









超时的处理
爬虫在向服务器请求时,若是服务器没有顺利返回响应,爬虫就会一直等待
有时这种长时间等待是没有没价值的
在requests.get()里添加参数,设置一个等待时间,若是响应超过这段时间还没有返回,就返回异常报告(ConnectTimeout):
#设置超时时间是0.001秒:
response=requests.get(url,timeout=0.001)AJAX、检查工具里的network和XHR
1.AJAX(Asynchronous JavaScript And XML):
一种异步更新技术,更新网页的部分内容,但是不重新加载整个网页(url不会变)。
在一些网站里,评论就是用JavaScript加载的,在一个<script>的标签内,这些评论数据就不会加载在初次出现的网页源代码里。
2.解释为什么requests请求到的响应会没有element里的标签:
浏览器打开一个网页,用右键【检查】打开查看网页源代码:
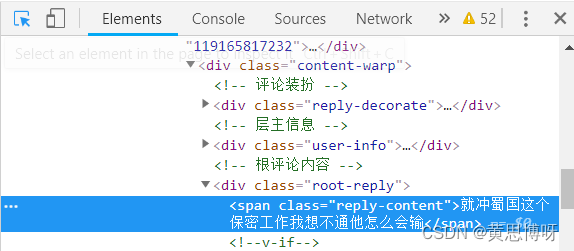
在【element】中,我们可以找到标签:<span class="reply-content">
而在右键【查看网页源代码】打开的网页里(打开的数据就是我们用requests爬到的):

是找不到这个标签(即使是在网页更新出新内容,再打开源代码,其内容也不会变)
3.network和XHR
右键【检查】或是【F12】打开的小窗的选择栏里有network这个栏目:
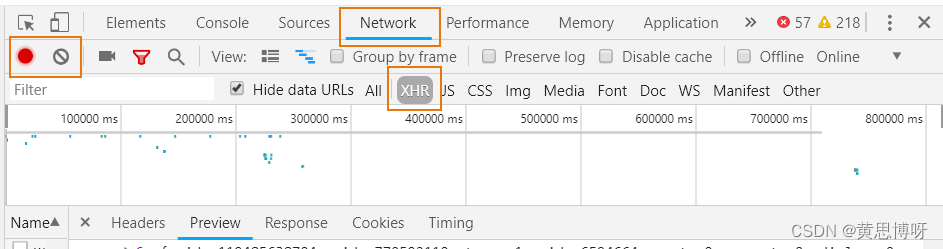
左侧红色的小灯:灯亮表示一直在监听页面内通过点击、按键发送的请求
禁止的符号:清除的意思,会清除掉我们找到的页内响应
XHR:不更新网页也可以传输的对象(比如页面内没有展开的评论和回复)
requests、network、SHR和json进行动态网页爬虫:
1、捕获网页源代码里没有的信息,比如说动态加载的评论
1.点击【network】中【禁止符号】对当前的XHR对象进行清除
2.在某网站的某个视频下点击了加载评论的按钮
3.可以发现有新的XHR对象出现(这难道就是传说中的抓包!)对应网页内评论完成更新,XHR对象完成更新(时间差完全可以忽略),在size列下也可以看XHR对象的数据大小。
4.查看这个XHR对象是不是真的有评论数据:
点击这个XHR对象,点击【Preview】进行内容预览,里面是json数据,点击【replies】慢慢往下掏,就有响应的评论内容:


2、打开这个XHR对象的【headers】,组装requests请求url:
将【authority】、【path】 和【scheme】组装成一个url:

3、用requests进行爬取:
import requests
url="阿巴阿巴"
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4533.400"}
response=requests.get(url,headers=headers)
print(response.text)4、json模块进行数据提取:
json是一种字典和列表组成的数据格式,可以做为XHR的一种传输文件格式。
导入和调用模块(python自带):
import json
words=response.content.decode("UTF8")
json_=json.loads(words)一个json格式化的网页:JSON在线解析及格式化验证 - JSON.cn

根据网页解析的分枝数格式进行编写代码:
comments=[]
id_names=[]
members=json_["data"]["replies"]
for each_member in members:
comment=each_member["content"]["message"]
comments.append(comment)
id_name=each_member["member"]["uname"]
id_names.append(id_name)
5、进行数据的简单保存:
with open("comments.txt","w+",encoding="utf8") as f:
for i in range(len(id_names)):
f.write(id_names[i]+":\n"+comments[i]+"\n\n")
f.close()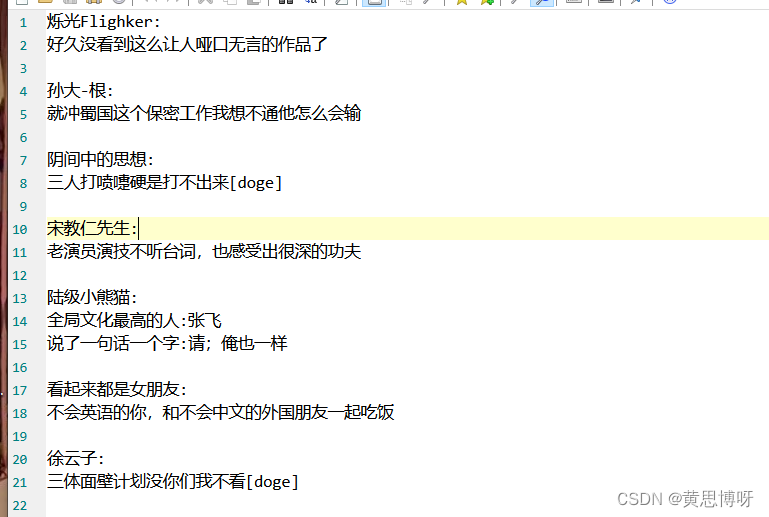
参考书籍: python网络爬虫从入门到实践 编者:唐松
















 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











