






YOLOv6:面向工业应用的单阶段目标检测框架
崔易李* 李露露* 江洪亮* 翁开恒* 耿亦飞* 李良*
Zaidan Ke∗ 清源李∗ Cheng Meng∗ Weiqiang Nie∗ Yiduo Li∗ Bo Zhang∗
芦飞良 纪园园 薛晓明 †储祥湘 徐晓明 魏小琳
美团公司
{lichuyi, lilulu05, jianghongliang02, wengkaiheng, gengyifei,liliang58, kezaidan, liqingyuan02, ChengMeng05, nieweiqiang, liyiduo, zhangbo97, liangyufei, zhoulinyuan, xuxiaoming04, chuxiangxiang, weixiaowing, weixiaolin02} @ meituan.com
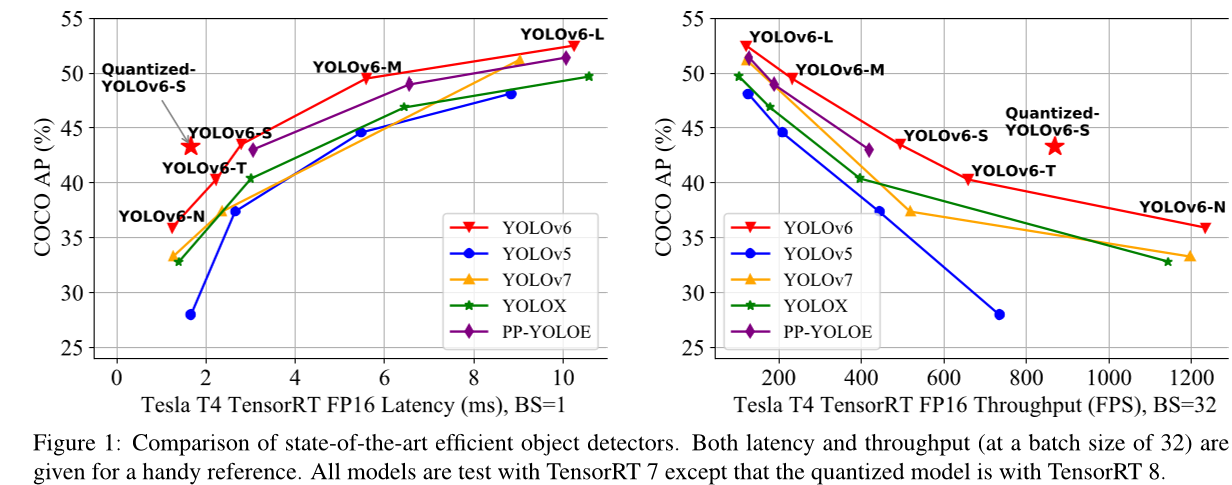
图 1:最先进的高效目标检测器的比较。为了方便参考,给出了延迟和吞吐量(批大小为 32)。所有模型都使用 TensorRT 7 进行测试,除了量化模型使用 TensorRT 8。
摘要
多年来,YOLO 系列一直是行业级高效目标检测的事实标准。YOLO 社区蓬勃发展,在众多硬件平台和丰富场景中丰富其应用。在本技术报告中,我们努力将其推向下一个水平,并以坚定的心态推动其在工业中的应用。考虑到现实环境中速度和准确性的多样化要求,我们广泛审查了来自工业界或学术界的最新物体检测进展。具体而言,我们大量吸收了最近网络设计、训练策略、测试技术和量化与优化方法的思想。除此之外,我们将我们的想法和实践结合在一起,构建了一个部署套件-
我们设计了不同规模的网络来适应各种用例。在YOLO作者的慷慨许可下,我们将其命名为YOLOv6。我们也热烈欢迎用户和贡献者对其进行进一步增强。作为性能的一个快照,我们的 YOLOv6-N 在 Nvidia Tesla T4 GPU 上以 1234 FPS 的速度在 COCO 数据集上达到了 35.9% 的 mAP。YOLOv6-S 在 495 FPS 时达到 43.5% 的 mAP,超过了同一规模的其他主流检测器(YOLOv5-S、YOLOX-S 和 PPYOLO-E-S)。我们的量化版本 YOLOv6-S 甚至带来了新的最先进的 43.3% mAP,在 869 FPS 时。此外,YOLOv6-M/L 在与其他具有相似推理速度的检测器相比具有更好的准确性(即,49.5%/ 52.3%)。我们仔细地进行了实验以验证每个组件的有效性。代码已在 https://github.com/meituan/YOLOv6 上发布。
