线】是把测量过程中采集的点进行最小二乘法计算。【轮廓算术平均中线】在取样长度内,使中线上下两部分轮廓的面积相等。
理论上最小二乘中线是理想的基准线,但在实际应用中很难获得,因此一般用轮廓的算术平均中线代替,且测量时可用一根位置近似的直线进行代替使用。
5 表面粗糙度如何获得
表面粗糙度的评价在制造业中越发被重视。要研究表面粗糙度,需要使用专用的机器,即:
表面粗糙度测量仪

复合测量机Formtracer Avant系列
表面粗糙度测量机是以安装高敏感性金刚石测针划过表面,就像是留声机的拾音器一样。再将大柜规模波纹以及轮廓的小波长粗糙度从较长波长中分离出来,即测量仪做电子过滤。
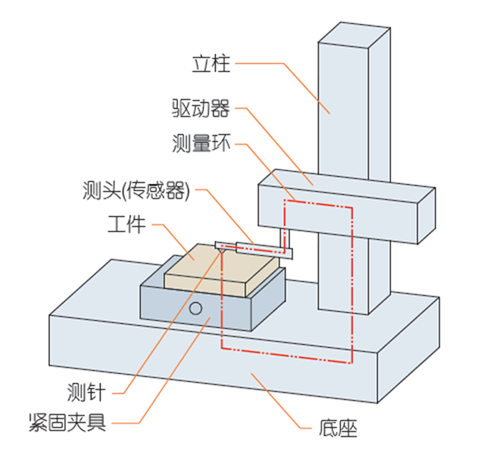
*测针型粗糙度测量仪特性的定义可参考ISO 3274:1996
测针式表面粗糙度测量仪的构成示意图:
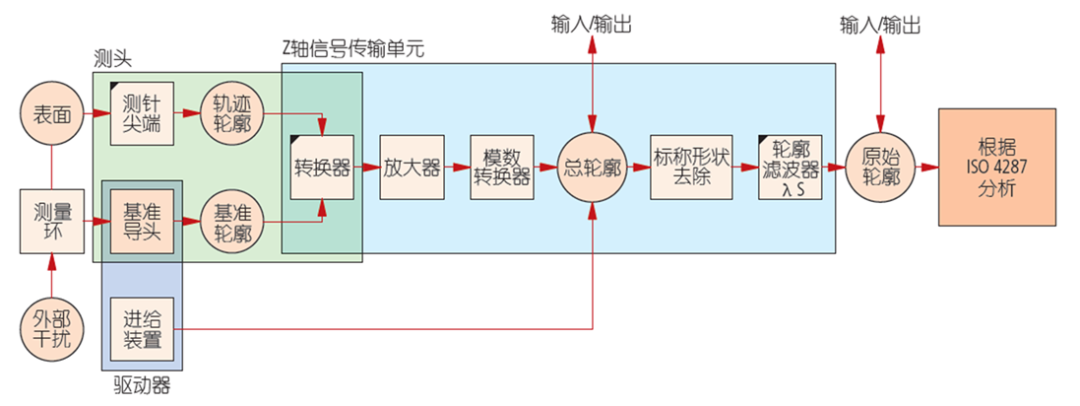
测针形状种类:
手持工具测量
大部分正确的、完整的表面粗糙度测量法,虽然都是使用专用的测量机,但在有的情况下,为了快捷且低成本操作也可以使用手持套装工具测量。
如下图:

粗糙度比较片是以镍为基础,以电铸方式制成的样本,用于金属加工非常理想,属于非常有效的辅助工具。操作者使用时只要以指甲在一组中的每一片表面都横刮而过,寻找与被比较工件最接近的即可。有人会将这些模型组作为查询表,但是值得注意的是,这并非材质标准。
粗糙度测量机可以实现的功能不同,评价的方法不同,成本也各有高低。选型之前可以到专业的生产厂商进行咨询,根据所需选择最适合的机型。

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









