







离散过滤器(Discrete Filter)
为了方便对离散贝叶斯过滤器的理解,开始使用了下面的一个例子,十分形象生动的阐述了离散贝叶斯的原理,以及实现过程。
虽然我本篇博客的目的不是为了直接对书进行翻译,但是这个例子很妙,从这个例子讲起来也是个十分不错的选择。
追踪狗狗的位置
作者假设了一个场景,他把他的狗----丧彪(书里面叫 Simon) 带到了公司。

丧彪(的脖子上带着一个可以实时检测与物体的距离和运动方向和速度的传感器。假设丧彪只会在公司的走廊里面跑动的话,当经过门的时候传感器就会回传“门”,当没有在门附近的时候传感器就会回传“走廊”。假设这个公司是个的走廊是个圆形的结构,也就是丧彪从走廊的开始一直向一个方向跑,一会它就会经过一圈,又会再跑回来原来的位置。
给这个圆形的场地划个区域,从 0 ~ 9 共 10 个区域。这个场地一共有三个门,和 7 个走廊.示意图如下,除了门之外都是走廊部分。
先使用一组数组来表示一下,丧彪在这个圆形区域中各部分可能的概率。

为啥都是 0.1? 因为刚开始不知道丧彪的位置,所以在这个圆形中的每一个位置都是十分之一,也就是 0.1。
在现代贝叶斯统计学(Bayessian statistics)中这被称为先验(prior)。先验就是在进行测量之前给出的概率,先验的全名叫做先验概率分布(prior probability distribution) 。这里所有先验的概率加在一起必须要是 1 ,因为 1 就代表了 100%,就拿这个追踪丧彪的例子来说,丧彪肯定会在这10个位置之内,不可能“越狱”逃跑或者“瞬间移动”到别的地方去。
上面已经使用数组表示了丧彪在 10 个位置中出现的概率,接下来使用另一个数组来标记一下门和走廊,门记作“1”走廊记作“0”.

如果假设丧彪项圈的传感器回传的都是“1”,这意味着丧彪在门的位置上,但是究竟是那一个人是不确定的。但是一共有 3 个门,所以说在各个门前的概率为 1/3 . 下图为 python 代码,和其生成的柱形图/直方图。

当然,我们也可以将概率化为小数的形式。

传感器误差
没有完美的传感器,只是误差的大小有区别,误差的形式有区别。那么如何将传感器产生的误差引入我们的存储位置概率的数组呢?
因为概率的综合要是 1,那么如果引入误差的话,在门旁边的概率就应该各自减小一些,以分摊到其他部分中。如下图

因为传感器都会噪声,但是一个传感器被设计出来肯定测得的结果正确要大于错误。如果不是这样的话这玩意被设计出来就没有什么意义了。
现在我们假设传感器测得的正确情况大于错误情况的 3 倍(实际情况肯定不只3倍),这种说法说起来可能和式子比起来可能不够直观:
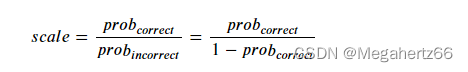
scale 是比例,prob correct 是正确的概率,prob incorrect 是错误概率。对于传感器误差就很直观了。
在这个时候如果传感器回传“门” 我们的概率数组就要变成下图中的样子了。

上图还是很好理解的吧~ 假设传感器接收到了“门”的位置。正确又是错误概率的三倍,也就是门的概率要是走廊的三倍,这样就有了这个直方图。但是这里面有个很关键的问题,概率的总和变为了 1.6 (因为只是将门的位置乘上了scale)。所以我们要想个办法把总和改回原来的 1 才行。
在可以使用数学中的归一方法(normalize function)。这个方法很简单,每一项分别除以总和就可以了。