1. 介绍
YOLO 系列是在工业应用中使用最广泛的检测框架,因为它在速度和准确率之间取得了很好的平衡。YOLO 系列的开创性工作是 YOLOv1-v3 [32–34],它们为后续的重大改进开辟了一条新的单阶段检测器的道路。YOLOv4[1] 重新组织了检测框架的各个部分(backbone、neck 和 head),并在设计适合在单个 GPU 上训练的框架时验证了 bag-of-freebies 和 bag-of-specials。目前,YOLOv5[10]、YOLOX[7]、PPYOLOv4[44] 和 YOLOv7[42] 都是部署高效检测器的竞争候选者。通常通过缩放技术获得不同大小的模型。
在这篇论文中,我们观察到几个重要的因素,这些因素驱使我们重新设计YOLO框架:(1) RepVGG [3] 中的参数重设是一种优越的技术,目前在检测领域尚未得到充分利用。我们还注意到,对RepVGG块进行简单的模型缩放变得不切实际,我们认为没有必要保持小网络和大网络之间优雅的一致性设计。对于小网络来说,简单的单路径架构是一个更好的选择,但对于较大的模型,单路径架构的指数增长会导致参数数量和计算成本过高;(2) 基于参数重设的检测器的定标也需要仔细处理,否则无法解决训练和推断期间由异构配置引起的性能下降问题。(3) 以前的工作[7, 10, 42, 44]往往不太关注部署,通常是在像V100这样的高成本机器上比较延迟。当涉及到真实的-serving环境时,存在硬件差距。通常,低功耗GPU如Tesla T4成本较低且具有相当不错的推理性能。(4) 高级领域特定策略(如标签分配和损失函数设计)需要进一步验证考虑到体系结构的差异。(5) 对于部署,我们可以容忍提高准确率但不增加推断成本的训练策略的调整,例如知识蒸馏。
在上述观察的基础上,我们带来了YOLOv6 的诞生,它目前在准确性和速度方面取得了最佳平衡。我们在图 1 中展示了与规模相似的其他同类比较。为了提高推理速度而不会降低太多性能,我们研究了最先进的量化方法,包括后训练量化 (PTQ) 和有意识的训练量化 (QAT),并将它们纳入YOLOv6以实现部署就绪网络的目标。
我们总结YOLOv6的主要方面如下:
我们定制了针对不同场景的工业应用的不同大小的网络线。不同的规模架构有所不同,以实现最佳的速度和准确性的权衡,其中小模型具有简单的单路径主干,而大型模型则基于有效的多分支块构建。
我们在分类任务和回归任务中都使用了自蒸馏策略来增强YOLOv6。与此同时,我们动态地调整来自老师的先验知识和标签,以帮助学生模型在所有训练阶段更有效地学习知识。
