







 本文深入解析残差网络如何解决深度学习中常见的梯度消失问题,通过引入跳跃连接,确保梯度在深层网络中有效传递,实现网络深度增加而性能不降。同时对比普通神经网络与残差网络结构,阐述其原理与优势。
本文深入解析残差网络如何解决深度学习中常见的梯度消失问题,通过引入跳跃连接,确保梯度在深层网络中有效传递,实现网络深度增加而性能不降。同时对比普通神经网络与残差网络结构,阐述其原理与优势。
卷积神经网络进阶用法---残差网络如何解决梯度消失问题
前言
我在三个月前写了关于卷积神经网络的系列文章,受到了很大的关注,深感荣幸。说明当前读者对深度学习的关注度是相当高的,之前的系列文章主要是关于卷积神经网络的基础概念介绍。其实实际工作中,卷积神经网络有很多的变形和进化,作者通过阅读大量的文献,整理出来一些心得,写在这里与诸君分享。如有错误,还请诸位大神指正。
以下为我之前写的关于CNN卷积神经网络的文章链接:
CNN卷积神经网络原理详解(上)
CNN卷积神经网络原理详解(中)
CNN卷积神经网络原理详解(下)
言归正传,下面开始今天的正文。
道路千万条,好用第一条
看过我上述博客的读者,或者对卷积神经网络有基本概念的读者应该都知道,神经网络是当前人工智能解决图像识别、语义识别等课题重要的手段之一。卷积神经网络如此重要,但是在它刚出现的时候,却存在很多缺陷,尤其是当网络较深时候会发生梯度消失/爆炸等问题。为了解决这些问题,科研工作者后来在经典卷积网络的基础上又进行了大量的优化工作。

图一
上图中提到的就是一些应用较为广泛的改进策略。本系列博文拟打算从原理上对这些方法策略进行逐一说明,考虑到篇幅原因,这些策略的实际应用会单独另开博客,本文不提。
本文重点介绍残差网络的内容,希望通过本文的介绍,让大家对残差网络有一个直观的理解。通过阅读本文,您会了解:1,残差网络解决了哪些问题;2,残差网络为何会有作用。
残差网络和跳跃连接
梯度消失问题
深度学习之所以叫深度学习,就是因为理论上网络越深,效果越好。当然,这是理论上的说法。实际情况却是:(1)随着网络的加深,增加了大量的参数,导致计算性能严重下降;(2)在网络优化的过程中,出现梯度消失或者梯度爆炸等现象。
这一小节跟大家介绍的残差网络则很好的解决了梯度消失的问题。
本节主要内容:
1,为何会出现梯度消失现象?
2,残差网络如何解决梯度消失问题?
关于为何出现梯度消失现象,大家不妨先来看一组动图。

