






一、写在前面
1、学习建议
- 研究生阶段,某些课程该跳过就跳过,有些课程,教的是1+1=2,考的是计算微积分。这种课程学不着东西,真正学东西还是得自己课下下功夫。总之,经过大学洗练,又进入研究生阶段,大伙儿应该也都渐渐明白,课堂已经不再是我们获取知识的主要手段了。
- 我这篇博客里带着对代码的讲解,分段讲解那种,大家可以仔细看看里面的注释。如果发现有错误或者更好的写法或者建议,欢迎在评论区留言交流讨论。
- 好好学习,但遇到不顺心、不公平的事儿时,想开点,珍惜生命就是以另一种方式赚到。
- 博客的代码里有讲解的注释!但我不希望你是来抄作业的,另外,同时希望你能在参考列表中注明出处。
2、声明
本代码在写作过程中也参考了其他博主,见 四.3.1和 四.3.6 两小节。
二、题目描述
搭建一个可以运行在不同优化器模式下的 3 层神经网络模型(网络层节点数 目分别为:5,2,1),对“月亮”数据集进行分类。
- 在不使用优化器的情况下对数据集分类,并可视化表示。
- 将优化器设置为具有动量的梯度下降算法,可视化表示分类结果。
- 将优化器设置为 Adam 算法,可视化分类结果。
- 总结不同算法的分类准确度以及代价曲线的平滑度。
注:以上算法均手动实现,提供数据集读取代码及相关方法代码。
然后题目给出了我们激活函数、前向传播函数、绘制边界函数等,我们需要做的是编写使用不同的优化器进行网络训练,以及结果展示部分的代码。
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
import math
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- sigmoid(x)
"""
s = 1 / (1 + np.exp(-x))
return s
def relu(x):
"""
Compute the relu of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- relu(x)
"""
s = np.maximum(0, x)
return s
def forward_propagation(X, parameters):
"""
Implements the forward propagation (and computes the loss) presented in Figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape ()
b1 -- bias vector of shape ()
W2 -- weight matrix of shape ()
b2 -- bias vector of shape ()
W3 -- weight matrix of shape ()
b3 -- bias vector of shape ()
Returns:
loss -- the loss function (vanilla logistic loss)
"""
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
z1 = np.dot(W1, X) + b1
a1 = relu(z1)
z2 = np.dot(W2, a1) + b2
a2 = relu(z2)
z3 = np.dot(W3, a2) + b3
a3 = sigmoid(z3)
cache = (z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3)
return a3, cache
def predict(X, y, parameters):
"""
This function is used to predict the results of a n-layer neural network.
Arguments:
X -- data set of examples you would like to label
parameters -- parameters of the trained model
Returns:
p -- predictions for the given dataset X
"""
m = X.shape[1]
p = np.zeros((1, m), dtype=np.int)
# Forward propagation
a3, caches = forward_propagation(X, parameters)
# convert probas to 0/1 predictions
for i in range(0, a3.shape[1]):
if a3[0, i] > 0.5:
p[0, i] = 1
else:
p[0, i] = 0
# print results
# print ("predictions: " + str(p[0,:]))
# print ("true labels: " + str(y[0,:]))
print("Accuracy: " + str(np.mean((p[0, :] == y[0, :]))))
return p
def predict_dec(parameters, X):
"""
Used for plotting decision boundary.
