







目录
3.1. Lane and anchor representation
3.8. Anchor fifiltering for speed effificiency
1.Introduction
作者提出了一个实时、高性能的车道线检测算法,将其命名为LaneATT。
该方法基于anchor实现,且应用了注意力机制,轻量级版本的推理速度达到250FPS 全局信息可能对推断其位置至关重要,特别是在遮挡、缺失车道标记等情况下。因此,这项工作提出了一种新的基于锚定的注意机制来聚合全局信息

2. Related work
Segmentation-based methods.
Row-wise classifification methods.
前人不足:牺牲精度换取速度,还有的代码不公开
我们提出了一种比现有的最先进的方法更快、更准确的方法。此外还公布完整代码
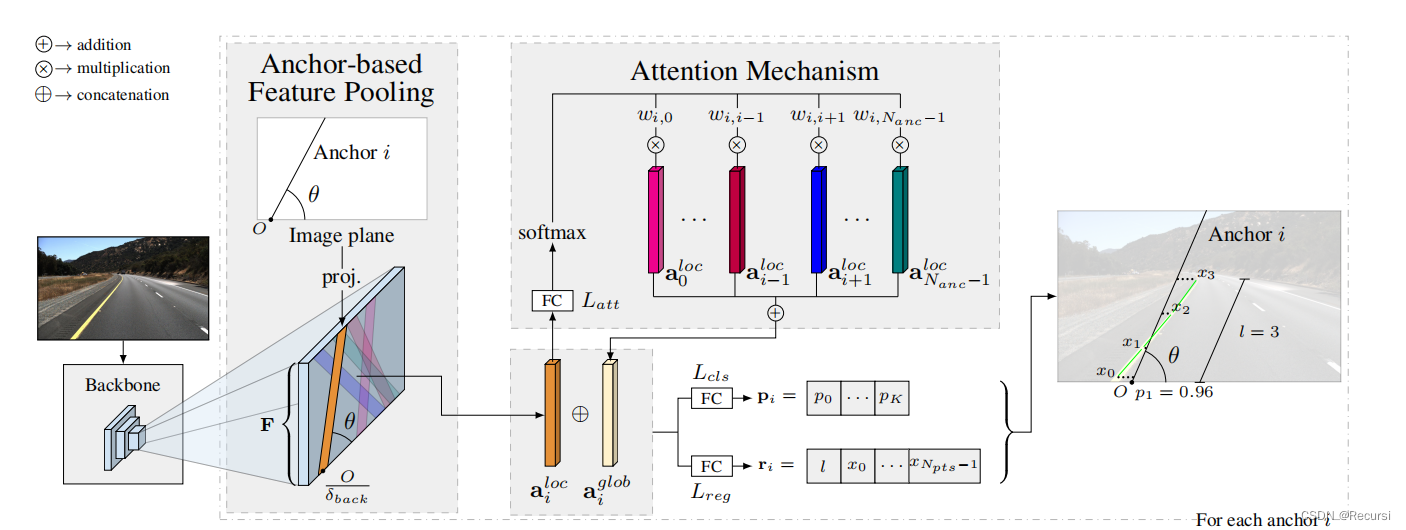
3. Proposed method
LaneATT:单阶段的model
从上图中可以看出,该算法将backbone的输出结果进行池化操作,以提取每个anchor的特征;将提取到的特征与注意力模块产生的全局特征进行融合,以解决遮挡、光照等原因导致车道线检测不到的问题;融合后的特征
作为全连接层的输入,全连接层输出车道线的置信度和相关参数。
3.1. Lane and anchor representation
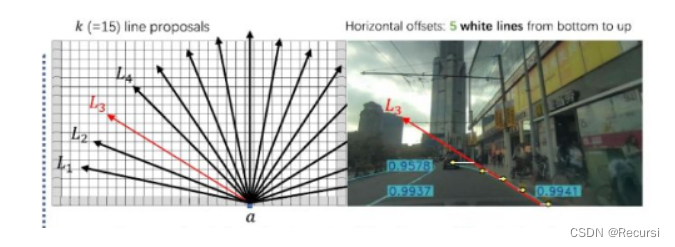
Lane的anchor表征方式与Line-CNN的方式一致。如上图所示,首先将特征图均分为一定大小的网格。然后,一条lane由起始点s和结束点e,以及方向a组成。也就是一条lane由起始点按照一定方向到结束点的所有2d坐标组成。
![]()