图二

图三

图四

图五
图二虚线框为一个神经元block,假设输入
x
x
x为10,权重
w
1
=
0.1
w1=0.1
w1=0.1,
w
2
=
0.1
w2=0.1
w2=0.1,
w
3
=
0.1
w3=0.1
w3=0.1,
w
4
=
0.1
w4=0.1
w4=0.1,每个神经元对输入的操作均为相乘。现在我们来看一下这一组神经元在前向传播和后向传播的过程中都发生了什么事情。
先看动图三,这是前向传播的过程,很简单,就是一开始输入
x
=
10
x=10
x=10,先和第一个权重
w
1
=
0.1
w_{1}=0.1
w1=0.1相乘,得到1,再和权重
w
2
=
0.1
w_{2}=0.1
w2=0.1相乘得到0.1,依次类推,最后和
w
4
=
0.1
w_{4}=0.1
w4=0.1相乘得到0.001. 这个过程不再赘述。
我们重点来看动图四(需要强调一点的是,假设从下一层网络传回来的梯度为1,最右边的数字)。为了便于说明,我把动图四呈现的内容固定为了图五。其中线程上的黑色数字是前向传播的结果,前面已经讲过。现在重点说明一下绿色和红色数字是怎么得到的。
红色数字代表了权重
w
w
w的梯度,计算过程如下:
▽
w
4
L
=
d
L
5
d
w
4
=
d
L
5
d
L
4
×
d
L
4
d
w
4
=
1
×
0.01
=
0.01
\bigtriangledown _{w_{4}}L=\frac{dL_{5}}{dw_{4}}=\frac{dL_{5}}{dL_{4}}\times \frac{dL_{4}}{dw_{4}}=1\times0.01=0.01
▽w4L=dw4dL5=dL4dL5×dw4dL4=1×0.01=0.01
其中
d
L
5
d
L
4
=
1
\frac{dL_{5}}{dL_{4}}=1
dL4dL5=1,回传梯度为1,上文有说明;
▽
w
3
L
=
d
L
5
d
w
3
=
d
L
5
d
L
4
×
d
L
4
d
L
3
×
d
L
3
d
w
3
=
1
×
0.1
×
0.1
=
0.01
\bigtriangledown _{w_{3}}L=\frac{dL_{5}}{dw_{3}}=\frac{dL_{5}}{dL_{4}}\times \frac{dL_{4}}{dL_{3}}\times \frac{dL_{3}}{dw_{3}}=1\times0.1\times0.1=0.01
▽w3L=dw3dL5=dL4dL5×dL3dL4×dw3dL3=1×0.1×0.1=0.01
▽
w
2
L
=
d
L
5
d
w
2
=
d
L
5
d
L
4
×
d
L
4
d
L
3
×
d
L
3
d
L
2
×
d
L
2
d
w
2
=
1
×
0.1
×
0.1
×
1
=
0.01
\bigtriangledown _{w_{2}}L=\frac{dL_{5}}{dw_{2}}=\frac{dL_{5}}{dL_{4}}\times \frac{dL_{4}}{dL_{3}}\times \frac{dL_{3}}{dL_{2}}\times \frac{dL_{2}}{dw_{2}}=1\times 0.1\times 0.1\times 1=0.01
▽w2L=dw2dL5=dL4dL5×dL3dL4×dL2dL3×dw2dL2=1×0.1×0.1×1=0.01
▽
w
1
L
=
d
L
5
d
w
1
=
d
L
5
d
L
4
×
d
L
4
d
L
3
×
d
L
3
d
L
2
×
d
L