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (m, K)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Predict using forward propagation and a classification threshold of 0.5
a3, cache = forward_propagation(X, parameters)
predictions = (a3 > 0.5)
return predictions
def load_dataset(is_plot=True):
np.random.seed(3)
train_X, train_Y = sklearn.datasets.make_moons(n_samples=300, noise=.2) # 300 #0.2
# Visualize the data
if is_plot:
plt.scatter(train_X[:, 0], train_X[:, 1], c=train_Y, s=40, cmap=plt.cm.Spectral);
train_X = train_X.T
train_Y = train_Y.reshape((1, train_Y.shape[0]))
return train_X, train_Y
##可视化分割线
def plot_decision_boundary(model, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1
y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(X[0, :], X[1, :], c=np.squeeze(y), cmap=plt.cm.Spectral)
plt.show()
##读取数据集代码
train_X, train_Y = load_dataset(is_plot=True)
三、必要知识讲解
1、“月亮”数据集
“月亮”数据集并非天上的月亮,这个题目并不是要求我们使用卷积神经网络对图片分类。而是使用BP神经网络对“月亮数据集”进行分类。月亮数据集是包含若干散点的数据,将散点画出来如下图所示:
该数据集数据是一系列散点坐标,标签是类别0和1,对应红色上弯钩和蓝色下弯钩数据。由于图形形似“月亮”,所以被称为“月亮数据集”。
sklearn.datasets.make_moons 函数已经为我们提供了生成数据集的函数,调用即可加载数据集(这部分代码在题目中已经给出)。加载的数据集是一个2行n列的数组(题目给定的n为300,接下来就用它了)
2、神经网络结构
首先我们来看一下输入的维度,在load_dataset函数中,加载了月亮数据集,返回到train_X和train_Y保存。在load_dataset 函数中,n_samples 设置为300,所以变量
t
r
a
i
n
_
X
∈
R
2
×
300
{\rm train\_X}\in{\mathcal R}^{2\times300}
train_X∈R2×300,
t
r
a
i
n
_
Y
∈
R
1
×
300
{\rm train\_Y}\in{\mathcal R}^{1\times300}
train_Y∈R1×300。 因此,输入层节点数为2,然后按题目要求,隐藏层节点数为5 2,输出层节点数为1。大致结构如下:
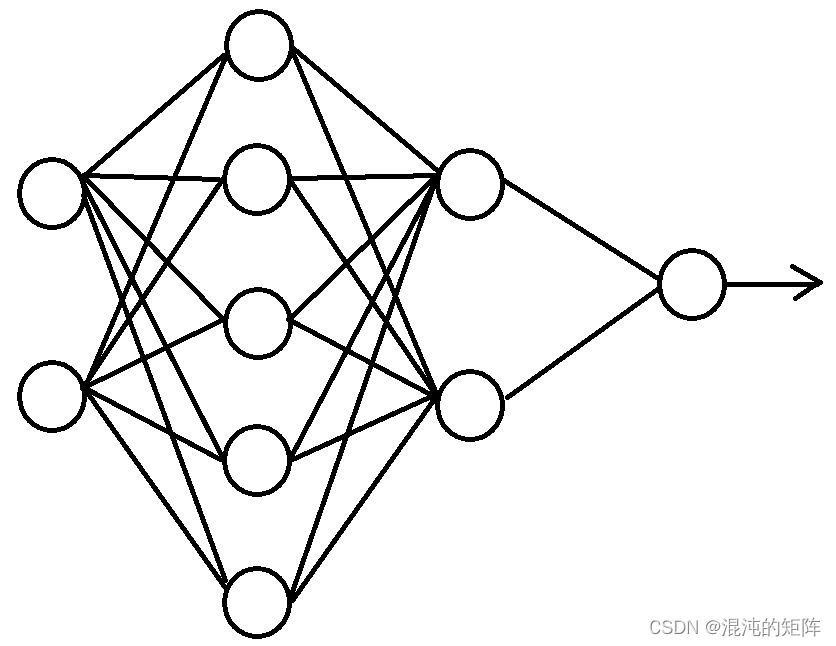
3、数据集分割
读取到的数据含有300个样本点,我们将它分为训练集和测试集,可以使用数据集分割函数,现在这个数据集比较少,手动分割也行。
# 使用数据集分割函数分割数据集
Xtrain, Xtest, Ytrain, Ytest = train_test_split(train_X.T, train_Y.T, test_size=0.1, random_state=100)
# 手动分割数据集
Xtrain = train_X[0:2, 0:270]
Ytrain = train_Y[0:1, 0:270]
Xtest = train_X[0:2 , 271:300]
Ytest = train_Y[0:1 , 271:300]
# 以上两种方法选择一种即可
# 两种方法均设置训练集和测试集比例为 9:1
4、优化器
这里我偷个懒,放个其他博主的博客吧,大伙想了解原理的自行参考
优化器(Optimizer)(SGD、Momentum、AdaGrad、RMSProp、Adam)
四、代码逐步解析