3.2. Backbone


式子中,x_orig,y_orig是起始点的坐标,θ 、是线的角度方向。这个公式的意思也比较好理解,就是按照网格y坐标找出line上的对应x坐标,这样就可以
挑出固定长度的特征出来,长度为特征图F的高度。如果出现了y对应的x点坐标在特征图外,就采用0 padding的方式补齐。
3.4. Attention mechanism

然后,将这些权重与局部特征相乘后相加,以产生相同维数的全局特征向量:
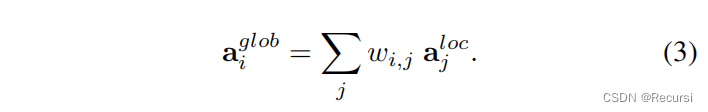
3.5. Proposal prediction



3.7. Model training

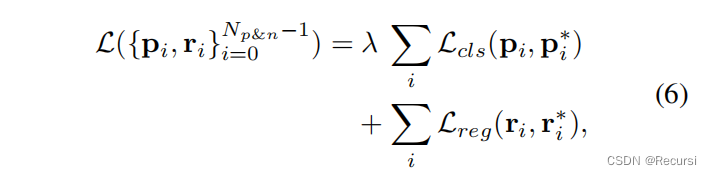

x坐标的共同指标(s‘和e’之间)的选择方式与车道距离(方程(5))相似,但使用e‘=egt而不是e’=min(eprop,egt),其中eprop和egt分别是建议及其相关的地面真相的最终指标。如果使用建议的
eprop中预测的结束索引,训练可能会通过收敛到退化解而变得不稳定(例如,eprop可能收敛到零)。
3.8. Anchor fifiltering for speed effificiency

