







前言
最近的课程设计是与数字人有关的项目,这里简短记录一下如何实现一个数字人,希望能帮大家规避一些坑(´▽`ʃ♡ƪ)
主要参考了如下教程:
用Audio2Face导出驱动MetaHuman的面部动画_metahuman audio2face、-CSDN博客
https://blog.csdn.net/Wenhao_China/article/details/135369976
https://github.com/metaiintw/build-an-avatar-with-ASR-TTS-Transformer-Omniverse-Audio2Face
https://blog.csdn.net/ljason1993/article/details/129995288
环境配置
具体的环境配置已经在上述链接中提到,流程如下
-
下载Omniverse
-
在Omniverse中下载audio2face
-
下载如果卡条的话就进入log中找到下载链接,直接从链接下载,然后删除原有的zip包,具体流程可以看相关教程(‾◡◝)
-
编程环境,下载一个pyhton3.8以上的虚拟环境吧,稳妥一点,然后就pip install openai(具体的实现代码可以参考我下方的实现)但是api-key可得自己充钱哦✪ ω ✪,教程在这: https://api-docs.deepseek.com/zh-cn/updates/
-
如果想自己体验捏脸的乐趣的话,可以在metahuman官网捏一个 https://metahuman.unrealengine.com/mhc ,然后导入ue,或者直接下载现成的 https://www.fab.com/listings/0281d63e-71f7-4e07-a344-5fa721ac4d35 登录自己的epic账号下载即可
-
差点儿忘了,记得下载一个UE5.3(o゜▽゜)o☆,因为要和audio2face的插件适配上,我们首先要在关联Audio2Face的目录中找到适配UE版本的插件
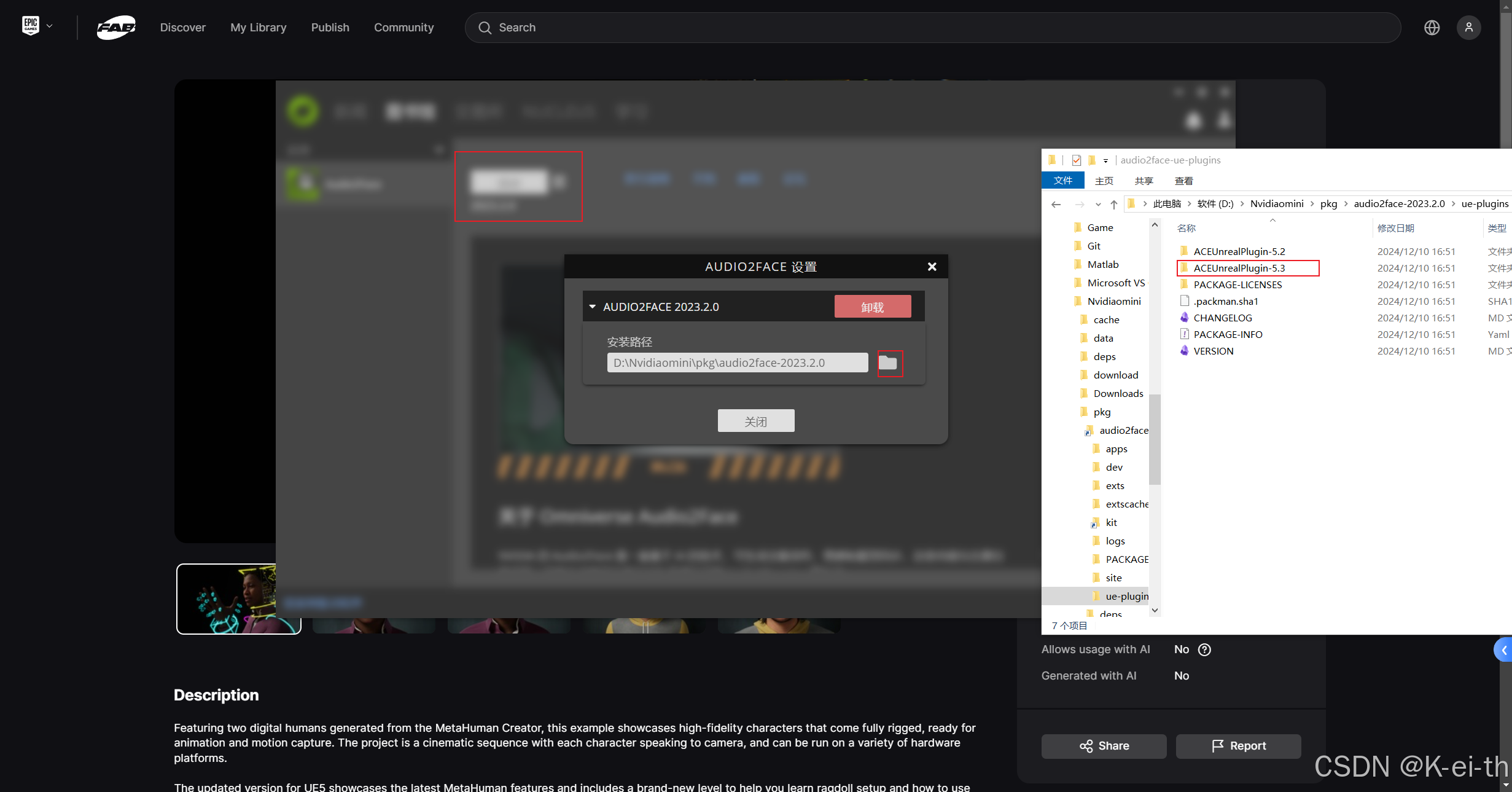
-
然后把插件拷贝到UE对应的插件目录下
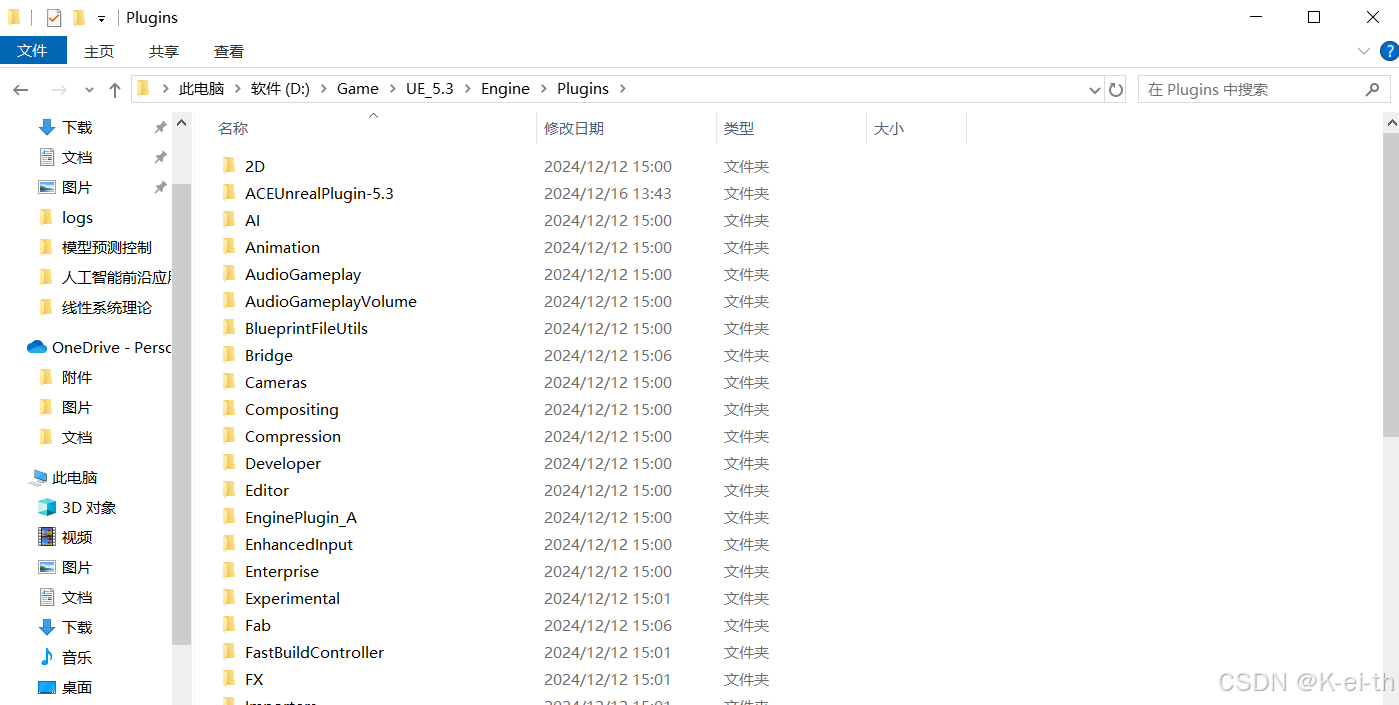
模型关联流
经过上述的操作之后我们终于可以看数字人张嘴啦(bushi,接下来让我们启动audio2face!
