






一 卷积的定义
卷积公式是一种数学运算,通常用于计算两个函数之间的关系。更好的理解可以参阅知乎回答:对卷积的困惑
首先,我们首先回顾一下卷积相关的基本概念,定义一个卷积层需要的几个参数。
卷积核大小(Kernel Size):卷积核大小定义了卷积的视野。2维中的常见选择是3 - 即3x3像素矩阵。
步长(Stride):步长定义遍历图像时卷积核的移动的步长。虽然它的默认值通常为1,但我们可以使用值为2的步长来对类似于MaxPooling的图像进行下采样。
填充(Padding):填充定义如何处理样本的边界。Padding的目的是保持卷积操作的输出尺寸等于输入尺寸,因为如果卷积核大于1,则不加Padding会导致卷积操作的输出尺寸小于输入尺寸。
输入和输出通道(Channels):卷积层通常需要一定数量的输入通道(I),并计算一定数量的输出通道(O)。可以通过I * O * K来计算所需的参数,其中K等于卷积核中参数的数量,即卷积核大小。
卷积计算公式:N=(W-F+2P)/S+1
其中N:输出大小;W:输入大小;F:卷积核大小;P:填充值的大小;S:步长大小
二 标准卷积
1.1D卷积
一维卷积通常有三种类型:full卷积、same卷积和valid卷积,下面以一个长度为5的一维张量I和长度为3的一维张量K(卷积核)为例,介绍这三种卷积的计算过程。