• 我们广泛验证了标签分配、损失函数和数据增强技术的高级检测方法,并选择性地采用它们来进一步提高性能。
我们借助 RepOptimizer [2] 和通道级蒸馏[36] 改进了检测器的量化方案,使其达到 43.3% 的 COCO AP 和在批大小为 32 时达到 869 FPS。
2. 方法
YOLOv6 的改进设计包括如下组件:网络设计、标签分配、损失函数、数据增强、行业便捷性改进以及量化与部署:
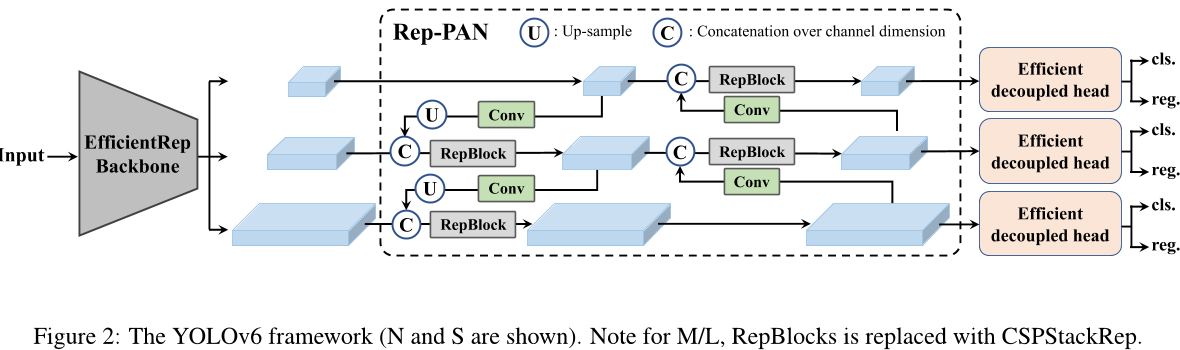
• 网络设计:骨干网络:与其它主流架构相比,我们发现 RepVGG [3] 骨干网络在小网络中具有更强的特征表示能力,但其推理速度与其他方法相当。然而,由于参数和计算成本的急剧增加,它几乎无法扩展以获得更大的模型。在这方面,我们将 RepBlock [3] 作为我们的小网络的基础块。对于大模型,我们修改了更高效的 CSP [43] 块,称为 CSPStackRep Block。脖子:YOLOv6 的脖子采用了 YOLOv4 和 YOLOv5 后采用的 PAN 架构[24]。我们通过 RepBlocks 或 CSPStackRep Blocks 来增强脖子,使其成为 RepPAN。头部:我们简化了分离头,使其更高效,称之为 Efficient Decoupled Head。
• 标签分配:我们通过大量实验评估了YOLOv6中标签分配策略的最新进展[5, 7, 18, 48, 51], 结果表明TAL[5] 更有效且更易于训练。
• 损失函数:主流无锚对象检测器的损失函数包含分类损失,
box回归损失和物体损失。对于每种损失,我们系统地与所有可用技术进行实验,并最终选择Varifocal Loss [50] 作为分类损失和SIoU [8] / GIoU [35] 损失作为回归损失。
• 行业便捷的改进:我们引入了额外的常见做法和技巧来提高性能,包括自蒸馏和更多的训练时期。对于自蒸馏,分类和框回归分别由教师模型监督。由于DFL [20],框回归的蒸馏成为可能。此外,通过余弦衰减动态降低来自软标签和硬标签的信息比例,这有助于学生在训练过程中的不同阶段选择性地获取知识。此外,在评估时我们遇到的问题没有添加额外的灰色边框以损害性能,为此我们提供了一些补救措施。
量化与部署:为了解决基于重参数化模型的性能退化问题,我们使用 RepOpti-mizer [2] 训练 YOLOv6,以获得对量化友好的权重。此外,我们还采用通道级蒸馏(QAT)[36] 和图优化来追求极端性能。我们的量化 YOLOv6-S 在 42.3% 的平均精度 (AP) 和 869 FPS (批大小 = 32) 的吞吐量下达到了新的最先进的水平。
2.1 网络设计
