







《SAMURAI: Adapting Segment Anything Model for Zero-Shot Visual Tracking with Motion-Aware Memory》
近日,华盛顿大学的研究团队发布了一个名为 SAMURAI 的新型视觉追踪模型。该模型基于沿的 Segment Anything Model2(SAM2),旨在解决在复杂场景中进行视觉对象追踪时所遇到的挑战,尤其是在处理快速移动和自遮挡物体时。关键是这篇文章的核心思想竟然是经典的“卡尔曼滤波”!前谷歌产品经理Bilawal Sidhu在看完论文后直呼“优雅”。
论文链接:https://arxiv.org/pdf/2411.11922
1. 导读
Segment Anything Model 2 (SAM 2)在对象分割任务中表现出强大的性能,但在视觉对象跟踪方面面临挑战,特别是在管理具有快速移动或自遮挡对象的拥挤场景时。此外,原始模型中的固定窗口存储器方法没有考虑被选择来调节下一帧的图像特征的存储器的质量,导致视频中的错误传播。本文介绍SAMURAI,它是SAM 2的增强版,专门用于视觉目标跟踪。通过将时间运动线索与所提出的运动感知记忆选择机制相结合,SAMURAI有效地预测了对象运动并优化了掩模选择,实现了鲁棒、准确的跟踪,而无需重新训练或微调。