










声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
很久没给大家带来故障诊断类的作品了。今天,给大家带来一期原创未发表的新颖代码,格拉姆角场+深度学习结合,一键运行即可实现东南大学齿轮箱数据故障诊断,不像其他程序一样需要运行很多次,并且附带详细的注释与使用说明!非常适合新手小白!精度高达99%!
当然,我们提出的这个方法,非常适合用来发文!目前,知网和WOS上都还没人用过!不信的小伙伴可以看下面截图:
知网:
WOS:
你先用,你就是创新!
您只需做的工作:下载压缩包,解压后运行main文件即可出图!
原理详解
此处使用的数据是东南大学官方的齿轮箱数据!首先说一下该数据集的处理步骤以及来源:

1.数据预处理。取官方下载的东南大学齿轮箱数据集,选择以下几个文件:
Chipped_20_0:故障状态为齿轮上有裂纹
Health_20_0:健康状态
Miss_20_0:故障状态为断齿
Root_20_0:故障状态为齿轮根部裂纹
Surface_20_0:故障状态为齿面磨损
提取五个数据的第三列,设置滑动窗口w为1000,每个数据的故障样本点个数s为2048 。将所有的数据滑窗设置完毕之后,将所有的数据和类别综合到一个Excel中(此处Excel已直接整理好,可直接进行后续步骤)。
2.格拉姆角场转换。也就是将一维轴承振动信号通过格拉姆矩阵转化为二维的格拉姆图像,我们先将时间序列映射到极坐标系(半径设置为100),然后基于角度构建出二维矩阵来表示序列之间的相互关系(相加或相减),从而在保留原始数据信息的同时包含了时间相关性。

上图以格拉姆角场差为例,展示了5种不同故障状态的时频图,我们再将图像输入到二维CNN中进行特征提取。
3.故障诊断。按照上述流程处理完数据集后,就是我们常见的机器学习分类数据集了。此处,我们划分70%为训练集,30%为测试集,将数据送入CNN中进行特征提取,再取CNN的全连接层结果作为LSSVM模型的输入,并利用2025年新出的梦境优化算法DOA对LSSVM的参数c和g实现自适应寻优,就能得到故障诊断结果!
创新点
①创新点一:最新优化算法自动参数调优
梦境优化算法(Dream Optimization Algorithm, DOA)于2025年3月发表在SCI一区Top期刊《Computer Methods in Applied Mechanics and Engineering》上!实验结果表明,DOA算法在大部分函数上均取得了最优结果!性能非常不错,解决了LSSVM模型参数难以人工准确设定的问题!之前推文有做过DOA和经典算法SCA的比较,效果显而易见!链接如下:
2025年3月SCI一区新算法-梦境优化算法(DOA)-公式原理详解与性能测评 Matlab代码免费获取
②创新点二:格拉姆角场实现一维信号转二维图像
将原始振动信号通过GAF转换为图像形式,既能保留时间序列的时序特征,又能在图像域内展现局部与全局的相互关联。这种将一维数据映射到二维图像的方式为后续深度网络提取特征提供了可视化和空间结构上的优势。
③创新点三:CNN-LSSVM新颖深度学习分类架构
将CNN作为前端的特征提取器,最后一层的全连接层表征输出送入LSSVM进行最终分类。CNN负责学习故障图像的表示,LSSVM在特征空间中进行判别分类,相比于单一模型可获得更好的鲁棒性与泛化能力。
结果展示
此处采用的CNN-DOA-LSSVM模型,知网上还没人用过,大家也可以自行替换成想要的优化算法!
