







 本文介绍了神经网络的优化算法,包括梯度下降、mini-batch梯度下降、momentum以及Adam优化器的工作原理和实现代码。通过对比,强调了Adam在优化效率和效果上的优势。
本文介绍了神经网络的优化算法,包括梯度下降、mini-batch梯度下降、momentum以及Adam优化器的工作原理和实现代码。通过对比,强调了Adam在优化效率和效果上的优势。
通过梯度下降可以更新参数并最小化cost函数,通过算法优化可以加速学习并可能会得到更优的cost函数值
一、梯度下降
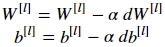
L是神经网络的层数,α代表学习率, 所有参数都存在parameters字典里
Arguments:
parameters -- python dictionary containing your parameters to be updated:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
grads -- python dictionary containing your gradients to update each parameters:
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
代码实现
for l in range(L):
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate*grads['dW' + str(l+1)]
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate*grads['db' + str(l+1)]
二、mini-batch梯度下降
1.shuffle
通过shuffle将(X,Y)数据集打乱,保证数据集随机划分到不同的batch里
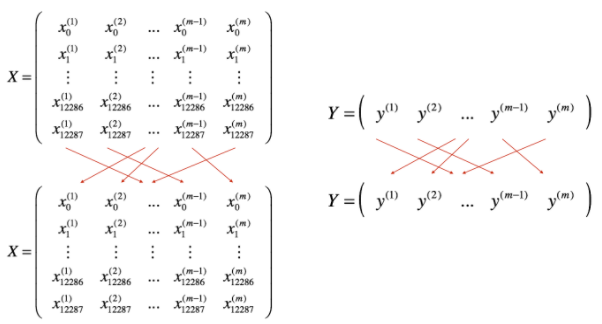
代码实现
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((1,m))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1388
1388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









