







作者 | Kevin吴嘉文
整理 | NewBeeNLP 公众号
https://zhuanlan.zhihu.com/p/617302168
Alpaca,ChatGLM 6B 等模型的效果可以接受,下文总结部分笔记,为训练自定义小型化(7B)模型提供点知识储备。
之前我们分享了LaMDA, Muppet, FLAN, T0, FLAN-PLAM, FLAN-T5等,见:盘点!Instruction Tuning 时代的大模型。今天继续,包括模型论文 LLAMA, PaLM, BLOOM, BLOOMZ-mT。
LLAMA
论文: LLaMA: Open and Efficient Foundation Language Models
论文的重点在于预训练,虽然也尝试了使用 instruction tuning 进行模型测试,但介绍部分并不多。
数据:约 1.4 T token 预训练,多语言但就是没有中文;
模型:
经典的大模型 Pre-normalization,采用 RMSNorm normalizing。使用 SwiGLU 激活函数,使用 ROPE。
模型规模有:7B, 13B, 33B, 65B
训练:
预训练:2048 A100 GPU 21 天
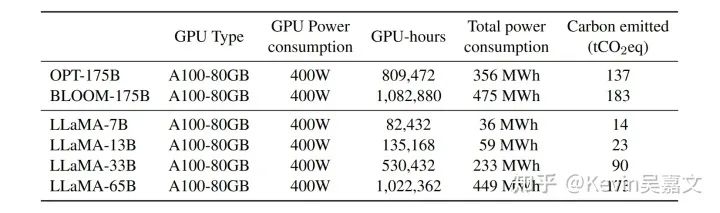
结果:
LLAMA 对标 GPT-3, PALM, OPT 等预训练模型。根据论文中各种指标表格,直观上来看,在 0-shot 以及 few-shot 效果上, 13B 的 LLAMA 与 GPT-3 可比,7B 的 LLAMA 不会落后 GPT-3 太多。
PaLM