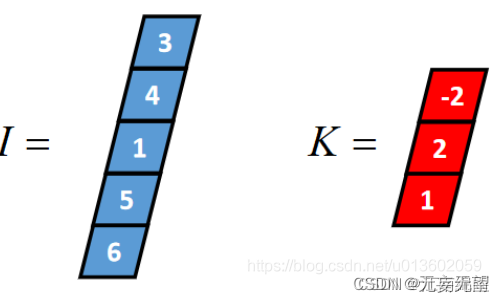
Ⅰ:一维Full卷积
Full卷积的计算过程是:K沿着I顺序移动,每移动到一个固定位置,对应位置的值相乘再求和,计算过程如下: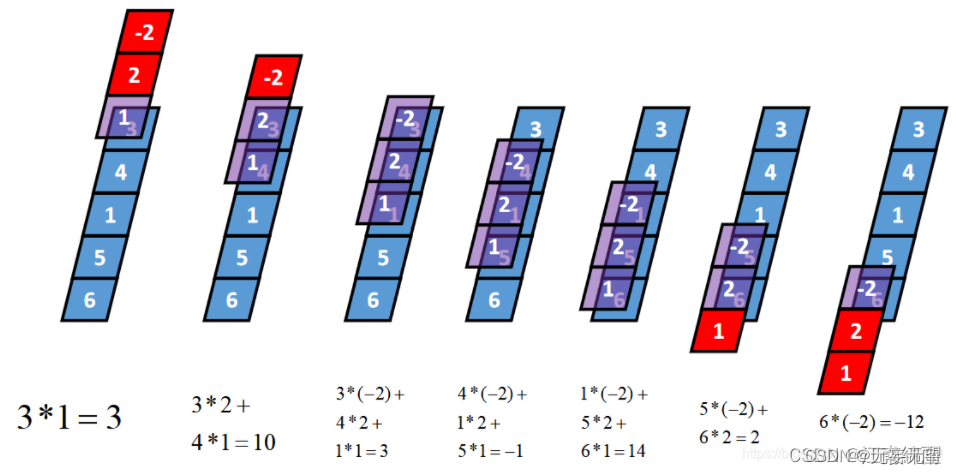

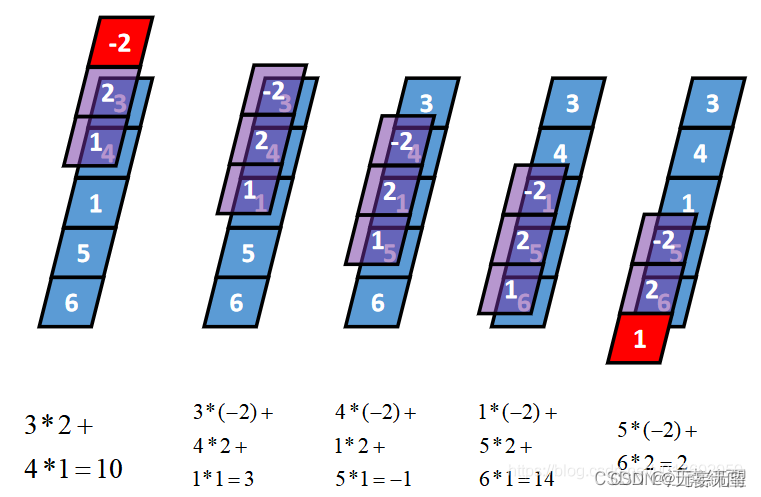
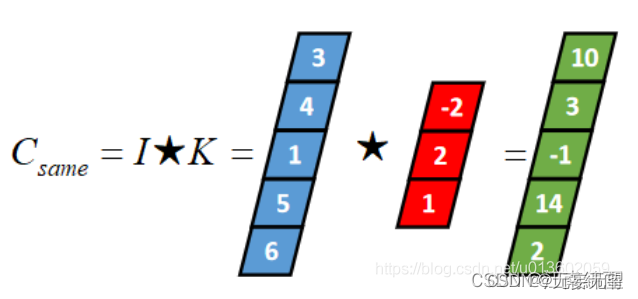
Ⅱ:一维Same卷积
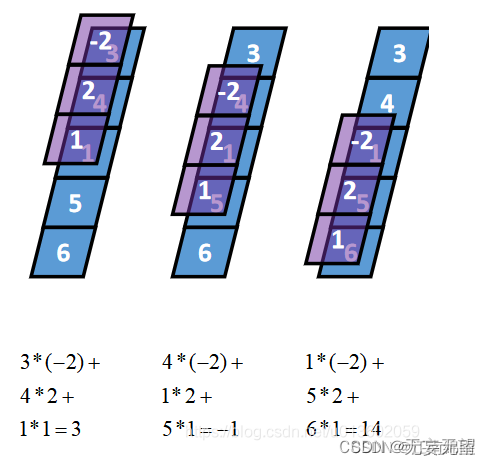
Same卷积核K都有一个锚点,然后将锚点顺序移动到张量I的每一个位置处,对应位置相乘再求和,计算过程如下:
Ⅲ:一维Valid卷积
valid卷积只考虑I能完全覆盖K的情况,即K在I的内部移动的情况,计算过程如下:

Ⅳ:三种一维卷积的相互关系

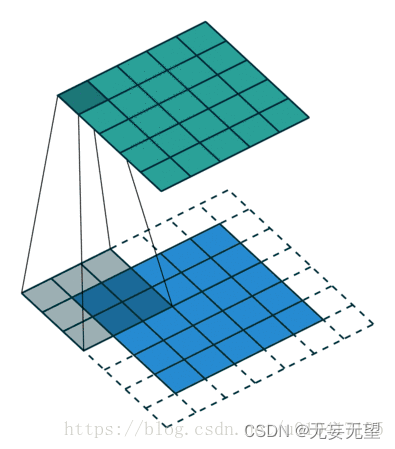
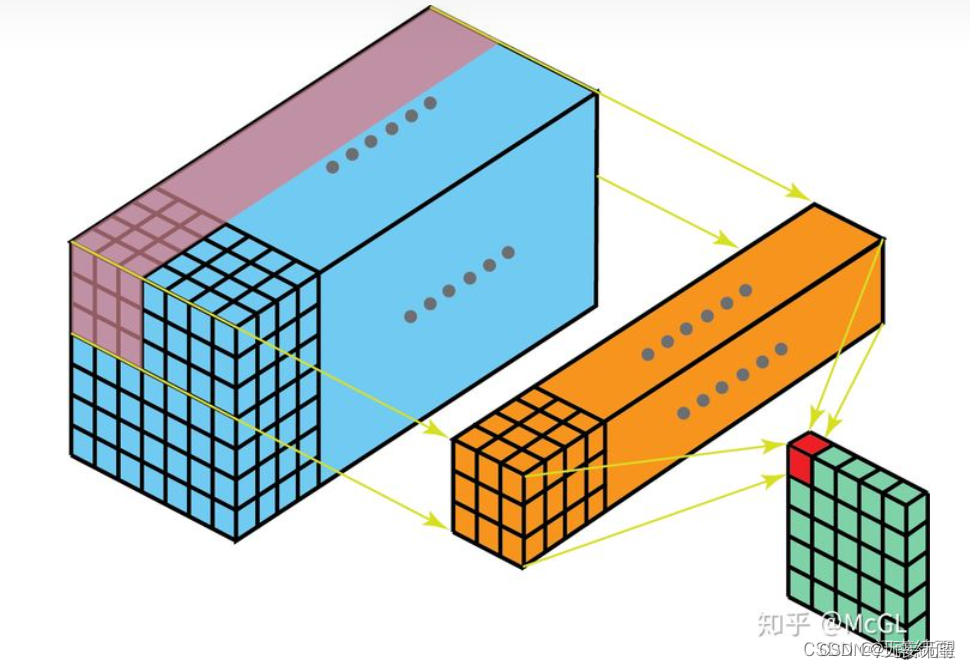
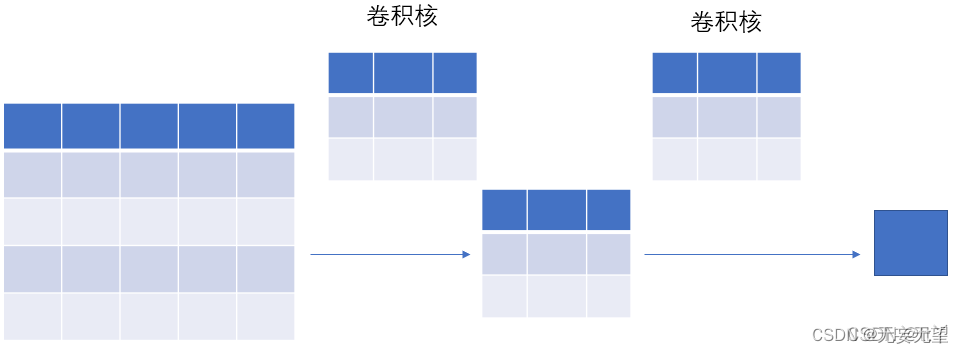