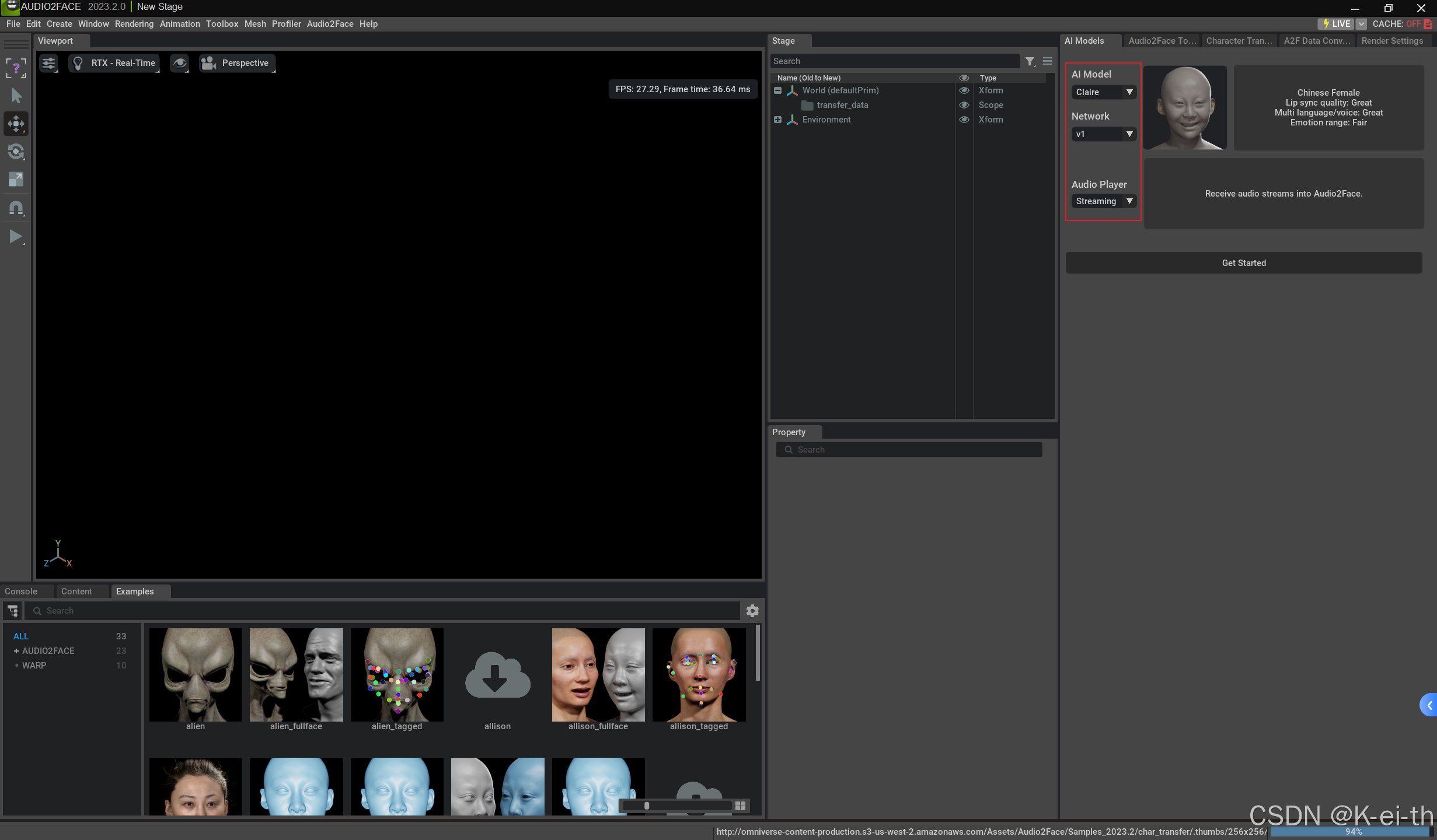
首先咱们要在AI Model中选择亚洲人面孔(看你项目情况嗷ヾ(•ω•`)o
选择流式输入,然后get started!
