







YOLOv8股市实时形态检测模型卡(基于屏幕捕捉)
模型概述
YOLOv8s股市形态检测模型是基于YOLO(You Only Look Once)框架的目标检测模型,专为实时检测屏幕捕捉的股市交易图表中的各类技术形态而设计。该模型通过自动化图表形态分析,为交易者和投资者提供及时洞察,辅助决策制定。模型经过多样化数据集微调,在实时交易场景中能高精度检测和分类股市形态。
模型详情
功能描述
本模型可实时检测股市屏幕截图中关键图表形态。随着市场快速变化,模型能提供及时洞察,帮助用户快速准确地做出决策。
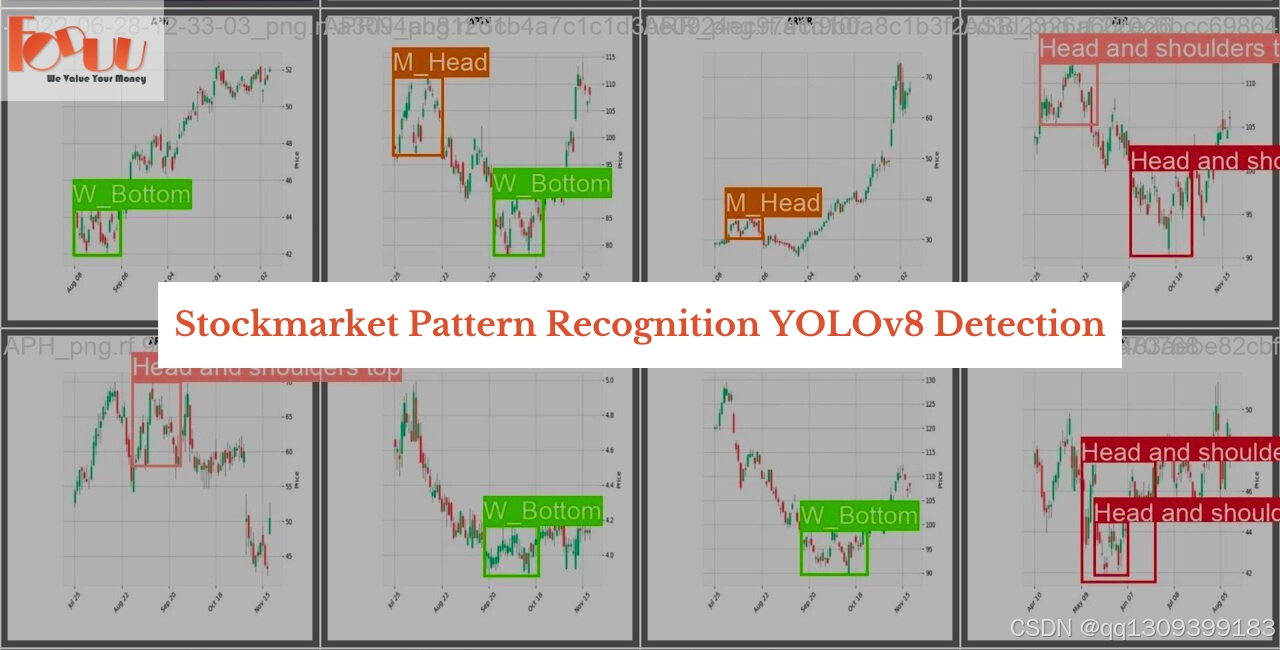
模型适用于股市交易图表的屏幕捕捉,可检测以下形态:
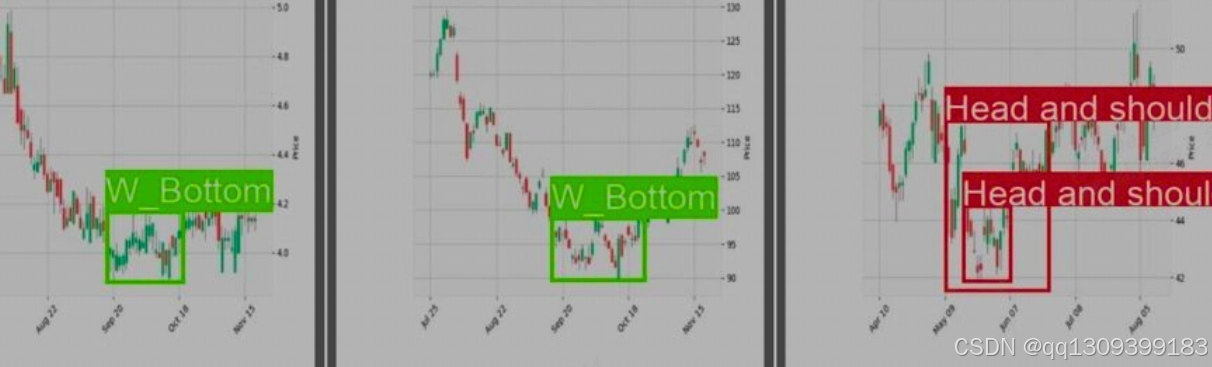
- 头肩底
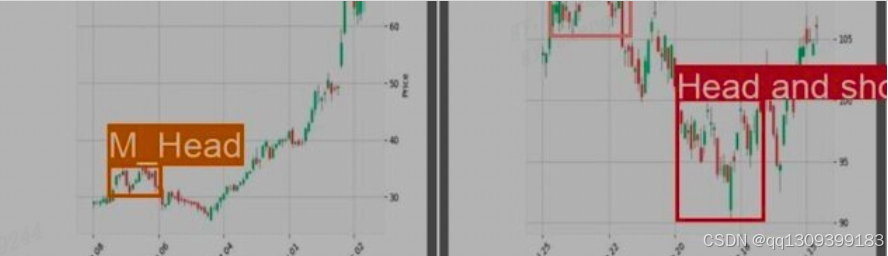
- 头肩顶
- M头
- 趋势线
- 三角形
- W底
开发方:FODUU AI
模型类型:目标检测
任务类型:屏幕捕捉的股市形态检测
支持标签
[‘头肩底’, ‘头肩顶’, ‘M头’, ‘趋势线’, ‘三角形’, ‘W底’]
应用场景
直接应用
- 实时检测股市图表形态
- 记录检测到的形态
- 标注检测图像
- 将结果保存至Excel文件
- 生成形态检测过程视频
衍生应用
- 自动化交易策略
- 特定形态预警
- 提升整体交易表现
训练数据
使用包含9000张训练图像和800张验证图像的自定义数据集进行训练。
非适用场景
本模型不适用于与股市屏幕捕捉形态检测无关的其他目标检测任务。
偏差、风险与局限
- 图表样式、屏幕分辨率和市场条件变化可能影响性能
- 市场剧烈波动和交易噪声可能降低准确性
- 训练数据未充分覆盖的市场特定形态可能检测困难
建议
用户应充分了解模型局限性和潜在偏差,建议在实盘部署前使用历史数据和实时市场条件进行测试验证。
快速开始
安装必要库:
pip install mss==10.0.0 opencv-python==4.11.0.86 numpy ultralytics==8.3.94 openpyxl==3.1.5
屏幕捕捉与形态检测实现代码:
import os
import mss # type: ignore
import cv2
import numpy as np
import time
import glob
from ultralytics import YOLO
from openpyxl import Workbook
# 获取用户主目录
home_dir = os.path.expanduser("~")
# 定义动态路径
save_path = os.path.join(home_dir, "yolo_detection")
screenshots_path = os.path.join(save_path, "screenshots")
detect_path = os.path.join(save_path, "runs", "detect")
# 确保目录存在
os.makedirs(screenshots_path, exist_ok=True)
os.makedirs(detect_path, exist_ok=True)
# 定义形态类别
classes = ['头肩底', '头肩顶', 'M头', '趋势线', '三角形', 'W底']
# 加载YOLOv8模型
model_path = "model.pt"
if not os.path.exists(model_path):
raise FileNotFoundError(f"未找到模型文件: {model_path}")
model = YOLO(model_path)
# 定义屏幕捕捉区域
monitor = {"top": 0, "left": 683, "width": 683, "height": 768}
# 创建Excel文件
excel_file = os.path.join(save_path, "classification_results.xlsx")
wb = Workbook()
ws = wb.active
ws.append(["时间戳", "预测图像路径", "标签"]) # 表头
# 初始化视频写入器
video_path = os.path.join(save_path, "annotated_video.mp4")
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
fps = 0.5 # 可调整帧率
video_writer = None
with mss.mss() as sct:
start_time = time.time()
last_capture_time = start_time # 记录上次捕获时间
frame_count = 0
while True:
# 持续捕捉屏幕
sct_img = sct.grab(monitor)
img = np.array(sct_img)
img = cv2.cvtColor(img, cv2.COLOR_BGRA2BGR)
# 每60秒执行一次YOLO预测
current_time = time.time()
if current_time - last_capture_time >= 60:
# 截图用于预测
timestamp = time.strftime("%Y-%m-%d %H:%M:%S")
image_name = f"predicted_images_{timestamp}_{frame_count}.png"
image_path = os.path.join(screenshots_path, image_name)
cv2.imwrite(image_path, img)
# 运行YOLO模型
results = model(image_path, save=True)
predict_path = results[0].save_dir if results else None
# 获取最新标注图像
if predict_path and os.path.exists(predict_path):
annotated_images = sorted(glob.glob(os.path.join(predict_path, "*.jpg")), key=os.path.getmtime, reverse=True)
final_image_path = annotated_images[0] if annotated_images else image_path
else:
final_image_path = image_path # 回退到原始图像
# 确定预测标签
if results and results[0].boxes:
class_indices = results[0].boxes.cls.tolist()
predicted_label = classes[int(class_indices[0])]
else:
predicted_label = "未检测到形态"
# 写入Excel(存储路径而非图像)
ws.append([timestamp, final_image_path, predicted_label])
# 读取图像用于视频处理
annotated_img = cv2.imread(final_image_path)
if annotated_img is not None:
# 添加时间戳和标签文本
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(annotated_img, f"{timestamp}", (10, 30), font, 0.7, (0, 255, 0), 2, cv2.LINE_AA)
cv2.putText(annotated_img, f"{predicted_label}", (10, 60), font, 0.7, (0, 255, 255), 2, cv2.LINE_AA)
# 初始化视频写入器
if video_writer is None:
height, width, layers = annotated_img.shape
video_writer = cv2.VideoWriter(video_path, fourcc, fps, (width, height))
video_writer.write(annotated_img)
print(f"帧 {frame_count}: {final_image_path} -> {predicted_label}")
frame_count += 1
# 更新最后捕获时间
last_capture_time = current_time
# 定期保存Excel文件
wb.save(excel_file)
# 实时显示屏幕捕捉(可选)
cv2.imshow("屏幕捕捉", img)
# 按Q键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放视频写入器
if video_writer is not None:
video_writer.release()
print(f"视频已保存至 {video_path}")
# 清理截图目录
for file in os.scandir(screenshots_path):
os.remove(file.path)
os.rmdir(screenshots_path)
print(f"结果已保存至 {excel_file}")
# 关闭OpenCV窗口
cv2.destroyAllWindows()


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