SAMURAI实时运行,并在不同的基准数据集上展示了强大的零射击性能,展示了其无需微调即可进行归纳的能力。在评估中,SAMURAI在成功率和精确度方面比现有的追踪器有了显著的提高,在LaSOT上AUC提高了7.1%外面的(exterior的简写)以及GOT-10k上3.5%的AO增益。此外,与LaSOT上的完全监督方法相比,它取得了有竞争力的结果,突出了它在复杂跟踪场景中的鲁棒性及其在动态环境中的实际应用潜力。
2. 引言
“Segment Anything Model”(SAM)在分割任务中展现出了卓越的性能。最近,SAM 2[35]引入了流式内存架构,使其能够按顺序处理视频帧,同时在长序列中保持上下文信息。尽管SAM 2在视频对象分割(Video Object Segmentation,VOS)任务中表现出色,能够为整个视频序列中的对象生成精确的像素级掩码,但在视觉对象跟踪(Visual Object Tracking,VOT)场景中仍面临挑战。
VOT中的主要关注点是在遮挡、外观变化和相似对象存在的情况下,保持对象身份和位置的连续性。然而,SAM 2在预测后续帧的掩码时往往忽略了运动线索,这导致在对象快速移动或存在复杂交互的场景中出现不准确的情况。这一局限性在拥挤场景中尤为明显,SAM 2在这些场景中往往更倾向于依据外观相似性而非空间和时间一致性进行决策,从而导致跟踪错误。如图1所示,存在两种常见的失败模式:拥挤场景中的混淆以及遮挡期间的无效内存利用。