2.2D卷积
2D卷积是最常见的卷积,在计算机视觉中大量使用,在此不再赘述。如下图所示:
3.3D卷积
在3D卷积中,kernel可以在3个方向上移动,因此获得的输出也是3D。

三 深度可分离卷积
深度可分离卷积是一种将标准卷积操作分解为两个步骤的技术。首先是depthwise convolution,它对每个输入通道进行卷积操作。然后是pointwise convolution,它使用1x1的卷积核将深度卷积的输出通道进行组合。这种分解操作可以减少计算量和参数数量,从而提高卷积神经网络的效率。在深度卷积的过程中,通过将卷积核拆分为单通道形式,可以保持输入和输出特征图的维度不变,但通道数会增加,因此可以获得更多有效的信息。
1.深度可分离卷积的作用
减少参数量: 标准卷积使用一个卷积核对输入数据进行卷积,而深度可分离卷积将卷积操作分解为深度卷积和逐点卷积,从而显著减少了参数量。深度卷积只使用一个卷积核对输入通道逐通道进行卷积,逐点卷积使用1x1的卷积核进行通道之间的混合。
降低计算复杂度: 由于减少了参数量,深度可分离卷积在计算上更加高效,适合在资源有限的环境下使用,如移动设备或嵌入式系统。
提升特征提取能力: 尽管参数量减少了,但深度可分离卷积通过逐点卷积将不同通道的信息进行了组合,从而保持了一定的特征提取能力。
