






论文分享 | 多模态大模型相关研究进展
我们从2024-12-03到2024-12-05的57篇文章中精选出5篇优秀的工作分享给读者。
-
Quantization-Aware Imitation-Learning for Resource-Efficient Robotic Control
-
Understanding the World’s Museums through Vision-Language Reasoning
-
NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
-
OODFace: Benchmarking Robustness of Face Recognition under Common Corruptions and Appearance Variations
-
VideoLights: Feature Refinement and Cross-Task Alignment Transformer for Joint Video Highlight Detection and Moment Retrieval
1.AV-Odyssey Bench: Can Your Multimodal LLMs Really Understand Audio-Visual Information?
Authors: Seongmin Park, Hyungmin Kim, Wonseok Jeon, Juyoung Yang, Byeongwook Jeon, Yoonseon Oh, Jungwook Choi
https://arxiv.org/abs/2412.01034
论文摘要
Recently, multimodal large language models (MLLMs), such as GPT-4o, Gemini 1.5 Pro, and Reka Core, have expanded their capabilities to include vision and audio modalities. While these models demonstrate impressive per formance across a wide range of audio-visual applications, our proposed DeafTest reveals that MLLMs often struggle with simple tasks humans find trivial: 1) determining which of two sounds is louder, and 2) determining which of two sounds has a higher pitch. Motivated by these observations, we introduce AV-Odyssey Bench, a comprehensive audio visual benchmark designed to assess whether those MLLMs can truly understand the audio-visual information. This benchmark encompasses 4,555 carefully crafted problems, each incorporating text, visual, and audio components. To successfully infer answers, models must effectively leverage clues from both visual and audio inputs. To ensure pre cise and objective evaluation of MLLM responses, we have structured the questions as multiple-choice, eliminating the need for humanevaluation or LLM-assisted assessment. We benchmark a series of closed-source and open-source mod els and summarize the observations. By revealing the limi tations of current models, we aim to provide useful insight for future dataset collection and model development.
论文简评
这篇论文针对当前多模态大语言模型(MLLMs)在音频视觉理解方面的不足,提出了AV-Odyssey Bench基准,为研究社区提供了一个全面且实用的评估工具。作者通过包含4555个多模态问题的数据集,系统地测试了模型在基本听觉任务和音频-视觉信息整合能力上的表现,并通过DeafTest揭示了当前模型在简单听觉辨别任务中的局限性。论文的贡献在于填补了现有基准中针对听觉理解的空白,同时为未来的数据集构建和模型优化提供了有价值的参考。整体而言,这项工作数据全面、问题设计合理,为多模态模型的研究提供了重要推动力。

2.Understanding the World’s Museums through Vision-Language Reasoning
Authors: Ada-Astrid Balauca, Sanjana Garai, Stefan Balauca, Rasesh Udayakumar Shetty, Naitik Agrawal, Dhwanil Subhashbhai Shah, Yuqian Fu, Xi Wang, Kristina Toutanova, Danda Pani Paudel, Luc Van Gool
https://arxiv.org/abs/2412.01370
论文摘要
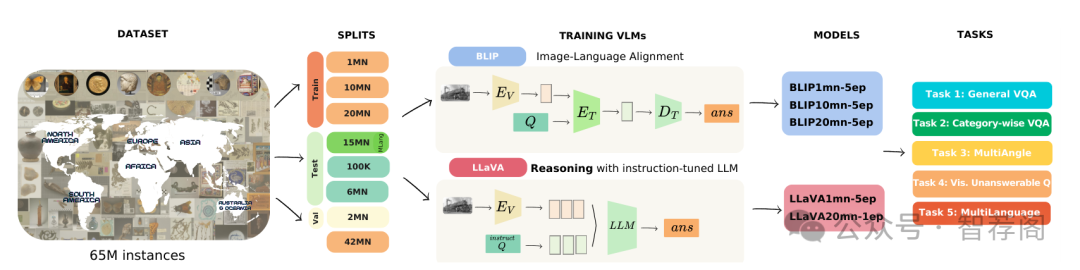
Museums serve as vital repositories of cultural heritage and historical artifacts spanning diverse epochs, civilizations, and regions, preserving well-documented collections. Data reveal key attributes such as age, origin, material, and cultural significance. Understanding museum exhibits from their images requires reasoning beyond visual features. In this work, we facilitate such reasoning by (a) collecting and curating a large-scale dataset of 65M images and 200M question-answer pairs in the standard museum catalog format for exhibits from all around the world; (b) training large vision-language models on the collected dataset; © benchmarking their