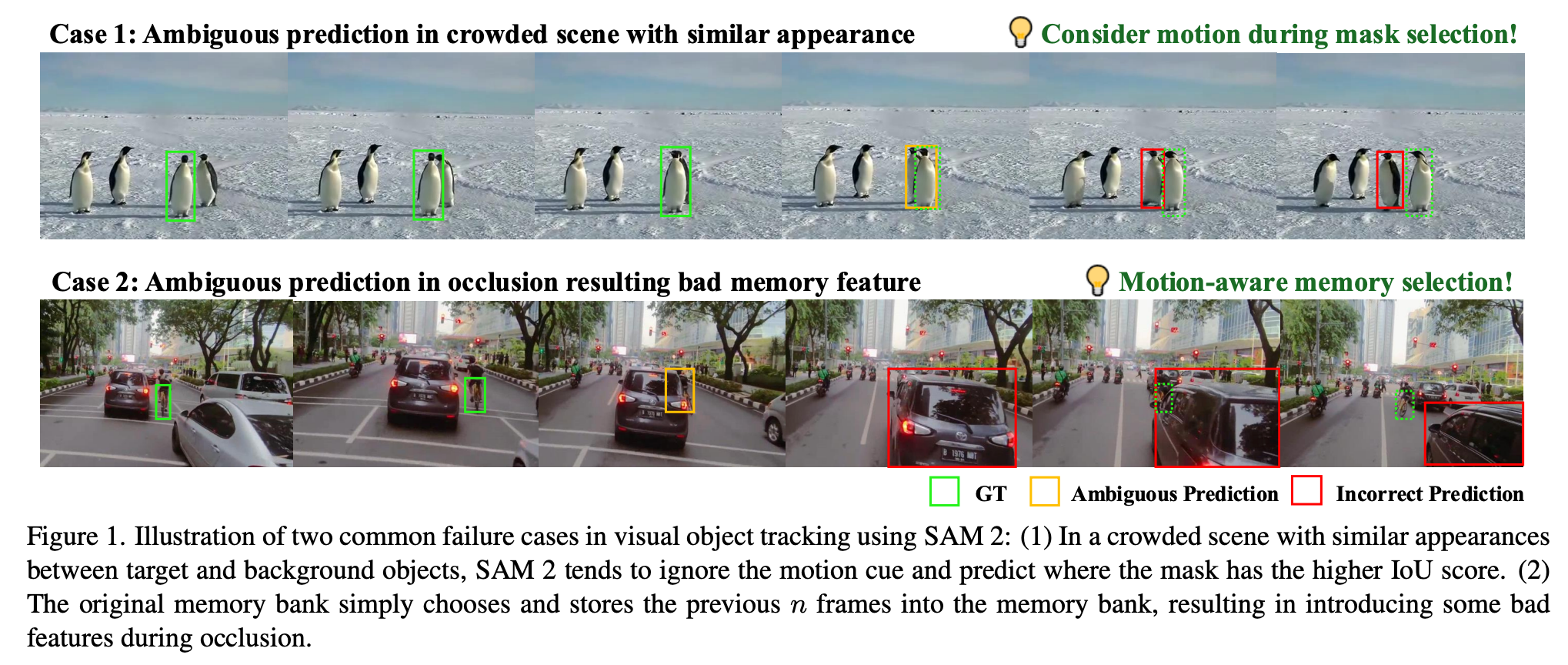
为解决这些局限性,我们提出将运动信息纳入SAM 2的预测过程。通过利用对象轨迹的历史信息,我们可以增强模型在视觉上相似对象之间进行区分的能力,并在遮挡情况下保持跟踪准确性。此外,优化SAM 2的内存管理也至关重要。当前方法无差别地将最近几帧存储在内存库中,这在遮挡期间引入了不相关特征,从而损害了跟踪性能。解决这些挑战对于将SAM 2丰富的掩码信息应用于稳健的视频对象跟踪至关重要。
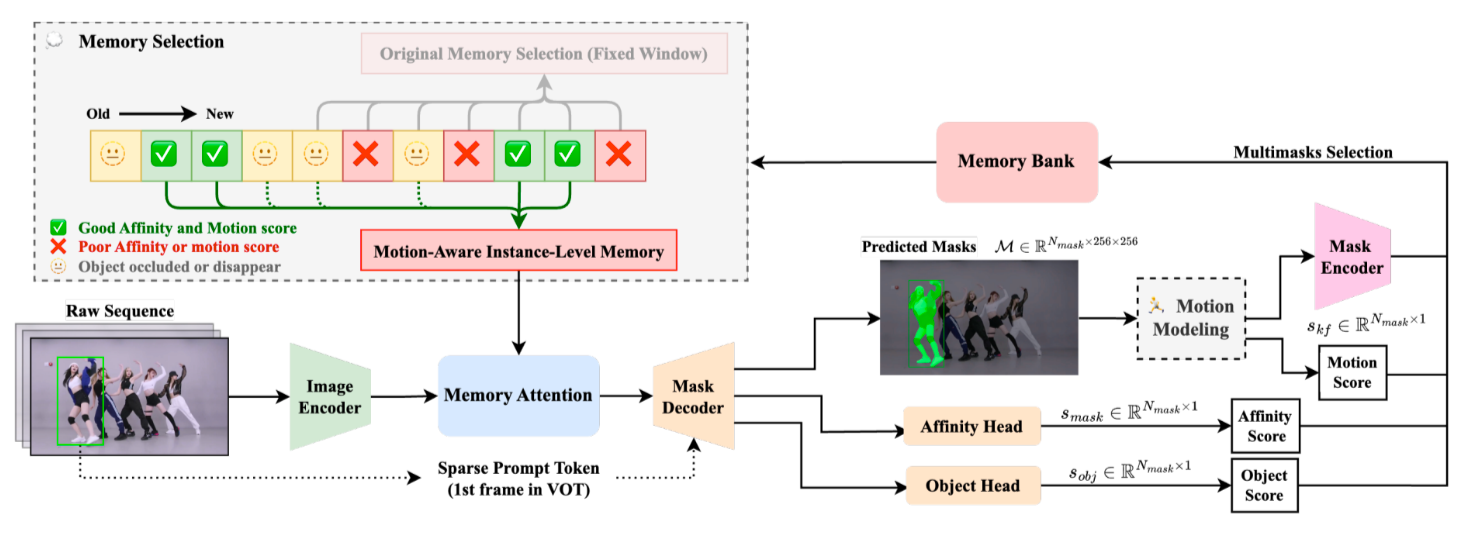
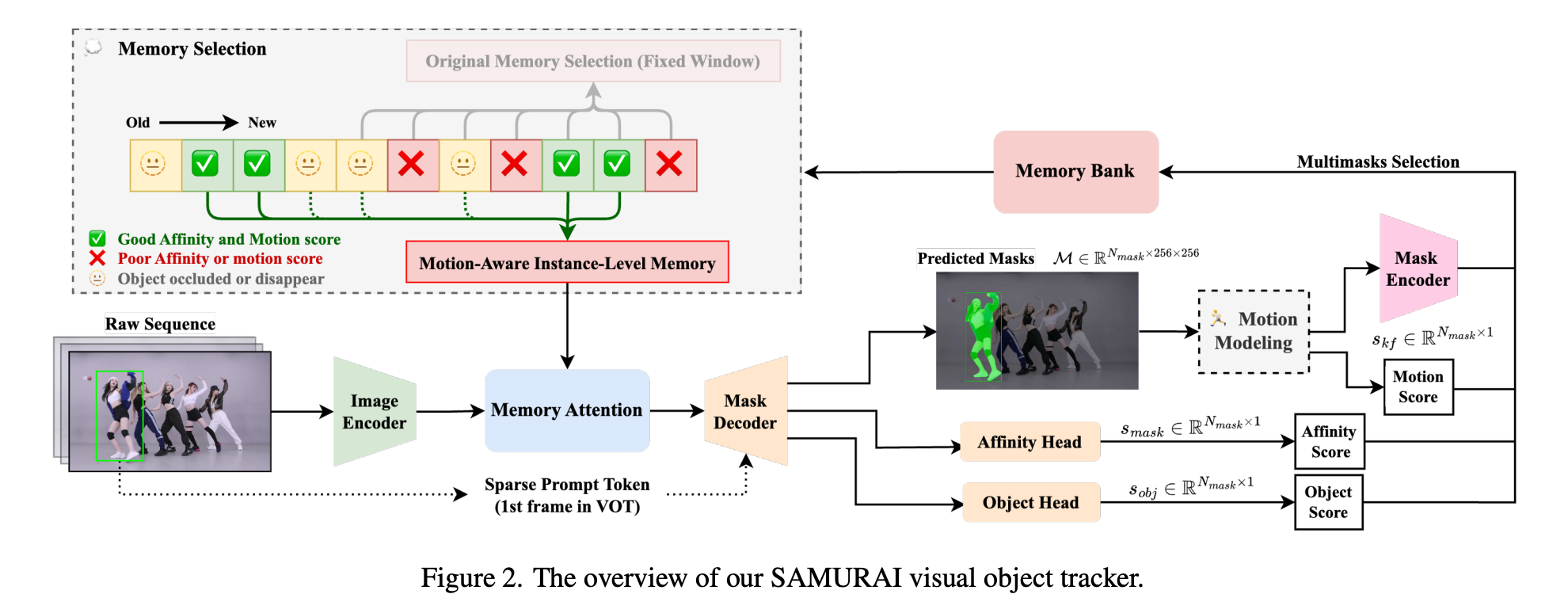
为此,我们提出了SAMURAI,这是一种基于SAM的统一且稳健的零样本视觉跟踪器,具有运动感知的实例级内存。我们提出的方法包含两项关键进展:(1)一个运动建模系统,用于完善掩码选择,从而在复杂场景中实现更准确的对象位置预测;(2)一个优化的内存选择机制,该机制利用混合评分系统,结合原始掩码亲和力、对象和运动评分来保留更多相关历史信息,从而提升模型的整体跟踪可靠性。
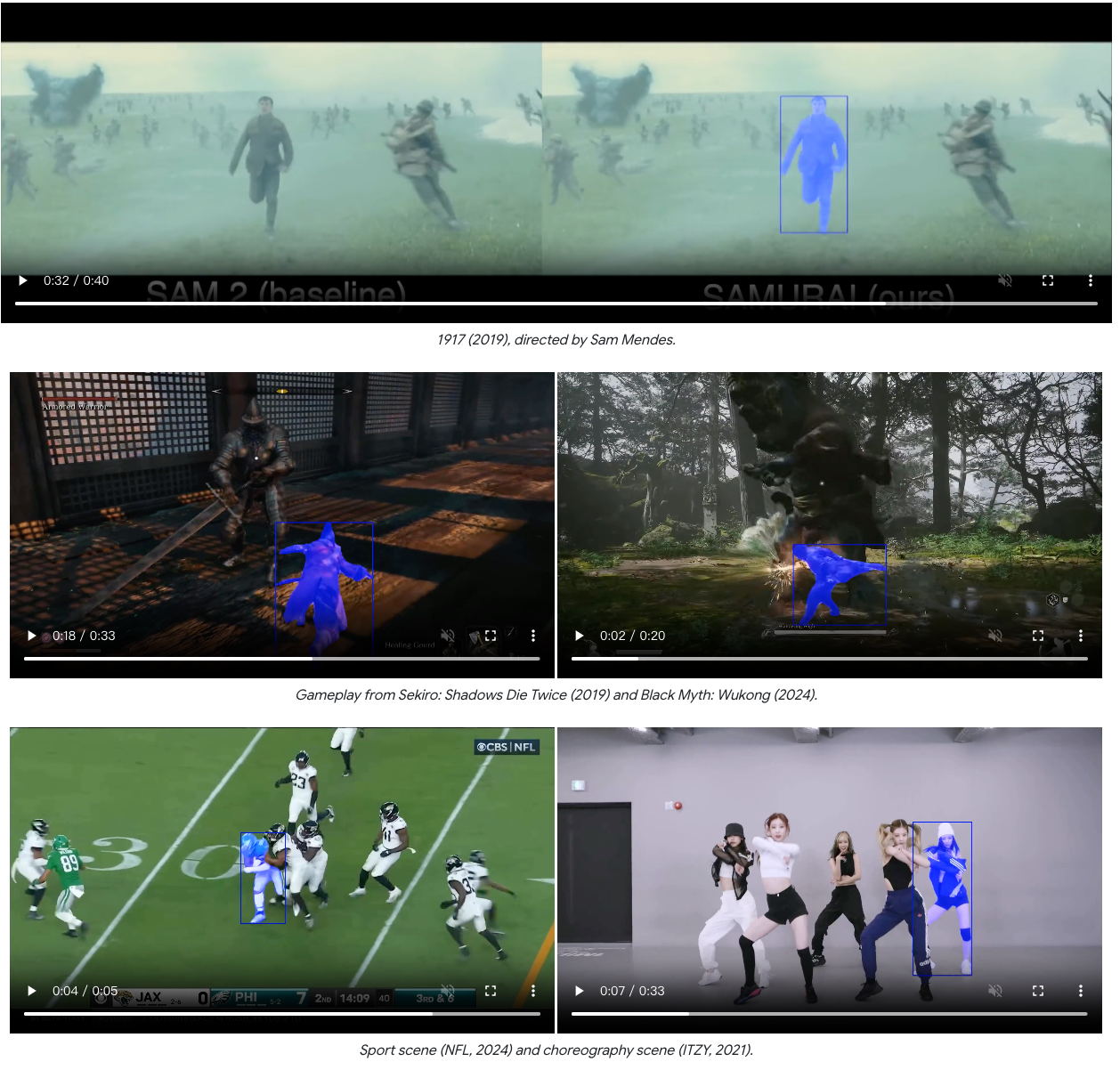
3. 效果展示
无论是只狼还是黑神话·悟空,都可以准确跟踪复杂动作,甚至“金箍棒”都可以准确分割。也完全无惧遮挡和复杂目标!