单阶段目标检测器通常由后背、脖子和头部组成。后背主要决定特征表示能力,同时其设计对推理效率有重要影响,因为它承担了大部分计算成本。脖子用于聚合低级物理特性和高级语义特性,然后在所有层次上构建金字塔特征图。头部
由多个卷积层组成,根据由脖子组装的多级特征预测最终检测结果。从结构的角度来看,它可以分为基于锚点的方法和非锚点方法,或者更准确地说,参数耦合头和参数解耦头。
在YOLOv6中,基于硬件友好网络设计的原则[3],我们提出了两种可缩放重参数化的骨干网络和脖子来适应不同大小的模型,以及一个具有混合通道策略的高效解耦头。YOLOv6的整体架构如图2所示。
2.1.1 后端
如上文所述,骨干网络的设计对检测模型的有效性和效率有很大的影响。以往的研究表明,多分支网络[13, 14, 38, 39] 通常比单路径网络[15, 37] 能够实现更好的分类性能,但代价是并行性降低以及推理延迟增加。相反,像 VGG[37] 这样的简单单路网络具有高度并行和内存占用小的优点,导致更高的推理效率。最近在 RepVGG[3] 中提出了一种结构参数化方法来分离训练时间和推断时间的多分支拓扑结构与平铺架构以实现更好的速度准确率权衡。
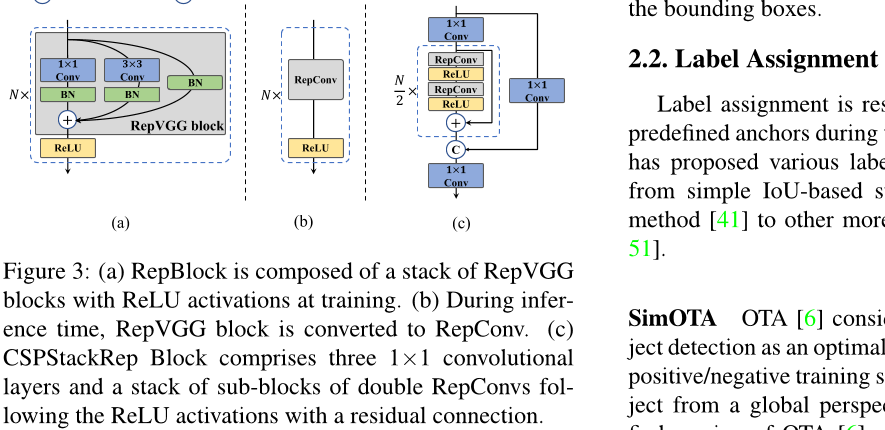
受上述工作的启发,我们设计了一个高效的可重参数化骨干网络,称为 EfficientRep。对于较小的模型,在训练阶段,主干部分的主要组件是 Rep-Block,如图 3 (a) 所示。在推断阶段,每个 RepBlock 都会被转换为堆叠的 3x3 卷积层(表示为 RepConv),带有 ReLU 激活函数,如图 3 (b) 所示。通常情况下,3x3 卷积在主流 GPU 和 CPU 上高度优化,并且具有更高的计算密度。因此,EfficientRep Backbon
利用硬件计算能力,同时显著降低推断延迟并提高表示能力。
然而,我们注意到随着模型容量的进一步扩展,单路径平面网络的计算成本和参数数量呈指数级增长。为了在计算负担和准确性之间取得更好的权衡,我们在中型和大型网络的骨干部分修改了CSPStackRep块。如图3 © 所示,CSPStackRep块由三个 1 × 1 卷积层组成,并且包含两个 RepVGG 块 [3] 或 RepConv(分别在训练或推断期间)的子块堆叠,具有残差连接。此外,采用了跨阶段部分(CSP)连接来提高性能,而不会带来过多的计算成本。与 CSPRepResStage [45] 相比,它具有更简洁的外观,并考虑了准确性和速度之间的平衡。
①:元素加法C:通道维度上的连接
2.1.2 颈部