2.应用
深度可分离卷积适用于对通道维度较大的三维数据进行卷积操作的任务。它可以有效地减少参数量和计算量,同时保持模型的性能。深度可分离卷积在图像分类、目标检测和语义分割等计算机视觉任务中广泛应用。、
3.深度可分离卷积结构及代码实现
深度可分离卷积将标准卷积操作分解为两步:深度卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)。
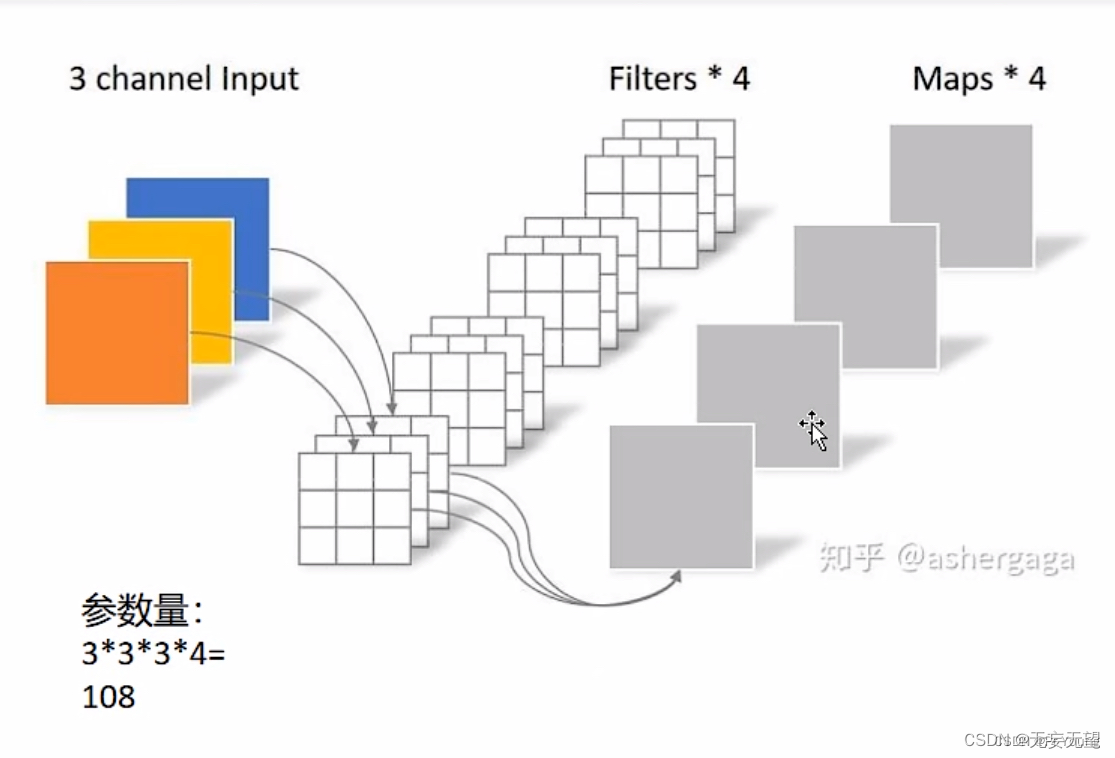
普通卷积:输入是三个通道,输出是四个通道
这里需要4个卷积核(输出几个通道就要几个卷积核,这里输出四个通道所以需要四个卷积核)
每个卷积核是3*3*3
所以参数总量是4个3*3*3,等于108个参数
深度卷积:
深度可分离卷积可分为两个过程,分别为逐通道卷积(Depthwise Convolution)和逐点卷积(Pointwise Convolution)
(1)逐通道卷积
这里参数量是3个3*3,等于27个
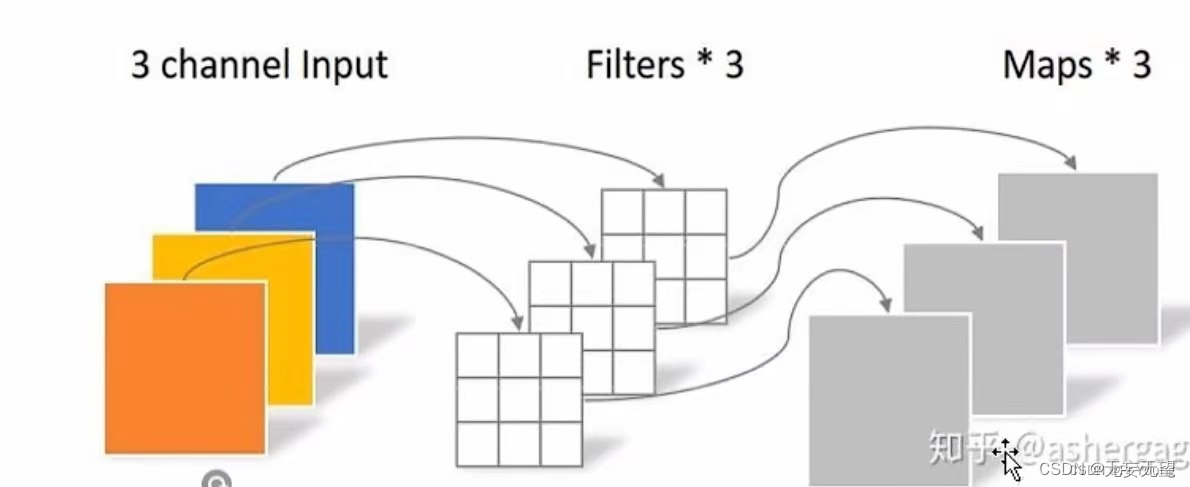
这样卷积的话,通道数不可改变,而且通道之间的信息也没有进行交互
(2)逐点卷积