4. 主要贡献
本文做出以下贡献:
- 我们通过运动建模引入运动信息,提高了SAM 2的视觉跟踪准确性,有效处理了快速移动和遮挡对象。
- 我们提出了一种运动感知的内存选择机制,与原始固定窗口内存相比,通过选择性存储由运动和亲和力评分混合决定的相关帧,减少了拥挤场景中的错误。
- 我们的零样本SAMURAI在LaSOT、LaSOText、GOT-10k和其他VOT基准测试中实现了最先进的性能,无需额外训练或微调,这证明了我们在不同数据集上提出的模块具有强大的泛化能力。
5. 方法
SAM 2在基本的视觉对象跟踪(VOT)和视频对象分割(VOS)任务中表现出色。然而,原始模型可能会错误地编码不正确或置信度低的对象,从而在长序列VOT中导致显著的错误传播。
为解决上述问题,我们在多掩码选择的基础上提出了基于卡尔曼滤波器(Kalman Filter,KF)的运动建模,并在基于混合评分系统(结合亲和力和运动评分)的增强内存选择方面进行了改进。这些增强旨在加强模型在复杂视频场景中准确跟踪对象的能力。重要的是,这种方法既不需要微调,也不需要额外训练,可以直接集成到现有的SAM 2模型中。通过在不增加额外计算开销的情况下改进预测掩码的选择,该方法为在线VOT提供了一种可靠且实时的解决方案。
整体来看,SAMURAI主要包含两个技术关键点:
- 运动建模(Motion Modeling)
- 运动感知记忆选择(Motion-Aware Memory Selection)
6. 实验结果
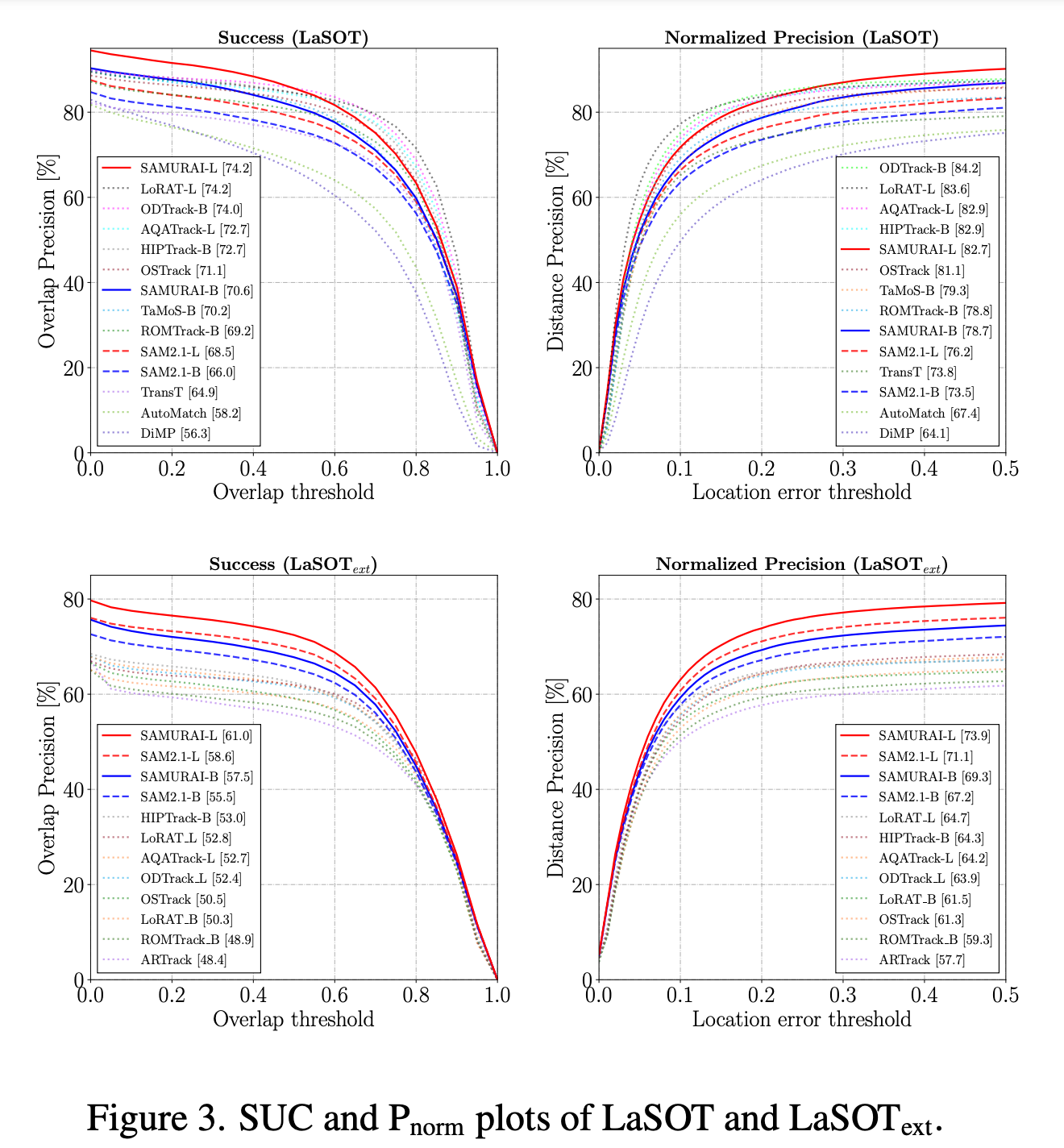
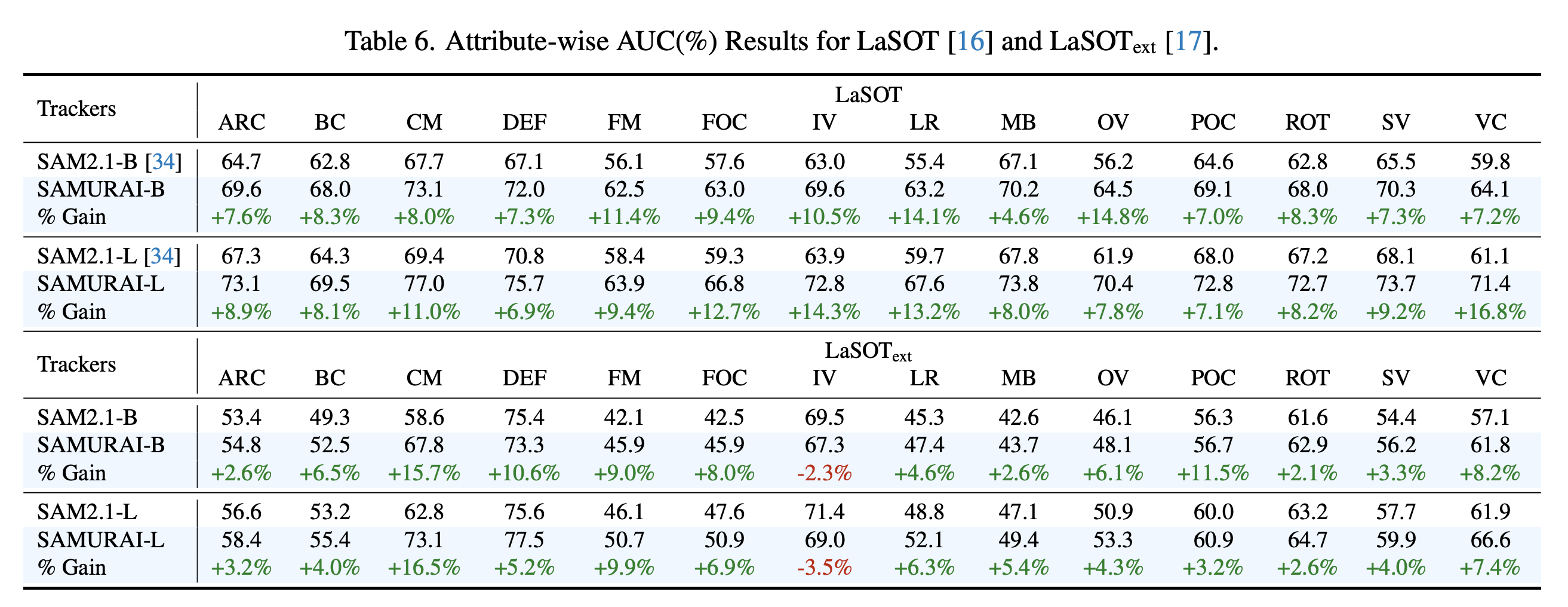
LaSOT和LaSOText的结果。表1展示了在LaSOT和LaSOText数据集上的视觉对象跟踪结果。我们的方法SAMURAI在所有三项指标上(如图3所示)相较于零样本方法和监督方法均表现出显著提升。尽管监督VOT方法取得了相当令人瞩目的结果,但相比之下,零样本SAMURAI展现了其出色的泛化能力,具有可比的零样本性能。此外,所有SAMURAI模型在LaSOText的所有指标上都超越了当前最优水平。
