







声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
中华穿山甲优化算法(Chinese pangolin optimizer, CPO)是一种新型的元启发式算法(智能优化算法),灵感来源于中华穿山甲独特的捕食行为。该算法利用马尔可夫链理论分析了该算法的收敛性,从理论上保证了算法在优化过程中的高效性和可靠性!该成果由Zhiqing Guo于2025年2月发表在SCI期刊《The Journal of Supercomputing》上!

由于发表时间较短,谷歌学术上还没人引用!你先用,你就是创新!

原理简介
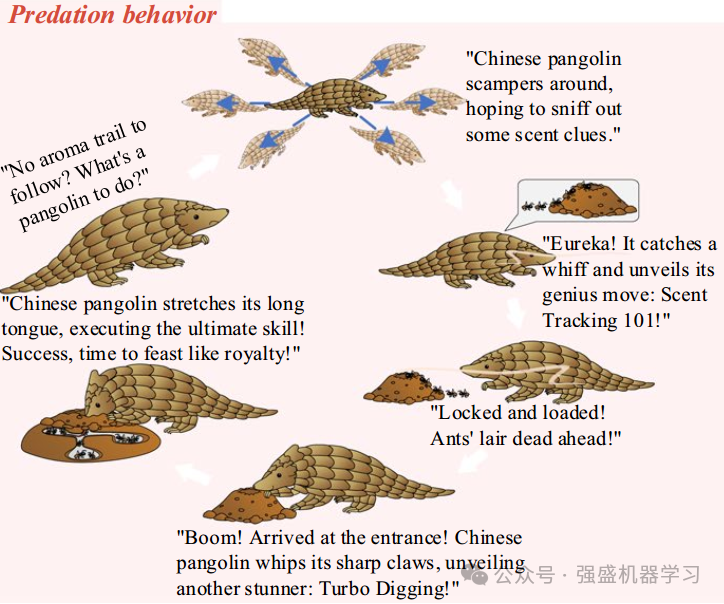
灵感:穿山甲对蚂蚁的捕猎行为可以分为两种行为:引诱和捕食。中国穿山甲依靠敏锐的嗅觉和狩猎本能判断猎物与自己位置的距离,有效地在引诱和捕食行为之间转换,这些行为是提出的CPO算法的主要灵感。

一、香气模型
在自然界中,穿山甲的主要捕食方式是依靠其敏锐的嗅觉来定位蚂蚁或散发其气味吸引蚂蚁,当穿山甲探测到较高的气味浓度时,表明它距离蚂蚁较近,增加了它成功获取食物的概率;同样,当蚂蚁探测到穿山甲散发的气味浓度较高时,因此,建立基于气味扩散的数学模型:
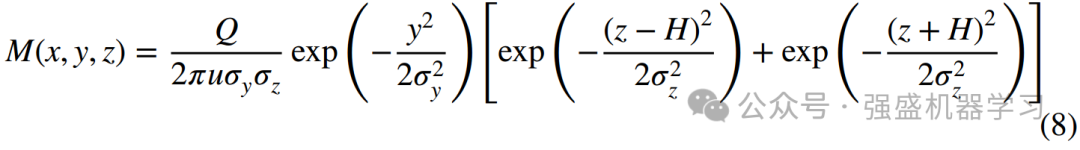