导入带有求解器的usd文件(或许你们在example里能下载成功?我不行所以就是自己导入的,加这个群里面有捏 http://qm.qq.com/cgi-bin/qm/qr?_wv=1027&k=q1-5RLm0FRt75SI2irLx3Lw3A9Ic0gcS&authKey=NKcPb4%2FrUtsuYFmxnxY8kv%2BrY8MT7p4H2KdLnZ%2BIK0MIUmB8QQ0s4mfN%2BcaAAPBP&noverify=0&group_code=547033086)
或者这个 https://forums.developer.nvidia.com/t/mark-solved-arkit-audio2face-2023-1-0-is-not-working/261116
btw USD 文件通常是文本格式(ASCII)或二进制格式,核心组件包括:
- 几何体描述(如网格、曲线)
- 材质和着色
- 动画和变换
- 场景分层(Layers)
- 引用和实例
- 变体(Variants)
导入之后我们在StreamLivelink中选择激活,然后记住端口号,这个后面要和UE中的插件关联起来
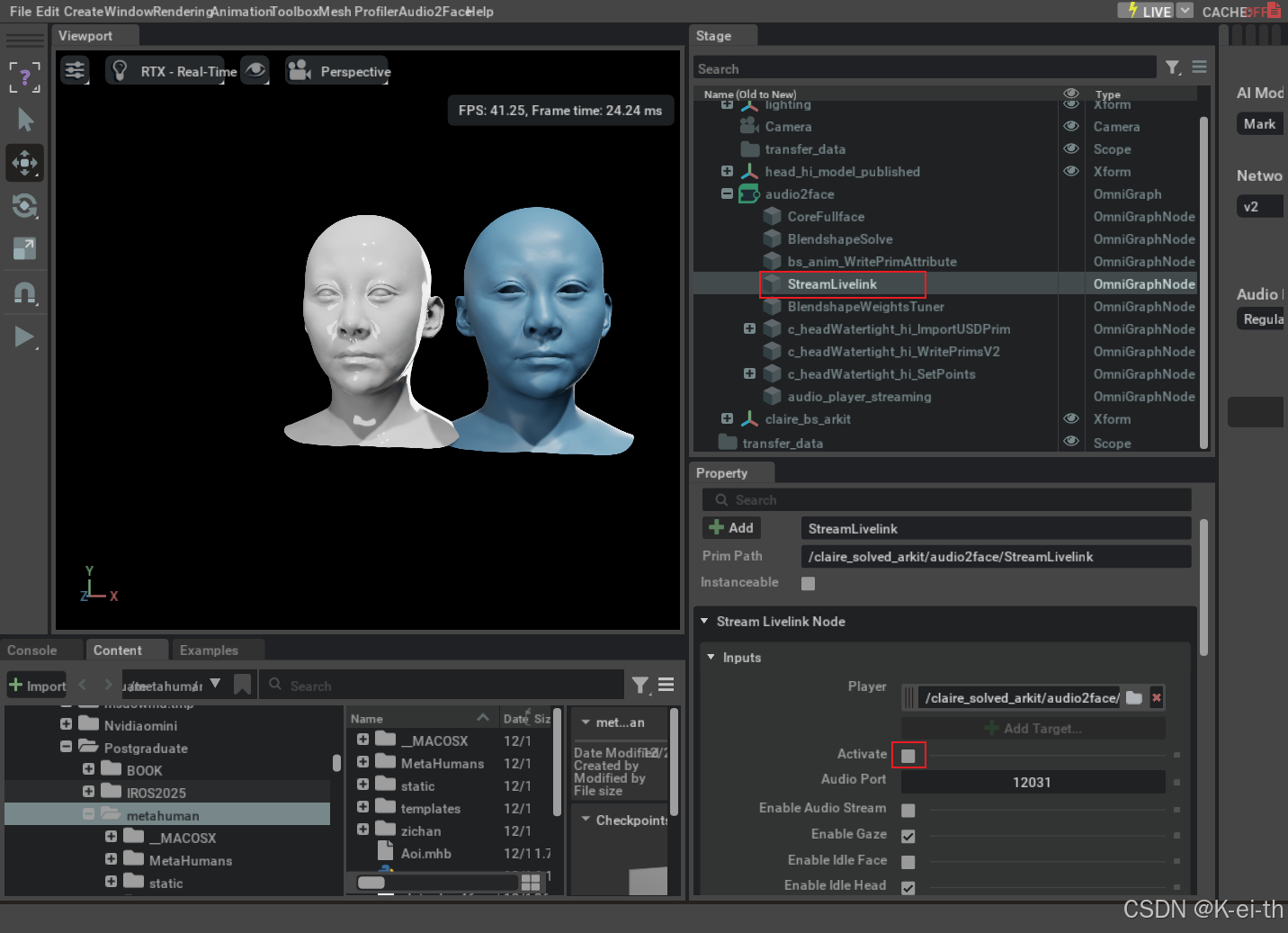
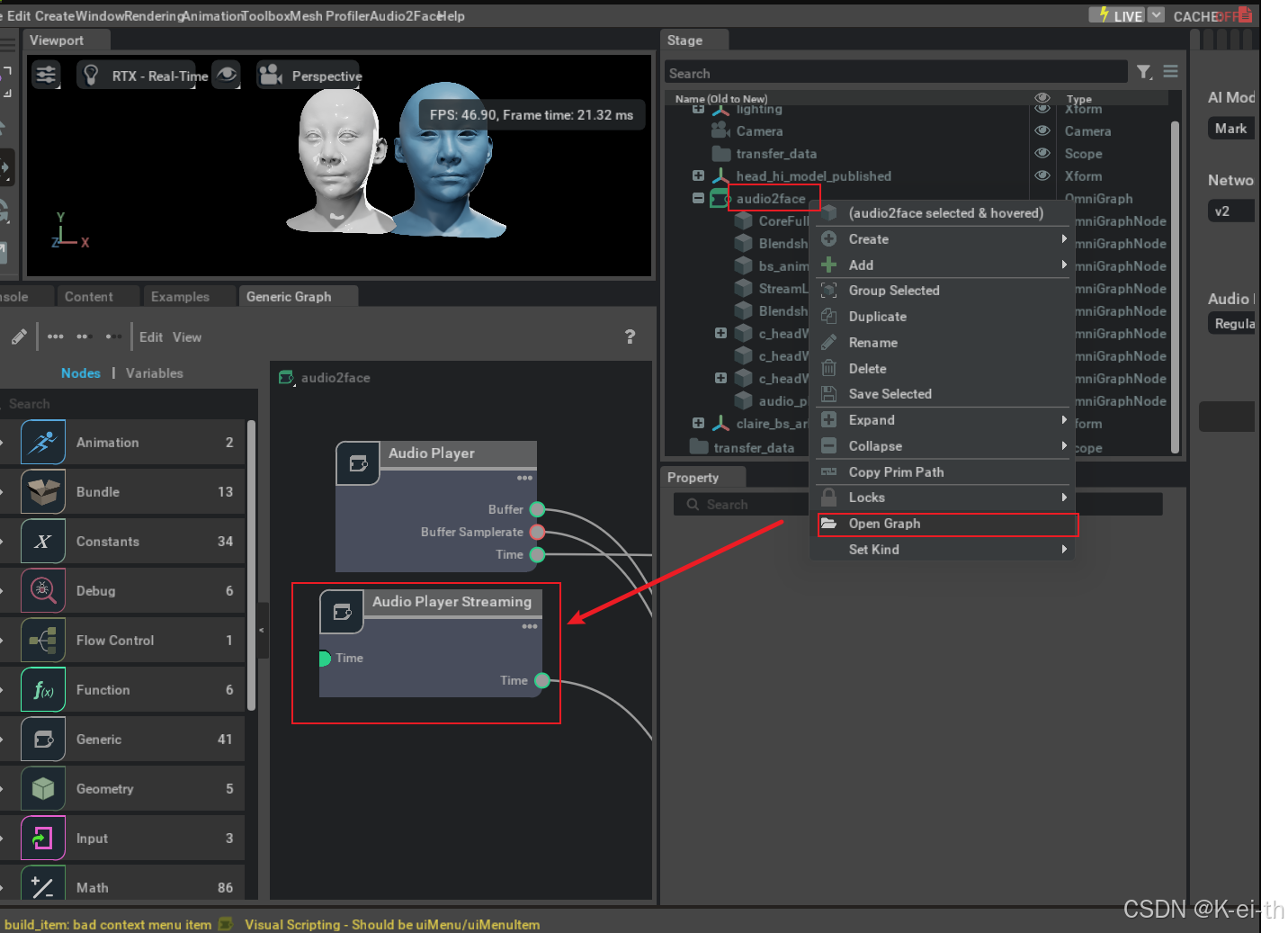
接着我们打开audio2face组件,加入一个音频流播放模块
