






自动驾驶车辆运动控制过程中,对PID控制参数的优化和整定。
传统PID控制算法,由于参数固定,在道路曲率较大和车速变化情况下难以满足控制需求,采用RL强化学习算法(DDPG算法,Actor-Critic框架)可实现控制参数的在线优化,科研就是这么有趣,
ID:554000671247877301
自动驾驶创新工坊
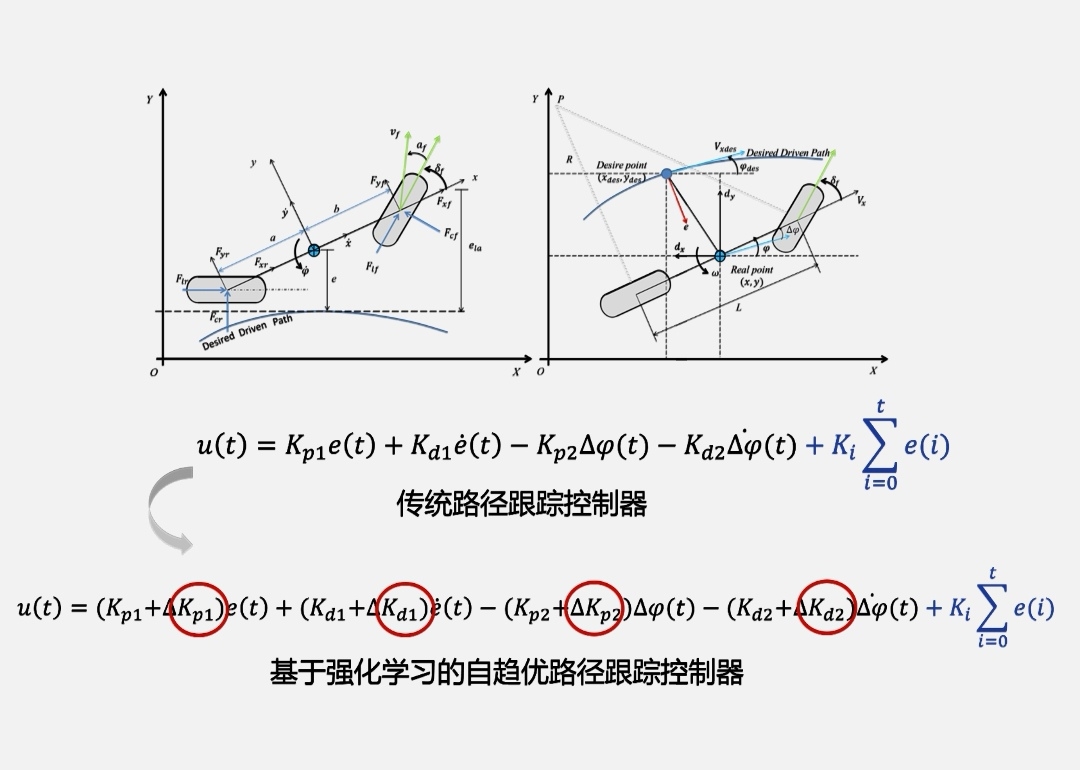
自动驾驶车辆是当今科技领域的热门研究方向,其运动控制过程对于实现安全、高效的驾驶至关重要。在自动驾驶车辆的运动控制中,PID控制算法是一种常用的控制方法。然而,在某些情况下,传统的PID控制方法由于参数固定,难以满足控制需求,特别是在道路曲率较大或车速变化较大的情况下。为了解决这一问题,研究者们引入了强化学习算法,并在自动驾驶车辆的运动控制中取得了显著的成果。
传统的PID控制算法采用了固定的控制参数,例如比例系数、积分系数和微分系数。这些参数需要通过试错法或经验法进行手动整定,往往需要耗费大量的时间和精力。而且,当道路曲率较大或车速发生变化时,传统的PID控制算法很难保持良好的控制性能。
为了解决这一问题,科研人员引入了RL强化学习算法,其中包括了DDPG算法和Actor-Critic框架。DDPG(Deep Deterministic Policy Gradient)算法是一种模型无关的强化学习算法,能够实现连续动作空间下的最优控制。而Actor-Critic框架则是DDPG算法的一种变体,它通过同时学习策略评估和策略改进来优化控制性能。这些算法的引入使得自动驾驶车辆的控制参数能够在线进行优化,从而提高了控制性能和适应性。
在实践中,基于RL强化学习算法的自动驾驶车辆运动控制方案已经取得了显著的效果。研究者们通过在真实道路和模拟环境中进行大量实验,验证了基于RL强化学习算法的自动驾驶车辆运动控制方案的可行性和有效性。实验结果表明,在道路曲率较大或车速变化较大的情况下,基于RL强化学习算法的自动驾驶车辆能够更好地适应环境变化,并实现更加准确、稳定的控制。
由此可见,对PID控制参数的优化和整定在自动驾驶车辆运动控制中具有重要意义。传统的PID控制算法由于参数固定,在某些特殊情况下难以满足控制需求。而基于RL强化学习算法的自动驾驶车辆运动控制方案能够实现控制参数的在线优化,提高了控制性能和适应性。这些研究成果为自动驾驶车辆的发展和应用提供了有力支持,也为我们揭示了科研的乐趣所在。
相关的代码,程序地址如下:http://wekup.cn/671247877301.html
















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