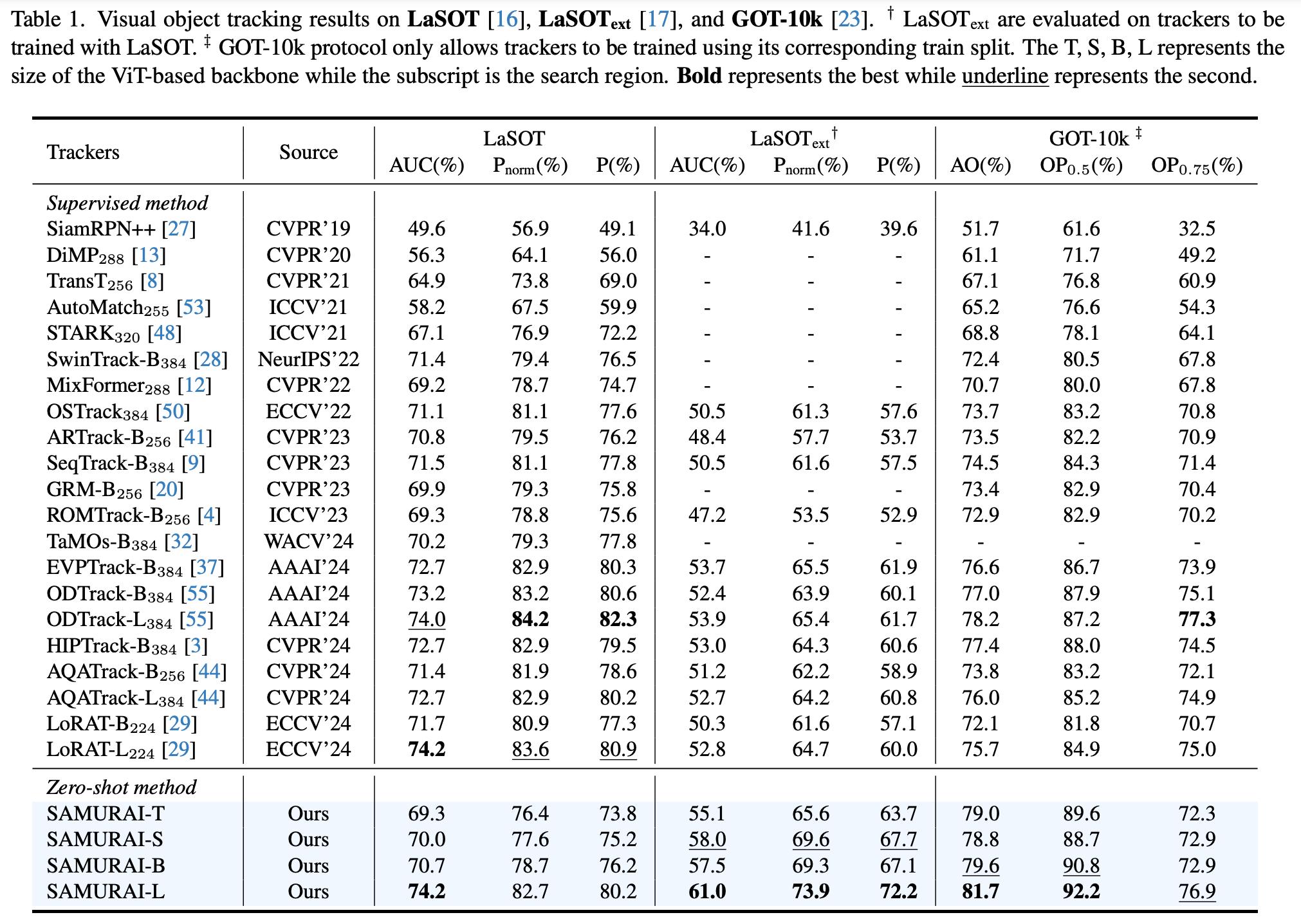
GOT-10k的结果。表1还展示了在GOT-10k数据集上的视觉对象跟踪结果。请注意,GOT-10k协议仅允许跟踪器使用其对应的训练集进行训练,因为一些论文可能会将其称为一次性方法。SAMURAI-B在AO上提高了2.1%,在OP0.5上提高了2.9%,相较于SAM2.1-B;而SAMURAI-L在AO上提高了0.6%,在OP0.5上提高了0.7%。所有SAMURAI模型在GOT-10k的所有指标上都超越了当前最优水平。
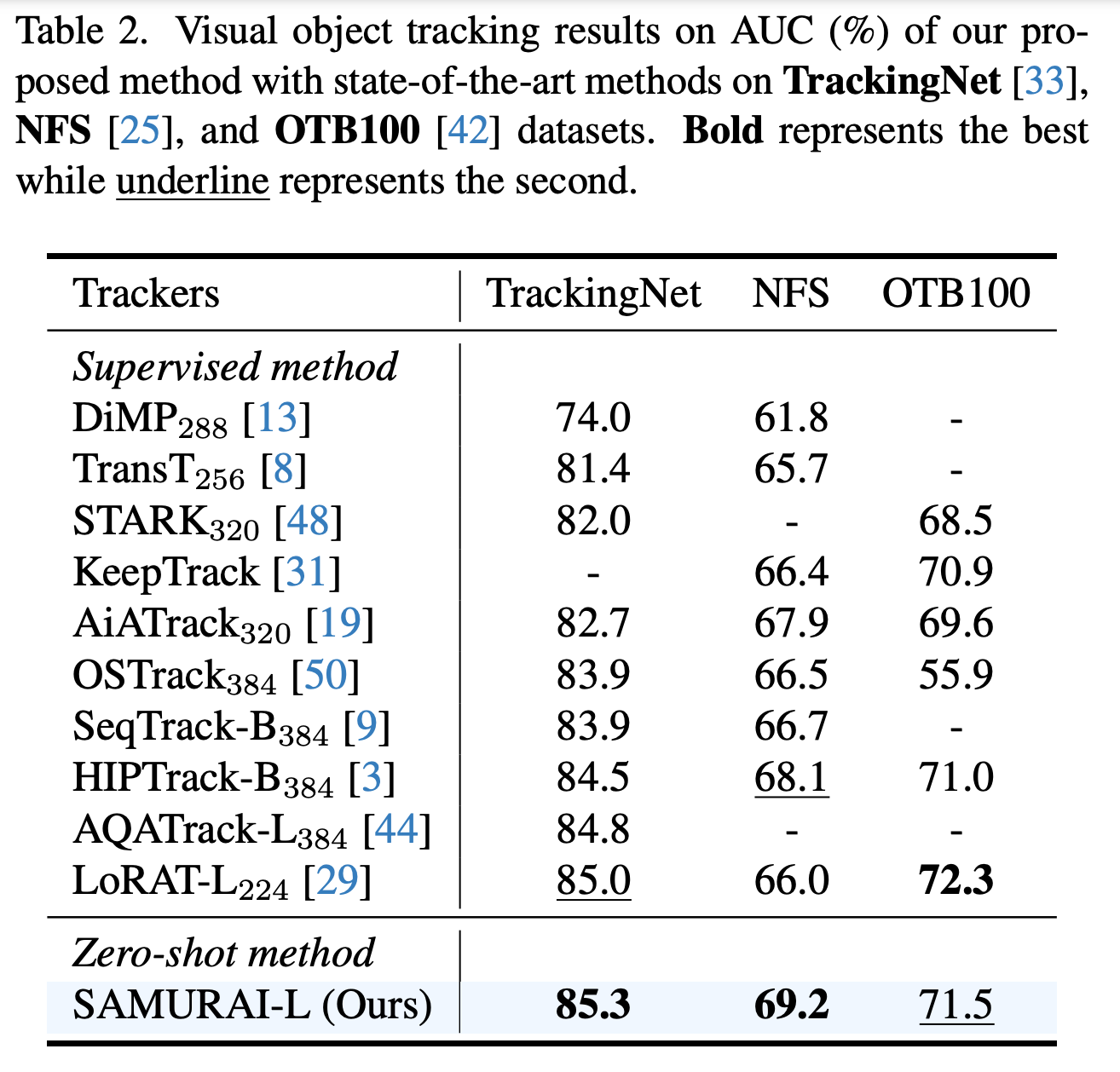
TrackingNet、NFS和OTB100的结果。表2展示了在四个广泛比较的基准数据集上的视觉对象跟踪结果。我们的零样本SAMURAI-L模型在AUC上与当前最优的监督方法相当或超越之,展示了我们的模型在不同数据集上的能力和泛化性。