4. Experiments
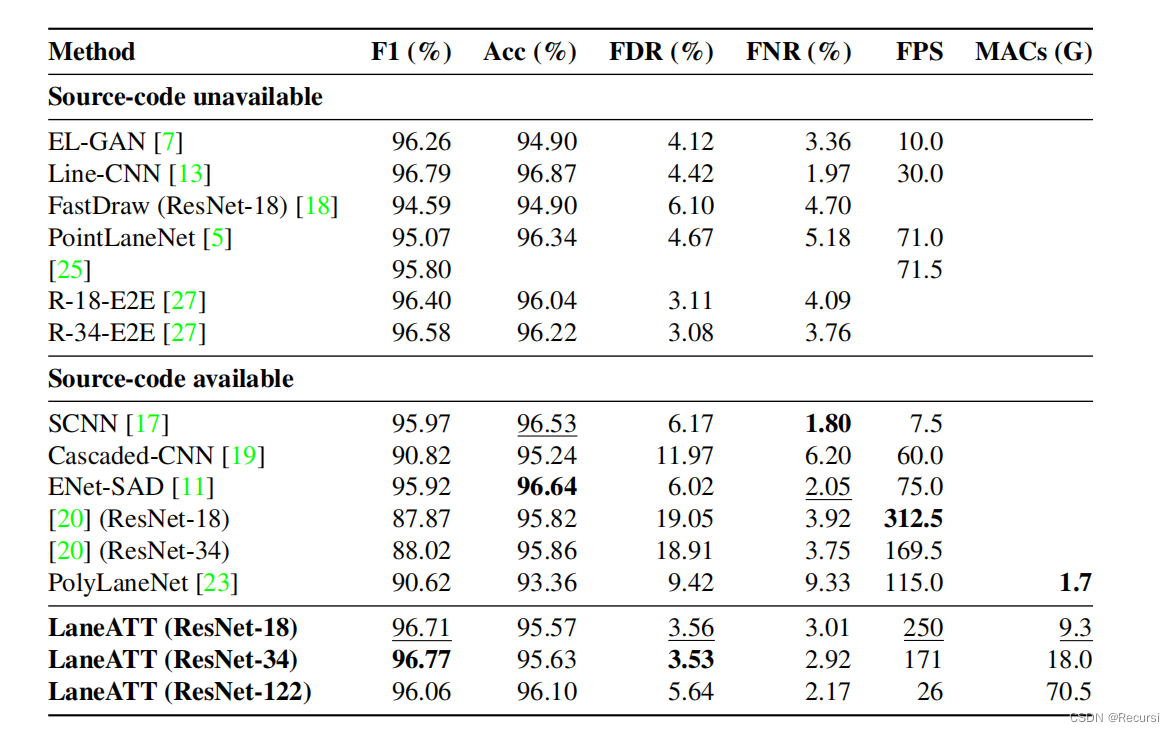
在[20]中提出的方法是唯一能与我们的速度相媲美的方法。由于FDR和FNR的指标在他们的工作中没有被报告,所以我们使用已发布的代码来计算它们,并报告了这些指标。虽然他们达到了很高的准确性,但FDR明显地很
高。例如,我们最高的FDR是5.64%(ResNet-122),而最低的是18.91%,几乎是它的4倍。
4.2. CULane
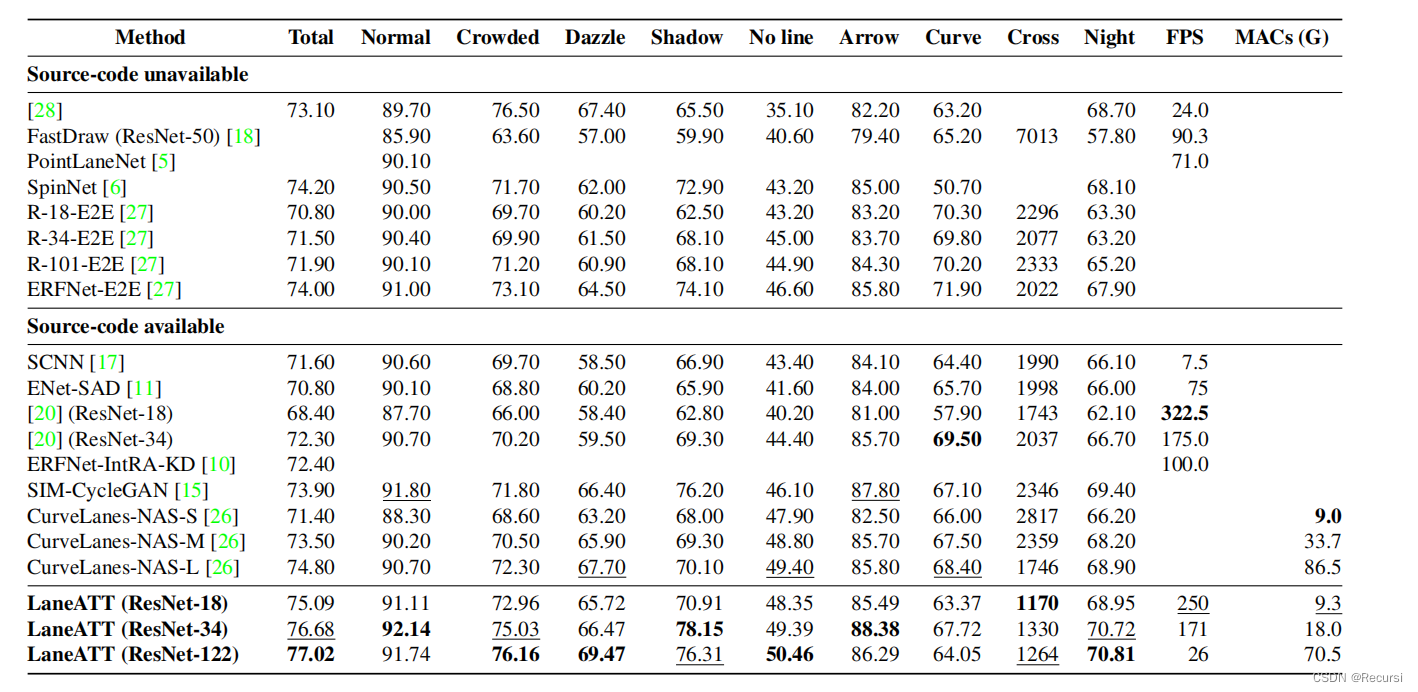
与[20]相比,我们最轻量级的型号(ResNet-18)比它们最大的(ResNet-34)多出F1的3%,同时要快得多(在同一台机器上250vs175FPS)
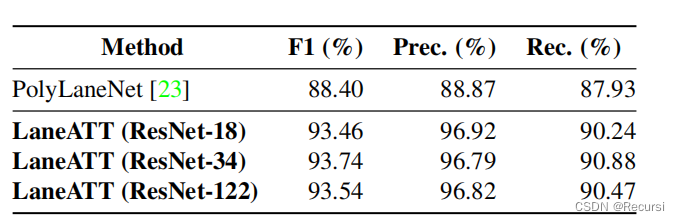
4.3. LLAMAS
4.4. Effificiency trade-offs
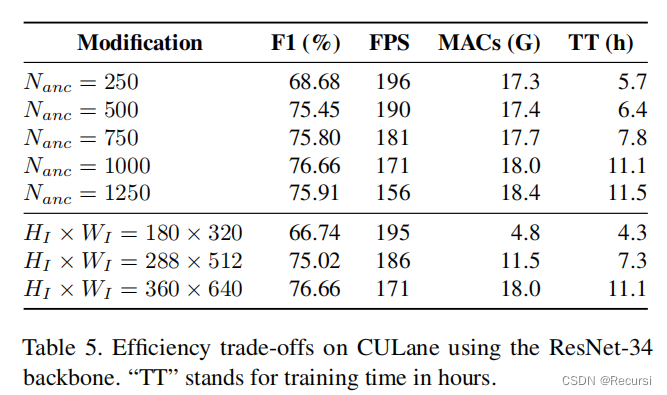