好了再把我们到目前位置学的都利用起来。这里还假设我们在传感器上读到的还是“门”的位置。那也就是说,首先要对整个概率分布直方图中“门”部门的概率乘上传感器的比例(scale),在使用归一算法(normalization function)调整比例的总额。
def scaled_update(hall, belief, z, z_prob):
scale = z_prob / (1. - z_prob) # 计算比率
belief[hall==z] *= scale # 将概率数组中接收到的位置乘以比率
normalize(belief) # 归一化操作
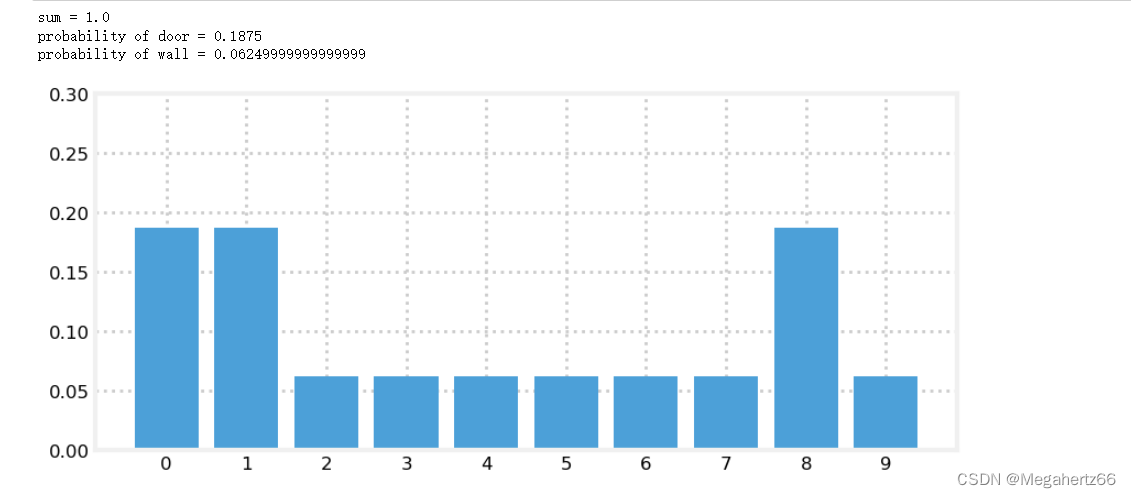
belief = np.array([0.1] * 10) # 初始化概率数组
scaled_update(hallway, belief, z=1, z_prob=.75)
print('sum =', sum(belief))
print('probability of door =', belief[0])
print('probability of wall =', belief[2])
book_plots.bar_plot(belief, ylim=(0, .3))
下面的图就是这个 python 代码的输出。这里大家需要看懂 scaled_update 函数的实现。
上图就表示了我们在初始阶段对于概率的模型,这个时候由于没有引入其他的一些外部信息,比如实际的测量值等。目前这个情况又称作”后验概率分布“也可以称为“后验”。这个术语有别于“先验”,因为先验是要结合实际的测量信息后得出的。
还有一个在这里很重要的的术语叫做可能性(likelihood)。是给定位置测量值的可能性,其实在代码中使用比率乘以概率的时候 belief[hall==z] *= scale 就是在做这个事。与分布概率不同的地方是,可能性的总和不用是 1,所以还要进行归一化。
后验有如下等式:

在滤波算法中一般处理前的状态叫做“先验(prior)”或者“预测值(prediction)”,使用滤波算法进行处理后得值成为“后验(posterior)”或者“评估值(estimated)”。
考虑丧彪的移动
我们门和走廊的位置关系用数组来表示就是 [1, 1, 0, 0, 0, 0, 0, 0, 1, 0] , 那么可不可以说如果我们连续的从传感器接收到 “门”“向右移动”“门”,这三个位置,丧彪就一定在 数组的第 0 位也,就是第一个门的位置呢?
NO! 不可以,虽然这种概率很高,由于误差的存在,这种情况只能说有很大的可能(接近 100%),而不能说就一定在第一个门的位置。
所以就算传感器接收到了丧彪移动的信息,并不能将其信息和实际的位置来对应。而是要将表示位置的概率数组整体移动,现在假设丧彪向右移动了一个位置:

接下来为了能更好的介绍后面的文章,这里需要解释一下几个术语:
系统( system )就是我们试图建立模型或者过滤器的事务,这里的系统就是指丧彪。态(state)就是当前的配置或者值,在这篇博客中就是指丧彪的位置。这里的态是不能准确得知的,所以我们要借助滤波器来对这个系统进行态的评估(estimated state)。
像上一篇博客中,系统为了是会根据测量值和预测值对评估值进行更新(update),这个过程也被称为系统进化(system evolution)或者系统繁衍(system propagation)。这个更新的行为也可以推导出系统伴随时间所产生的变化。
对这个系统行为进行建模的过程称为“过程模型(process model)”。在这篇博文中“过程模型”就是丧彪随着时间的流逝其位置变化的过程。但是这种建模是无法模拟丧彪的准确位置的,这其中就存在误差,我们管这种误差叫做“系统误差(system error)”或者“过程误差(process error)”。
来看一个小学问题,如果丧彪在位置 17m 处,以 15m/s 的速度,现在预测两秒后的位置应该在哪里:
x
‾
=
17
+
(
15
∗
2
)
=
47
\begin{aligned} \overline{x} = 17 + (15 * 2) \\ = 47 \end{aligned}
x=17+(15∗2)=47
现在我们已经依靠速度对位置进行了预测,可以把预测的过程写成下面的函数,对应上面的式子,
x
k
x_k
xk 就是丧彪的当前的位置/状态 17。