首先看一下模式识别前后的样本分布情况:
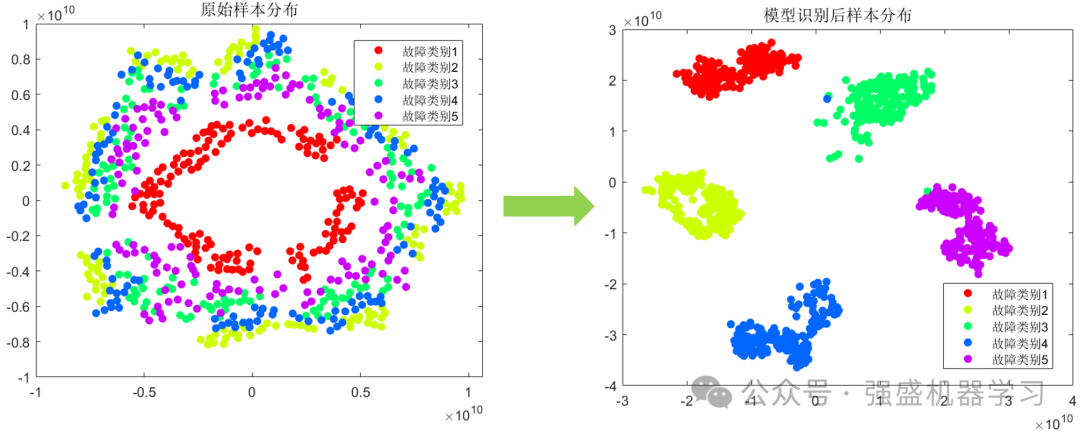
可以看到,模型识别前,故障类别较为无序,无法很好地区分。经过模型识别后,样本分布都集中在了一起,能够很好地区分与辨识!
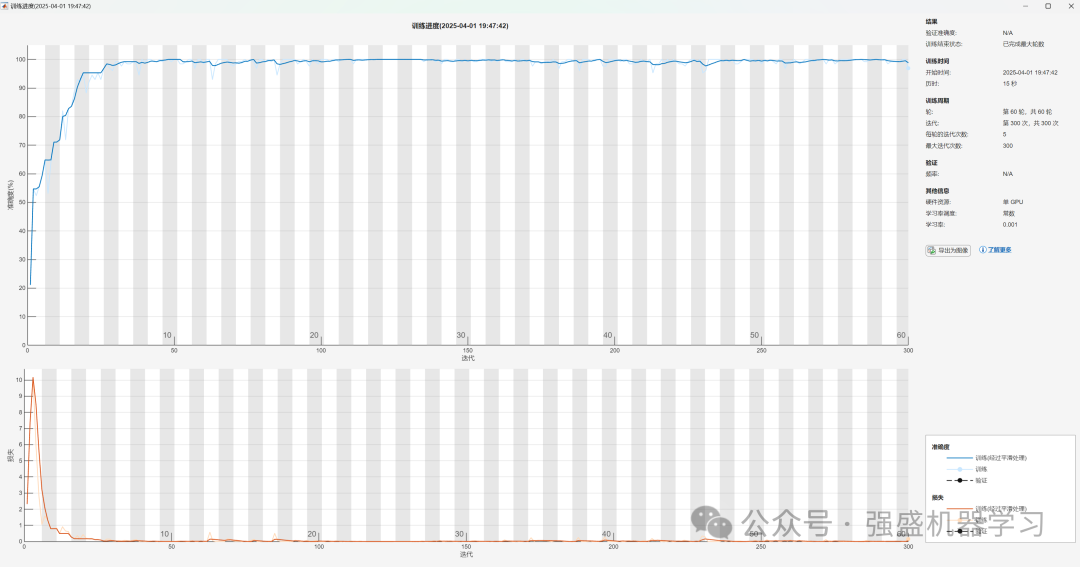
接着是分类效果图,包括训练集与测试集:
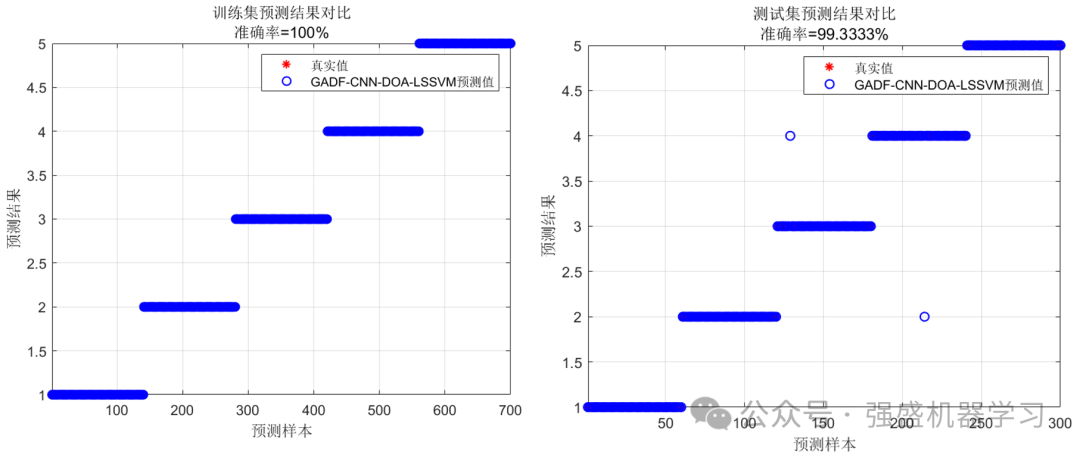
