







A. 对极几何与三角测量
对极几何主要采用特征点法,如SIFT、SURF和ORB等获取两帧图像对应的特征点。如图1所示,设第一幅图像为![]() 第二幅图像为
第二幅图像为![]() 。
。

图1 对极几何与三角测量示意图
三维空间中的一点![]() 在两幅不同视角图像下的投影分别为
在两幅不同视角图像下的投影分别为![]() ,
,![]() 。以相机开机时拍摄第一帧图像时的相机坐标系预定义为世界坐标系,则两幅图像的投影方程式分别为:
。以相机开机时拍摄第一帧图像时的相机坐标系预定义为世界坐标系,则两幅图像的投影方程式分别为:
![]() (1)
(1)
![]() (2)
(2)
由于在三维空间中的场景在投影到图像平面的过程中丢掉了深度这一维度,单靠一幅图像无法得到深度信息,因此采用归一化平面进行计算。归一化平面是将所有深度进行归一化的平面,可以看作相机成像平面前方深度为1的平面,两幅图像归一化平面的坐标为![]() ,
,![]() 。归一化平面与像素坐标之间的变换关系为:
。归一化平面与像素坐标之间的变换关系为:
![]() (3)
(3)
![]() (4)
(4)
将式(1)至式(3)进行整合,得:
![]() (5)
(5)
在上式的基础上两边同时左乘平移矩阵![]() 的反对称矩阵,可以得到:
的反对称矩阵,可以得到:
![]() (6)
(6)
在上式的基础上两边左乘![]() ,可以得到:
,可以得到:
![]() (7)
(7)
设![]() (E称为本质矩阵),则有:
(E称为本质矩阵),则有:
0 ![]() (8)
(8)
其中![]() ,
,![]() 。其展开形式为:
。其展开形式为:
 (9)
(9)
由此可知,通过8对特征点,可以计算出![]() 。通过矩阵分解,可以得出旋转与平移矩阵。
。通过矩阵分解,可以得出旋转与平移矩阵。
有了旋转平移矩阵之后,可以进一步利用式(1)与(2)得到三维空间点![]() 在不同图像视角下的深度,该过程称为三角测量。
在不同图像视角下的深度,该过程称为三角测量。
B. 直接法
如图2所示,三维空间中存在任意一个点![]() 以及与之相关的两个不同时刻不同视角下的相机。
以及与之相关的两个不同时刻不同视角下的相机。![]() 在世界坐标系下的坐标为
在世界坐标系下的坐标为![]() 。点
。点![]() 投影到两个不同时刻相机下的像素坐标为
投影到两个不同时刻相机下的像素坐标为![]() 、
、![]() ,这里的
,这里的![]() 、
、![]() 为非齐次坐标的形式,目的是求解两个不同时刻相机的相对变换,也就是旋转和平移。以第一个相机的相机坐标系作为参考,假设两个不同时刻下的相机的变换矩阵为
为非齐次坐标的形式,目的是求解两个不同时刻相机的相对变换,也就是旋转和平移。以第一个相机的相机坐标系作为参考,假设两个不同时刻下的相机的变换矩阵为![]() ,其李代数的形式为
,其李代数的形式为![]() 。两个不同时刻的相机为同一相机,具有相同的内参
。两个不同时刻的相机为同一相机,具有相同的内参![]() 。
。

