






基于YOLOv11的眼病分类项目
项目概述
本项目应用了YOLOv11这一先进的物体检测与分类算法,对眼部图像进行分类,以检测与失明相关的疾病。数据集来源于的eye disease([点击查看数据集]。
关键特性
-
数据准备
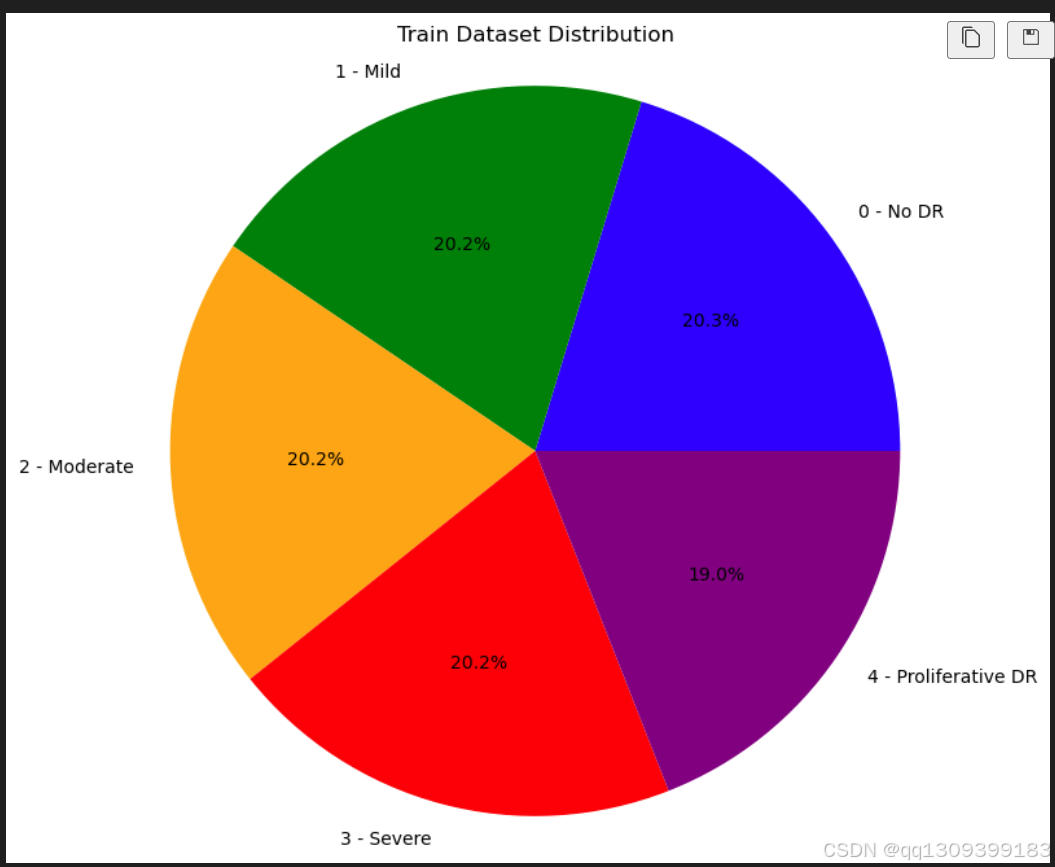
• 数据集按80:20的比例划分为训练集和验证集。
• 通过限制每个类别的图像数量,确保类别平衡。 -
模型实现
• YOLOv11被训练用于根据失明严重程度对图像进行分类。
• 性能指标包括精确率(precision)、召回率(recall)和F1分数(F1-score)。 -