由于穿山甲和蚂蚁都是沿着地面寻找香气源的,因此,地面香气浓度计算公式可用于模拟本文提出的香气浓度模型,地面香气浓度计算公式为:
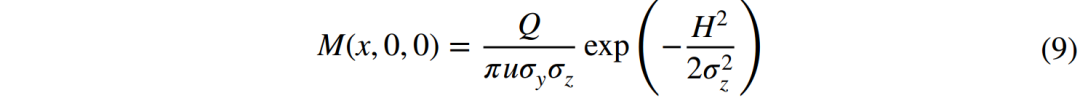
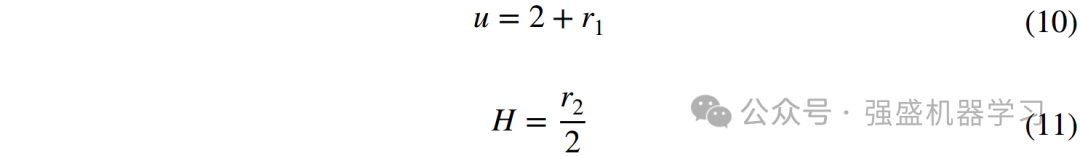
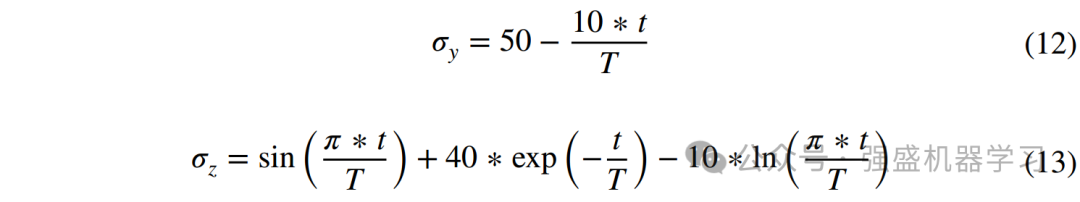
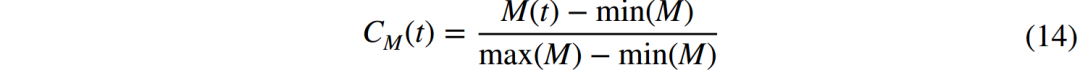
二、初始化
与其他生物启发式元启发式算法类似,CPO的种群进化和迭代优化规则都是基于种群的初始化来实现的:
![]()
三、引诱行为
当中华穿山甲周围蚂蚁的香气浓度较高,且不主动捕食猎物时,穿山甲会采取“装死”的策略,释放固体香气吸引蚂蚁靠近自己,实现成功取食,在CPO中,这种引诱行为可分为两个阶段:吸引捕获阶段和运动摄食阶段(CM(t)≥ 0.2&r1 ≤ 0.5)。
case1:吸引捕获阶段。穿山甲通过释放香气吸引蚂蚁,蚂蚁跟踪香气轨迹并逐渐靠近,直至被穿山甲捕获,因此,在此情境下,穿山甲与蚂蚁的位置关系主要受香气轨迹、疲劳指数、以及蚂蚁运动过程中的能量波动。对应于该阶段的数学模型可以定义为:
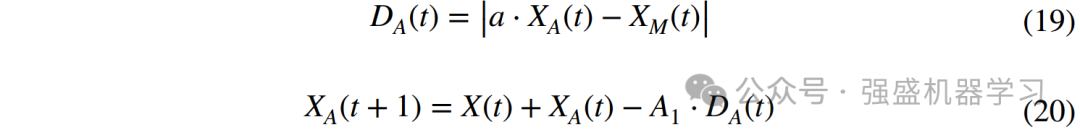
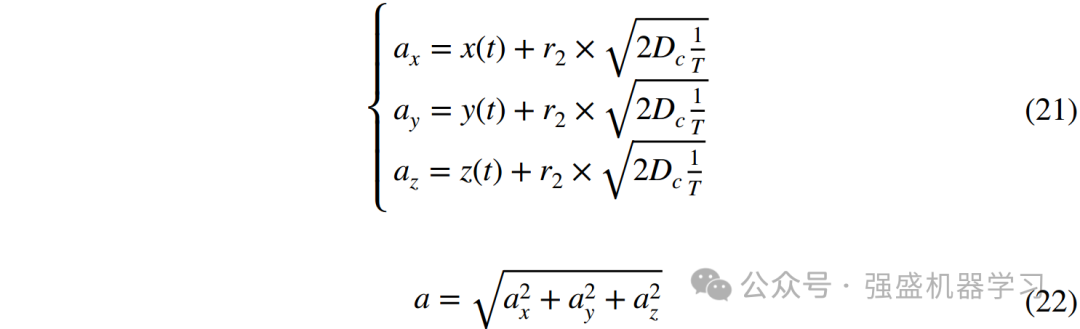