图2 直接法示意图
完整的投影方程为:
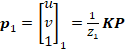 (10)
(10)
 (11)
(11)
其中![]() 是三维点
是三维点![]() 的深度,
的深度,![]() 是三维点
是三维点![]() 在第二个相机坐标系下的深度,也就是
在第二个相机坐标系下的深度,也就是![]() 的第三个坐标值。由于
的第三个坐标值。由于![]() 只能和齐次坐标相乘,所以要取出前三个元素。
只能和齐次坐标相乘,所以要取出前三个元素。
直接法由于没有特征匹配,无从知道哪一个![]() 与
与![]() 对应于同一个点。直接法的思路是根据当前相机的位姿估计值,来寻找
对应于同一个点。直接法的思路是根据当前相机的位姿估计值,来寻找![]() 的位置。但若相机位姿不够好,
的位置。但若相机位姿不够好,![]() 的外观和
的外观和![]() 会有明显差别。于是,为了减小这个差别,优化相机的位姿,来寻找与
会有明显差别。于是,为了减小这个差别,优化相机的位姿,来寻找与![]() 更相似的
更相似的![]() 。通过解光度误差这个优化问题进行计算,其形式为:
。通过解光度误差这个优化问题进行计算,其形式为:
![]() (12)
(12)
其中![]() 是一个标量,优化目标为该误差的二范数:
是一个标量,优化目标为该误差的二范数:
![]() (13)
(13)
直接法假设一个空间点在各个视角下,成像的灰度是不变的。如果有N个空间点![]() ,那么,整个相机位姿估计问题变为:
,那么,整个相机位姿估计问题变为:
![]() ,
,![]() (14)
(14)
其中需要优化的变量是相机位姿![]() ,需要通过分析它们的导数关系来求解这个优化问题。因此,使用李代数上的扰动模型。给
,需要通过分析它们的导数关系来求解这个优化问题。因此,使用李代数上的扰动模型。给![]() 左乘一个小扰动
左乘一个小扰动![]() ,得:
,得:
 (15)
(15)
简写为![]() 或
或![]() 。
。
这里的![]() 为
为![]() 在扰动之后,位于第二个相机坐标系下的坐标,而
在扰动之后,位于第二个相机坐标系下的坐标,而![]() 为它的像素坐标。利用一阶泰勒展开,有:
为它的像素坐标。利用一阶泰勒展开,有:
 (16)
(16)
通过式(16)可知,一阶导数由于链式法则分成了三项,而这三项可分别计算。
在上面的推导中,![]() 是一个已知位置的空间点。在RGB-D相机下,可以把任意像素反投影到三维空间,然后投影到下一个图像中。如果在单目相机中,需考虑由
是一个已知位置的空间点。在RGB-D相机下,可以把任意像素反投影到三维空间,然后投影到下一个图像中。如果在单目相机中,需考虑由![]() 的深度带来的不确定性。根据
的深度带来的不确定性。根据![]() 的来源,可以把直接法分为三类:1.
的来源,可以把直接法分为三类:1.![]() 来自于稀疏关键点称之为稀疏直接法。通常使用数百个至上千个关键点,假设它周围像素也是不变的。这种稀疏直接法不必计算描述子,并且只使用数百个像素,因此速度最快,但只能计算稀疏的重建。2.
来自于稀疏关键点称之为稀疏直接法。通常使用数百个至上千个关键点,假设它周围像素也是不变的。这种稀疏直接法不必计算描述子,并且只使用数百个像素,因此速度最快,但只能计算稀疏的重建。2.![]() 来自部分像素。可以考虑只使用带有梯度的像素点,舍弃像素梯度不明显的地方,这称之为半稠密的直接法,可以重构一个半稠密结构。3.
来自部分像素。可以考虑只使用带有梯度的像素点,舍弃像素梯度不明显的地方,这称之为半稠密的直接法,可以重构一个半稠密结构。3.![]() 为所有像素,称为稠密直接法。稠密重构需要计算所有像素(一般几十万至几百万个),因此多数不能在现有的CPU上实时计算,需要GPU的加速。从稀疏到稠密的重建,都可以用直接法来计算。它们的计算量是逐渐增长的。稀疏方法可以快速地求解相机位姿,而稠密方法可以建立完整地图。
