






运动规划-动态避让基础算法
概要
本文旨在介绍 运动规划(Motion Planning) 领域的一个细分问题------动态避障。即机器人在运动过程中,基于环境中其它物体的位置、速度等信息,调整自己的速度以避免碰撞。

运动碰撞基本示意图

附赠自动驾驶最全的学习资料和量产经验:链接
fiorini 等于 1993 年,将机器人和障碍物的位置和速度,抽象为平面几何上的状态空间,提出 速度障碍区(VO, Velocity Obstacle) 的计算模型。并指出机器人的速度只要避开 VO 区,即可避免发生碰撞。
但有没有可能,两个智能体做出的避让决策存在冲突呢?举个例子,两人分别从南北方向而来,碰面后相互礼让,同时向东移动,无法通行,再一起向西移动,依然无法通行,甚至来回调整好几次。这是因为两人各自所做的避让决策,是局部的,缺少全局协调,且基于当前状态,无法对未来做出准确预测。
一种直观的思路是做全局规划,通过全局协调器,掌握所有运动体的运行状况,并规划好各自的行进路线与速度。该方式有几个缺陷:
-
日常很多场景都是个体独立决策,无法被统筹,比如私家车;
-
全局调度的计算开销较大,可能存在计算瓶颈;
-
全局调度的可靠性要求高,万一故障则所有运动体的行进会被影响。
Jur van den Berg 等人于 2008 年提出了 相互速度障碍区(RVO, Reciprocal Velocity Obstacles) ,确保各个智能体只要使用相同的计算方法,即使分布式独立决策,也可避免碰撞。比如上文提到的南北相向而行的两人,在各自视角下均向右移动,从全局视角来看一个向东、一个向西,可直接通行。

本文将针对这三篇论文的基础思想和演进过程进行介绍。
Collision Cone(碰撞锥体区)


以 B 为参照系的碰撞锥面区

Velocity Obstacle(速度障碍区)


针对障碍物 B 的 A 的速度障碍区


多个障碍物的 VO 区求并集


只考虑近期碰撞的速度障碍区
避障机动

擦边弧线

擦边弧线示意图

可达避障速度
现实世界中,智能体的速度空间有限,总要受到各种约束(Fully Constrained Agent)。这些约束定义了智能体在特定环境中的行为和决策能力,比如:
-
物理约束。受到动力装置的影响,移动范围、速度和力量限制,那么加速度的方向和大小有限,新的速度必处于有限空间内。比如百公里加速需要 5s,转向不超过 60∘ 等。
-
逻辑/规则约束。比如在单行道上只能前进不能后退;或者在游戏中遇到施法地块只能避让不能抵达。
-
资源约束。计算资源、时间开销等,限制了智能体可以执行的任务数量或复杂度。

可达避障速度

避障轨迹计算
前文介绍了速度障碍(Velocity Obstacle),以及基于智能体实际机动能力的可达避障速度(Reachable Avoidance Velocities)。这里回归到运动规划的基本目标上,即智能体如何高效的抵达目的地,而且过程中不发生碰撞。可以先将几个关键目标和约束条件罗列出来:
-
目的地。即智能体所要到达的最终地点,并假设智能体出发前知道其绝对坐标,且可以正确感知环境中其它物体的位置和移动速度。
-
硬性目标——不能和其它静止或运动的智能体,及障碍物发生碰撞。
-
软性约束条件。可以结合实际情况进行设置,比如:
-
尽可能用最短时间抵达
-
路程尽可能短
-
尽可能少的调整速度,包括大小和方向
-
这是典型的持续路径规划的过程,假设环境中所有物体的决策信息不会共享,只能通过观察获取,那么在某一个时刻建立几何建模所做的预测,并不一定完全准确。随着运动的持续,环境中各个物体的位置和速度都可能发生预期外的变化,因此需要不断刷新环境信息,不断刷新智能体的决策。
我们用下面的方式对该问题进行建模:

以智能体在某一时刻的位置为节点,不同速度选择在下一时刻得到智能体的新位置,并建立从当前时刻位置到下一时刻 新位置的有向边。这样就会形成以当前时刻当前位置为根节点的无环有向图。如下所示:

基于不同速度选择生成所有解空间的有向图
该有向图代表了从当前时刻到最终到达节点的所有解空间,对该图进行完整遍历,同时计算各种约束条件下的开销,可以获得全局最优解。不难想象计算开销非常巨大:
-
一方面 RAV 即使网格化,操作选择也会非常多,假设量级为 N;
-
另一方面,从当前时刻到最终到达目的地,经过的时间可能较长,假设需要经过 M 次运算;