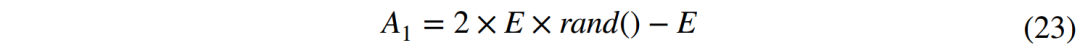
![]()
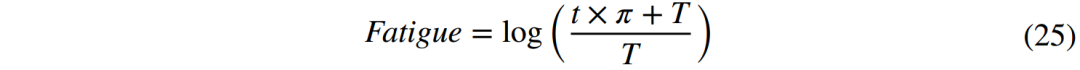
case2:移动和进食阶段。穿山甲捕捉到蚂蚁后,会迅速向最近的小河(或池塘)移动。一旦到达水边,穿山甲会爬入水中,释放身上的鳞片,然后用长长的舌头进食漂浮在水面上的蚂蚁。在这种情况下,中国穿山甲和蚂蚁处于同一位置,中国穿山甲将蚂蚁带向最佳位置。对应于该阶段的数学模型可以定义为:
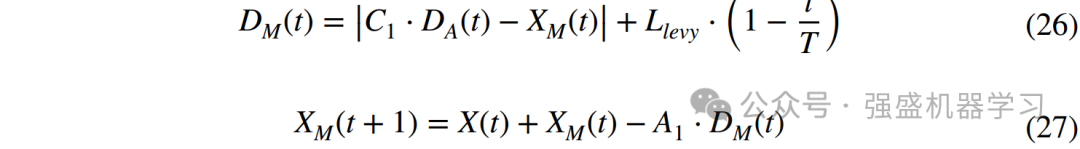
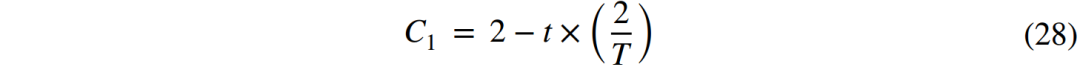
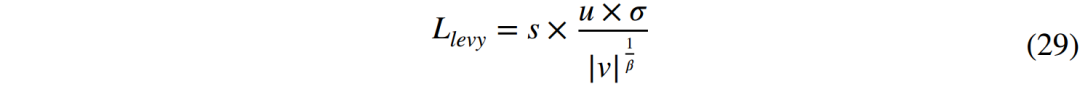
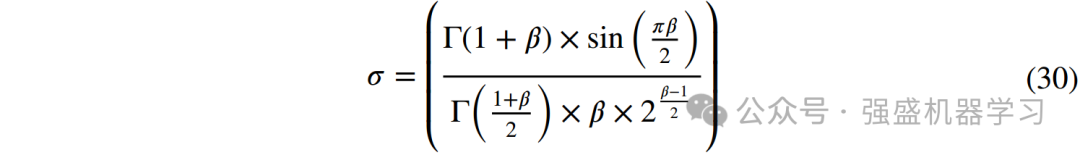
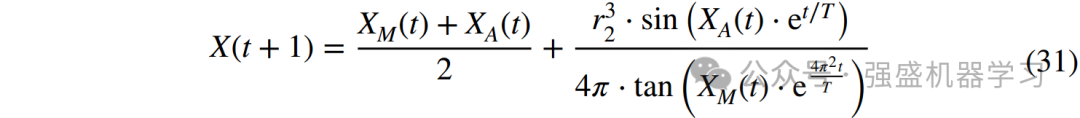
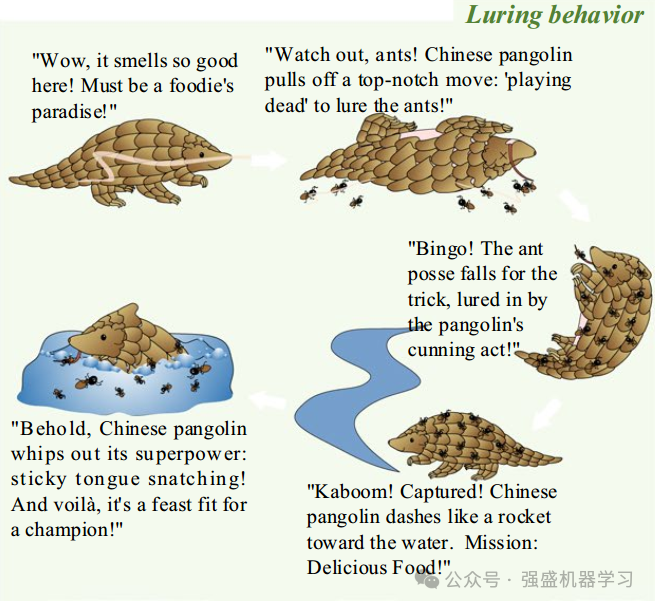
四、捕食行为
当周围蚂蚁释放的气味浓度较低或穿山甲愿意主动捕食时,它首先根据气味浓度快速定位蚁巢,然后沿着气味轨迹快速接近蚁巢,到达蚁巢后,用四肢挖掘洞穴,迅速捕获蚂蚁。在CPO中,这种捕食行为可以分为三个阶段:搜索定位、快速接近、挖食(CM < 0.7|| r1 > 0.5)。