读取数据集并完成分割数据集后,就要写网络并进行训练。基本思路是:设置超参数、初始化网络、初始化优化器、训练网络(包括分割数据批次、前向传播、后向传播、使用优化器更新参数)、预测输出与展示结果
1、设置超参数、初始化全局变量
# 题目要求的层节点数量,输出是一个向量,默认就是1了
n1 = 5
n2 = 2
# 设置参数
EPOCHS = 10000 # 迭代总数
optimizer = 'SGD' # 通过更改'SGD' 'SGDM' 'ADAM' 来选择优化器,以满足题目要求
learning_rate = 0.1 # 学习率,不要太大也不要太小,太大导致容易发散,太小导致收敛速度慢
mompara = 0.9 # 优化器要用到的系数,在优化器中详解,下同
beta2 = 0.999
epsilon = 1e-8
loss = [] # 用于储存损失值的列表
accuracy = [] # 用于储存准确率的列表
2、初始化优化器及其参数
global s
np.random.seed(3) # 指定随机种子
n_x, n_y = Xtrain.shape[0], Ytrain.shape[0] # 神经网络输入层节点数和输出层节点数可以通过数据集拿到
t = 0
v = {}
parameters = initialize_parameters(n_x, n1, n2, n_y)
# 初始化动量
if optimizer == 'SGDM':
v = initialize_sgdm(parameters)
elif optimizer == 'ADAM':
v, s = initialize_adam(parameters)
else: pass # SGD不需要初始化动量
显然,这里面有三个函数待写:initialize_parameters、initialize_sgdm和initialize_adam,接下来我们解决掉他们
2.1 initialize_parameters
def initialize_parameters(n_x, n1, n2, n_y):
"""
参数:
n_x - 输入层节点的数量 2
n1,n2 - 隐藏层节点的数量 5 2
n_y - 输出层节点的数量 1
返回:
parameters - 包含参数的字典
说明:抛开题目要求,如果允许将节点数改变,似效果更好些,大家可以尝试一下,我试了试是这样
"""
np.random.seed(3) # 指定一个随机种子
W1 = np.random.randn(n1, n_x) # W1 - 输入层 - 隐藏层 1 的权重矩阵
b1 = np.zeros((n1, 1)) # b1 - 输入层 - 隐藏层 1 的偏置
W2 = np.random.randn(n2, n1) # W2 - 隐藏层1 - 隐藏层2 的权重矩阵
b2 = np.zeros((n2, 1)) # b2 - 隐藏层1 - 隐藏层2 的偏置
W3 = np.random.randn(n_y, n2) # W3 - 隐藏层2 - 输出层的权重矩阵
b3 = np.zeros((n_y, 1)) # b3 - 隐藏层2 - 输出层的偏置
# 把它们做成字典,方便提取值使用。题目在给出的代码中是使用的字典存储,这里也使用字典存储
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
return parameters
2.2 initialize_sgdm
Q:为什么这里要定义这个v ?
A:与优化器原理有关,参考上文给出的那个博主的博客,或者其他博主的博客,这里不详细介绍了,就是优化器的一个参数。
def initialize_sgdm(parameters):
dW1 = np.zeros(parameters["W1"].shape)
db1 = np.zeros(parameters["b1"].shape)
dW2 = np.zeros(parameters["W2"].shape)
db2 = np.zeros(parameters["b2"].shape)
dW3 = np.zeros(parameters["W3"].shape)
db3 = np.zeros(parameters["b3"].shape)
v = {"dW1": dW1, "db1": db1,
"dW2": dW2, "db2": db2,
"dW3": dW3, "db3": db3}
return v
2.3 initialize_adam
Q1:为什么这里要定义这个v s ?
A1:与优化器原理有关,参考上文给出的那个博主的博客,或者其他博主的博客,这里不详细介绍了,就是优化器的一个参数。
Q2:上面那个 sgdm 的初始化函数也用 v ,这里也用 v ,不会冲突吗?