在实践中,多个尺度上的特征整合已被证明是目标检测的关键且有效的部分。[9, 21, 24, 40] 我们采用改进版的PAN架构[24] 作为我们的检测器脖子的基础。此外,我们用 RepBlock(用于小模型)或CSPStackRep块(用于大模型)替代YOLOv5中使用的CSP块,并相应地调整其宽度和深度。YOLOv6的脖子被称为Rep-PAN。
2.1.3 头部
高效的解耦头部 YOLOv5 的检测头 是一个参数共享 分类和定位分支的耦合头,而它的
FCOS [41] 和 YOLOX [7] 中的对应分支解耦,并在每个分支中引入了两个额外的 3 × 3 卷积层以提高性能。
在YOLOv6中,我们采用了一种混合通道策略来构建一个更有效的解耦头部。具体来说,我们将中间的 3x3 卷积层的数量减少到只有一个。头的宽度由主干部分和脖子的宽度乘数共同缩放。这些修改进一步降低了计算成本,实现了更低的推理延迟。
无需锚点检测器 由于其更好的泛化能力和解码预测结果的简单性,无需锚点检测器脱颖而出。它的后处理时间成本大大降低。有两种类型的无需锚点检测器:基于锚点[7,41]和基于关键点[16,46,53]。在YOLOv6中,我们采用了基于锚点的方法,其框回归分支实际上预测了锚点到边界框四边的距离。
2.2 标签分配
标签分配负责在训练阶段为预定义锚点分配标签。以往的研究提出了各种标签分配策略,从简单的基于IoU的方法[41]到其他更复杂的方案[5, 7, 18, 48, 51]。
SimOTA [6] 将对象检测中的标签分配视为最优传输问题。它从全局角度为每个真实目标定义了正/负训练样本。SimOTA [7] 是OTA [6] 的简化版本,减少了额外的超参数并保持了性能。在YOLOv6的早期版本中使用了SimOTA作为标签分配方法。然而,在实践中,我们发现引入SimOTA会减慢训练过程,并且不稳定地训练并不罕见。因此,我们希望有一个替代方案来取代SimOTA。
任务对齐学习 任务对齐学习(TAL)首先在 TOOD [5] 中被提出,它设计了一个统一的分类分数和预测框质量度量。使用此度量替代 IoU 来分配对象标签。在一定程度上缓解了任务(分类和回归)之间的不匹配问题。
TOOD 的另一个主要贡献是关于任务对齐头(T 头)。T 头堆叠卷积层以构建交互特征,然后在这些特征之上使用任务对齐预测器(TAP)。PP-YOLOE [45] 通过用来自“感知注意力”的替代来改进 T 头。
轻量级的ESE注意力机制,形成ET头。然而我们发现ET头会降低我们的模型的推断速度,并且不会带来准确率上的提升。因此,我们保留了Efficient Decoupled Head的设计。
此外,我们观察到 TAL 可以比 SimOTA 带来更多的性能提升并稳定训练。因此,我们在 YOLOv6 中采用了 TAL 作为默认标签分配策略。