为所有像素,称为稠密直接法。稠密重构需要计算所有像素(一般几十万至几百万个),因此多数不能在现有的CPU上实时计算,需要GPU的加速。从稀疏到稠密的重建,都可以用直接法来计算。它们的计算量是逐渐增长的。稀疏方法可以快速地求解相机位姿,而稠密方法可以建立完整地图。
C. PnP
图像的投影过程是空间中的三维点与图像中的二维点对应的一个过程,如果这两个点已知,并且知道它们是对应的情况下,可以利用PnP来计算相机位姿。
根据 相机与图像模型 可知,世界坐标系到像素坐标系需要经过相机的外参以及内参。相机的外参就是变换矩阵![]() ,其可以具体表示为
,其可以具体表示为![]() ,其中
,其中![]() 是旋转矩阵,
是旋转矩阵,![]() 是位移向量。定位,也就求解相机在世界坐标系下旋转与平移了多少的问题,即求解
是位移向量。定位,也就求解相机在世界坐标系下旋转与平移了多少的问题,即求解![]() 。世界坐标系使用
。世界坐标系使用![]() 表示,相机坐标系使用Pc
表示,相机坐标系使用Pc![]() 表示,则世界坐标系与相机坐标的变换关系为Pc=Rt×Pw
表示,则世界坐标系与相机坐标的变换关系为Pc=Rt×Pw![]() 。相机归一化平面上的坐标使用X
。相机归一化平面上的坐标使用X![]() 进行表示,相机坐标系到归一化平面需要相机的内参K
进行表示,相机坐标系到归一化平面需要相机的内参K![]() 。则有对应的数学关系:
。则有对应的数学关系:
![]() (17)
(17)
根据式(17),归一化平面上的坐标![]() 已知,通过求解线性方程组得到
已知,通过求解线性方程组得到![]() 的初值,再利用非线性最小二乘法迭代求得最优变换矩阵
的初值,再利用非线性最小二乘法迭代求得最优变换矩阵![]() 。具体形式为,考虑某个三维空间点
。具体形式为,考虑某个三维空间点![]() ,其齐次坐标为
,其齐次坐标为![]() 。点
。点![]() 对应的归一化平面齐次坐标的点
对应的归一化平面齐次坐标的点![]() 。相机的位姿是未知的。定义增广矩阵
。相机的位姿是未知的。定义增广矩阵![]() 为一个3×4的矩阵,包含了旋转与平移信息。它的展开形式列写如下:
为一个3×4的矩阵,包含了旋转与平移信息。它的展开形式列写如下:
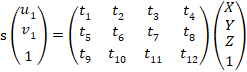 (18)
(18)
利用来自激光雷达或RGB-D相机的深度图可以获得标记点的尺度信息![]() ,标记点世界坐标
,标记点世界坐标![]() 已知,与其对应的归一化平面上的点
已知,与其对应的归一化平面上的点![]() 已知。
已知。![]() 为3×4矩阵,共有12维,因此通过六对匹配点,来实现变换矩阵
为3×4矩阵,共有12维,因此通过六对匹配点,来实现变换矩阵![]() 的线性求解。当匹配点大于六对时,使用奇异值分解的方法对超定方程求最小二乘解。
的线性求解。当匹配点大于六对时,使用奇异值分解的方法对超定方程求最小二乘解。
D. 三维建图
在已知图像的位姿以及图像的深度之后,可以将图像中的像素还原到空间坐标系中。如果有一系列的图像,将每幅图像中的像素反投影到三维空间中就可以进行三维重建。由于在投影的模型中,图像的深度信息起到决定作用,因此三维重建的分辨率取决于图像深度的分辨率。因此,根据图像深度的稠密程度,可以分为稀疏三维重建、半稠密三维重建以及稠密三维重建。如图3所示,稀疏三维重建只能重建图像中的一些关键点,半稠密重建可以重建大部分的信息,稠密重建可以恢复出稠密的三维场景。

图3 重建结果意图[19]
对极几何以及三角测量只能得到图像中的稀疏点,因此只能用于稀疏三维重建。PnP主要是针对RGB-D相机的一种定位方法,因此通过RGB-D相机采集的稠密深度值可以进行稠密三维重建。直接法通常可以得到半稠密的图像深度,因此多用来做半稠密三维重建。三维重建的表示形式有多种形式,其中以点云、网格以及面元等形式的重建居多,其形式如图4所示。

图4 三维重建的不同形式















 235
235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