( ‾ x ) k + 1 = f ( ⋅ ) + x k \overline(x)_{k+1} = f(\cdot) + x_k (x)k+1=f(⋅)+xk
引入一些预测位置中的不确定性
为了更好的将传感器的误差(不确定性)也纳入滤波系统中,我们假设丧彪项圈内的传感器蒸正确率为 80%,剩下的两个 10% 是当前检测正确位置的左边和右边。
如果当前丧彪的位置在 3 ,那么如果传感器回传显示丧彪向右移动了 2 个位置。那么实际上应该是丧彪有 80% 的概率在位置5,10%的概率在位置4 ,10% 的概率在位置6.
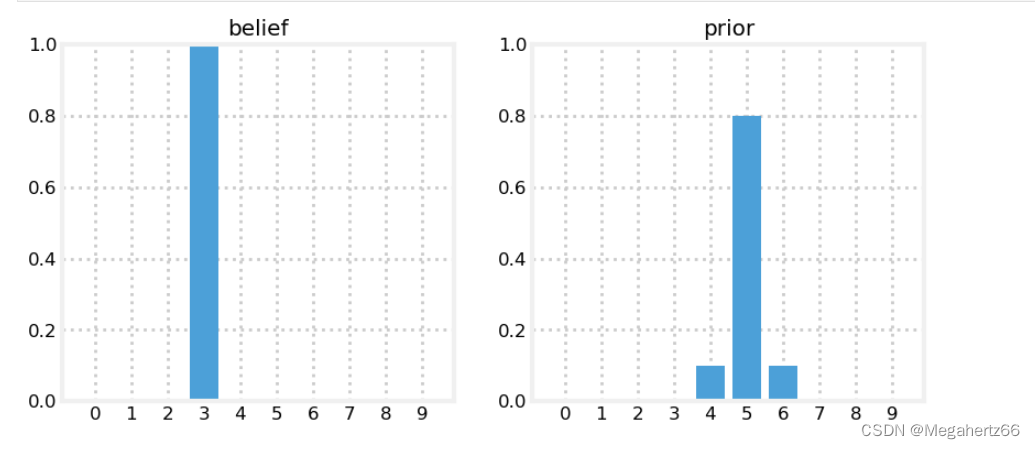
因为传感器存在误差,我们也不能准确的丧彪的位置。如果当前丧彪 60% 在位置 3 ,40% 在位置 2。拿这种情况再向右移动 2 个位置呢?
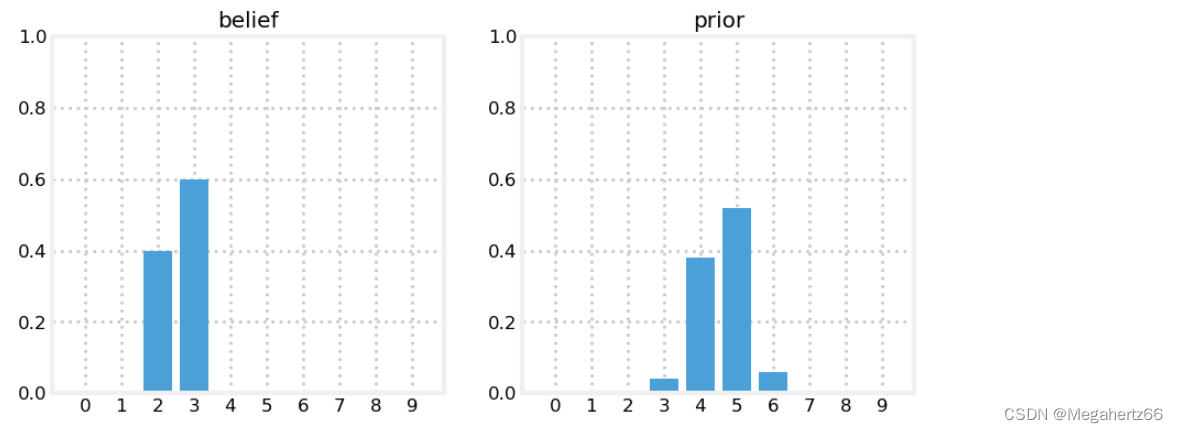
下面解释一下上图各个位置的具体数值:
位置 3 :0.4 * 0.1 = 0.04
位置 4 :0.4 * 0.8 + 0.6 * 0.1 = 0.38
位置 5 :0.6 * 0.8 + 0.4 * 0.1 = 0.52
位置 6 :0.6 * 0.1 = 0.06
所以大家现在想象一下,如果每一步都会分摊一些到别的位置,或者说每次迭代都会丢失一些数据。那么经过长期的迭代一定会平摊在图上。
下图就是迭代 70 次后的样子,几乎概率相同。根本没有办法判断丧彪的位置了。所以接下来就要卷积出马了。

