







非模式生物富集分析
非模式菌株搜索方法
library("AnnotationHub")
require("AnnotationHub")
hub <- AnnotationHub() #这步需要点时间
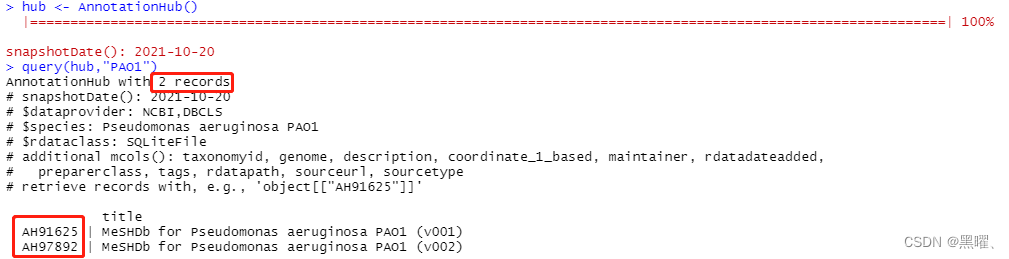
query(hub,"PAO1")
查询包含PAO1的物种信息,一共查询到2条信息。记住ID号:
创建OrgDb包
但我想自己建包,所以在数据库下的注释信息(我这是假单胞菌的基因组网站):
https://v2.pseudomonas.com/goterms/list?accession=&goterm=&ecoCode=&strain_id=107&term=Pseudomonas+aeruginosa+PAO1+%28Reference%29&offset=0
setwd("此处填文件所在路径")
egg<-read.csv("gene_ontology_csv.csv")
如果有空行运行:
NAegg[egg=="-"] <- NA
我的注释文件长这个样子(至少应该有GID, GENENAME, GO):

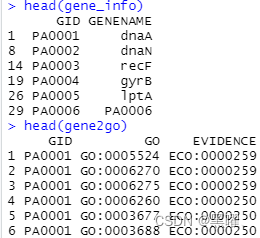
创建gene_info和gene2go文件:
gene_info <- egg %>%dplyr::select(GID = Locus.Tag, GENENAME = Gene.Name) %>% na.omit() #把GID和GENENAME相应提取出来。
gene_info <- unique(gene_info) #我这里有行重复,你的没有的话可以忽略
gene2go <- egg %>%dplyr::select(GID = Locus.Tag, GO = Accession, EVIDENCE = Evidence.Ontology.ECO.Code) %>% na.omit() #同理把GID,GO和Evidence提取出来, Evidence随意什么都行。
gene2go <- unique(gene2go)
write.table(gene2go,file="gene2go.txt",sep="\t",row.names=F,quote=F) #保存成文件gene2go.txt
文件长这样:
如果有KEGG注释的话运行以下代码,我没有就跳过了:
koterms <- egg %>%dplyr::select(GID = GID, KO=KEGG_ko)%>%na.omit()%>% filter(str_detect(KO,"ko")) #根据egg第一列和KEGG_ko列的标题提取基因的KEGG注释。
load("kegg_info.RData")
library(dplyr)
colnames(ko2pathway)=c("KO",'Pathway') #把ko2pathway的列名改为KO和Pathway,与koterms一致。
koterms$KO=str_replace_all(koterms$KO,"ko:","") #把koterms的KO值的前缀ko:去掉,与ko2pathway格式一致。
gene2pathway <- koterms %>% left_join(ko2pathway, by = "KO") %>%dplyr::select(GID, Pathway) %>%na.omit() #合并koterms和ko2pathway到gene2pathway,将基因与pathway的对应关系整理出来
#可选
gene2pathway_name<-left_join(gene2pathway,pathway2name,by="Pathway") #合并gene2pathway和pathway2name
write.table(gene2pathway_name,file="gene2pathway_name.txt",sep="\t",row.names=F,quote=F)【optional】保存成文件gene2pathway_name.txt,可以给通用KEGG富集分析用。
这里面的tax_id去NCBI的Taxonomy查Taxonomy ID信息:
https://www.ncbi.nlm.nih.gov/Taxonomy/Browser/wwwtax.cgi
比如Melastoma candidum的Taxonomy ID为119954。
#BiocManager::install("AnnotationForge")
library(AnnotationForge)
makeOrgPackage(gene_info=gene_info, go=gene2go, version="0.1", maintainer='你的名字 <邮箱地址>',
author='你的名字 <邮箱地址>',outputDir=".", tax_id="208964", genus="Pseudomonas",
species="PAO",goTable="go")
然后你所在目录就会生成一个org.XXX.eg.db的包,把它安装到你的R上:
install.packages('org.PPAO.eg.db',repos = NULL, type="source") #安装包
library(org.PPAO.eg.db) #加载包
然后就可以正常进行富集分析啦!
GO富集分析
setwd("你的数据路径")
gene<-read.csv("deg.csv",header = T)
gene_up <- gene[which(gene$change == c("UP")),1]
#需要注意的是你的基因名和注释里的是否一样,如果不一样建议用SYMBOL更准确些
up_go <- enrichGO(gene = gene_up,
OrgDb = org.PPAO.eg.db,
keyType = 'GENENAME',
ont = 'BP',
qvalueCutoff = 0.05,
minGSSize = 10,
maxGSSize = 500)
head(up_go)
up_go_bar <- barplot(up_go,showCategory=10,drop=T, title = "GO") #只显示前十个
up_go_bar
KEGG富集分析
这里是以小鼠为例:
#install.packages('R.utils')
R.utils::setOption("clusterProfiler.download.method",'auto')
up_geneid <- bitr(up_genes, fromType = "SYMBOL", toType = "ENTREZID", OrgDb = org.Mm.eg.db)
up_kegg <- enrichKEGG(gene = up_geneid$ENTREZID, organism = 'mmu', keyType = 'kegg', pvalueCutoff = 0.05,
pAdjustMethod = 'BH', minGSSize = 3, maxGSSize = 500, qvalueCutoff = 0.2,
use_internal_data = FALSE)
head(up_kegg)
up_kegg_bar <- barplot(up_kegg,showCategory=10,drop=T, title = "KEGG")
up_kegg_bar
参考:
https://zhuanlan.zhihu.com/p/536082841















 476
476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