A2:不会,因为在前面超参数设置的时候,要先选择优化器,我们并没有同时使用两个优化器。
def initialize_adam(parameters) :
v = {}
s = {}
v["dW1"] = np.zeros(parameters["W1"].shape)
v["db1"] = np.zeros(parameters["b1"].shape)
s["dW1"] = np.zeros(parameters["W1"].shape)
s["db1"] = np.zeros(parameters["b1"].shape)
v["dW2"] = np.zeros(parameters["W2"].shape)
v["db2"] = np.zeros(parameters["b2"].shape)
s["dW2"] = np.zeros(parameters["W2"].shape)
s["db2"] = np.zeros(parameters["b2"].shape)
v["dW3"] = np.zeros(parameters["W3"].shape)
v["db3"] = np.zeros(parameters["b3"].shape)
s["dW3"] = np.zeros(parameters["W3"].shape)
s["db3"] = np.zeros(parameters["b3"].shape)
return v, s
3、训练神经网络
训练的思想是这样的:
总共训练 EPOCHS 轮,EPOCHS 是前文设置的超参数之一。在每一轮中,先将训练集随机打乱分割批次,打乱是为了避免由于排列组合顺序造成的干扰,分割批次是为了一次性训练一个 minibatch,这样更快,但是得到的损失曲线波动性也更大。
seed = 5 # 随机数种子,用于批次分割
cost = 0 # 损失值,先初始化为零,后面计算每次的 cost,然后记录下来
print("================== 训练神经网络 ======================")
for i in range(EPOCHS):
seed = seed + 1
minibatches = random_mini_batches(Xtrain, Ytrain, 64, seed) # 待写,下文给出
for minibatch in minibatches:
(minibatch_X, minibatch_Y) = minibatch # 当然了,这里也可以使用枚举enumerate拿到minbatch_X 和 minibatch_Y 以及批数idx
A, cache = forward_propagation(minibatch_X, parameters) # 题目代码给出
cost = cost_computing(A, minibatch_Y) # 待写,下文给出
predictions = predict(Xtest, Ytest, parameters) # 题目代码给出
accuracy.append(float((np.dot(Ytest, predictions.T) + np.dot(1 - Ytest, 1 - predictions.T)) / float(Ytest.size) * 100)) # 把计算得到的准确率加入到列表中
loss.append(cost) # 把计算得到的损失值加入到列表中
grads = backward_propagation(cache, minibatch_X, minibatch_Y) # 待写,下文给出
# 根据optimizer选择合适的优化器
if optimizer == "SGD":
parameters = sgd(parameters, grads, learning_rate) # 待写,下文给出
elif optimizer == "SGDM":
parameters, v = sgdm(parameters, grads, v, mompara, learning_rate) # 待写,下文给出
elif optimizer == "ADAM":
t = t + 1 # Adam counter
parameters, v, s = adam(parameters, grads, v, s, t, learning_rate, e, mompara, beta2) # 待写,下文给出
if i % (EPOCHS/10) == 0:
print("第 ", i, " 次循环,cost为:" + str(cost))
# 当这个循环执行完毕后,得到的 parameters 字典就是训练好的参数字典,然后就可以拿到题目给出的plot_decision_boundary函数里使用了。
下面依次实现上文框架中的函数。
3.1 random_mini_batches函数
老实说,这块代码我当时直接参考的另一个博主的,但是那篇文章我没保存,找不到了,但肯定有,大伙儿感兴趣可以去csdn上C一下。大致思想就是先把数据集打乱,然后分为若干批,每一批含有mini_batch_size个数据,最后除不尽的单独做为一批数据。每批数据打包成一个元组,存入列表。
def random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):
"""
Creates a list of random minibatches from (X, Y)
Arguments:
X -- input data, of shape (input size, number of examples)
Y -- true "label" vector (1 for blue dot / 0 for red dot), of shape (1, number of examples)
mini_batch_size -- size of the mini-batches, integer
Returns:
mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)
"""
np.random.seed(seed) # To make your "random" minibatches the same as ours
m = X.shape[1] # number of training examples
mini_batches = []
# Step 1: Shuffle (X, Y)
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((1,m))
# Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.