case1:搜索定位阶段(0 ≤ CM < 0.3)。在此阶段,由于蚁巢与穿山甲所在位置的距离,穿山甲无法探测到蚁巢释放的香气。因此,穿山甲最初会选择在周围的空间中随机游走,直到闻到蚂蚁散发的气味,然后根据气味进行蚂蚁巢穴的定位,在这个过程中,穿山甲的随机游走遵循一个Levy飞行函数,穿山甲的能量水平在这个随机游走过程中也会发生变化,因此,该阶段的数学模型表示为:
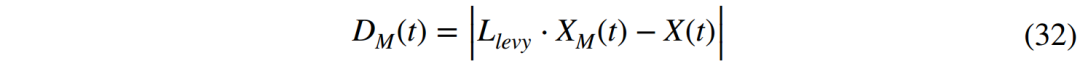
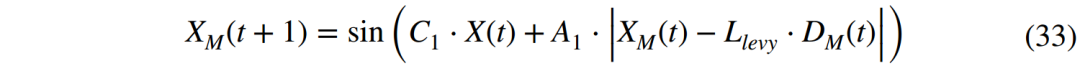
case2:快速接近阶段(0.2 ≤ CM < 0.6)。经过搜索定位阶段后,穿山甲已经成功定位到蚁穴,因此,穿山甲会沿着香气轨迹快速前进,跟踪直至逐渐接近蚁穴位置,此阶段的数学模型表示为:
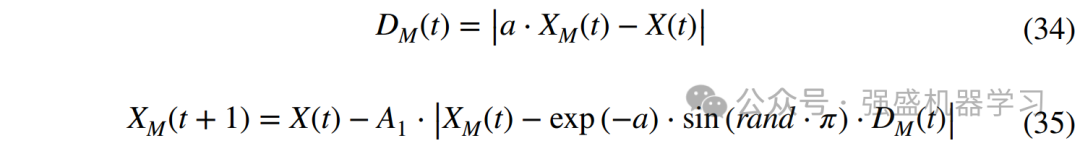
case3:挖食阶段(CM ≥ 0.6)。此时中国穿山甲已经成功定位蚁穴,它会用锋利的四肢快速挖食蚁穴,最后将长长的舌头伸入蚁穴中捕捉蚂蚁,该阶段的数学模型为:
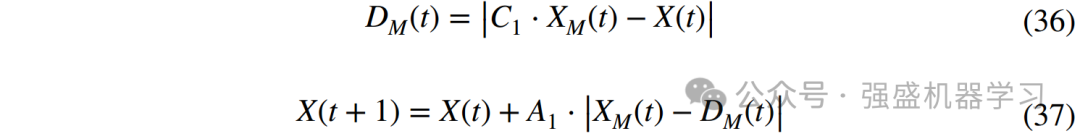
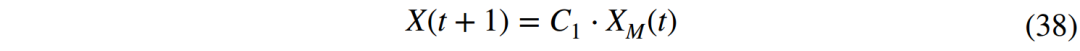
算法流程图和伪代码
为了使大家更好地理解,这边给出作者算法的流程图和伪代码,非常清晰!