论文: Scaling Language Modeling with Pathways
论文主要以研究预训练模型为主,但部分 instruction tuning 模型会与 PaLM 作比较,因此记录一些关注点:
模型架构上:
SwiGLU 激活函数,采用 RoPE,共享 input, output embedding,所有 layer 不用 biases,更改 Transformer Block 中 Layernorm 的并行方式,使用 multi-query attention 取代 multi_head attention(仅将 Q 映射到
[k, h],K,V 保持[1, h])
训练 :
预训练 780 billion tokens
针对训练过程中,loss 爆炸的情况,采用回滚的方式:在loss 爆炸点前 100 steps 开始,跳过 200 到 500 个 data batches,这样使得训练更加稳定
结果:总体看来 540 B 的 PaLM 在大部分任务上式新 SOTA
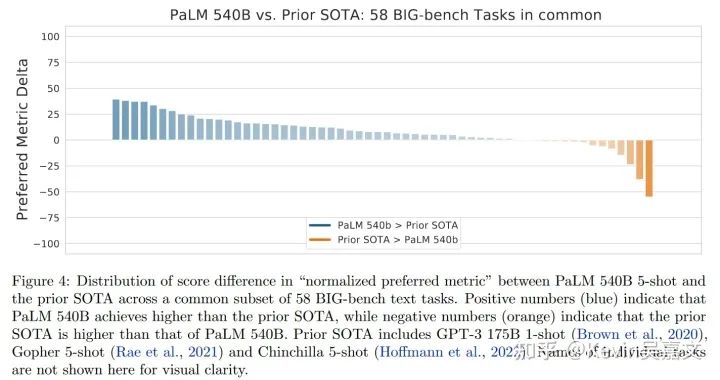
同时 PaLM 62B 的效果与 GPT-3 相近。
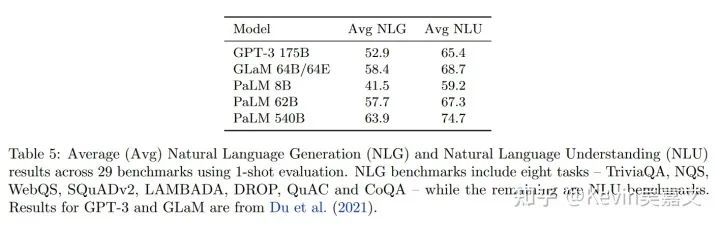
Bloom
论文: BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Bloom 偏向于研究预训练的文章,文章将较大比重放在了多语言能力的实验上,文中的 Bloom 和 BLOOMz 两个模型也都开源。
模型: Vocab size 比 LLAMA 等其他模型大很多。位置编码采用了 ALiBi Positional Embeddings。