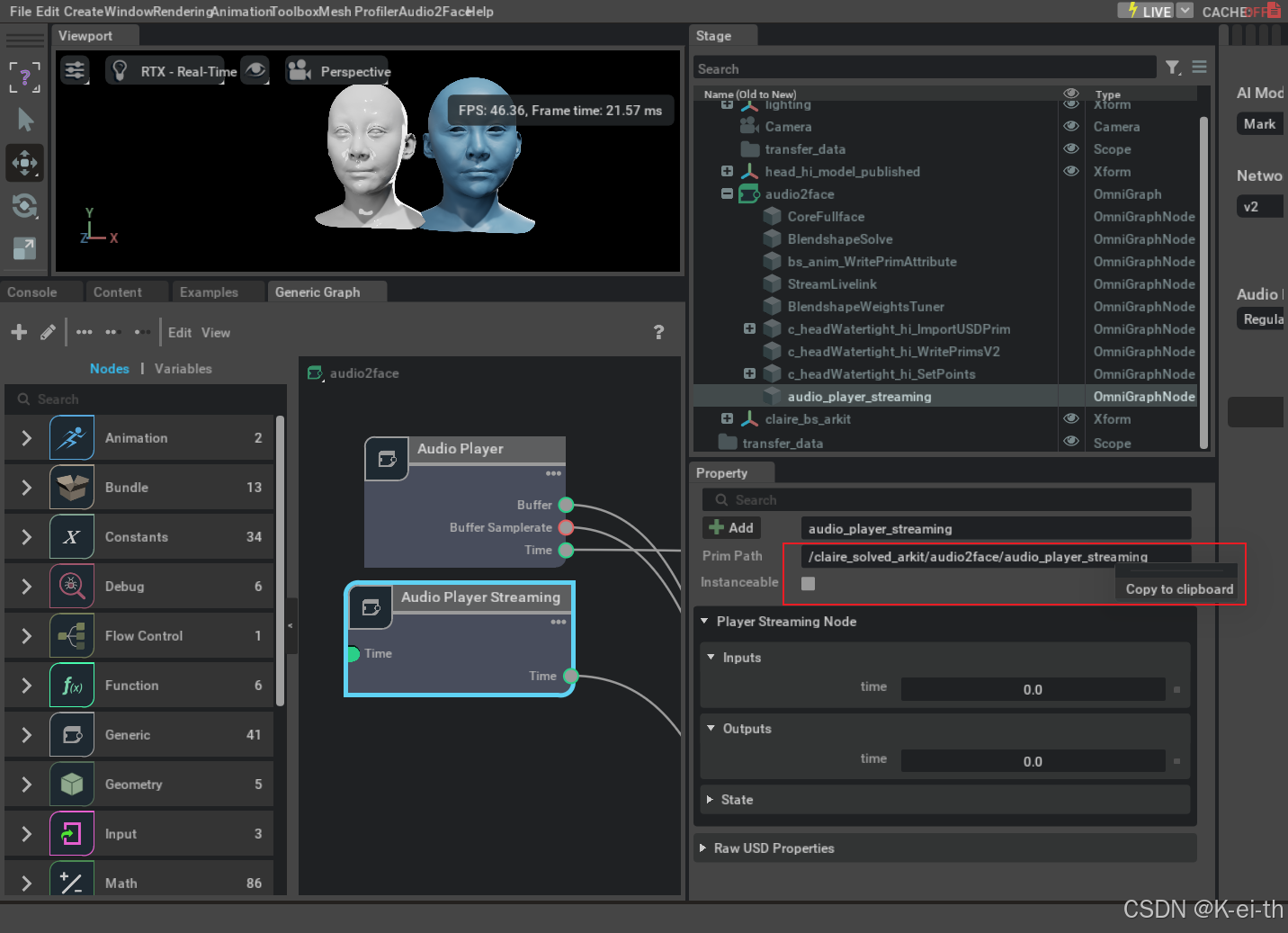
然后咱们还要记住这个路径,后续进行通讯需要用到(●’◡’●)
UE部分
接下来让我们打开UE,把捏好的数字人导入
通过Quixel插件导入我们创建好的数字人到我们的空白关卡中
在插件中添加Audio2face插件,然后重启
紧接着打开Livelink源
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 717
717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