ability on five visual question answering tasks. The complete dataset is labeled by museum experts, ensuring the quality as well as the practical sig- nificance of the labels. We train two VLMs from differ- ent categories: the BLIP model, with vision-language aligned embeddings, but lacking the expressive power of large language models, and the LLaVA model, a powerful instruction-tuned LLM enriched with vision-language reasoning capabilities. Through exhaustive experiments, we provide several insights on the complex and fine-grained understanding of museum exhibits. In particular, we show that some questions whose answers can often be derived directly from visual features are well answered by both types of models. On the other hand, questions that require the grounding of the visual features in repositories of human knowledge are better answered by the large vision-language models, thus demonstrating their superior capacity to perform the desired reasoning. Find our dataset, benchmarks, and source code at: github.com/insait-institute/Museum-65
论文简评
这篇论文介绍了一个名为MUSEUM-65的大规模数据集,包含650万张图像和2亿对问题-答案,旨在增强博物馆场景中的视觉问答(VQA)。它比较了两个视觉语言模型BLIP和LLaVA,并在多种与文化遗产相关的任务上评估它们的表现。该研究的主要贡献在于提供了丰富的资源,为未来的研究奠定了坚实的基础。此外,通过比较BLIP和LLaVA的性能,论文提出了有价值的见解,显示出这些模型在不同文化背景下的表现差异。此外,论文强调了MUSEUM-65对于教育和研究的重要性,因为它填补了现有数据集的空白,使研究者能够更深入地探索文化和历史知识的可视化表达方式。综上所述,本文不仅展示了MUSEUM-65的数据价值,也揭示了其对视觉问答领域的影响和意义,因此值得读者关注与研究。
3.NLPrompt: Noise-Label Prompt Learning for Vision-Language Models
Authors: Bikang Pan, Qun Li, Xiaoying Tang, Wei Huang, Zhen Fang, Feng Liu, Jingya Wang, Jingyi Yu, Ye Shi
https://arxiv.org/abs/2412.01256
论文摘要
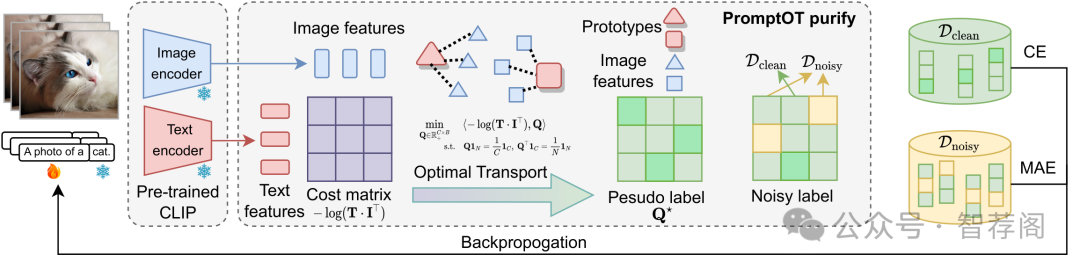
The emergence of vision-language foundation models, such as CLIP, has revolutionized image-text representation, enabling a broad range of applications via prompt learning. Despite its promise, real-world datasets often contain noisy labels that can degrade prompt learning performance. In this paper, we demonstrate that using mean absolute error (MAE) loss in prompt learning, named PromptMAE, significantly enhances robustness against noisy labels while maintaining high accuracy. Though MAE is straightforward and recognized for its robustness, it is rarely used in noisy-label learning due to its slow convergence and poor performance outside prompt learning scenarios. To elucidate the robustness of PromptMAE, we leverage feature learning theory to show that MAE can suppress the influence of noisy samples, thereby improving the signal-to-noise ratio and enhancing overall robustness. Additionally, we introduce PromptOT, a prompt-based optimal transport data purification method to further enhance robustness. PromptOT employs text encoder representations in vision-language models as prototypes to construct an optimal transportation matrix, effectively partitioning datasets into clean and noisy subsets, allowing for the application of cross-entropy loss to the clean subset and MAE loss to the noisy subset. Our Noise-Label Prompt Learning method, named NLPrompt, offers a simple and efficient approach that leverages the expressive representation and precise alignment capabilities of vision-language models for robust prompt learning. We validate NLPrompt through extensive experiments across various noise settings, demonstrating significant performance improvements.