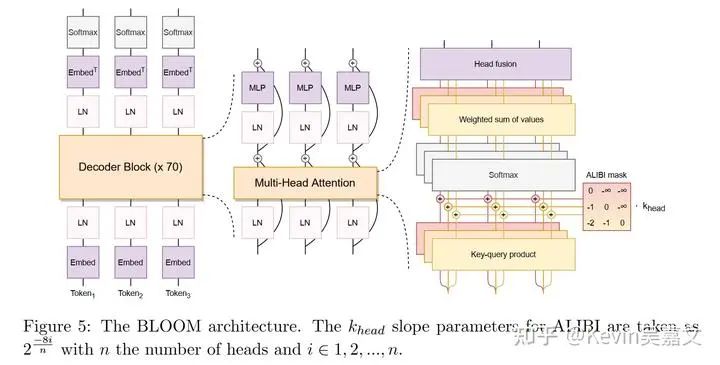
数据:预训练:498 个 huggingface 数据集,1.6 TB 文本(涵盖 46 种语言和 13中编程语言);BLOOMz 在多语言多任务数据集上额外进行了训练。
效果:
superGLUE 的评分图:
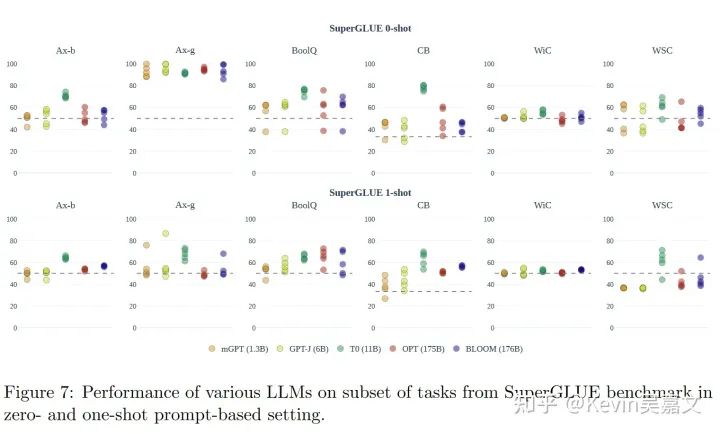
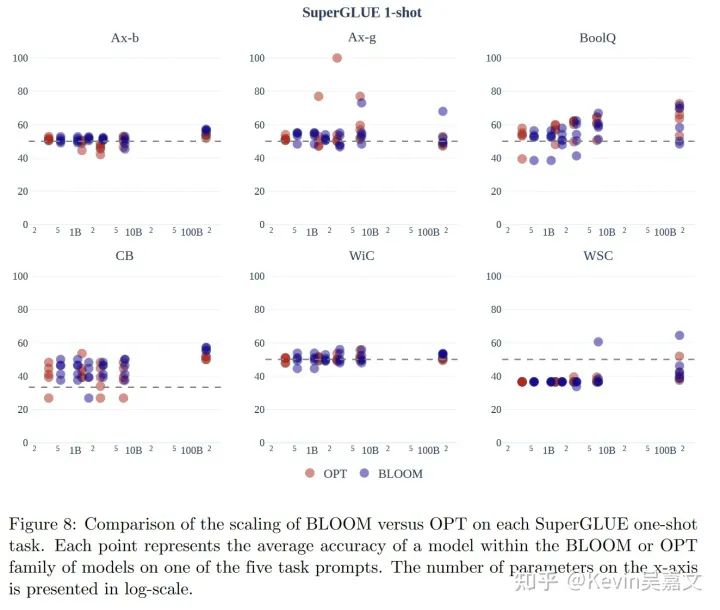
文中还有其他评分任务,总体看来, BLOOM 效果好于 OPT。 不同规格的 BLOOM 效果差距还是很大的。
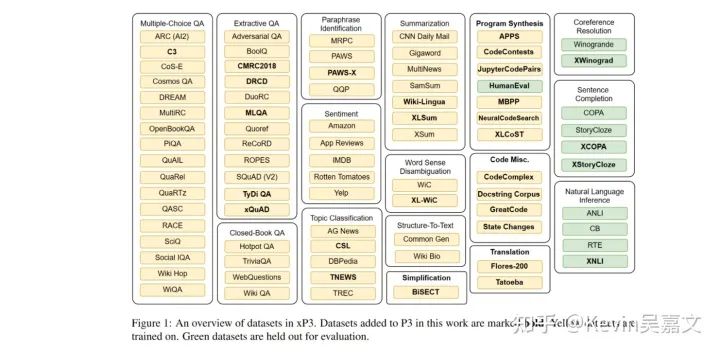
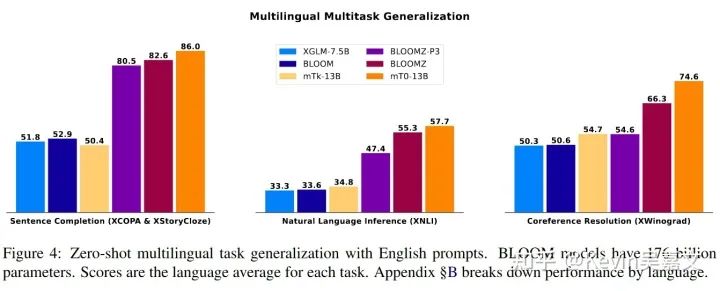
Bloomz/mT0
论文: Crosslingual Generalization through Multitask Finetuning
在 BLOOM 和 mT5 上实验了 Multitask prompted finetuning 的效果。
模型:实验的都是多语言模型,文中使用了 BLOOM 和 mT5
数据:仍然采用公开数据集
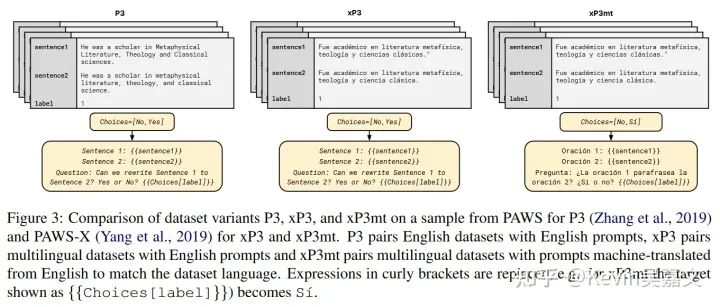
prompt finetuning 采用的 prompt 也被分成三种形式进行测试:
结果:
对照上图文中对比了三种模型的结果:BLOOMZ-P3 (prompt数据为 P3 数据),BLOOMZ(prompt数据为 xP3 数据),BLOOMZ-MT(prompt数据为 xP3mt 数据)。