2.3 损失函数
目标检测包含两个子任务:分类和定位,分别对应于分类损失和边界框回归损失。对于每个子任务,近年来提出了各种各样的损失函数。在本节中,我们将介绍这些损失函数,并描述如何为 YOLOv6 选择最佳损失函数。
2.3.1 分类损失
提高分类器性能是优化检测器的关键部分。Focal Loss [22] 修改了传统的交叉熵损失以解决正负样本或硬样本和易样本之间的类别不平衡问题。为了处理训练和推断中质量估计与分类的不一致用法,Quality Focal Loss (QFL) [20] 进一步扩展了 Focal Loss,并使用分类监督下的分类得分和定位质量的联合表示来计算 focal loss。而 VariFocal Loss (VFL) [50] 来源于 Focal Loss [22],但它是以不同的重要性对待正负样本。通过考虑正负样本的不同重要性,它平衡了来自两个样本的学习信号。Poly Loss [17] 将常用的分类损失分解为一系列加权多项式基。它在不同的任务和数据集上调整多项式系数,实验证明这比交叉熵损失和 focal loss 更好。
我们评估了YOLOv6上的所有这些高级分类损失,最终采用VFL [50]。
2.3.2 盒子回归损失
盒子回归损失提供了定位边界框的显著学习信号。早期工作的原始盒子回归损失是L1损失。随着研究的深入,出现了各种精心设计的盒子回归损失函数,如IoU系列损失[8,11,35,47,52,52] 和概率损失[20]。
IoU 系列损失 IoU 损失 [47] 将预测框的四个边界作为整体进行回归。这已经被证明
因为与评估度量的一致性,它是有效的。有许多IoU变体,如GIoU [35]、DIoU [52]、CIoU [52]、α-IoU [11] 和SIoU [8] 等,形成相关的损失函数。在这项工作中,我们对GIoU、CIoU和SIoU进行了实验。在YOLOv6-N和YOLOv6-T中应用了SIoU,而其他方法使用了GIoU。
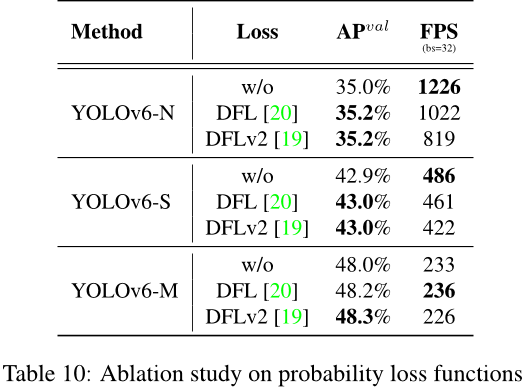
概率损失分布Focal Loss (DFL) [20] 将目标框位置的连续分布简化为离散的概率分布。它考虑了数据中的模糊性和不确定性,而无需引入任何其他强先验知识,这对于提高尤其是当真实框边界模糊时的目标框定位精度非常有帮助。在DFL的基础上,DFLv2 [19] 开发了一个轻量级子网络来利用分布统计与实际定位质量之间的密切相关性,从而进一步提高了检测性能。然而,DFL通常输出比普通目标框回归多出17倍的回归值,导致显著的开销。额外的计算成本大大阻碍了小模型的训练。DFLv2由于额外的子网络增加了计算负担。在我们的实验中,DFLv2 在我们的模型上带来了与DFL相似的性能提升。因此,我们只在YOLOv6-M / L中采用了DFL。实验细节请参见第3.3.3节。