num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning
for k in range(0, num_complete_minibatches):
### START CODE HERE ### (approx. 2 lines)
mini_batch_X = shuffled_X[:, k*mini_batch_size : (k+1)*mini_batch_size]
mini_batch_Y = shuffled_Y[:, k*mini_batch_size : (k+1)*mini_batch_size]
### END CODE HERE ###
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# Handling the end case (last mini-batch < mini_batch_size)
if m % mini_batch_size != 0:
### START CODE HERE ### (approx. 2 lines)
mini_batch_X = shuffled_X[:, num_complete_minibatches*mini_batch_size : m]
mini_batch_Y = shuffled_Y[:, num_complete_minibatches*mini_batch_size : m]
### END CODE HERE ###
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
比如在本例子中,前文提到过,加载的数据样本总共为300个,其中划分了训练集为270个。因此,这个random_mini_batches函数的返回值mini_batches是一个列表,列表含有5个元素,每个元素都是一个元组,每个元组形式为 (mini_batch_X, mini_batch_Y),其中,前四个元组中,每个mini_batch_X和mini_batch_Y都包含了mini_batch_size个(本例设置为64)数据样本,最后一组包含了剩余的14个数据样本
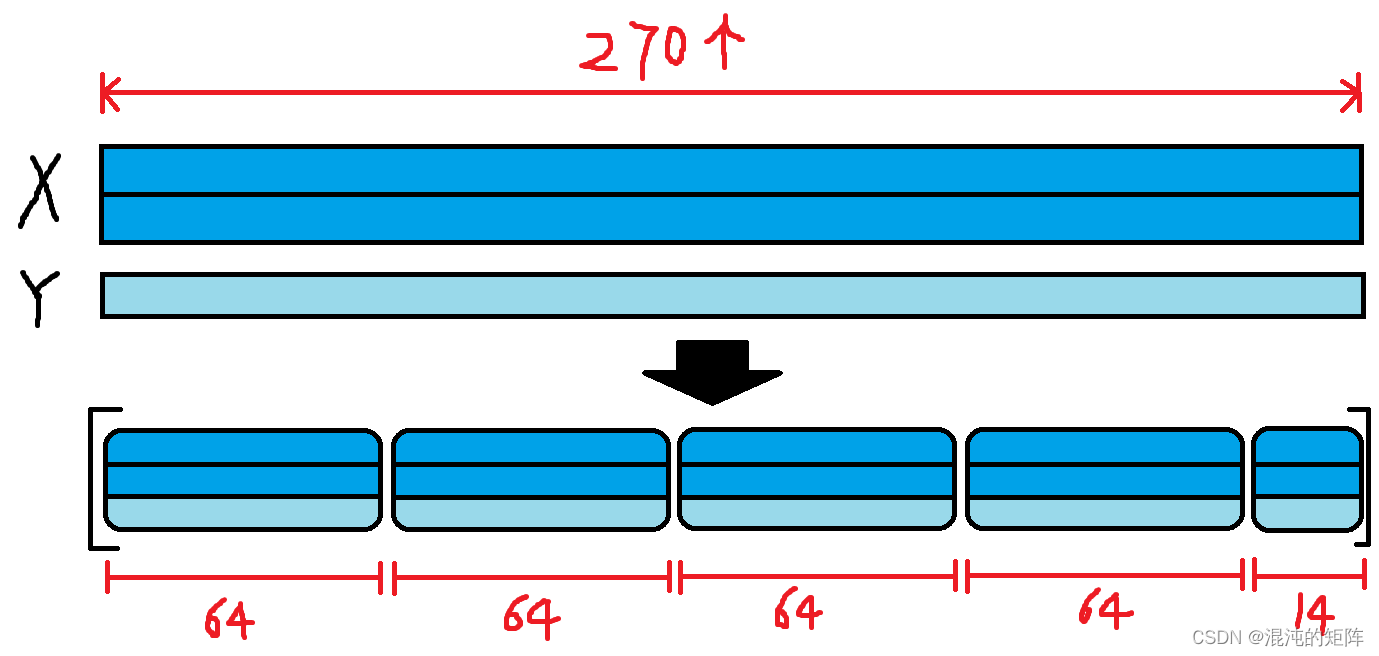
3.2 cost_computing函数
def cost_computing(A, Y):
m = Y.shape[1]
logloss = np.multiply(np.log(A), Y) + np.multiply((1 - Y), np.log(1 - A))
cost = - np.sum(logloss) / m
return cost
损失计算公式: L = y log y p + ( 1 − y ) log ( 1 − y p ) L=y\log{y_p}+(1-y)\log{(1-y_p)} L=ylogyp+(1−y)log(1−yp)
3.3 backward_propagation函数
反向传播的目的,是得到关于各个参数的梯度,各个参数在前向传播时储存在 cache 中(见题目代码)。因此 backward_propagation 函数的返回值是W1 W2 W3 b1 b2 b3这六个参数的梯度
def backward_propagation(cache, X, Y):
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = 1./ m * (A3 - Y)
dW3 = np.dot(dZ3, A2.T)
db3 = np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = np.dot(dZ2, A1.T)
db2 = np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = np.dot(dZ1, X.T)
db1 = np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW3": dW3, "db3": db3,
"dW2": dW2, "db2": db2,
"dW1": dW1, "db1": db1}
return grads
附反向传播公式:
3.4 sgd函数
SGD是使用梯度下降法优化,参数 θ \theta θ 的梯度下降公式为: θ : = θ − η d θ \theta:=\theta-\eta \space d\theta θ:=θ−η dθ如果参数是一个向量 v \mathbf{v} v ,显然改写为: v : = v − η g r a d v \mathbf{v}:=\mathbf{v}-\eta\space{\rm grad}\mathbf{v} v:=v−η gradv如果参数是一个矩阵 A \mathbf{A} A ,显然改写为: A : = A − η A ′ \mathbf{A}:=\mathbf{A}-\eta\space\mathbf{A}^\prime A:=A−η A′
接下来为统一,参数统一只说 θ \theta θ,但他不一定是标量,接下来不再分标量、向量和矩阵讨论。
def sgd(parameters, grads, learning_rate):
W1, W2, W3 = parameters["W1"], parameters["W2"], parameters["W3"]