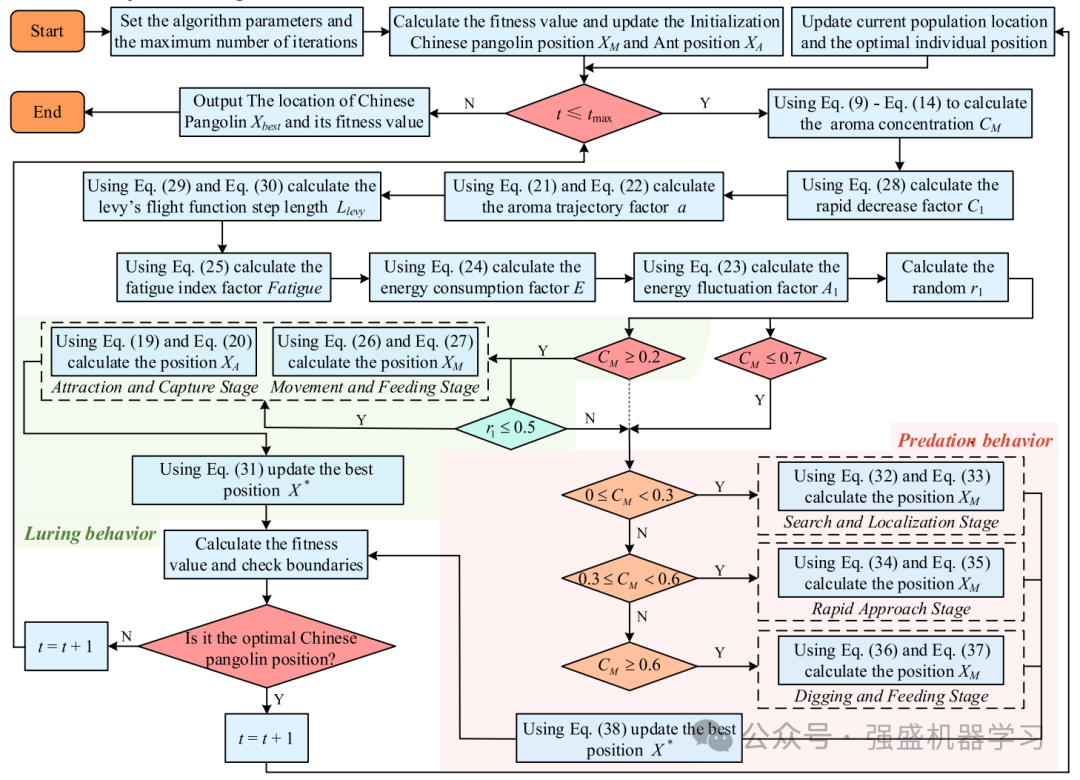

如果实在看不懂,不用担心,可以看下源代码,再结合上文公式理解就一目了然了!
性能测评
原文作者在74个标准基准函数以及CEC2017、CEC2019和CEC2022测试集上的实验结果及统计分析表明,CPO算法在求解复杂数值优化问题时是有效和收敛的,并成功地应用于三个标准的数值优化问题实验。
这边为了方便大家对比与理解,采用23个标准测试函数,即CEC2005,设置种群数量为30,迭代次数为1000,和2024年新出的鹅优化算法进行对比!这边展示其中5个测试函数的图,其余十几个测试函数大家可以自行切换尝试!
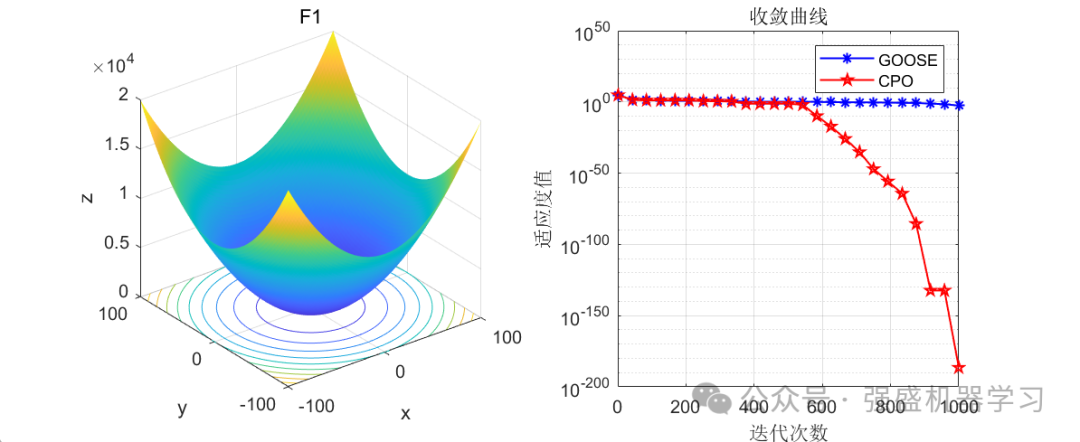
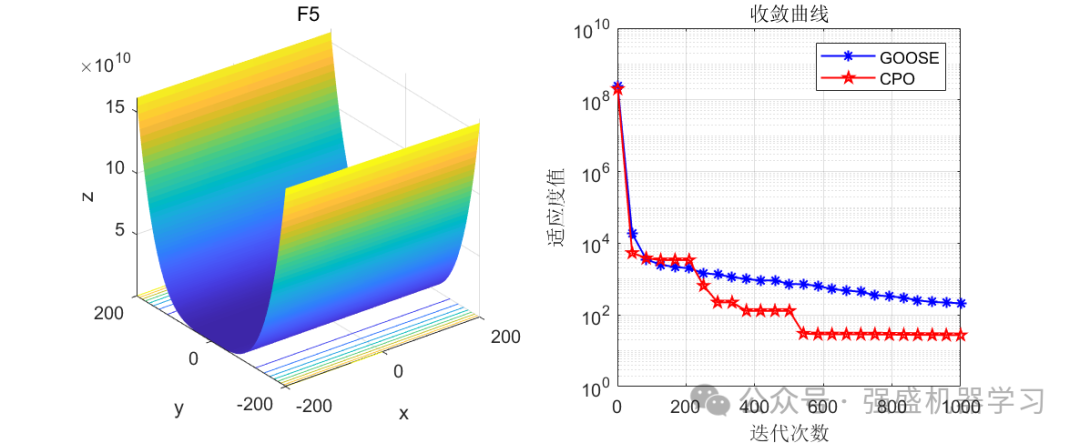
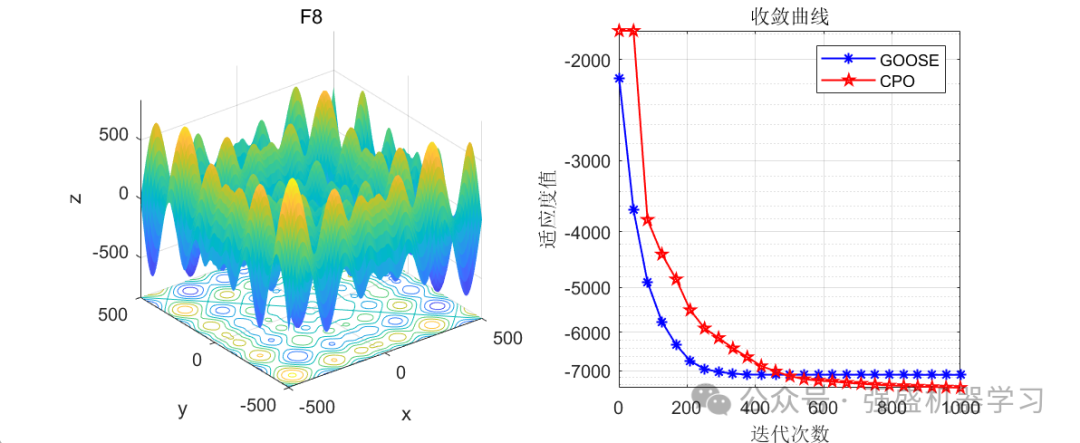
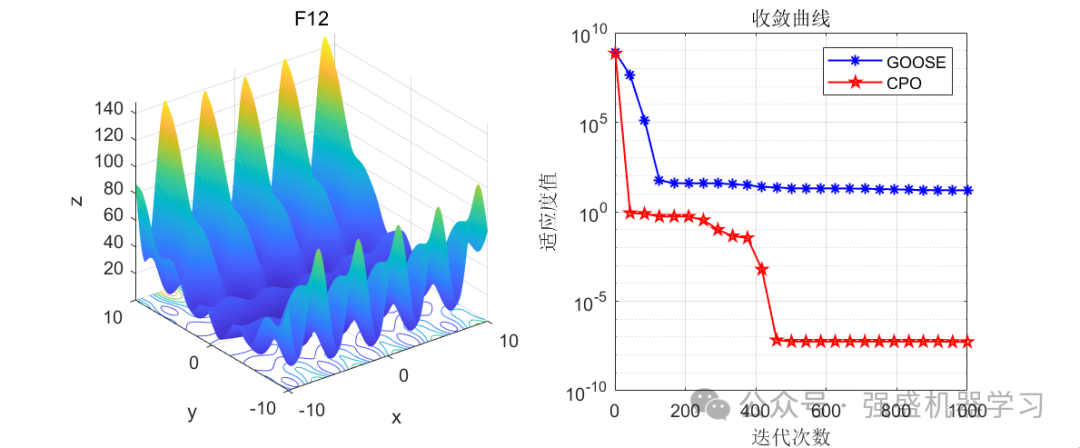
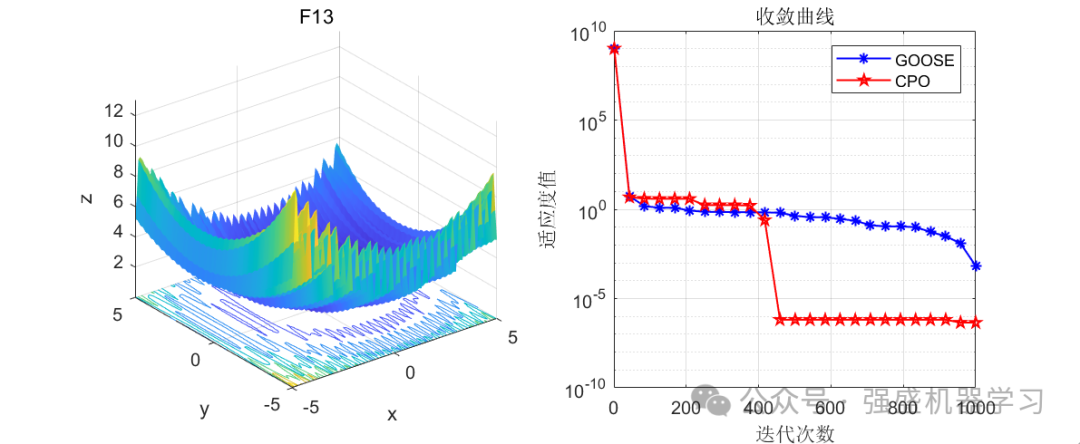