2.3.3 目标损失
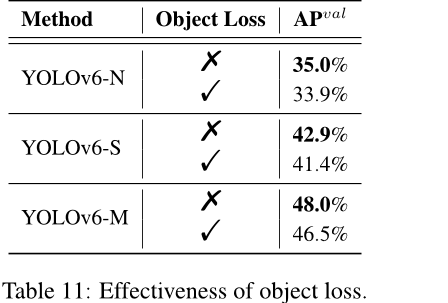
对象损失首先在FCOS [41]中被提出,以降低低质量的边界框分数,以便在后处理过程中将其过滤掉。它还用于YOLOX [7]以加速收敛并提高网络精度。作为锚框自由框架如FCOS和YOLOX,我们在YOLOv6中尝试了对象损失。不幸的是,这并没有带来很多积极的影响。详情请参见第3节。
2.4 行业就绪
下面这些技巧可以在实际使用中直接使用。它们并不是为了公平地比较,而是稳定地产生性能提升,不需要太多费力的工作。
2.4.1 更多训练周期
经验结果表明,随着训练时间的增长,检测器的表现会越来越好。我们把训练时长从300个时期延长到了400个时期,以达到更好的收敛。
2.4.2 自我蒸馏
为了在不引入太多额外计算成本的情况下进一步提高模型准确率,我们应用了分类器-
我们使用基于KL散度的知识蒸馏技术来最小化教师模型和学生模型之间的预测分布之间的KL散度。我们限制教师模型为预训练的学生模型,因此称为自蒸馏。请注意,KL散度通常用于衡量数据分布之间的差异。然而,在目标检测中有两个子任务,只有分类任务可以直接利用基于KL散度的知识蒸馏。得益于DFL损失 [20],我们也可以将其应用于框回归。知识蒸馏损失可以表示为:
其中pcls t 和pclss分别是老师模型和学生模型的分类预测,preg t 和preg s 分别是框回归预测。整体损失函数现在可以表示为:
其中Ldet是由预测值和标签计算得出的检测损失。引入超参数α是为了平衡这两种损失。在训练初期,来自教师的软标签更容易学习。随着训练的进行,学生的表现会与老师匹配,因此硬标签会帮助学生更多。基于此,我们对α应用余弦权重衰减来动态调整来自硬标签和教师软标签的信息。我们在YOLOv6上进行了详细的实验以验证自蒸馏的效果,将在第3节中讨论。
2.4.3 图片灰色边框
我们注意到,在 YOLOv5 [10] 和 YOLOv7 [42] 的实现中,每个图像周围都有一条半步长的灰色边框来评估模型性能。尽管没有添加任何有用的信息,但它有助于检测图像边缘附近的对象。这个技巧也适用于YOLOv6。