这里我们再用四个卷积核,每个卷积核大小为1*1*3
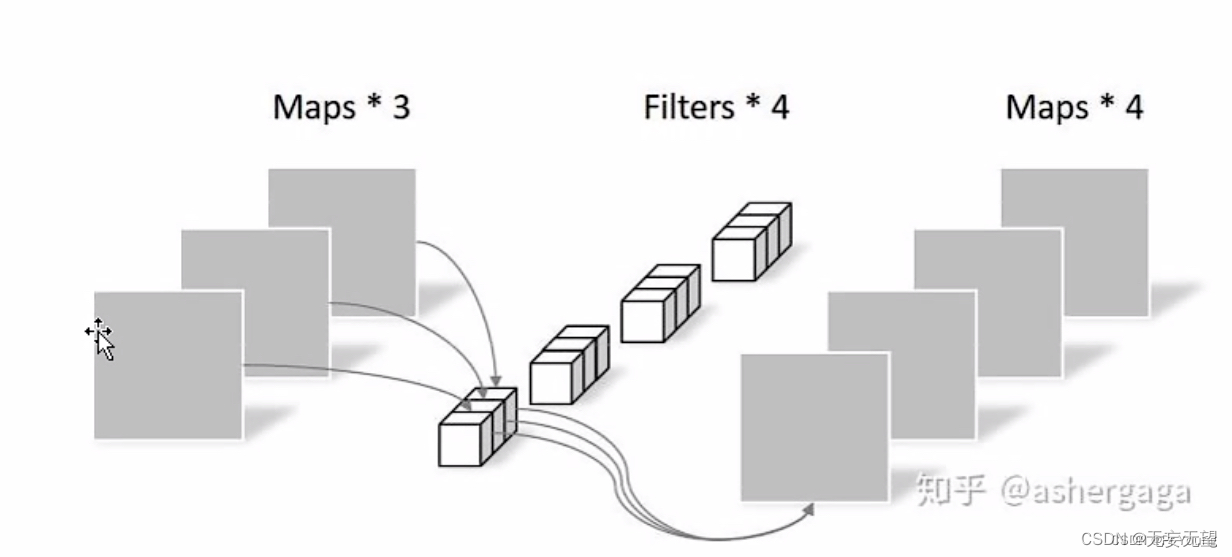
这样的话,参数总量就是4*1*1*3+27=39
可以看到,参数量大大减少
上面两步合起来就是:
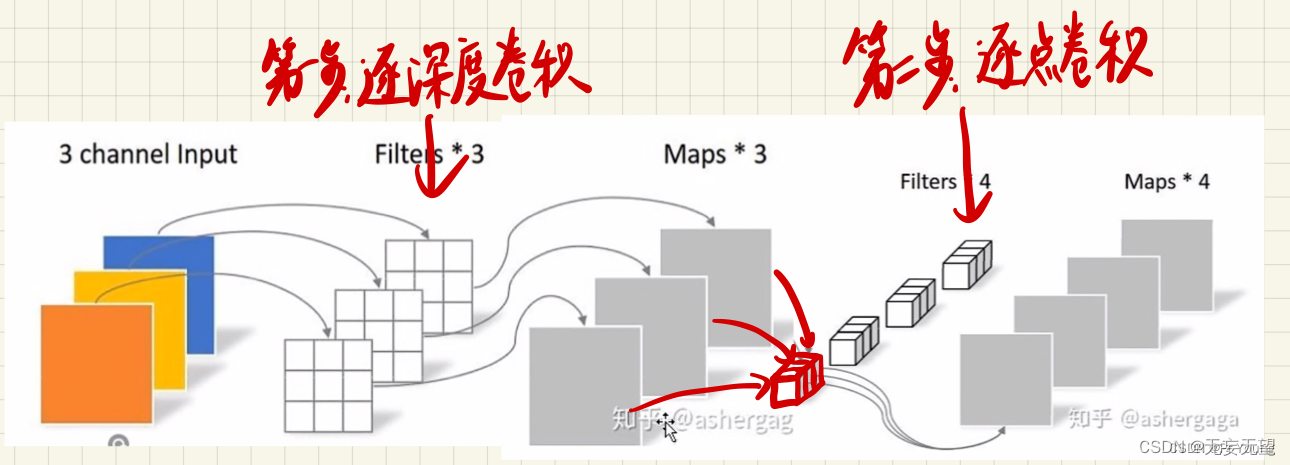
代码实现:
class DepthWiseConv(nn.Module):
def __init__(self,in_channel,out_channel):
#这一行千万不要忘记
super(DepthWiseConv, self).__init__()
# 逐通道卷积
self.depth_conv = nn.Conv2d(in_channels=in_channel,
out_channels=in_channel,
kernel_size=3,
stride=1,
padding=1,
groups=in_channel)
# groups是一个数,当groups=in_channel时,表示做逐通道卷积
#逐点卷积
self.point_conv = nn.Conv2d(in_channels=in_channel,
out_channels=out_channel,