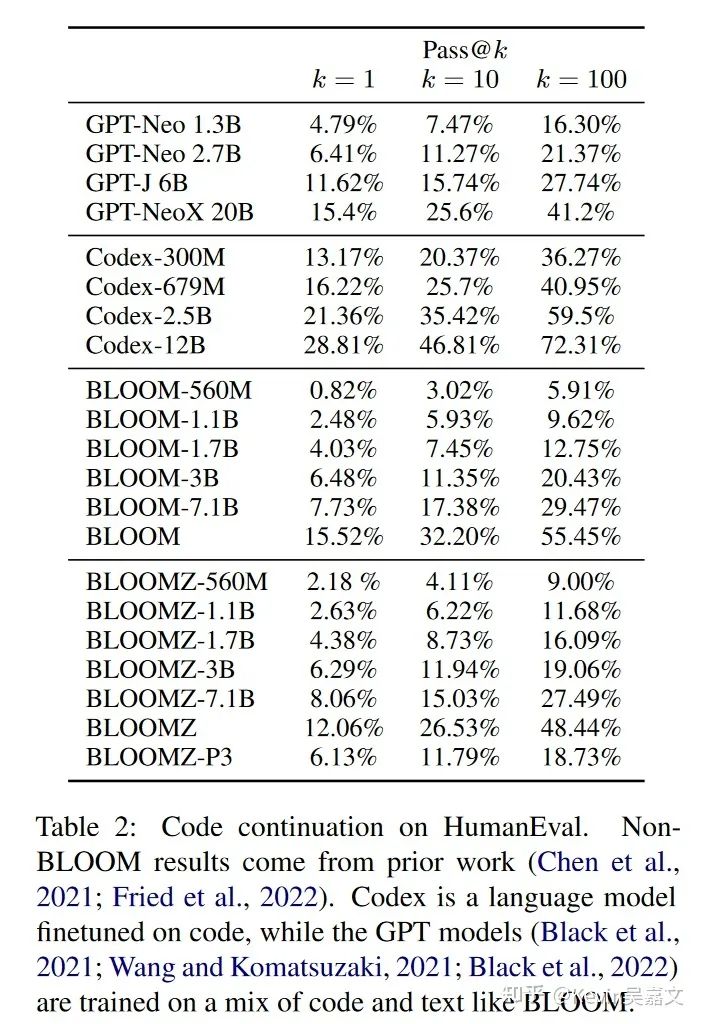
论文中没有找到直接与 GPT 对比的实验,但根据下面的 code 续写成绩来看,BLOOM系列和 GPT 差距应该不小。
SELF-INSTRUCT
论文: Aligning Language Model with Self Generated Instructions
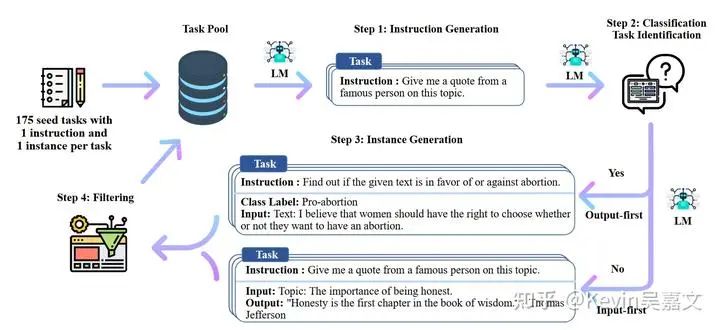
大致数据生成流程:

数据:82k sample,52k instruction
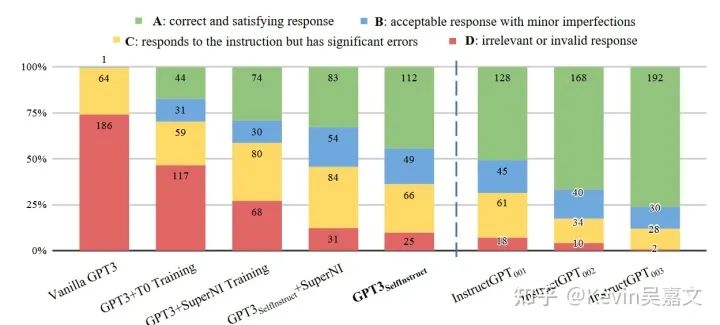
论文中基于 ROUGE-L 进行的结果对比不太公平,毕竟数据集是冲着低 ROUGE-L 去做的。还是参考下图的人工评测结果好点。self-instruct 后 GPT-3 效果能够接近 InstructGPT-001,同时在 self-instruct 数据集上训练的效果会好于在公开数据集上训练的效果:
Alpaca 中稍微修改了 self-instruct 生成数据的方式。一共使用 52K instruction 即 sample 对 LLAMA 进行训练,花费 3 hours on 8 80GB A100s。
BELLE 基于 BLOOMz-mt 进行了中文微调,根据论文实验的结果看来,想要达到 ALPACA 类似的成绩,可能有点悬。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 265
265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









