






一、下采样与上采样。
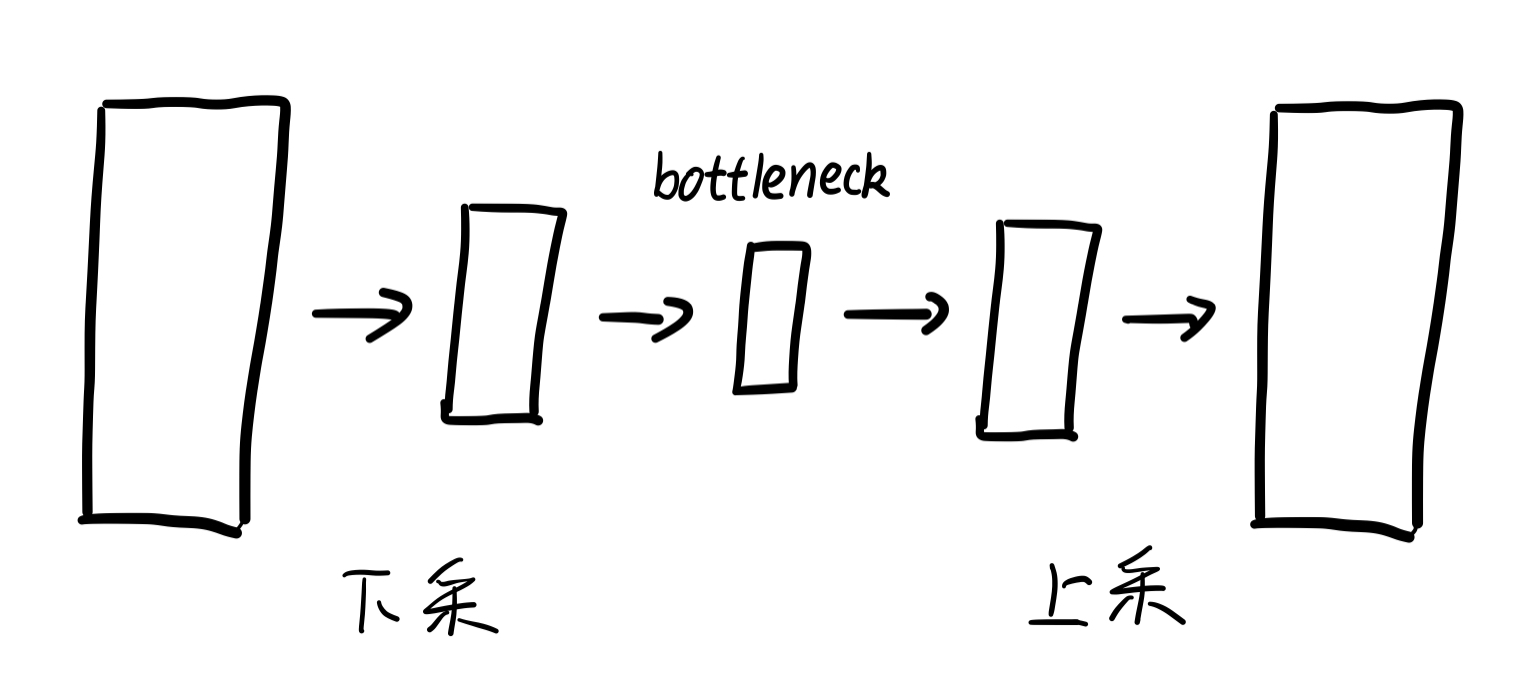
下采样(subsampled)又称为降采样(downsampled),即抽取特征 缩小图像尺寸,减少矩阵的采样点数。
有两个作用:减少计算量,防止过拟合;增大感受野,使得后面的卷积核能够学到更加全局的信息。
常用方法:1、加入池化层,如Max-pooling(相比平均池化,最大池化计算简单而且能够更好的保留纹理特征);
2、加入卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
上采样(upsampling)又称为插值(interpolating),即放大图像,增加矩阵的采样点数,是下采样的逆向操作。在卷积神经网络中,由于输入图像通过CNN提取特征后,输出的尺寸往往会变小,而有时需要将图像恢复到原来的尺寸以便进行进一步的计算(如图像的语义分割),这个使图像由小分辨率映射到大分辨率的操作。
常用方法:1、插值,一般使用的是双线性插值,效果最好,计算上比其他插值方法稍微复杂,但不值一提,其他插值方式还有最近邻插值、三线性插值等;
2、转置卷积又名反卷积(Transpose Conv),通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大;
3、Up-Pooling - Max Unpooling && Avg Unpooling --Max Unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0
二、token
在NLP输入一段句子,分词器会将句子中的单词、符号转换成一个个token,可以认为每一个单词是一个token,然后还有一个标注句子语义的标注cls。
在CV领域,不能直接把每个像素看作一个token(token太多了,远超BERT的上限512个),所以ViT把图像切割成一个个16x16的patch(具体数值可以修改),每个patch块看作是一个token。
三、embedding
在深度神经网络中,Embedding层可以理解为一个高维向量向低维向量的映射,即高维稀疏特征向量到低维稠密特征向量的转换。
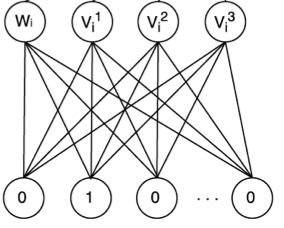
稀疏one hot向量向稠密向量的映射
将Embedding层与整个深度学习网络整合后一同进行训练是理论上最优的选择,因为上层梯度可以直接反向传播到输入层,模型整体是自洽和统一的。但这样做的缺点同样显而易见的,由于Embedding层输入向量的维度甚大,Embedding层的加入会拖慢整个神经网络的收敛速度。
因此,Embedding层往往采用预训练的方式完成。Embedding的训练往往独立于深度学习网络进行。在得到稀疏特征的稠密表达之后,再与其他特征一起输入神经网络进行训练。
和传统的降维方法如PCA相比,Embedding优势?
因为梯度下降的训练方式,Embedding更能够利用在大数据集上,适合海量数据和特征;
Eembedding可以学习到序列(或者图)中的行为语义和结构信息,其灵活性和表达性较强;
pca主要是依靠多属性的线性组合降维,这样的降维是为了样本之前的区分度最大,其处理稀疏样本的能力并不好,且对于one-hot场景 pca并不适合。
四、Concatenation
Concatenation拼接,是将新向量拼接到原来的向量之后,对应着维数增加。
五、BatchNorm和LayerNorm
BatchNorm: 对一个batch-size样本内的每个特征做归一化;
LayerNorm: 针对每个样本,对每个样本的所有特征做归一化。
简单举例:
假设现在有个二维矩阵:行代表batch-size, 列表示样本特征:
BatchNorm就是对这个二维矩阵中每一列的特征做归一化,也就是竖着做归一化;
LayerNorm就是对这个二维矩阵中每一行数据做归一化。
相同点: 都是在深度学习中让当前层的参数稳定下来,避免梯度消失或者梯度爆炸,方便后面的继续学习。
不同点:
1、如果你的特征依赖不同样本的统计参数,那BatchNorm更有效, 因为它不考虑不同特征之间的大小关系,但是保留不同样本间的大小关系。
2、Nlp领域适合用LayerNorm, CV适合BatchNorm,
3、对于Nlp来说,LayerNorm不考虑不同样本间的大小关系,保留样本内不同特征之间的大小关系。
六、对比学习损失以及温度超参τ
InfoNCE对比损失:

InfoNCE, 又称global NCE, 继承了NCE的基本思想,从一个新的分布引入负样例,构造了一个新的多元分类问题,并且证明了减小这个损失函数相当于增大互信息(mutual information)的下界,这也是名字infoNCE的由来。
加入τ后也就是:
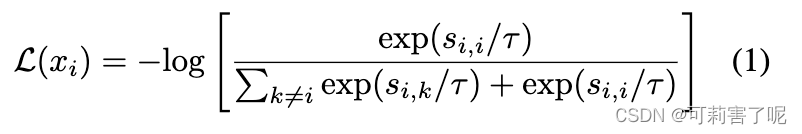
其中τ是温度系数。直观来说,该损失函数要求第i个样本和它的正样本i之间的相似度尽可能大,而与其他的实例(负样本k)之间的相似度尽可能小。
显而易见,infoNCE最后的形式就是多元分类任务常见的交叉熵(cross entropy)softmax 损失。因为表示已经归一化,据前所述,向量内积等价于向量间的距离度量。故由softmax的性质,上述损失就可以理解为,我们希望在拉近原样例与正样例距离的同时,拉远其与负样例间的距离,这正是对比学习的思想。
温度超参τ用什么作用?
τ为softmax的温度超参,并不是原始InfoNCE损失的组成部分,它被引入的一个重要前提假设就是“不完全信任用户的点击标签”,意在控制模型对标签的信任程度,越小(趋向于0),则越信任,反之则越不信任。
τ越小,softmax越接近真实的max函数,越大越接近一个均匀分布。
因此,当τ很小时,只有难区分的负样例才会对损失函数产生影响,同时,对错分的样例(即与原样例距离比正样例与原样例距离更近)有更大的惩罚。
τ趋于无穷大时,对所有负样本的权重都相同,即对比损失失去了关注困难样本的特性。这样不好(关注困难样本的作用就是:对于那些已经远离的样本,不需要继续让其远离,而主要聚焦在如何使没有远离的那些的样本远离,从而使得到的表示空间更均匀uniformity。)
对比损失随着τ的增大而倾向于“一视同仁”,随着τ的减少而只关注最困难的负样本,τ发挥着一种调节负样本关注度的作用。而且实验结果表明,对比学习对 τ 很敏感。
七、kaiming_normal
nn.init.kaiming_normal_(m.weight, a=0, mode='fan_out')
nn.init.constant_(m.bias, 0.0)
即Kaiming正态分布初始化方法(kaiming_normal_),该方法是根据激活函数的特性来初始化权重,能够更好地适应不同的激活函数。具体来说,它根据fan_out参数来计算标准差,以使输出方差等于输入方差,从而避免了梯度消失或爆炸的问题。


















 6327
6327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