论文简评
这篇论文探讨了如何通过引入NLPrompt方法来提高视觉语言模型中的提示学习效果。该方法的核心在于使用均方误差(Mean Absolute Error, MAE)损失函数以及PromptOT数据净化策略,旨在有效分离干净与有噪声的数据。实验结果表明,在不同噪声水平下,这种改进显著提高了模型性能。总的来说,这篇文章为机器学习中的一个重要问题——对抗性噪音标签,提供了一种有效的解决方案,为视觉语言模型的发展提供了新的思路。
4.OODFace: Benchmarking Robustness of Face Recognition under Common Corruptions and Appearance Variations
Authors: Caixin Kang, Yubo Chen, Shouwei Ruan, Shiji Zhao, Ruochen Zhang, Jiayi Wang, Shan Fu, Xingxing Wei
https://arxiv.org/abs/2412.02479
论文摘要
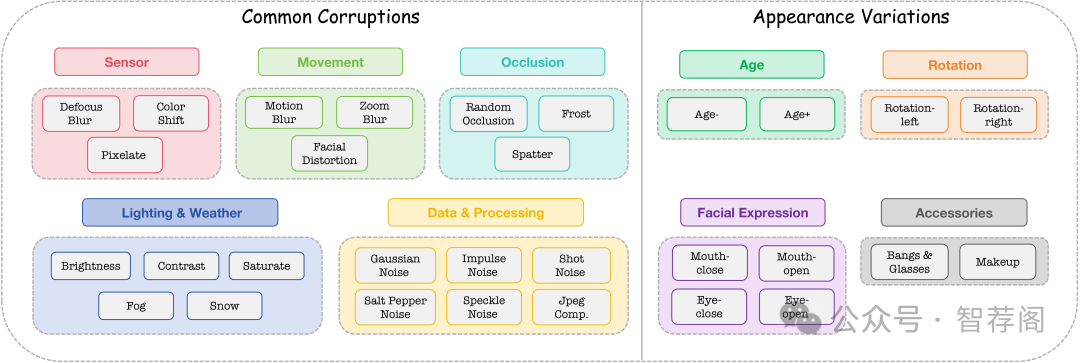
With the rise of deep learning, facial recognition technology has seen extensive research and rapid development. Although facial recognition is considered a mature technology, we find that existing open-source models and commercial algorithms lack robustness in certain real-world Out-of-Distribution (OOD) scenarios, raising concerns about the reliability of these systems. In this paper, we introduce OODFace, which explores the OOD challenges faced by facial recognition models from two perspectives: common corruptions and appearance variations. We systematically design 30 OOD scenarios across 9 major categories tailored for facial recognition. By simulating these challenges on public datasets, we establish three robustness benchmarks: LFW-C/V, CFP-FP-C/V, and YTF-C/V. We then conduct extensive experiments on 19 different facial recognition models and 3 commercial APIs, along with extended experiments on face masks, Vision-Language Models (VLMs), and defense strategies to assess their robustness. Based on the results, we draw several key insights, highlighting the vulnerability of facial recognition systems to OOD data and suggesting possible solutions. Additionally, we offer a unified toolkit that includes all corruption and variation types, easily extendable to other datasets. We hope that our benchmarks and findings can provide guidance for future improvements in facial recognition model robustness.
