






<Multimodal Pathway: Improve Transformers with Irrelevant Data from Other Modalities>
论文地址:https://arxiv.org/abs/2401.14405
项目网页:https://ailab-cvc.github.io/M2PT/
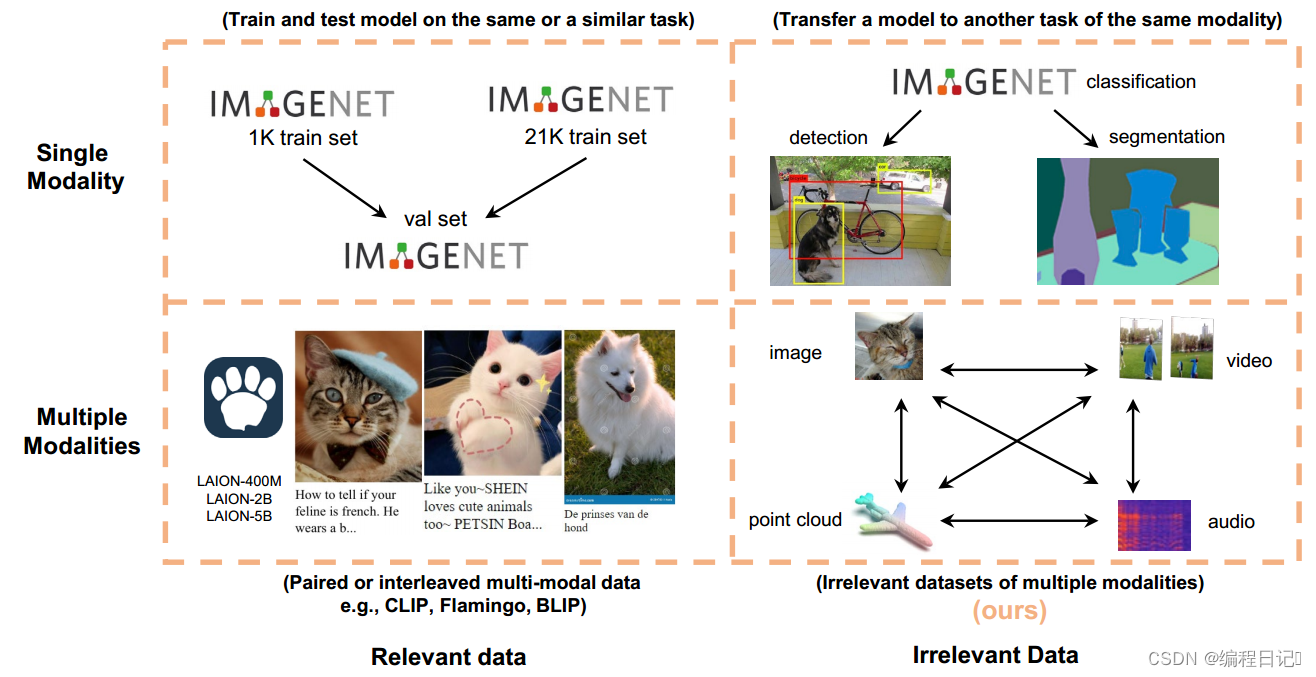
图1:与使用对齐良好的多模态数据的已知范式相比,本文关注的是数据样本来自多个模态但不相关的场景,这是文献中的一个开放问题。
一、核心概念
- 目标模态与辅助模态:目标模态是指我们想要改进性能的模型的模态,例如图像。辅助模态则是与目标模态不相关的其他模态的数据,例如音频或点云数据。
- 多模态路径(Multimodal Pathway):这是一种连接目标模态Transformer和辅助模态Transformer的结构,允许目标模态数据通过两个模型的组件进行处理,从而获得两种模态的序列到序列建模能力。
- 跨模态重参数化(Cross-Modal Re-parameterization):这是一种技术手段,利用辅助模态的Transformer块,无需任何推理成本即可提升目标模态的性能。
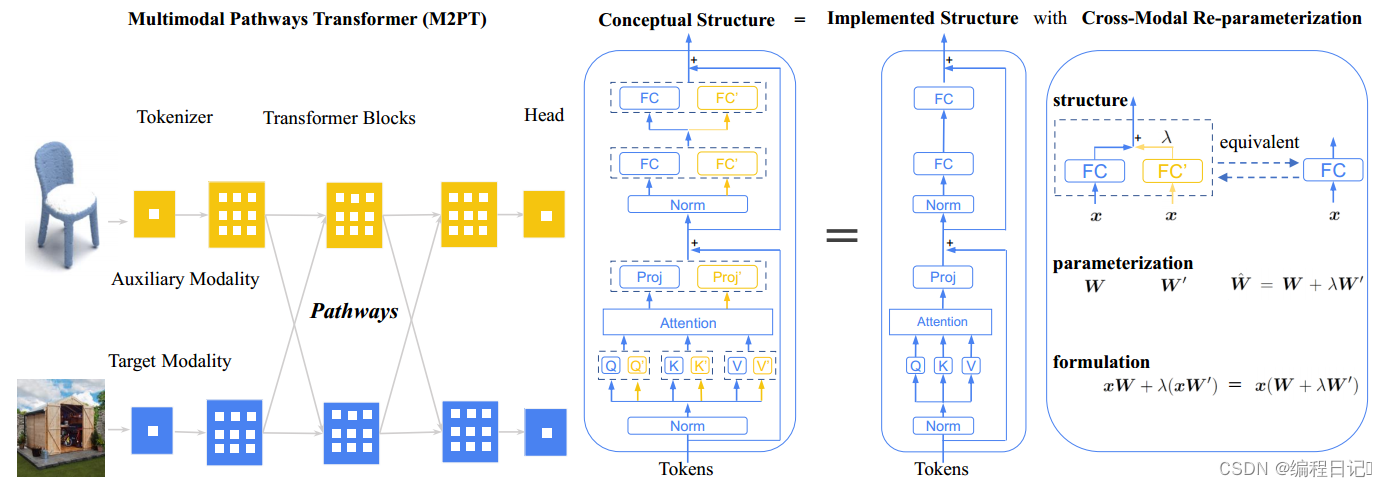
图2:(左) 多模态通路变压器(M2PT)框架。以点云和图像模态为例。transformer的常用做法遵循相同的流程:使用1)标记器将输入数据转换为序列,2)转换器块处理序列,3)磁头解码序列。通过建立不同模态组件之间的路径来升级序列到序列建模,以便处理特定模态的令牌可以利用与另一模态训练的转换块。
(中) M2PT的概念设计,其中路径是通过让目标模型中的线性层(包括注意力块中的查询/键/值/投影层和FFN块中的线性层)与辅助模型中的对应层合作来实现的。
(右) 跨模态重参数化通过将目标模型的权重与辅助模型的权重重新参数化,引入边际训练成本,完全没有推理成本,有效地实现了M2PT。
本文提出了一个简单而有效的M2PT实现,其中关键是连接两个模型的路径的具体实现。如上所述,由于通用建模能力,不同模态上的transformer可能具有不同的标记器,但它们的主体(即transformer块)可能具有相同的结构。对于与主体结构相同的目标模型和辅助模型,前者主体中的一层在后者中应该有对应的一层。例如,目标模型的第9块中的Query层的对应物,即辅助模型中的第9个Query层应该存在,并且它们在两个模型中扮演类似的角色。考虑到这一点,通过将目标模型的transformer块中的每个线性层与辅助模型中的对应层进行扩充来建立两个模型之间的连接。在这样的概念设计中,让两个层接受相同的输入并将它们的输出相加,如图2(中间)所示。
