






1.iVISPAR – An Interactive Visual-Spatial Reasoning Benchmark for VLMs
Authors: Julius Mayer, Mohamad Ballout, Serwan Jassim, Farbod Nosrat Nezami, Elia Bruni
Affiliations: University of Osnabruck
https://arxiv.org/abs/2502.03214
论文摘要
Vision-Language Models (VLMs) are known to struggle with spatial reasoning and visual alignment. To help overcome these limitations, we introduce iVISPAR, an interactive multi-modal benchmark designed to evaluate the spatial reasoning capabilities of VLMs acting as agents. iVISPAR is based on a variant of the sliding tile puzzle-a classic problem that demands logical planning, spatial awareness, and multi-step reasoning. The benchmark supports visual 2D, 3D, and text-based input modalities, enabling comprehensive assessments of VLMs’ planning and reasoning skills. We evaluate a broad suite of state-of-the-art open-source and closed-source VLMs, comparing their performance while also providing optimal path solutions and a human baseline to assess the task’s complexity and feasibility for humans. Results indicate that while some VLMs perform well on simple spatial tasks, they encounter difficulties with more complex configurations and problem properties. Notably, while VLMs generally perform better in 2D vision compared to 3D or text-based representations, they consistently fall short of human performance, illustrating the persistent challenge of visual alignment. This highlights critical gaps in current VLM capabilities, highlighting their limitations in achieving human-level cognition.
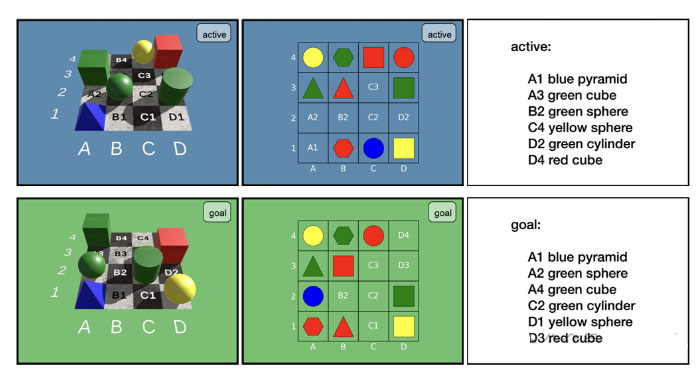
论文简评: iVISPAR 是一个交互式基准,用于评估使用滑动瓷砖框架的视觉语言模型(VLM)在空间推理方面的能力。它评估了在不同模态(2D、3D 和文本)下VLM的表现,并强调了与人类基线相比,在复杂空间任务中性能差距的显著性。该研究通过引入 iVISPAR,解决了当前在评估VLM空间推理能力时被忽视的重要问题,为实际场景中的空间推理研究提供了有价值的工具。此外,研究还对多个最先进的VLM进行了实证评估,揭示了它们在不同模态下的强项和弱点,从而为未来的研究提供指导。
2.From Foresight to Forethought: VLM-In-the-Loop Policy Steering via Latent Alignment
Authors: Yilin Wu, Ran Tian, Gokul Swamy, Andrea Bajcsy
Affiliations: Carnegie Mellon University; UC Berkeley
https://arxiv.org/abs/2502.01828
论文摘要
While generative robot policies have demonstrated significant potential in learning complex, multimodal behaviors from demonstrations, they still exhibit diverse failures at deployment-time. Policy steering offers an elegant solution to reducing the chance of failure by using an external verifier to select from low-level actions proposed by an imperfect generative policy. Here, one might hope to use a Vision Language Model (VLM) as a verifier, leveraging its open-world reasoning capabilities. However, off-the-shelf VLMs struggle to understand the consequences of low-level robot actions as they are represented fundamentally differently than the text and images the VLM was trained on. In response, we propose FOREWARN, a novel framework to unlock the potential of VLMs as open-vocabulary verifiers for runtime policy steering. Our key idea is to decouple the VLM’s burden of predicting action outcomes (foresight) from evaluation (forethought). For foresight, we leverage a latent world model to imagine future latent states given diverse low-level action plans. For forethought, we align the VLM with these predicted latent states to reason about the consequences of actions in its native representation–natural language–and effectively filter proposed plans. We validate our framework across diverse robotic manipulation tasks, demonstrating its ability to bridge representational gaps and provide robust, generalizable policy steering.