锚的数量可以减少为一个轻微的提高的效率,而没有一个大的F1下降。然而,如果减少的幅度太大,F1就会开始大幅下降。此外,如果使用了太多的锚,效果也会降低,这可能是不必要的锚干扰训练的结果。输入大小的结果相似,尽管mac下降幅度更大。锚的数量和输入大小的最大影响是对训练时间。
4.5. Ablation study
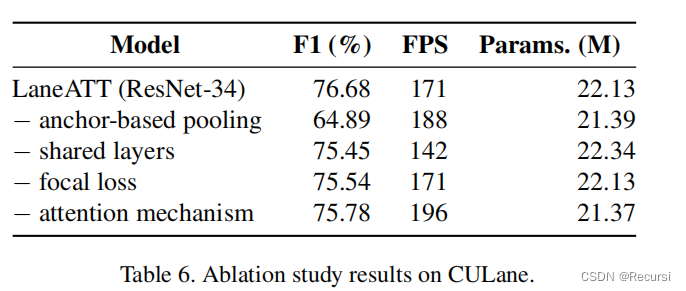
第一行包含了标准LaneATT的结果,而下面的行显示了略微修改的版本的结果。
在第二行中,删除基于锚的pooling,使用选择Line-CNN[13]特征的相同过程(即每个锚只使用特征图中单个点的特征)。
在第三种方法中,不是使用一对全连接层(Lreg和Lcls)进行最终预测,而是使用了三对(六层),每个边界使用一对(左、下或右)。
第四个是用交叉熵代替焦点损失,最后一个是去除注意机制。
当删除基于锚点的池化过程时,性能的大量下降显示了它的重要性。














 2156
2156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