其次是混淆矩阵图,包括训练集与测试集:
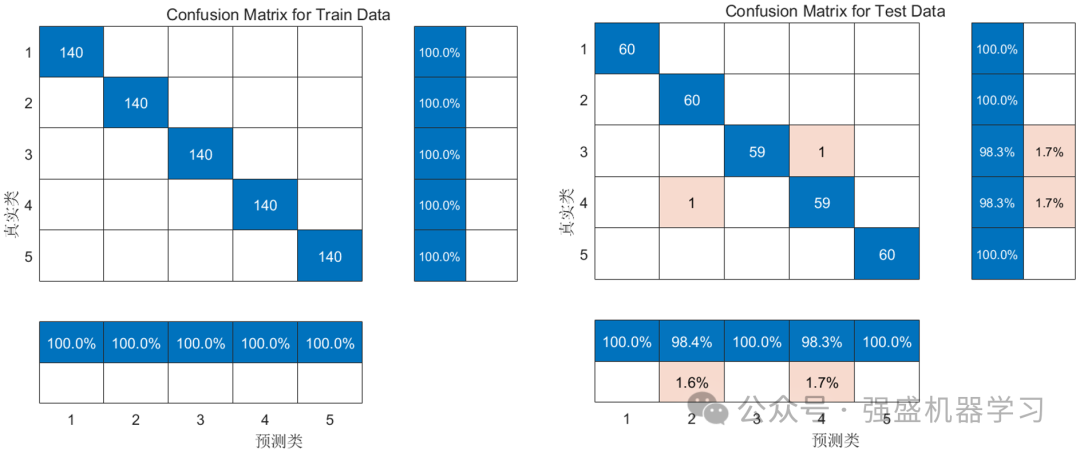
可以看到,经过我们新方法得到的故障诊断准确率结果相当之高,测试集预测结果在99%以上!
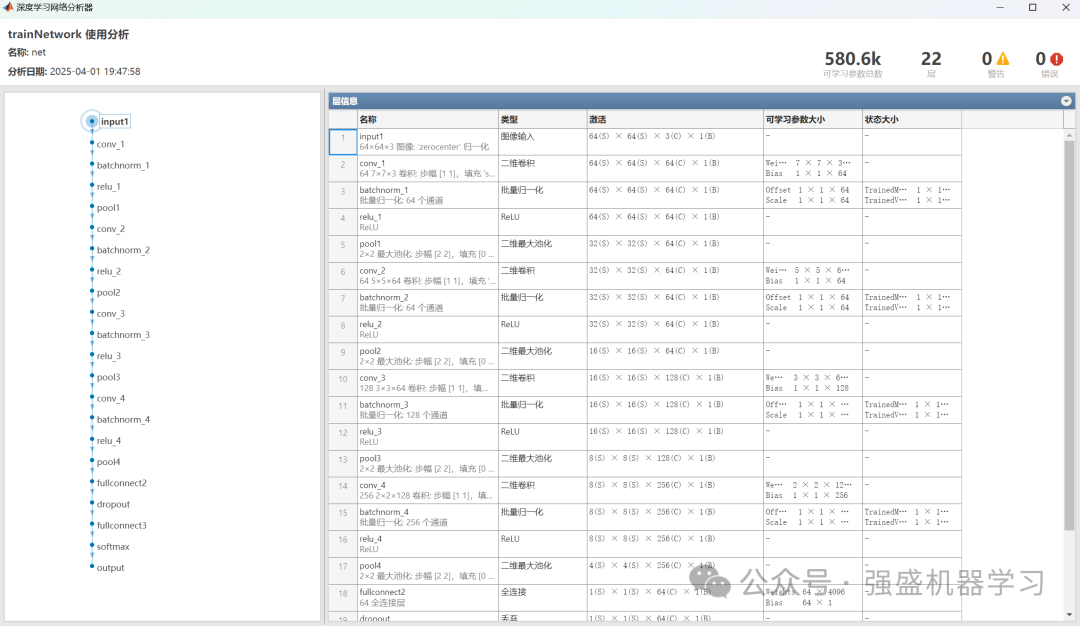
以及CNN网络结构图:
以上所有图片,作者都已精心整理过代码,都可以一键运行main直接出图,不像其他代码一样需要每个文件运行很多次!