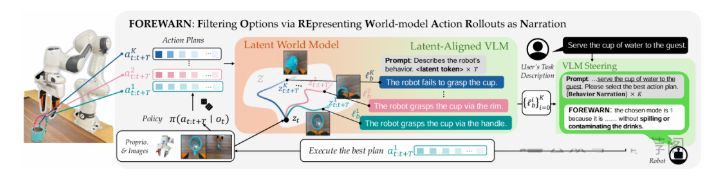
论文简评: 本文主要探讨了利用视觉语言模型(VLMs)和隐式动力学模型来改进动态环境中的行动选择策略的一种新颖政策引导框架——FOREWARN。该方法通过解耦结果预测和评估,为机器人任务中的可靠决策提供了更多可能性。文章中提出了使用隐式动力学模型对行动结果进行预测,并引入了视觉语言模型来解释机器人行为的创新方法。实验结果显示,这种方法显著提高了政策引导性能,在处理多样化操作任务时表现出良好的有效性。因此,本文提出的FOREWARN框架不仅具有理论意义,还在实际应用中展现了良好的效果。
3.Disentangling CLIP Features for Enhanced Localized Understanding
Authors: Samyak Rawelekar, Yujun Cai, Yiwei Wang, Ming-Hsuan Yang, Narendra Ahuja
Affiliations: Uni versity of Illinois Urbana-Champaign; University of Queensland; UC Merced; Yonsei University
https://arxiv.org/abs/2502.02977
论文摘要
Vision-language models (VLMs) demonstrate impressive capabilities in coarse-grained tasks like image classification and retrieval. However, they struggle with fine-grained tasks that require localized understanding. To investigate this weakness, we comprehensively analyze CLIP features and identify an important issue: semantic features are highly correlated. Specifically, the features of a class encode information about other classes, which we call mutual feature information (MFI). This mutual information becomes evident when we query a specific class and unrelated objects are activated along with the target class. To address this issue, we propose Unmix-CLIP, a novel framework designed to reduce MFI and improve feature disentanglement. We introduce MFI loss, which explicitly separates text features by projecting them into a space where inter-class similarity is minimized. To ensure a corresponding separation in image features, we use multi-label recognition (MLR) to align the image features with the separated text features. This ensures that both image and text features are disentangled and aligned across modalities, improving feature separation for downstream tasks. For the COCO-14 dataset, Unmix-CLIP reduces feature similarity by 24.9%. We demonstrate its effectiveness through extensive evaluations of MLR and zero-shot semantic segmentation (ZS3). In MLR, our method performs competitively on the VOC2007 and surpasses SOTA approaches on the COCO-14 dataset, using fewer training parameters. Additionally, Unmix-CLIP consistently outperforms existing ZS3 methods on COCO and VOC.
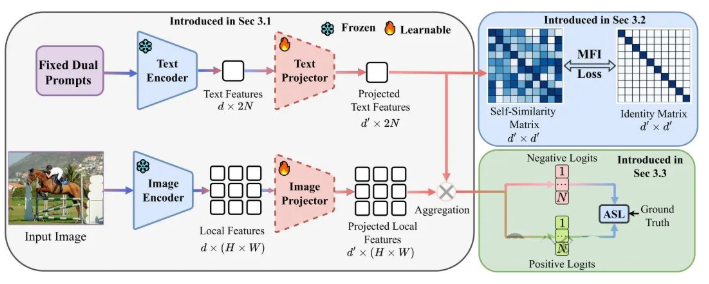
论文简评: 《Unmix-CLIP:一种改进视觉语言模型(VLM)本地理解能力的方法》提出了Unmix-CLIP这一框架,旨在通过解决视觉语言模型(VLM)中互相关联特征信息(MFI)的问题来改善其在细粒度任务中的表现。该文引入了MFI损失以解耦类特征,并使文本和图像特征更好地匹配,从而提升多标签识别和零样本语义分割等任务的表现。实验结果表明,该方法在基准数据集上的性能表现优异,展现了改进框架的有效性。总的来说,本文对互相关联特征信息作为CLIP适应细粒度任务的关键问题进行了深入探讨,同时提出了一种新颖的解决方案——MFI损失,为解决此类问题提供了新的思路。
4.RadVLM: A Multitask Conversational Vision-Language Model for Radiology
Authors: Nicolas Deperrois, Hidetoshi Matsuo, Samuel Ruipérez-Campillo, Moritz Vandenhirtz, Sonia Laguna, Alain Ryser, Koji Fujimoto, Mizuho Nishio, Thomas M. Sutter, Julia E. Vogt, Jonas Kluckert, Thomas Frauenfelder, Christian Blüthgen, Farhad Nooralahzadeh, Michael Krauthammer
Affiliations: University of Zurich; Kobe University; ETH Zurich; Kyoto University; University Hospital Zurich
https://arxiv.org/abs/2502.03333
论文摘要
The widespread use of chest X-rays (CXRs), coupled with a shortage of radiologists, has driven growing interest in automated CXR analysis and AI-assisted reporting. While existing vision-language models (VLMs) show promise in specific tasks such as report generation or abnormality detection, they often lack support for interactive diagnostic capabilities. In this work we present RadVLM, a compact, multitask conversational foundation model designed for CXR interpretation. To this end, we curate a large-scale instruction dataset comprising over 1 million image-instruction pairs containing both single-turn tasks – such as report generation, abnormality classification, and visual grounding – and multi-turn, multi-task conversational interactions. After fine-tuning RadVLM on this instruction dataset, we evaluate it across different tasks along with re-implemented baseline VLMs. Our results show that RadVLM achieves state-of-the-art performance in conversational capabilities and visual grounding while remaining competitive in other radiology tasks. Ablation studies further highlight the benefit of joint training across multiple tasks, particularly for scenarios with limited annotated data. Together, these findings highlight the potential of RadVLM as a clinically relevant AI assistant, providing structured CXR interpretation and conversational capabilities to support more effective and accessible diagnostic workflows.
