








论文网址:Biologically Plausible Brain Graph Transformer
英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
目录
2.4. Biologically Plausible Brain Graph Transformer
2.4.1. Network Entanglement-based Node Importance Encoding
2.4.2. Functional Module-Aware Self-Attention
2.5.4. Comparative Analysis of Node Importance Measurement
2.5.5. Biological Plausibility Analysis
1. 心得
(1)慎看,感觉很物理,需要一定基础,什么量子纠缠。我不是很懂纠缠
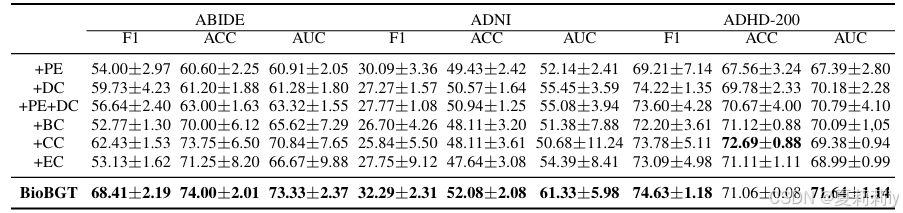
(2)(题外话)我将diss所有沙壁审稿人,我论文和这篇ICLR2025效果几乎一模一样(对比模型一样数据集一样结果一样),审稿人说我“你的模型二分类才70多太糟糕了”/“几乎没有提升”/“性能平平”,对我复现的论文,从这篇可以看到BrainGNN在ABIDE上就是五十多,GAT也是。审稿人说我“故意压低基线”/“和原论文极大不符,疑似学术造假~”/“怀疑结果真实性”。先四格🐎吗审稿人宝宝们?已读不回是审稿人宝宝们论文都被拒了是吧~
(3)先放表。能不能告诉全世界ABIDE数据集在2025年就是这个β样子:
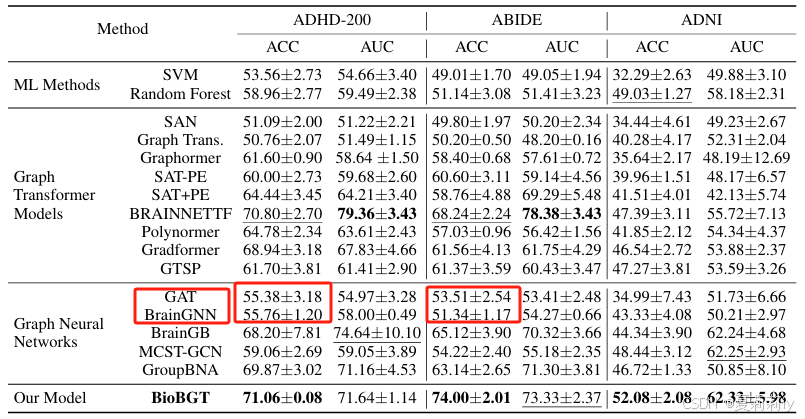
(4)文尾有drama事件。BNT惨遭无辜炮轰。
2. 论文逐段精读
2.1. Abstract
①Existing works fail to represent brain framework
2.2. Introduction
①(a) Hub and functional modules, and (b) functional connectivity (FC) in different brain regions of ADHD:
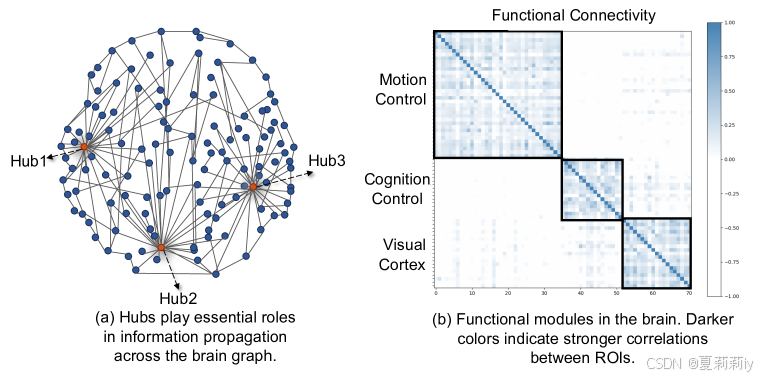
2.3. Preliminaries
2.3.1. Problem Definition
①Graph: , with node set
, dege set
, feature matrix
, and
ROIs (nodes)
2.3.2. Graph Transformers
①Transformer block: an attention module and a feed-forward network (FFN)
②Attention mechanism with :
where denotes similarity between queries and keys
③Output of attention blocks:
2.4. Biologically Plausible Brain Graph Transformer
①Rewrite to:
(FM后面是短横线,不是减号)where denotes a network entanglement-based node importance encoding method
②Overall framework of BioBGT:

2.4.1. Network Entanglement-based Node Importance Encoding
①Normalized information diffusion propagator:
where denotes information diffusion propagator,
denotes positive parameter,
is Laplacian matrix,
is the partition function
②von Neumann entropy, to capture global topology and information diffusion process of graphs:
where is the density matrix-based spectral entropy,
denotes the trace operation computing the trace of the product of the density matrix
and its natural logarithm
③Node importance (node entanglement value (VE value)):
where is the
-control graph obtained after the perturbation of node
④To approximate NE value:
where and
is node number and edge number respectively,
⑤Node representation:
where denotes learnable embedding vector specified by
2.4.2. Functional Module-Aware Self-Attention
(1)Community Contrastive Strategy-based Functional Module Extractor
①Updating by
, where
denotes functional module extractor and
is functional module node
belongs to
②Augment graph to
and
by edge drop
③Employing contrastive learning by regarding nodes in the same functional module as positive sample and in the different functional module as negative. They use InfoNCE loss:
where node features are represented as in graph
(2)Updated Self-Attention Mechanism
①Attention module with exponential kernels:
where denotes non-negative kernel,
is dot product,
is linear value function
②Functional module-aware self-attention bound:
where and
are representations of nodes
and
after the functional module extractor
2.5. Experiments
2.5.1. Experimental Setup
(1)ABIDE Dataset
①Subjects: 1009 with 516 ASD and 493 NC
②Brain atlas: Craddock 200
(2)ADNI Dataset
①Subjects: 407 with 190 NC, 170 MCI and 47 AD
②Brain atlas: AAL 90
(3)ADHD-200
①Subjects: 459 with 230 NC and 229 ADHD
②Brain atlas: CC200(但作者在这只用了190个?)
(4)Setting
①Brian graph construction: Pearson correlation
②Threshold applied
③Optimizer: AdamW
④Loss: BCE loss
⑤Data split: 0.8/0.1/0.1
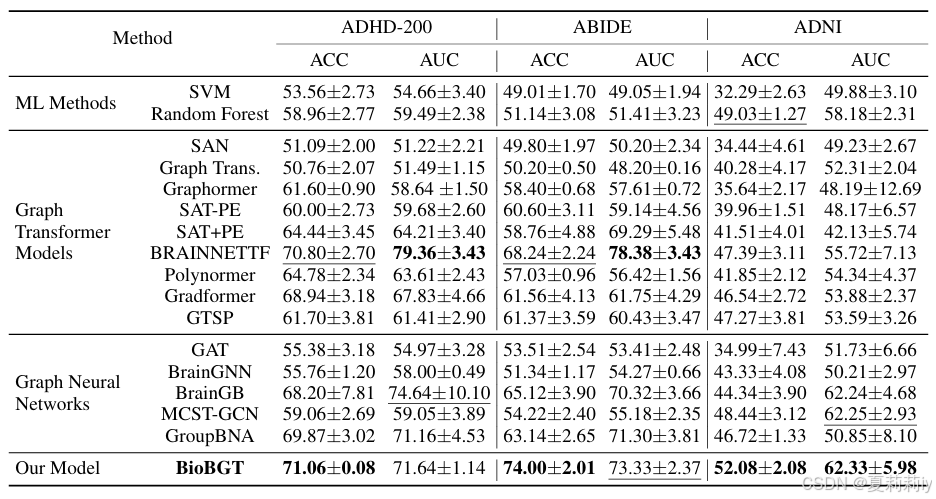
2.5.2. Results
①Performance:
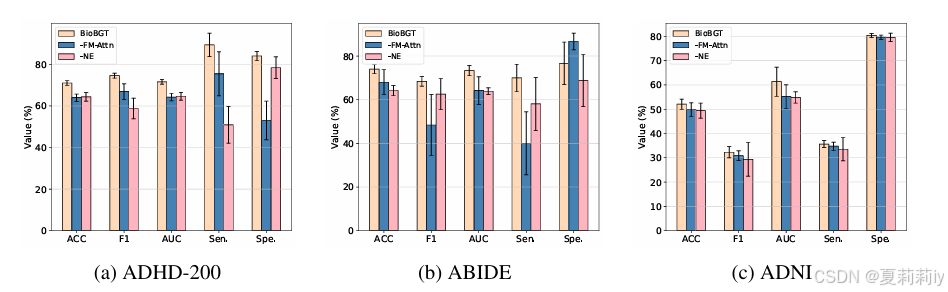
2.5.3. Ablation Studies
①Module ablation:
2.5.4. Comparative Analysis of Node Importance Measurement
①Encoder ablation:
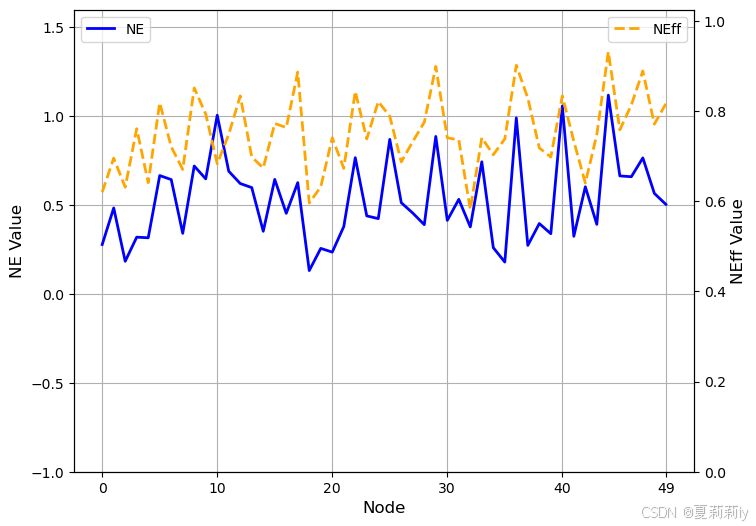
2.5.5. Biological Plausibility Analysis
①The NE and NEff values of 50 randomly selected nodes from a sample in the ABIDE dataset:
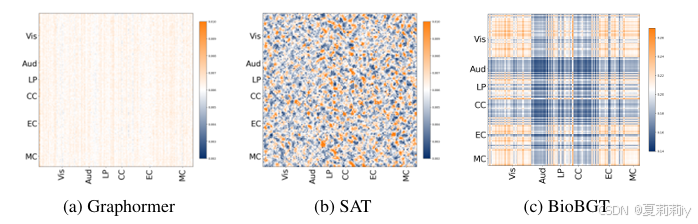
②The heatmaps of the average self-attention scores:
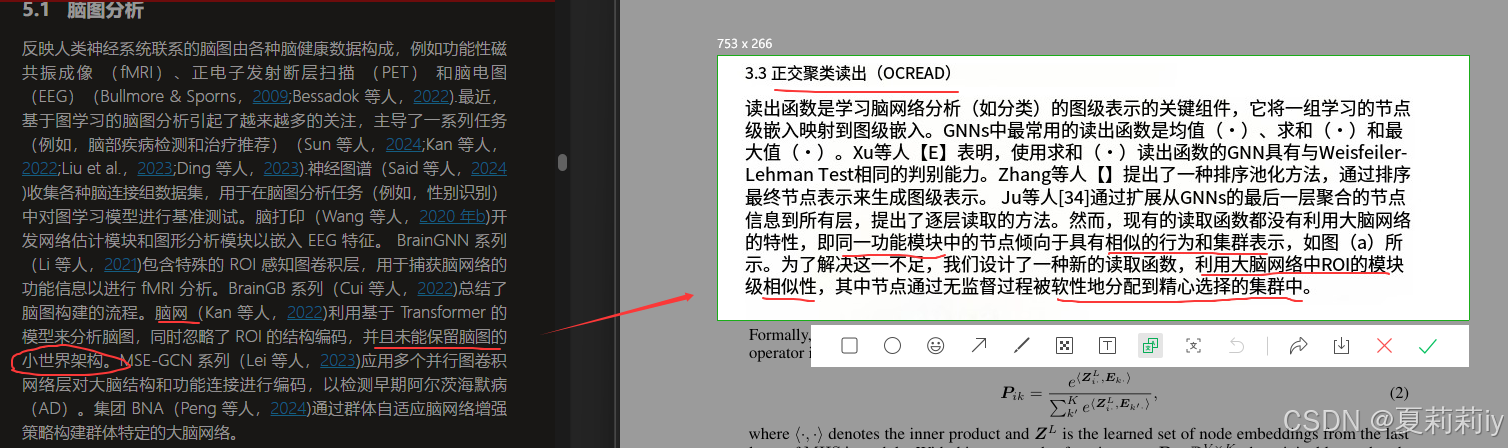
2.6. Related Work
2.6.1. Brain Graph Analysis
①虽然我不厨Kan Xuan,也不推BrainNetworkTransformer,但BioBGT说:
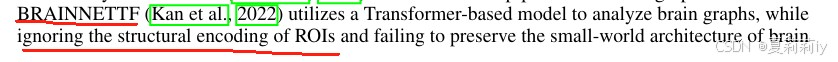
无辜的BNT独自承担了一切。BNT原文:



②我很难得看一下相关工作,不要一看就很...(方便起见放中文了,左边BioBGT右边BNT。BNT人家也有在认真聚类好吧。虽然没有觉得BNT牛到哪里去但是给了代码+效果是真的不错所以嘎嘎点赞啊)
2.6.2. Graph Transformers
①介绍了一些相关的
2.7. Conclusion
~

















 1608
1608

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









