







概率密度函数(Probability Density Function, PDF)详解
概率密度函数(PDF)是统计学和概率论中的重要概念,它描述了连续随机变量的概率分布。通过概率密度函数,我们可以计算某个变量在某个区间内取值的概率,这对于数据分析、机器学习、物理建模等领域至关重要。
本文将从概率密度函数的定义、公式、性质、计算方法、应用场景以及示例等方面详细展开。
1. 概率密度函数的定义
在离散随机变量的情况下,我们可以用概率质量函数(PMF, Probability Mass Function)直接表示某个取值的概率。然而,在连续随机变量的情况下,直接计算某个具体数值的概率是不可能的,因为在实数集上,每个点的概率为 0。因此,我们需要用概率密度函数来描述数据的分布情况。
正式定义
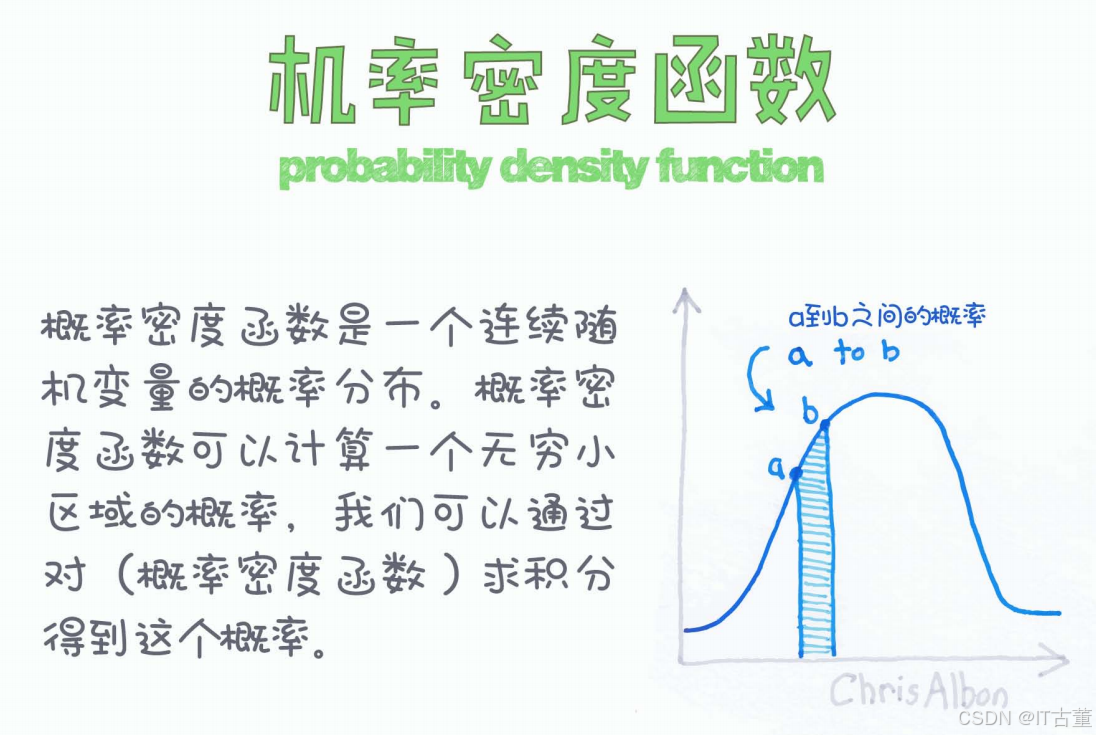
设 XXX 是一个连续随机变量,如果存在一个函数 f(x)f(x)f(x),使得对于任意区间 [a,b][a, b][a,b] ,随机变量 XXX 取值落在该区间的概率可以由以下积分计算:
其中:
- f(x) 称为概率密度函数(Probability Density Function, PDF)。
表示 X 取值落在区间 [a, b] 内的概率。
- 该积分计算的是概率密度曲线在区间 [a, b] 下的面积。
在图示中,概率密度函数 f(x) 以一条光滑的曲线表示,阴影部分(从 a 到 b 之间的面积)代表 X 落在该区间的概率。
2. 概率密度函数的性质
概率密度函数 f(x) 需要满足以下几个基本性质:
-
非负性:概率密度函数必须是非负的,即:
这意味着密度不能为负数。
-
总概率为 1(归一化条件):
这表示在整个定义域上,随机变量取值的总概率为 1。
-
任意区间的概率等于密度函数在该区间的积分:
这一点强调了概率密度函数的核心作用,即用积分计算概率。
-
单点概率为 0:
由于积分上、下限相同,积分结果为 0,说明对于连续随机变量而言,取某个具体值的概率总是 0。
3. 概率密度函数的计算
在实际应用中,我们通常使用以下方式来计算概率密度函数:
3.1 直接给定的概率密度函数
有些情况下,概率密度函数是已知的。例如,正态分布(高斯分布)的概率密度函数为:
其中:
- μ 是均值
- σ 是标准差
如果我们知道随机变量服从某种特定分布(如正态分布、均匀分布、指数分布等),我们可以直接使用这些分布的已知密度函数进行计算。
3.2 通过累积分布函数(CDF)求导
累积分布函数(Cumulative Distribution Function, CDF)定义为:
如果我们知道 X 的累积分布函数 F(x),那么概率密度函数 f(x) 可以通过对 F(x) 进行求导得到:
4. 概率密度函数的常见分布
概率密度函数在不同的概率分布中有不同的表达方式,以下是几个常见的例子:
-
均匀分布(Uniform Distribution)
-
正态分布(Normal Distribution)
-
指数分布(Exponential Distribution)
-
伽马分布(Gamma Distribution)
这些分布广泛应用于自然科学、工程、金融等领域。
5. 应用场景
概率密度函数在许多领域都有广泛应用:
-
数据分析与统计建模
- 统计数据的分布情况,例如工资分布、房价分布等。
- 进行假设检验,例如正态性检验。
-
机器学习
- 生成概率模型,例如 Naive Bayes 分类器使用概率密度函数计算似然概率。
- 变分推断(Variational Inference)和概率图模型中使用概率密度进行推导。
-
物理与工程
- 在信号处理中,噪声往往被假设为高斯分布。
- 在可靠性分析中,设备寿命常用指数分布建模。
-
金融领域
- 资产收益率通常被建模为正态分布或对数正态分布。
- 风险管理中使用概率密度函数估计资产价格的可能范围。
6. 总结
概率密度函数(PDF)是描述连续随机变量概率分布的重要工具。它的主要特性包括:
- 通过积分计算区间概率
- 总概率为 1
- 取某个具体值的概率为 0
- 可以通过累积分布函数求导得到
在现实应用中,概率密度函数广泛用于数据分析、机器学习、工程建模、金融分析等多个领域。理解和掌握概率密度函数的概念,有助于我们更深入地分析数据,做出更科学的预测和决策。

















 675
675

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