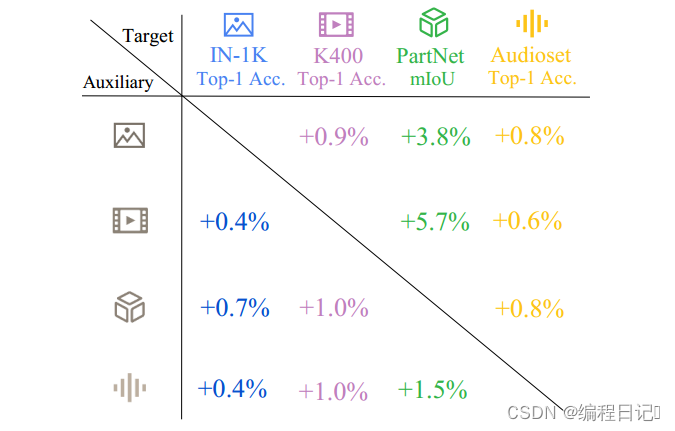
图3:M2PT在图像、视频、点云和音频这四种模式上带来了一致的改进。这些指标分别是ImageNet-1K精度、Kinetics-400精度、PartNet mIoU和AudioSet精度。这些数字分别代表了M2PT模型相对于使用mastyle方法[22、23、30、49]在四种模式上预训练的基线模型的性能的改进百分比。
本文尝试了图像、视频、点云和音频模式。图3显示了M2PT在四种模式中一致带来的相对改进。这些结果表明,变压器中序列对序列建模的模态互补知识是存在的。
作为早期的探索,我们的实证研究证实,这种改进不仅仅是由于更多的参数,并且表明这种模态互补知识可能与一般处理分层表示的能力有关。抽象层次以多种形式存在,概念从低级到高级,这可以解释所学知识的普遍性。换句话说,当转换器使用图像进行训练时,它既学习(能力a)如何理解图像,又学习(能力B)如何将标记从低级模式转换为高级模式,而不假设它们最初来自图像。
同时,由于另一个Transformer正在用音频数据进行预训练,它对音频学习了不同的“能力a”和相似的“能力B”,从而可以帮助前面提到的Transformer进行图像识别。
二、方法论
-
模态特定的分词器和任务特定的头部:如同常规的Transformer模型,使用模态特定的分词器来处理输入数据,将其转换为序列(即tokens),并使用任务特定的头部来进行最终的任务(如分类、检测等)。
-
利用辅助模态的知识:通过将目标模态的Transformer与一个已经在辅助模态数据上训练好的Transformer连接起来,目标模态可以通过跨模态重参数化技术,利用辅助模态模型的权重来增强其性能。
三、重要性与贡献
- 开拓新领域:这篇论文探索了一个较少被研究的领域——如何利用与目标模态不相关的数据来改进模型性能,这在以往的研究中是一个未被充分探讨的问题。
- 通用模型能力的展示:这项工作进一步证明了Transformer的通用序列到序列建模能力,即使是在跨模态的情况下也能够有效。
四、结论
这篇论文提出的多模态路径方法为利用跨模态数据来改进特定模态的Transformer模型提供了一种新的视角和方法。通过引入辅助模态的知识,即使这些数据与目标任务不直接相关,也能显著提升目标模态的模型性能。这不仅展示了Transformer的强大通用性,也为未来的多模态学习研究开辟了新的方向。

















 815
815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