b1, b2, b3 = parameters["b1"], parameters["b2"], parameters["b3"]
dW1, dW2, dW3 = grads["dW1"], grads["dW2"], grads["dW3"]
db1, db2, db3 = grads["db1"], grads["db2"], grads["db3"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
W3 = W3 - learning_rate * dW3
b3 = b3 - learning_rate * db3
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2,
"W3": W3,
"b3": b3}
return parameters
3.5 sgdm函数
SGDM对原来的SGD进行了改进,参数 θ \theta θ 的更新公式: θ : = θ − η v t \theta:=\theta-\eta\space v_t θ:=θ−η vt v t = β v t − 1 + ( 1 − β ) d θ v_t=\beta\space v_{t-1}+(1-\beta)\space d\theta vt=β vt−1+(1−β) dθ
def sgdm(parameters, grads, v, beta, learning_rate):
v["dW1"] = beta * v["dW1"] + (1-beta) * grads["dW1"]
v["db1"] = beta * v["db1"] + (1-beta) * grads["db1"]
v["dW2"] = beta * v["dW2"] + (1-beta) * grads["dW2"]
v["db2"] = beta * v["db2"] + (1-beta) * grads["db2"]
v["dW3"] = beta * v["dW3"] + (1-beta) * grads["dW3"]
v["db3"] = beta * v["db3"] + (1-beta) * grads["db3"]
parameters["W1"] = parameters["W1"] - learning_rate * v["dW1"]
parameters["b1"] = parameters["b1"] - learning_rate * v["db1"]
parameters["W2"] = parameters["W2"] - learning_rate * v["dW2"]
parameters["b2"] = parameters["b2"] - learning_rate * v["db2"]
parameters["W3"] = parameters["W3"] - learning_rate * v["dW3"]
parameters["b3"] = parameters["b3"] - learning_rate * v["db3"]
return parameters, v
3.6 adam函数
和前文mini_batches那个函数一样,这个adam优化器当时有点绕晕,就去参考了网上的资料。
Adam的公式如下:
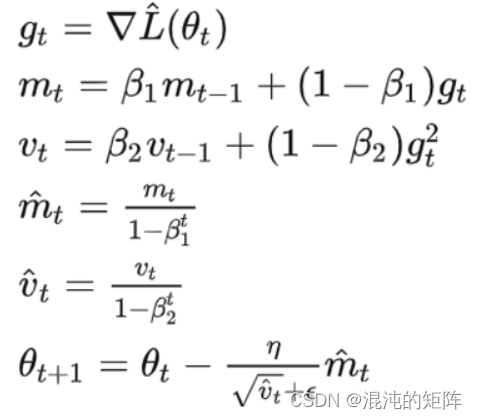
def adam(parameters, grads, v, s, t, learning_rate, epsilon, beta1 = 0.9, beta2 = 0.999):
v_t = {}
s_t = {} # ADAM中包含了两个动量字典,要分别初始化,分别建立校正
v["dW1"] = beta1 * v["dW1"] + (1 - beta1) * grads['dW1']
v["db1"] = beta1 * v["db1"] + (1 - beta1) * grads['db1']
v["dW2"] = beta1 * v["dW2"] + (1 - beta1) * grads['dW2']
v["db2"] = beta1 * v["db2"] + (1 - beta1) * grads['db2']
v["dW3"] = beta1 * v["dW3"] + (1 - beta1) * grads['dW3']
v["db3"] = beta1 * v["db3"] + (1 - beta1) * grads['db3']
v_t["dW1"] = v["dW1"] / (1 - beta1 ** t)
v_t["db1"] = v["db1"] / (1 - beta1 ** t)
v_t["dW2"] = v["dW2"] / (1 - beta1 ** t)
v_t["db2"] = v["db2"] / (1 - beta1 ** t)
v_t["dW3"] = v["dW3"] / (1 - beta1 ** t)
v_t["db3"] = v["db3"] / (1 - beta1 ** t)
s["dW1"] = s["dW1"] + (1 - beta2) * (grads['dW1'] ** 2)
s["db1"] = s["db1"] + (1 - beta2) * (grads['db1'] ** 2)