不信的话可以看下面文件夹截图,非常清晰明了,并且有使用说明!
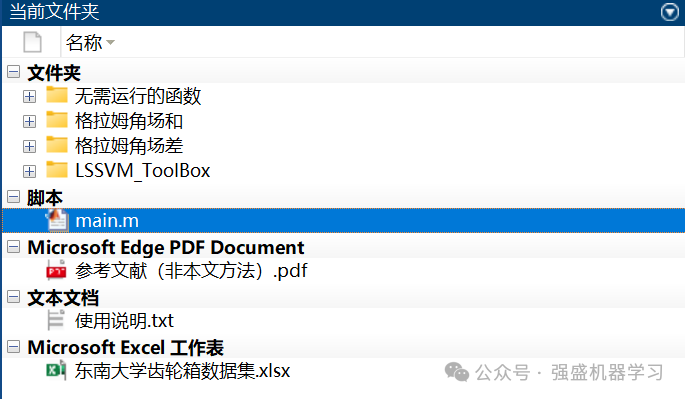
其中,刚刚讲到的数据预处理部分已帮大家整理成Excel格式,特征提取部分已单独放到了txt文件中可自行下载。并且,我们也给了一键运行与节约时间两种版本,方便大家自行选择喜欢的版本!

部分代码展示
%% 导入图像数据与标签
input = resizeimg(:,1); % 第 1 列:图像数据
output = resizeimg(:,2); % 第 2 列:对应标签
%% 分析数据
res = resizeimg';
num_res = size(res, 1); % 样本数(每一行,是一个样本)
res = res(randperm(num_res), :); % 打乱数据集(不打乱数据时,注释该行)
num_size = 0.7; % 训练集占数据集的比例
allLabels = cell2mat(res(:, 2));
uniqueLabel = unique(allLabels);
num_class = length(uniqueLabel); % 类别数
%% 设置变量存储数据
P_train = {}; T_train = {};
P_test = {}; T_test = {};
%% 划分数据集
for i = 1 : num_class
currentClass = uniqueLabel(i); % 找到第 i 类样本所在行
idx_this = find(allLabels == currentClass);
mid_res = res(idx_this, :); % 该类所有样本
mid_size = size(mid_res, 1); % 该类的样本数
mid_tiran = round(num_size * mid_size); % 训练集样本数
% 前 mid_tiran 行用于训练,其余用于测试
P_train = [P_train; mid_res(1 : mid_tiran, 1)]; % 图像
T_train = [T_train; mid_res(1 : mid_tiran, 2)]; % 标签
P_test = [P_test; mid_res(mid_tiran+1 : end, 1)];
T_test = [T_test; mid_res(mid_tiran+1 : end, 2)];
end
%% 整合 4D 图像数组 + categorical 标签
M = size(P_train, 1); % 训练集样本数
N = size(P_test, 1); % 测试集样本数
imgExample = P_train{1};
[H, W, C] = size(imgExample);完整代码获取
如果需要以上完整代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
GZZDE

















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