2
d
L
1
×
d
L
1
d
w
1
=
1
×
0.1
×
0.1
×
0.1
×
10
=
0.01
\bigtriangledown _{w_{1}}L=\frac{dL_{5}}{dw_{1}}=\frac{dL_{5}}{dL_{4}}\times \frac{dL_{4}}{dL_{3}}\times \frac{dL_{3}}{dL_{2}}\times \frac{dL_{2}}{dL_{1}}\times \frac{dL_{1}}{dw_{1}}=1\times0.1\times0.1\times0.1\times10=0.01
▽w1L=dw1dL5=dL4dL5×dL3dL4×dL2dL3×dL1dL2×dw1dL1=1×0.1×0.1×0.1×10=0.01
绿色数字代表传播路径上输入值的梯度,计算过程如下:
L
5
=
X
×
w
1
×
w
2
×
w
3
×
w
4
×
w
5
L_{5}=X\times w_{1}\times w_{2}\times w_{3}\times w_{4}\times w_{5}
L5=X×w1×w2×w3×w4×w5
L
4
=
X
×
w
1
×
w
2
×
w
3
×
w
4
L_{4}=X\times w_{1}\times w_{2}\times w_{3}\times w_{4}
L4=X×w1×w2×w3×w4
L
3
=
X
×
w
1
×
w
2
×
w
3
L_{3}=X\times w_{1}\times w_{2}\times w_{3}
L3=X×w1×w2×w3
L
2
=
X
×
w
1
×
w
2
L_{2}=X\times w_{1}\times w_{2}
L2=X×w1×w2
L
1
=
X
×
w
1
L_{1}=X\times w_{1}
L1=X×w1
▽
L
4
L
5
=
w
5
=
1
\bigtriangledown_{L_{4}}L_{5}=w_{5}=1
▽L4L5=w5=1
▽
L
3
L
5
=
w
5
×
w
4
=
0.1
\bigtriangledown_{L_{3}}L_{5}=w_{5}\times w_{4}=0.1
▽L3L5=w5×w4=0.1
▽
L
2
L
5
=
w
5
×
w
4
×
w
3
=
0.01
\bigtriangledown_{L_{2}}L_{5}=w_{5}\times w_{4}\times w_{3}=0.01
▽L2L5=w5×w4×w3=0.01
▽
L
1
L
5
=
w
5
×
w
4
×
w
3
×
w
2
=
0.001
\bigtriangledown_{L_{1}}L_{5}=w_{5}\times w_{4}\times w_{3}\times w_{2}=0.001
▽L1L5=w5×w4×w3×w2=0.001
▽
X
L
5
=
w
5
×
w
4
×
w
3
×
w
2
×
w
1
=
0.0001
\bigtriangledown_{X}L_{5}=w_{5}\times w_{4}\times w_{3}\times w_{2}\times w_{1}=0.0001
▽XL5=w5×w4×w3×w2×w1=0.0001
其实就是遵循一个链式法则
这就是梯度消失。假如模型的层数越深,这种梯度消失的情况就更加严重,导致浅层部分的网络权重参数得不到很好的训练,这就是为什么在残差网络出现之前,CNN网络都不超过二十几层的原因。
那么问题来了,残差网络是如何解决梯度消失的问题的?我们接着往下看:

图六
图六是针对上述问题改进的一个网络结构,我们在这个block的旁边加了一条“捷径”(如图六橙色箭头),也就是常说的“skip connection”。假设左边的上一层输入为
x
x
x,虚线框的输出为
F
(
x
)
F(x)
F(x),上下两条路线输出的激活值相加为
h
(
x
)
h(x)
h(x),即
h
(
x
)
=
F
(
x
)
+
x
h(x) = F(x) + x
h(x)=F(x)+x,得出的
h
(
x
)
h(x)
h(x)再输入到下一层。
下面我们来具体说一下这么做的原因。
残差网络的原理
什么是残差网络呢?我之前有一篇文章深度学习:白话解释ResNet残差网络,里面对残差网络的基本概念做了解释。
这里我们再回顾一下。

上图就是残差网络的设计思想。通过在一个浅层网络基础上叠加
y
=
x
y=x
y=x 的层(称identity mappings,恒等映射),可以让网络随深度增加而不退化。如图中曲线所示,将浅层的输入值直接连接到端部位置,这样就避免了在层层映射过程中,由于权重小于1而最终导致的梯度消失的现象。
该网络学习的残差函数可以表示为 F ( x ) = H ( x ) + x F(x) = H(x)+ x F(x)=H(x)+x(有些博客也会把它写作 F ( x ) = H ( x ) − x F(x) = H(x)- x F(x)=H(x)−x)。当 F ( x ) = 0 F(x)=0 F(x)=0时,该网络变成恒等映射,考虑到实际情况 F ( x ) F(x) F(x)的取值是趋近与0而不是0,因此,该网络可以看作是恒等映射的一个逼近情况。
我们观察这个网络可以发现,残差网络并不会引入额外的参数也不会增加计算的复杂度。
残差网络的由来
作为一个经典的残差网络Resnet,它最初的灵感是为了解决这样一个问题:随着网络的不断加深,准确率会出现先增长后下降的趋势。导致这个的原因不是过拟合,因为不仅测试集会出现这种情况,训练集也会出现这种情况。
现在我们假设有一个浅层的网络达到了饱和的准确率,此时我们在网络的后面增加几个 y = x y=x y=x的恒等映射,那么不管增加多少层,误差都不会继续增加,因为我们将映射直接从前一层传递到了最后一层。这就是Resnet的灵感来源。
我们假设某段神经网络的输入是 x x x,期望输出为 H ( x ) H(x) H(x),如果我们直接把 x x x传递到输出端,那么我们要学习的目标就是 F ( x ) = H ( x ) − x F(x) = H(x)- x F(x)=H(x)−x,此时目标相当于发生了变更,我们称之为残差。
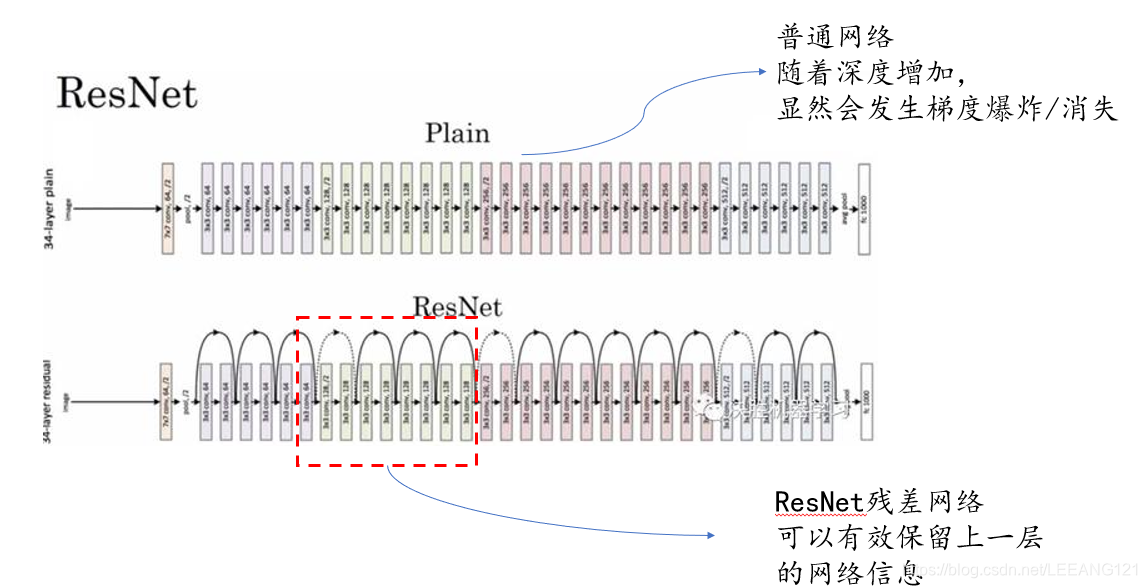
图七

图八
上图(图七和图八)是对普通神经网络和残差网络的结构做了对比,并介绍了残差网络的传递过程。
DenseNet网络
ResNet正是有了这样的Skip Connection,梯度能畅通无阻地通过各个Res blocks,该网络唯一影响深度的就是内存不足,因此只要内存足够,上千层的残差网络也都能实现。
这个问题在DenseNet网络中得到了很好的解决。DenseNet的skip connection不仅仅只连接上下层,直接实现了跨层连接,每一层获得的梯度都是来自前面几层的梯度加成。

DenseNet在增加深度的同时,加宽每一个DenseBlock的网络宽度,能够增加网络识别特征的能力,而且由于DenseBlock的横向结构类似 Inception block的结构,使得需要计算的参数量大大降低。因而此论文获得了CVPR2017最佳论文奖项!
总结
纸上得来终觉浅,得知此事须躬行。
想要深入了解残差网络的原理,我们还需要通过代码实现的方式做一段实际的学习。关于用代码实现残差网络,我会在之后的博客中为大家整理更新,如果您觉得本文有用,欢迎关注,博主会持续更新关于深度学习的相关内容。
后续还会为大家介绍开头图片里面提到的可变形卷积、分组卷积等内容。
本文参考文章:
可变形卷积网络:计算机新‘视’界
如何理解空洞卷积(dilated convolution)?
为什么ResNet和DenseNet可以这么深?一文详解残差块为何有助于解决梯度弥散问题。
极深网络(ResNet/DenseNet): Skip Connection为何有效及其它
深度学习——残差神经网络ResNet在分别在Keras和tensorflow框架下的应用案例
基于深度卷积神经网络和跳跃连接的图像去噪和超分辨
梯度弥散与梯度爆炸
Group Convolution分组卷积,以及Depthwise Convolution和Global Depthwise Convolution


















 4731
4731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