论文简评
OODFace作为面部识别系统对抗常见污染和外观变异的一套基准,是当前研究中一个重要方向。该文针对面部识别系统的弱点设计了30个OOD场景,并基于公开数据集建立了三个评估标准。实验结果表明,尽管模型和API在OOD挑战中的表现各异,但它们都存在一些共同的问题,如对局部细节的鲁棒性不足和泛化能力差等。这些发现为未来的研究提供了有价值的参考,并促使我们思考如何通过改进算法、优化特征提取过程等方式来提高面部识别系统的抗OOD能力。总的来说,该文深入分析了面部识别系统在OOD环境下的表现及其存在的问题,对于提升这一领域的研究具有重要意义。
5.VideoLights: Feature Refinement and Cross-Task Alignment Transformer for Joint Video Highlight Detection and Moment Retrieval
Authors: Dhiman Paul, Md Rizwan Parvez, Nabeel Mohammed, Shafin Rahman
https://arxiv.org/abs/2412.01558
论文摘要
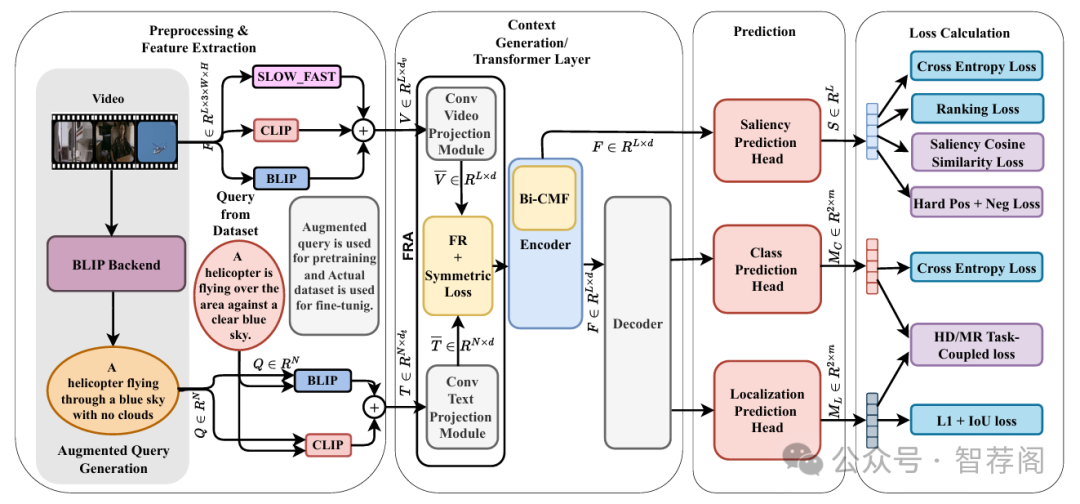
Video Highlight Detection and Moment Retrieval (HD/MR) are essential in video analysis. Recent joint prediction transformer models often overlook their cross-task dynamics and video-text alignment and refinement. Moreover, most mod els typically use limited, uni-directional attention mechanisms, resulting in weakly integrated representations and suboptimal performance in capturing the interdependence between video and text modalities. Although large-language and vision-language models (LLM/LVLMs) have gained prominence across various domains, their application in this field remains relatively un derexplored. Here we propose VideoLights, a novel HD/MR framework addressing these limitations through (i) Convolutional Projection and Feature Refinement modules with an alignment loss for better video-text feature alignment, (ii) Bi-Directional Cross-Modal Fusion network for strongly coupled query-aware clip representations, and (iii) Uni-directional joint-task feedback mechanism enhancing both tasks through correlation. In addi tion, (iv) we introduce hard positive/negative losses for adaptive error penalization and improved learning, and (v) leverage LVLMs like BLIP-2 for enhanced multimodal feature integra tion and intelligent pretraining using synthetic data generated from LVLMs. Comprehensive experiments on QVHighlights, TVSum, and Charades-STA benchmarks demonstrate state-of the-art performance. Codes and models are available at: https: //github.com/dpaul06/VideoLights.
论文简评
VideoLights 是一种开创性的方法,将视频和文本模态相结合,以解决视频中亮点检测与片段检索的联合任务问题。论文提出了一种新颖的框架,利用多个预训练的视觉-语言模型来实现更好的特征对齐和任务相互依赖性。作者引入了多个创新模块,提升了视频-文本的融合效果和性能,为计算机视觉与自然语言处理领域的研究人员和实践者提供了重要工具。在最新基准测试上取得了令人瞩目的成果,VideoLights 展现出其作为联合亮点检测和片段检索强大工具的潜力。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 3424
3424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