自动化与可扩展性
• 脚本自动化数据组织,确保实验可重复性。
• 包含工具以验证数据集的完整性和平衡性。
数据集
数据集包含经过调整大小的眼部扫描图像,标注了不同类别的失明严重程度。数据经过预处理,去除冗余数据并保持类别间的平衡。
使用方法
- 克隆项目仓库。
- 安装所需依赖(
requirements.txt)。 - 运行训练管道以在数据集上训练YOLOv11。
- 在验证数据上评估模型。
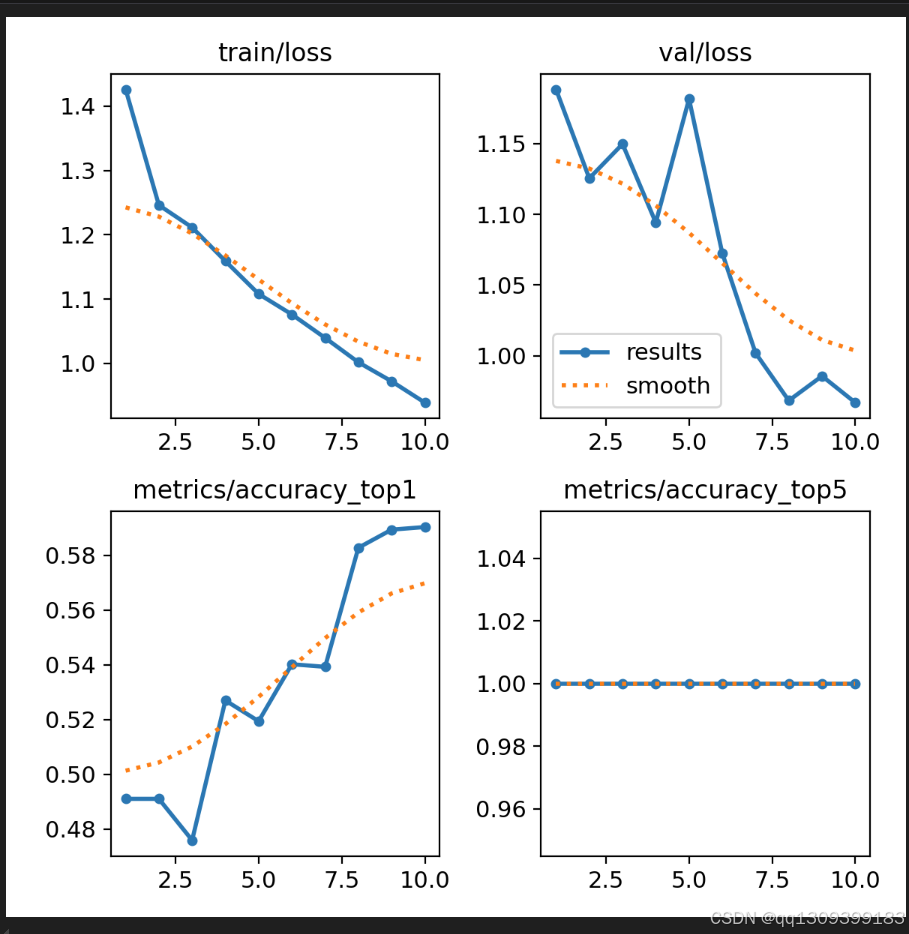
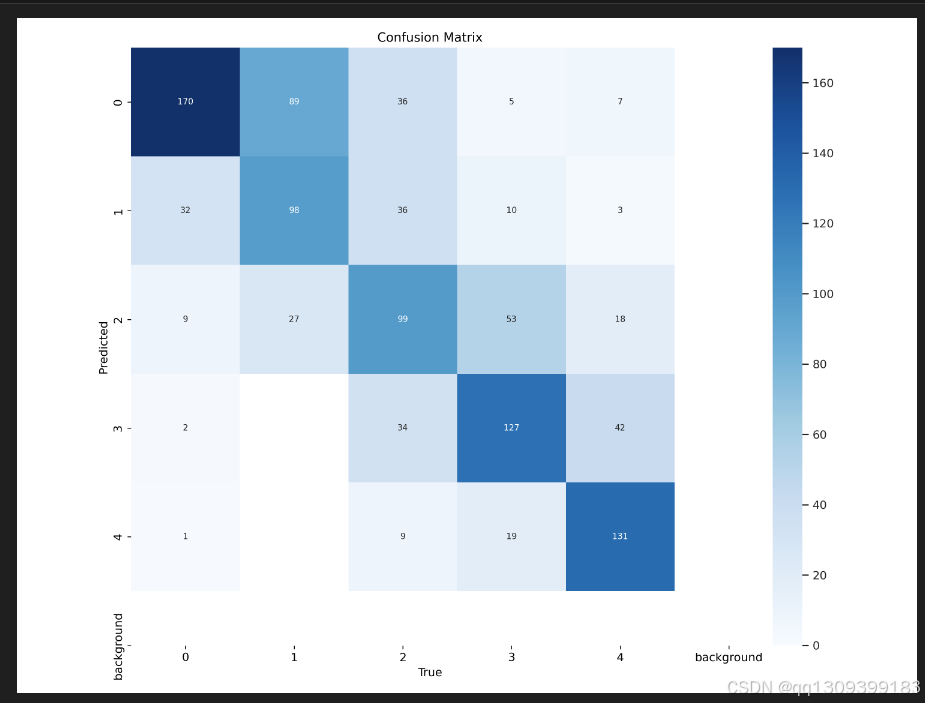