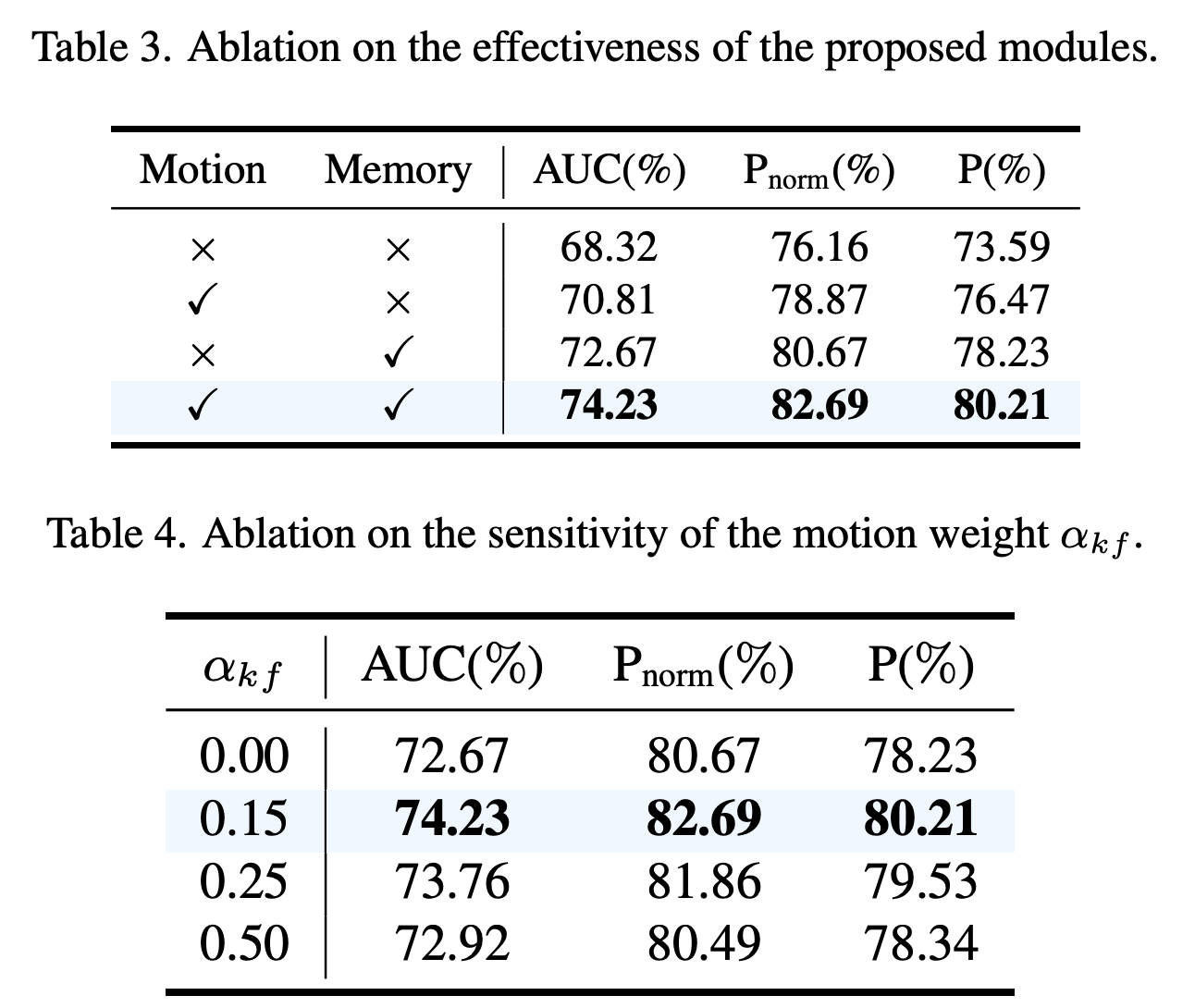
单个模块的效果。我们在表3中展示了有无记忆选择在不同设置下的效果。两个提出的模块都对SAM 2模型产生了积极影响,而两者结合可以在LaSOT数据集上获得最佳的AUC(74.23%)和Pnorm(82.60%)。
MotionWeights的效果。我们在表4中展示了在决定信任哪个掩码时分数加权的效果。运动分数和掩码亲和分数之间的权衡对跟踪性能有显著影响。我们的实验表明,在LaSOT数据集上,将运动权重αmotion设置为0.2时,可以获得最佳的AUC和Pnorm分数,这表明最优的平衡可以提高掩码选择的准确性和鲁棒性。
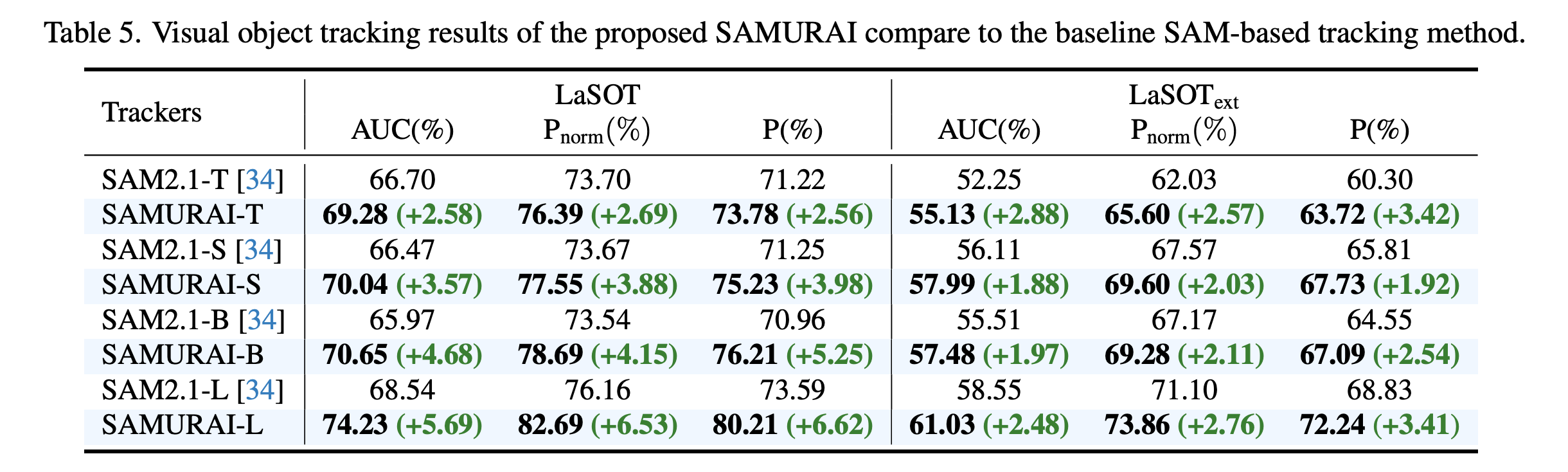
基线比较。为了证明SAMURAI中提出的运动建模和运动感知记忆选择机制的有效性,我们对SAM 2在LaSOT和LaSOText上的所有主干变体进行了详细的同类比较。基线SAM 2采用原始的记忆选择方法,并直接预测具有最高IoU分数的掩码。表5显示,所提出的方法在所有三项指标上都显著优于基线,这凸显了我们的方法在不同模型配置中的鲁棒性和泛化性。
7. 总结 & 未来工作
我们提出了SAMURAI,这是一个基于“分割万物”模型的视觉对象跟踪框架,通过引入基于运动的分数来改进掩码预测和记忆选择,以处理拥挤场景中的自我遮挡和突然运动。所提出的模块在所有SAM模型变体上,在多个VOT基准的所有指标上都表现出一致的改进。该方法无需重新训练或微调,同时在多个VOT基准上展现出稳健的性能,并具备实时在线推理的能力。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文。


















 2012
2012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