-
减少有向图的深度。只考虑最近一段时间范围内的计算。
-
减少速度选择空间,当前时刻下根据约束条件,从 RAV 中直接选择与开销最小的速度。
什么是 “开销最小” 呢?具体的定义和应用场景的需求有关,比如:
-
新速度,在方向上选择与目标点偏离最小的,在大小上尽可能选择避障空间内的最大值。该策略以减少转向为主要目标,近乎直线运行,并在尽可能短的时间内抵达目的地。但该方式可能导致速度大小降到很低,甚至停止不动。可类比高速直达线路堵车,与绕远路的差异。
-
与 1 类似,但先考虑速度大小再考虑方向:尽可能选择 RAV 区间内速度极大值,同时要求新速度和目标点之间的夹角不能超过阈值 � 。这意味着,绕远路可以但不要太离谱,同时速度尽可能快。
-
安全第一,合理选择速度方向,确保不论速度大小都不会与障碍物碰撞。可以参考之前提到的擦边弧线,以及 �� 区间,找到 VO 区的凸点,确保智能体到凸点所在的射线全部落于 RAV 区。这样速度大小的控制就有较大的容错空间,哪怕不精准也一定不会碰撞。
Oscillation(振荡运动)
上面介绍的避让算法,只能保证智能体基于 当前状态 预测,但其它智能体或者障碍物的 未来状态 并不一定总是符合预期,还是有可能出现开篇提到的 振荡 问题。如下图所示:


Reciprocal Velocity Obstacles(相互速度障碍)

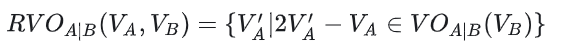

相互速度障碍区示意图

避免碰撞证明

避免振荡证明

具体证明过程过程如下所示:

速度选择

Reciprocal n-body Collsiion Avoidance(多物体相互避让)

模型更新


考虑时间因素的 VO 区示意图


VO 圆面随时间变化示意图

Optimal Reciprocal Collision Avoidance

那么 ORCA 解空间,具体怎么确定呢?思路如下所示:


ORCA 计算示意图

多目标避障计算(n-body Collision Avoidance)
和之前的方法类似,环境中智能体和障碍物的速度持续变化,因此需要通过一定的时间间隔( Δ� ),持续感知环境状态,调整速度。以单个智能体 A 为例,基本流程如下所示:


宽松解

汇总
到这里,我们就已经了解动态避障基础算法所涉及的基础问题:
-
基于平面几何,对智能体和障碍物的位置、速度进行建模。提出 VO 区,智能体的速度选择只要逃逸出 VO 区,即可避免碰撞。
-
多个智能体使用基础避让算法后,依然可能出现振荡不前的情况。故而演化出 RVO ,确保每个智能体选择的速度变更,在自己的视角,总是方向一致。比如都是向左转或者向右转,从而避免相撞。
-
最后将 RVO 的思路进行泛化,纳入时间因素,并通过线性规划的方式高效解决多体场景下的速度避让。
下面基于北卡罗来纳大学官方提供的 Optimal Reciprocal Collision Avoidance 代码(https://gamma.cs.unc.edu/RVO2/),并使用 javaFX 绘制 UI,展示分布为一个圆形的多个智能体,尝试抵达圆心对称点的避障过程。

00:37
总结
本文介绍了动态环境下,多智能体和障碍物持续运动,在没有统一调度和信息共享的情况下,各智能体通过观察周边智能体和障碍物的位置、速度,通过一定算法进行避让的解决方案。
本文涉及三篇论文,基本代表了避障算法的基本思路与核心概念。概括如下:
-
Velocity Obstacles。面向智能体 A,在考虑其他智能体和障碍物的位置与速度后,得到可能和其它物体发生碰撞的速度空间。只要智能体选择的新速度不在 VO 区内,那么可以保证避让。
-
Reciprocal Velocity Obstacles。多个智能体使用基础避让算法后,在未来时刻依旧可能相撞,甚至出现振荡不前的情况。RVO 对 VO 的计算做了改进,将智能体当前速度和 VO 进行平均,确保智能体与其参照系选择的速度变更,关于原点对称,即避让方向一致。从而在无需中心协调点的情况,通过分布式独立计算,避免振荡。
-
Optimal Reciprocal Collision Avoidance。将时间因素纳入到 RVO 模型,将目标速度求解,转化为半平面求交集方式。并提出宽松解的方法,将平面交集问题退化为 ORCA 分界线距离最小化问题。
总之,上述论文通过平面几何对避障问题进行合理建模,并不断优化,最终提出通过线性规划的方式在多体场景下获得较优解。在游戏、机器人、自动驾驶等领域均具有较好的参考价值。
References
-
Berg, Jur van den, Stephen J. Guy, Ming Lin, and Dinesh Manocha. 2011. “Reciprocal n-Body Collision Avoidance.” In, 3–19. Springer Berlin Heidelberg. https://doi.org/10.1007/978-3-642-19457-3_1.
-
Berg, Jur van den, Ming Lin, and Dinesh Manocha. 2008. “Reciprocal Velocity Obstacles for Real-Time Multi-Agent Navigation.” 2008 IEEE International Conference on Robotics and Automation, May. https://doi.org/10.1109/robot.2008.4543489.
-
Fiorini, Paolo, and Zvi Shiller. 1998. “Motion Planning in Dynamic Environments Using Velocity Obstacles.” The International Journal of Robotics Research 17 (7): 760–72. https://doi.org/10.1177/027836499801700706.
-
Fiorini, P., and Z. Shiller. n.d. “Motion Planning in Dynamic Environments Using the Relative Velocity Paradigm.” [1993] Proceedings IEEE International Conference on Robotics and Automation. https://doi.org/10.1109/robot.1993.292038.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