s["dW2"] = s["dW2"] + (1 - beta2) * (grads['dW2'] ** 2)
s["db2"] = s["db2"] + (1 - beta2) * (grads['db2'] ** 2)
s["dW3"] = s["dW3"] + (1 - beta2) * (grads['dW3'] ** 2)
s["db3"] = s["db3"] + (1 - beta2) * (grads['db3'] ** 2)
s_t["dW1"] = s["dW1"] / (1 - beta2 ** t)
s_t["db1"] = s["db1"] / (1 - beta2 ** t)
s_t["dW2"] = s["dW2"] / (1 - beta2 ** t)
s_t["db2"] = s["db2"] / (1 - beta2 ** t)
s_t["dW3"] = s["dW3"] / (1 - beta2 ** t)
s_t["db3"] = s["db3"] / (1 - beta2 ** t)
mdW1 = v_t["dW1"] / (np.sqrt(s_t["dW1"]) + epsilon)
mdb1 = v_t["db1"] / (np.sqrt(s_t["db1"]) + epsilon)
mdW2 = v_t["dW2"] / (np.sqrt(s_t["dW2"]) + epsilon)
mdb2 = v_t["db2"] / (np.sqrt(s_t["db2"]) + epsilon)
mdW3 = v_t["dW3"] / (np.sqrt(s_t["dW3"]) + epsilon)
mdb3 = v_t["db3"] / (np.sqrt(s_t["db3"]) + epsilon)
parameters["W1"] = parameters["W1"] - learning_rate * mdW1
parameters["b1"] = parameters["b1"] - learning_rate * mdb1
parameters["W2"] = parameters["W2"] - learning_rate * mdW2
parameters["b2"] = parameters["b2"] - learning_rate * mdb2
parameters["W3"] = parameters["W3"] - learning_rate * mdW3
parameters["b3"] = parameters["b3"] - learning_rate * mdb3
return parameters, v, s
至此,神经网络训练过程已经写完,最后要得到的值就是 parameters 字典
4、绘制损失函数
在训练时,我们已经得到每轮的损失cost,并储存在全局变量损失列表loss中,接下来就可以将其绘制出来。使用matplotlib很简单了
plt.plot(np.array(loss))
plt.title('Loss function plot with ' + optimizer) # optimizer是在超参数定义时定义的字符串变量
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
5、绘制准确率曲线
在训练时,我们已经得到每轮的准确率,并储存在全局变量准确率列表accuracy中,接下来就可以将其绘制出来。
plt.plot(np.array(accuracy))
plt.title('Accuracy plot with ' + optimizer) # optimizer是在超参数定义时定义的字符串变量
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.show()
6、绘制决策边界
大伙儿有没有发现,题目给出的predict_dec函数和plot_decision_boundary函数还没有用到。这个 dec 是什么意思呢?哈哈,当然是 decision 咯。下面按题目要求把决策边界绘制出来。
这里用到 lembda 表达式作为plot_decision_boundary函数中第一个参数 model 的实参。
axes = plt.gca()
plot_decision_boundary(lambda x: predict_dec(x.T,parameters), train_X, train_Y)
predictions = predict(Xtest, Ytest, parameters)
print('准确率: %d' % float((np.dot(Ytest, predictions.T) + np.dot(1 - Ytest, 1 - predictions.T)) / float(Ytest.size) * 100) + '%')
五、结束语
至此,代码已经全部写完了。完整版代码及其运行结果会在下一篇博客中给出,今天时间不早了,哥们要回宿舍睡觉了。个人代码功底也不是很好,写博客的时候也有所删删改改,如有错误可在评论区留言讨论,我会第一时间去进行学习和更正。
更新:
完整代码和运行结果
















 805
805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