使用卷积来避免上述的问题
\
卷积的理解
知乎作者 palet 的回答,非常的精彩!原文链接。
卷积的积分形式:
(
f
∗
g
)
(
t
)
=
∫
0
t
f
(
τ
)
g
(
t
−
τ
)
d
τ
(f \ast g) (t) = \int_0^t \!f(\tau) \, g(t-\tau) \, \mathrm{d}\tau
(f∗g)(t)=∫0tf(τ)g(t−τ)dτ
卷积的加权累加形式:
( f ∗ g ) [ t ] = ∑ τ = 0 t f [ τ ] g [ t − τ ] (f \ast g) [t] = \sum\limits_{\tau=0}^t \!f[\tau] \, g[t-\tau] (f∗g)[t]=τ=0∑tf[τ]g[t−τ]
相信大家在看过我推荐的知乎牛文之后都已经基本掌握卷积的原理了。这里也是一样,这里需要处理的函数是我们的概率数组,而 g(x) 则是我们前面假设的传感器传感器概率 [0.1, 0.8, 0.1]。
下图就是进行了卷积后预测丧彪在位置 5 的概率。

下面就是实现卷积预测的 python 代码:
# pdf: 概率分布数组
# offset: 需要计算的卷积前需要移动概率数组中的位置
# kernel: g(x) 用与处理概率数组的数组
def predict_move_convolution(pdf, offset, kernel):
N = len(pdf)
kN = len(kernel)
width = int((kN - 1) / 2)
prior = np.zeros(N)
for i in range(N):
for k in range (kN):
index = (i + (width-k) - offset) % N
prior[i] += pdf[index] * kernel[k]
return prior
第一个 for 需要循环 N 次,也就是 pdf(概率数组) 的长度。第二级的 for 需要循环 kN(kernel 数组的长度此处为 3) 次。
模上 N 是为了让 index 不超过 pdf 数组长度。所以代码中的 index 就是每次在 pdf 移动一位之后再取 3 位。之后用 pdf 中 3 位中每一位和 kernel 中的每一位相乘,再把这三个加起来。也就是点积。
至于 offset 的作用,也就是让每次 index 都少 offset 长度,每次减少 offset 就相当于开始之前就将 pdf 向右平移 offset(说实话,这里我竟然要想 5 分钟,手艺下滑了)。
这里还有一张图,这个图中修改了 kernel 数组的值,并且移动了 3 步。
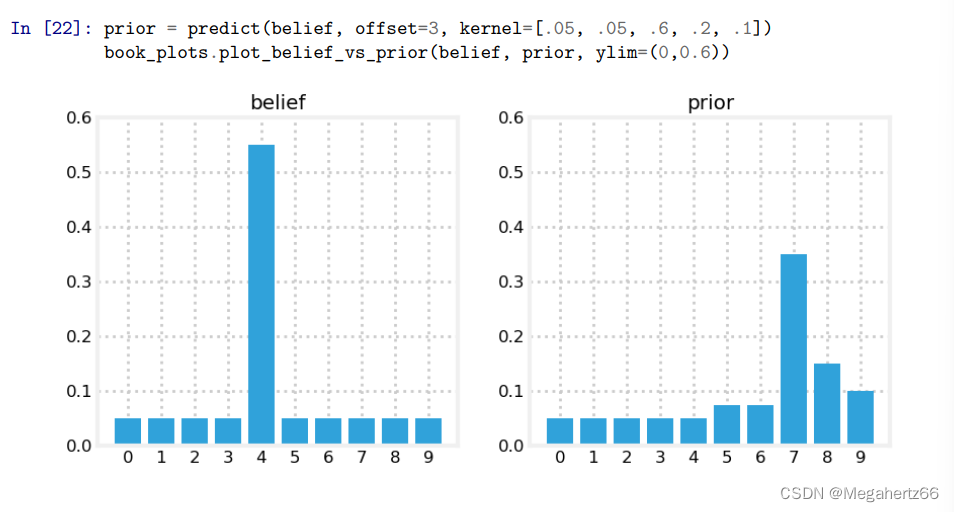
上图中 predict 函数的实现就是和上面的卷积代码是一样的。
整合预测和运动更新
在这篇博客的前面介绍了 scaled_update 算法,在上一部分介绍了使用卷积的办法来预测未来位置的概率。
下面代码中的 update 函数就是 我们的 scaled_update 算法。当丧彪的项圈回传”1“也就是门的位置时,首先更新一下位置:
hallway = np.array([1, 1, 0, 0, 0, 0, 0, 0, 1, 0])
prior = np.array([.1] * 10)
likelihood = lh_hallway(hallway, z=1, z_prob=.75)
posterior = update(likelihood, prior)

kernel = (.1, .8, .1)
prior = predict(posterior, 1, kernel)
如果再次接收到门的信号时,再次更新位置
likelihood = lh_hallway(hallway, z=1, z_prob=.75)
posterior = update(likelihood, prior)