kernel_size=1,
stride=1,
padding=0,
groups=1)
def forward(self,input):
out = self.depth_conv(input)
out = self.point_conv(out)
return out四 反卷积
1.什么是反卷积
反卷积和转置卷积都是一个意思,所谓的反卷积,就是卷积的逆操作,我们将上图的卷积看成是输入通过卷积核的透视,那么反卷积就可以看成输出通过卷积核的透视,具体如下图所示:
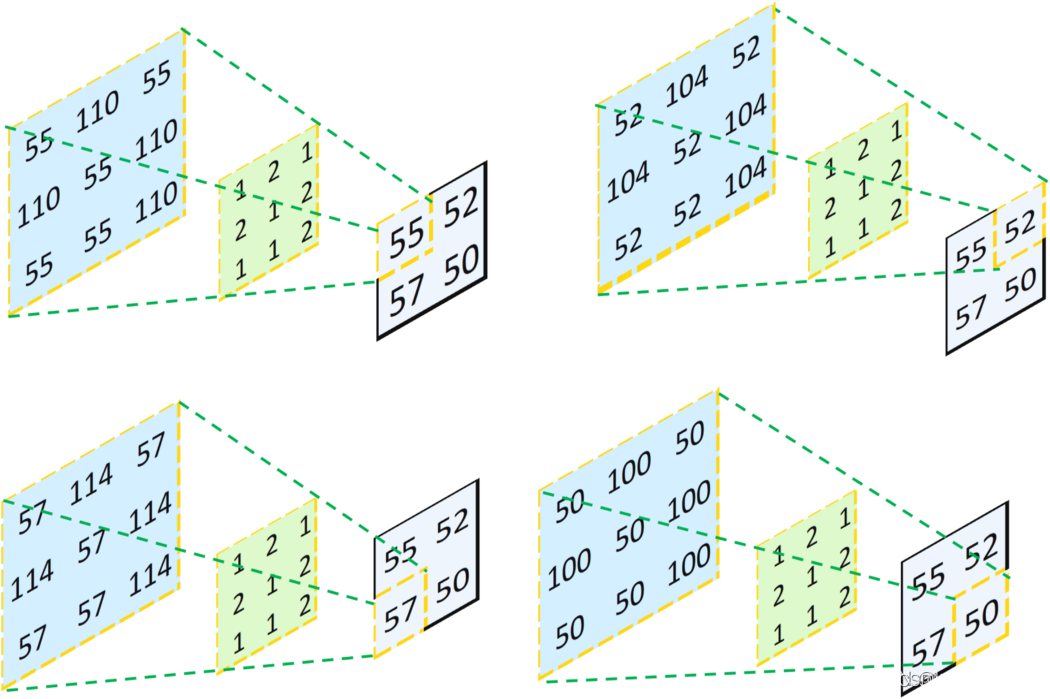
比如左上角的图,将输出的55按照绿色的线的逆方向投影回去,可以得到[[55,110,55],[110,55,110],[55,55,110]]的结果;
我们将得到的四张特征图进行叠加(重合的地方其值相加),可以得到下图:
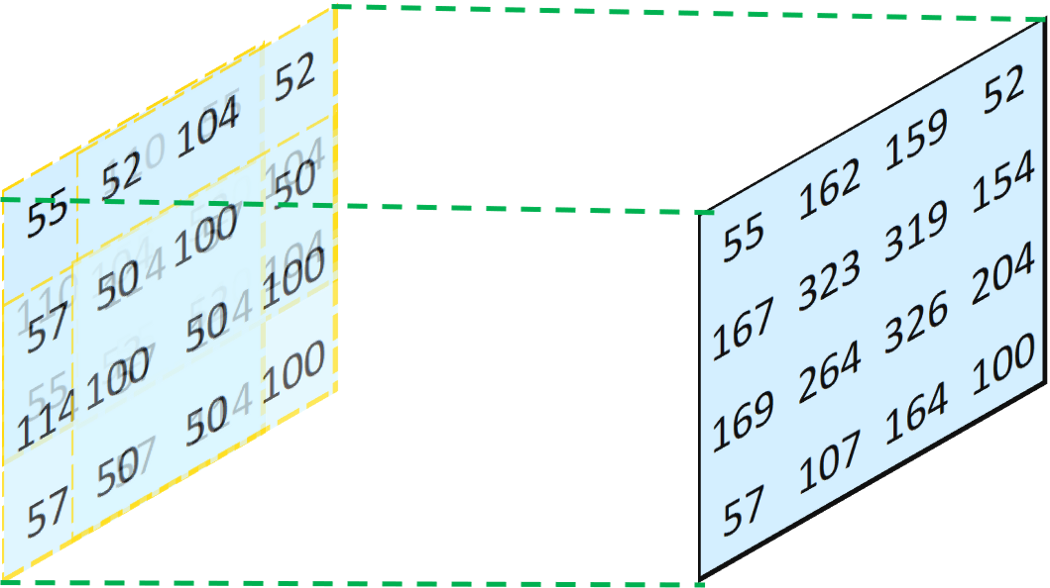
最终我们得到的特征图与卷积输入的特征图值的大小并不相同,说明卷积和反卷积并不是完全对等的可逆操作(因为采用相同的卷积核,卷积和反卷积得到的输入输出不同),也就是反卷积只能恢复尺寸,不能恢复数值
五 空洞卷积
1 感受野