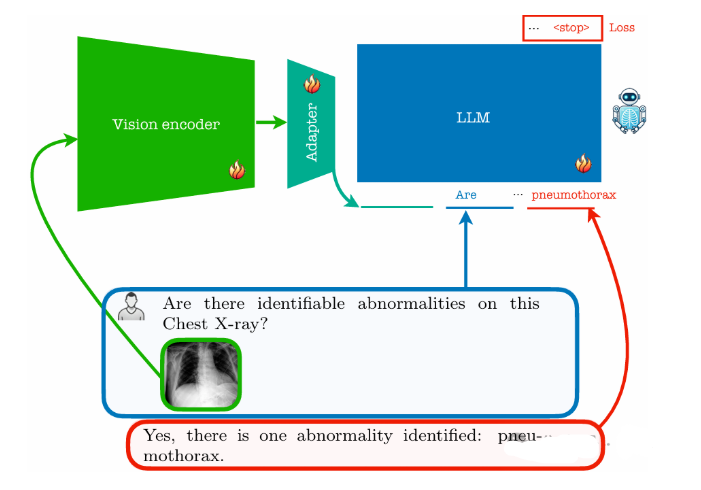
论文简评: 这篇论文深入探讨了胸部X线成像中的关键问题,并提出了一个名为RadVLM的多任务视觉语言模型,旨在辅助胸片解读。该文强调了构建自动化解决方案以解决这一问题的重要性。此外,作者详细介绍了他们设计的大规模指导数据集,并对模型进行了广泛评估,涵盖报告生成、异常分类和视觉定位等多个任务。通过与现有模型的比较,可以明显看出,RadVLM在多个任务上的表现优于竞争对手,尤其是在对话能力方面展现出卓越的表现。总的来说,本文提供了一种有效的解决方案以提高胸片解读的效率和准确性,具有重要的研究价值和应用前景。
5.SKI Models: Skeleton Induced Vision-Language Embeddings for Understanding Activities of Daily Living
Authors: Arkaprava Sinha, Dominick Reilly, Francois Bremond, Pu Wang, Srijan Das
Affiliations: University of North Carolina at Charlotte; Universit´ e Cˆ ote d’Azur; Inria
https://arxiv.org/abs/2502.03459
论文摘要
TThe introduction of vision-language models like CLIP has enabled the development of foundational video models capable of generalizing to unseen videos and human actions. However, these models are typically trained on web videos, which often fail to capture the challenges present in Activities of Daily Living (ADL) videos. Existing works address ADL-specific challenges, such as similar appearances, subtle motion patterns, and multiple viewpoints, by combining 3D skeletons and RGB videos. However, these approaches are not integrated with language, limiting their ability to generalize to unseen action classes. In this paper, we introduce SKI models, which integrate 3D skeletons into the vision-language embedding space. SKI models leverage a skeleton-language model, SkeletonCLIP, to infuse skeleton information into Vision Language Models (VLMs) and Large Vision Language Models (LVLMs) through collaborative training. Notably, SKI models do not require skeleton data during inference, enhancing their robustness for real-world applications. The effectiveness of SKI models is validated on three popular ADL datasets for zero-shot action recognition and video caption generation tasks.
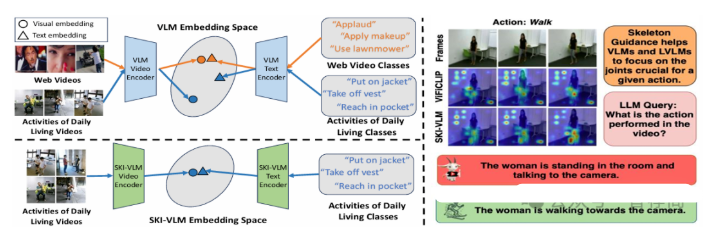
论文简评: 本文提出了一种名为SKI模型的新方法,该方法将三维骨架数据整合到视觉语言模型中,以改善日常生活活动(ADL)中的零样本动作识别能力。作者提出了一种称为骨骼CLIP汇聚的协作训练方法,允许模型通过增强视频表示来理解微妙的动作变化。实验结果表明,该方法在多个任务上显示了对零样本动作识别的改进,并且效果优于现有基准,表明了提出解决方案的价值。总的来说,本文展示了如何利用三维骨架数据提高视觉-语言模型在日常活动中的动作识别能力和适应性,这对于未来的研究具有重要的启示意义。
6. 如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 2081
2081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