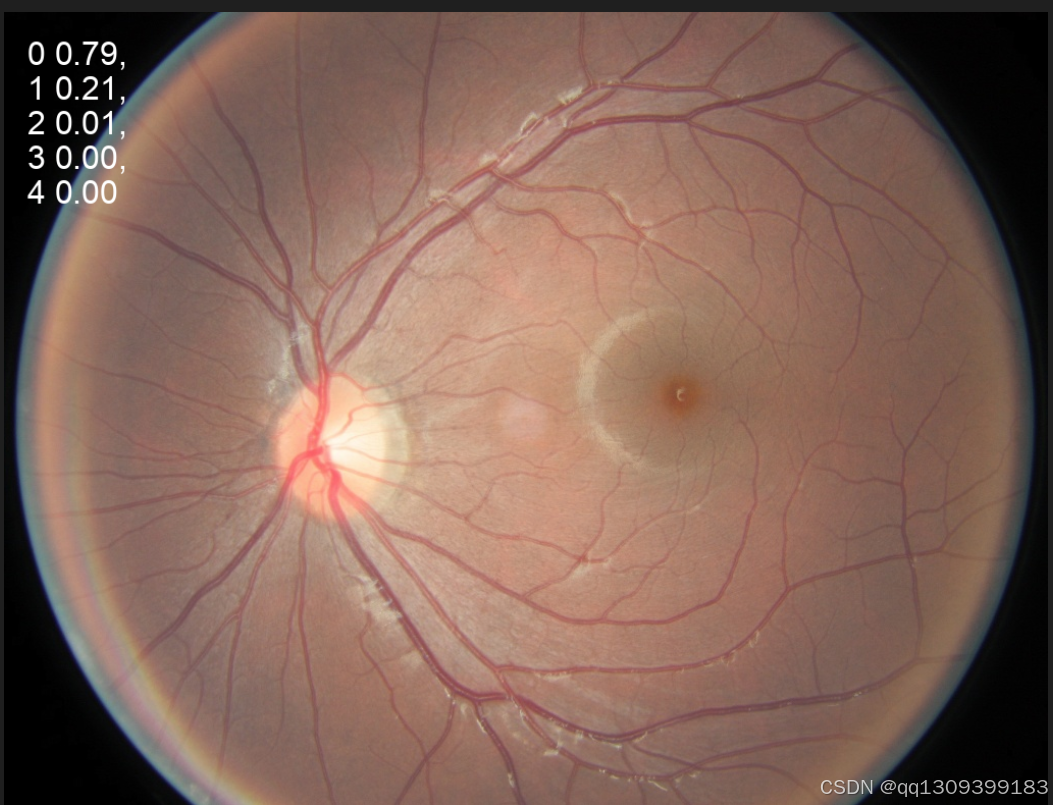
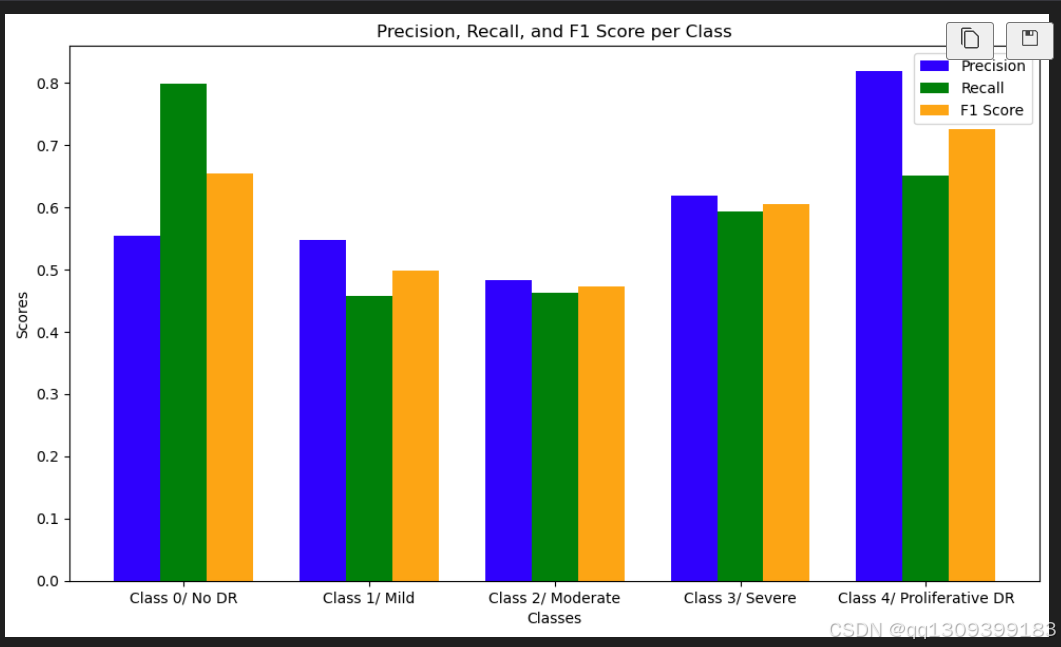
结果
YOLOv11模型取得了显著成果,展示了其在医学图像分类任务中的潜力。
YOLOv11的优势
YOLOv11在实时物体检测领域实现了重大飞跃,具有更快的处理速度、更少的参数和更高的准确度。其轻量级架构和增强的速度使其成为各种计算机视觉任务的强大工具。


















 139
139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