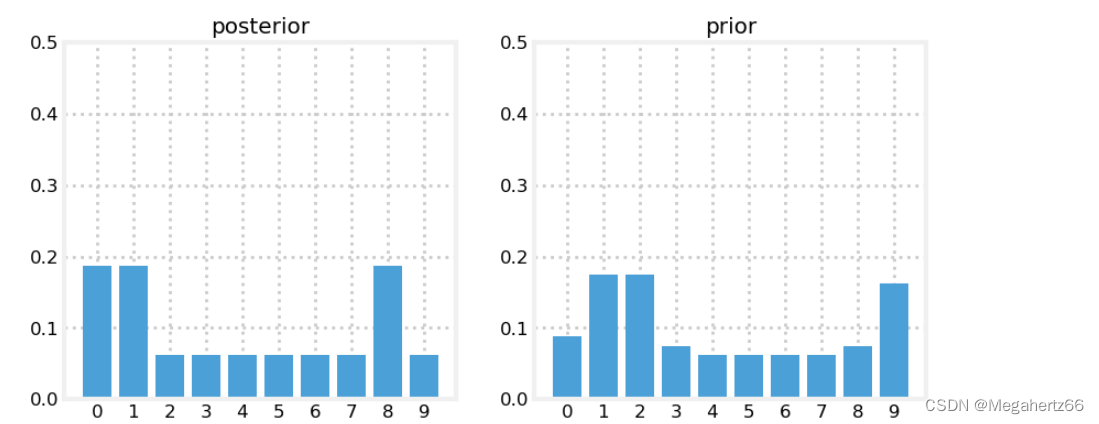
这里再次对丧彪进行位置预判(offset == 1, 意味着向右移动了一个位置)。然后再次更新,让我们看一下现在的图。
prior = predict(posterior, 1, kernel)
likelihood = lh_hallway(hallway, z=0, z_prob=.75)
posterior = update(likelihood, prior)

这里位置”2“的概率高达 35%,从图中可知,我们设计的过滤器已经生效了。
离散贝叶斯算法(Discrete Bayes Algorithm)
这里关于离散贝叶斯算法的流程图和前面的 g-h 算法十分的相近(或者说是一摸一样)。
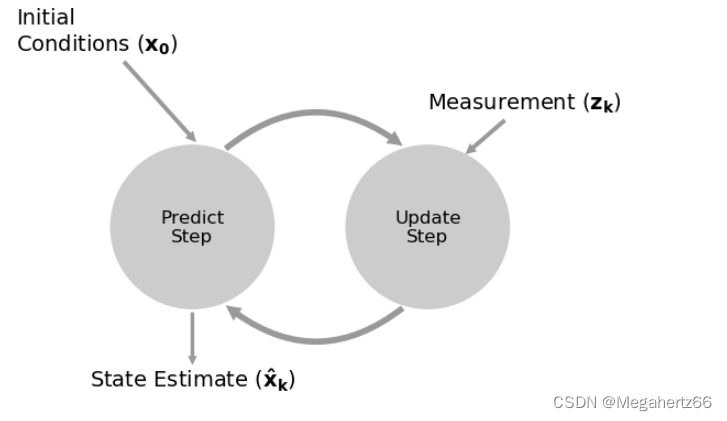
这里面也是由两个关键的步骤:1. 预测;2.更新。
x ˉ = x ∗ f x ( ∙ ) Predict Step x = ∥ L ⋅ x ˉ ∥ Update Step \begin{aligned} \bar {\mathbf x} &= \mathbf x \ast f_{\mathbf x}(\bullet)\, \, &\text{Predict Step} \\ \mathbf x &= \|\mathcal L \cdot \bar{\mathbf x}\|\, \, &\text{Update Step}\end{aligned} xˉx=x∗fx(∙)=∥L⋅xˉ∥Predict StepUpdate Step
书上也为这个算法提供了伪代码:
初始化:
1. 初始化最初状态的概率。
预测:
1. 基于当前系统的行为,预测下一步的状态;
2. 要将之前没有考虑的因素(就是 kernel 数组,其用于表示传感器的误差)调整到预测概率之中。
更新:
1. 接收实际测量值,并与之概率进行对应;
2. 计算测量值和实际状态的可能性;
3. 通过可能新去更新概率,从而获得我们要的评估值。
















 2934
2934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