可以看到,这个算法在迭代后期收敛曲线下降非常快,大部分函数上均优于GOOSE算法,表明其局部寻优能力非常强!大家应用到各类预测、优化问题中也是一个不错的选择~
参考文献
[1]Guo Z, Liu G, Jiang F. Chinese Pangolin Optimizer: a novel bio-inspired metaheuristic for solving optimization problems[J]. The Journal of Supercomputing, 2025, 81(4): 517.
完整代码
如果需要免费获得图中的完整测试代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
中华穿山甲
也可点击下方小卡片,再后台回复个人需求(比如CPO-LSTM)定制以下CPO算法优化模型(看到秒回):
1.回归/时序/分类预测类:SVM、RVM、LSSVM、ELM、KELM、HKELM、DELM、RELM、DHKELM、RF、SAE、LSTM、BiLSTM、GRU、BiGRU、PNN、CNN、BP、XGBoost、TCN、BiTCN、ESN、Transformer等等均可~
2.组合预测类:CNN/TCN/BiTCN/DBN/Transformer/Adaboost结合SVM、RVM、ELM、LSTM、BiLSTM、GRU、BiGRU、Attention机制类等均可(可任意搭配非常新颖)~
3.分解类:EMD、EEMD、VMD、REMD、FEEMD、TVFEMD、CEEMDAN、ICEEMDAN、SVMD、FMD等分解模型均可~
4.路径规划类:机器人路径规划、无人机三维路径规划、冷链物流路径优化、VRPTW路径优化等等~
5.优化类:光伏电池参数辨识优化、光伏MPPT控制、储能容量配置优化、微电网优化、PID参数整定优化、无线传感器覆盖优化、故障诊断等等均可~~
6.原创改进优化算法(适合需要创新的同学):原创改进2025年的指数中华穿山甲优化算法CPO以及鱼鹰OOA、蜣螂DBO等任意优化算法均可,保证测试函数效果!

















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









