







 超级会员免费看
超级会员免费看
 本文介绍了如何利用Chrome浏览器的开发者工具查看HTTP请求头信息,以获取网页访问的关键信息,这对于Python爬虫的模拟请求至关重要。通过查看请求URL、Method、Status Code、Request Headers等内容,我们可以更好地理解浏览器与服务器的交互,并在爬虫开发中模拟这些行为。
本文介绍了如何利用Chrome浏览器的开发者工具查看HTTP请求头信息,以获取网页访问的关键信息,这对于Python爬虫的模拟请求至关重要。通过查看请求URL、Method、Status Code、Request Headers等内容,我们可以更好地理解浏览器与服务器的交互,并在爬虫开发中模拟这些行为。
☞ ░ 前往老猿Python博客 https://blog.csdn.net/LaoYuanPython ░
一、开启开发者工具
为了简单处理,本次介绍的内容是基于网站已经登录的情况下去获取网页访问的http信息。
首先需要使用谷歌浏览器登录指定网站,并访问需要爬取的网页,如老猿使用谷歌浏览器登录csdn,并访问老猿Python的主页:https://blog.csdn.net/LaoYuanPython。
等网页内容呈现后,按F12键调出开发者工具,缺省情况下开发者工具会在当前网页右边的叠加窗口呈现,如图黄色标记区域:
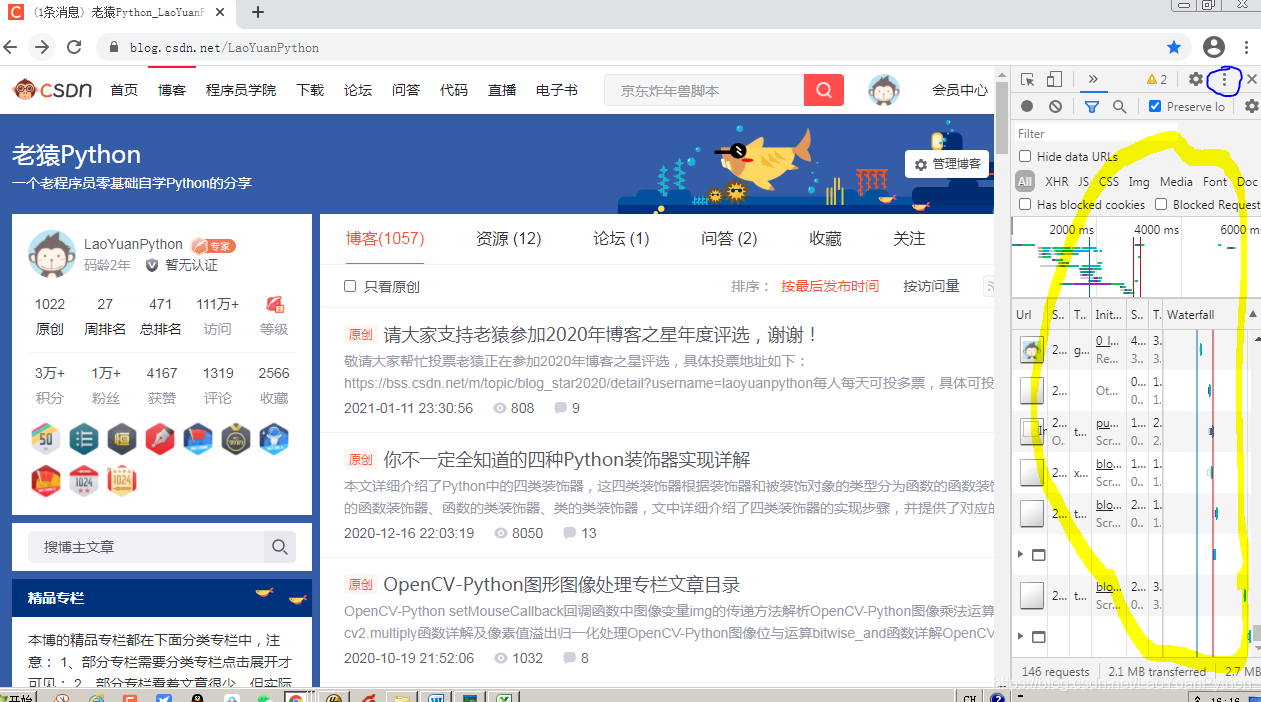
该窗口也可能出现在左边、下边,但这种模式使用不是很方便,可以点击上图中右上角蓝色标记的三个竖点,选择:Dock side(窗口出现位置)中的第一个选项如下:

将开

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