感受野指:卷积神经网络每一层输出的特征图上的像素点在输入图片上映射的区域大小,即FC层每个输出节点的值都依赖FC层所有输入,而CONV层每个输出节点的值仅依赖CONV层输入的一个区域,这个区域之外的其他输入值都不会影响输出值,该区域就是感受野。简单来说就是特征图上的一个点对应输入图上的区域。
举个栗子:一个5*5的特征图经过2个3*3卷积核后(步长为1,padding为0)的感受野是5*5
注:计算感受野的大小时忽略了图像边缘的影响,即不考虑padding的大小
1.1感受野的计算
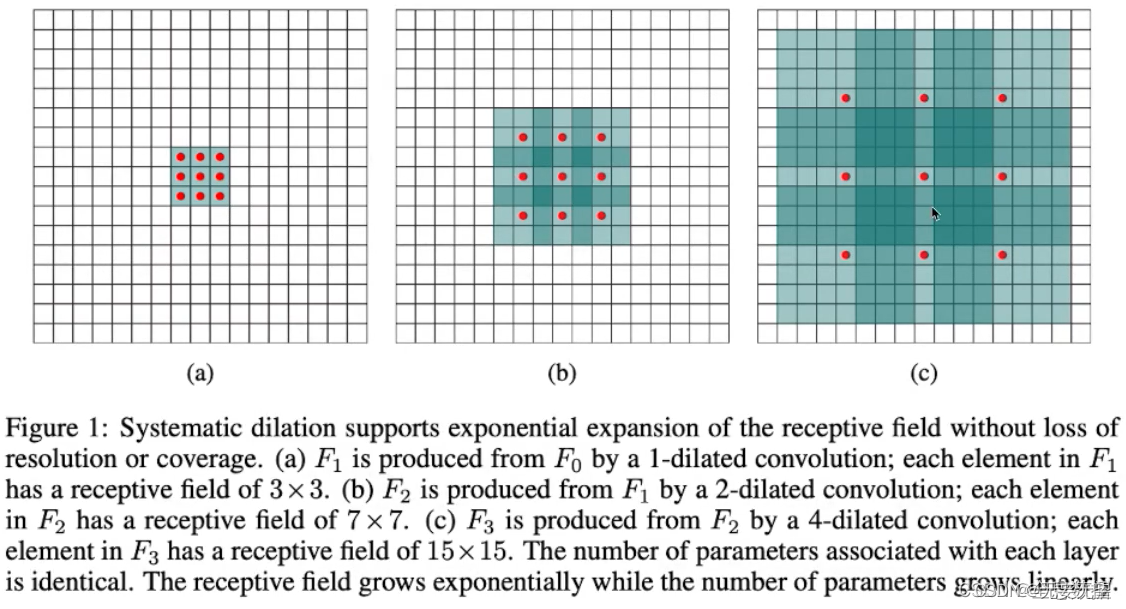
(a):对输入原图进行3×3的常规卷积,所以卷积后的每一个点的感受野为3×3;
(b):对(a)输出的feature map进行dilation为2的空洞卷积,(b)图每一个红点代表的感受野都为3×3,所以(b)图的感受野为7×7;
(c):以此类推,(c)图的感受野为15×15;
2 空洞卷积原理
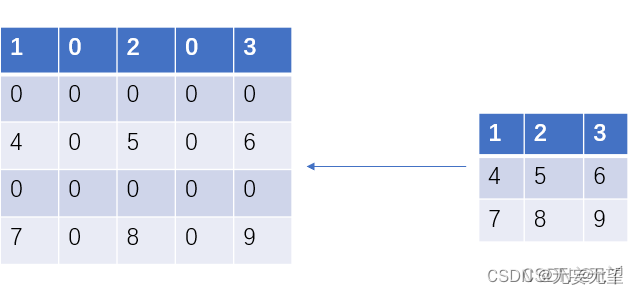
空洞卷积有一个参数可以设置dilation rate,具体含义就是在卷积核中相邻两个值内填充dilation rate-1个0

比如说一个3*3卷积核,dilation rate=2,那么如图所示
2.1 空洞卷积后的feature size大小
因为空洞卷积是对kernel size进行插值,所以空洞卷积后的feature size大小为:

上面这个式子应该都能看懂,只是加了dilation[0]之后,kernel size变成了dilation[0]*(kernel size[0]-1)+1,然后再替换原先的kernel size即可。
1.2.1空洞卷积的反卷积输出
说白了就是把上式的H_out、W_out作为输入,然后求出上式的H_in、W_in,此时的H_in、W_in作为空洞卷积反卷积之后的输出:
2.1 为什么使用空洞卷积
简单来说有两点:
1、增大了感受野;
一般来说,在深度神经网络中增加感受野并且减少计算量的方法是下采样。但是下采样牺牲了空间分辨率和一些输入的信息。
空洞卷积一方面增大了感受野可以检测分割大目标,另一方面相较于下采样增大了分辨率可以精确定位目标。
2、捕获多尺度上下文信息
当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息
参考:















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