然而,额外的灰色像素明显降低了推断速度。没有灰色边框时,YOLOv6 的性能会下降,[10,42] 中也观察到了这种情况。我们推测这个问题与 mosaic 数据增强中的灰色边框填充有关。为了验证这一点,我们在最后几个时期关闭了 mosaic 数据增强(即所谓的淡入策略)。在这方面,我们改变了灰色边框的区域,并直接将带有灰色边框的图像调整为目标图像大小。结合这两种策略,我们的模型可以在不降低推理速度的情况下保持甚至提高性能。
2.5. 量身定制和部署
在工业部署中,为了进一步提高运行速度而牺牲较小的性能通常采用量化。后训练量化(Post-Training Quantization,简称 PTQ)直接使用一小部分校准集对模型进行量化。而利用训练数据的有意识训练(Quantization-Aware Training,简称 QAT)可以进一步提高性能,它通常与蒸馏一起使用。然而,由于 YOLOv6 中大量使用了重参数化块,之前的 PTQ 技术无法产生高性能,而在训练和推断期间匹配假量化器时很难整合 QAT。在这里,我们展示了部署中的陷阱和我们的解决方案。
2.5.1 重新参数化优化器
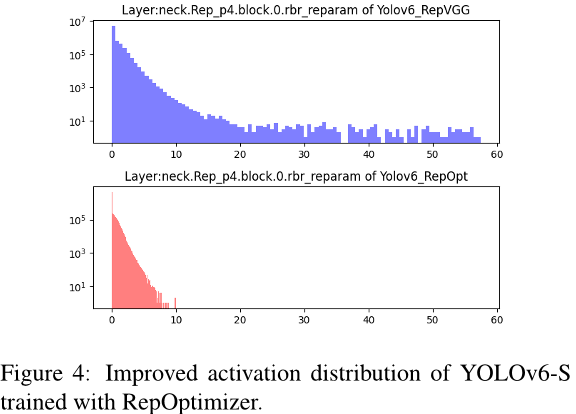
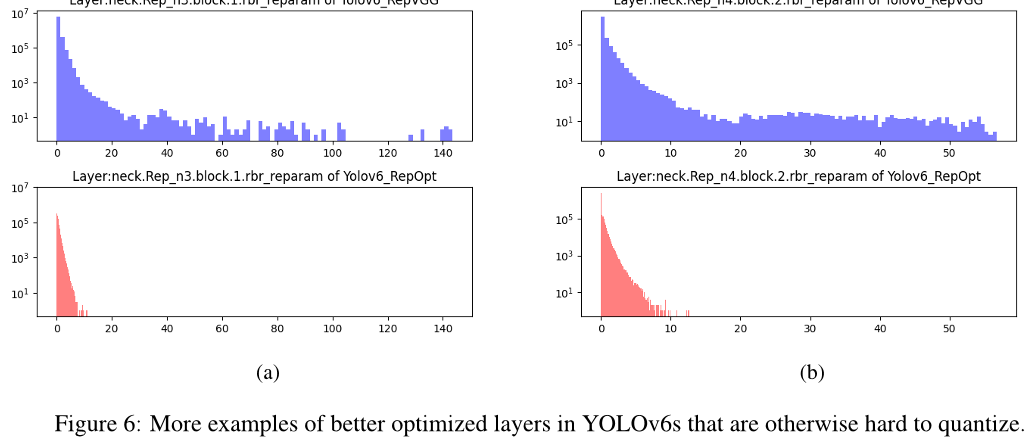
RepOptimizer [2] 提出了在每个优化步骤中对梯度进行重新参数化。这种技术也可以很好地解决基于重参数化的模型的量化问题。因此,我们以这种方式重建了YOLOv6 的重参数化块,并使用 RepOptimizer 进行训练,以获得对量化友好的权重。特征图的分布大大缩小(例如,见图 4 和 B.1),这极大地有利于量化过程;参见第 3.5.1 节的结果。
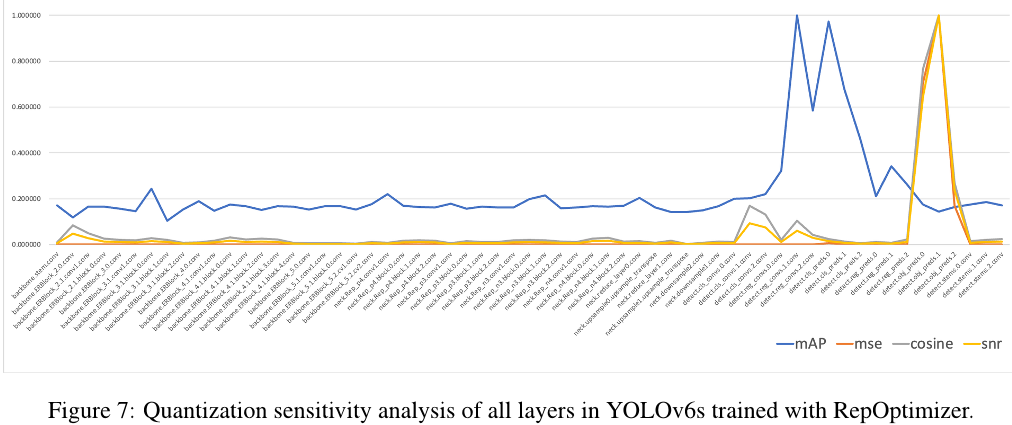
2.5.2 敏感性分析
我们通过部分转换为浮点计算来进一步提高 PTQ 的性能。为了获得敏感性分布,通常使用几个指标:均方误差(MSE)、信噪比(SNR)和余弦相似度。通常来说,对于比较,可以选择激活某一层之后的输出特征图,并且在量化之前计算这些指标。作为替代方案,也可以
计算在某一层上启用了或禁用了量化时的验证AP [29]。
我们在使用 RepOptimizer 训练的 YOLOv6-S 模型上计算所有这些指标,并选择前 6 个敏感层以浮点运行。敏感性分析的完整图表可以在 B.2 中找到。
2.5.3 通道级蒸馏的有意识训练
如果 PTQ 不足,我们建议使用有意识的训练(QAT)来提高量化性能。为了解决训练和推断过程中假量化器不一致的问题,有必要在 RepOptimizer 的基础上构建 QAT。此外,在YOLOv6 框架中采用了通道级蒸馏[36] (后来称为CW Distill),如图5所示。这也是一个自我蒸馏方法,其中教师网络是在FP32精度下的学生本身。见第3.5.1节中的实验。
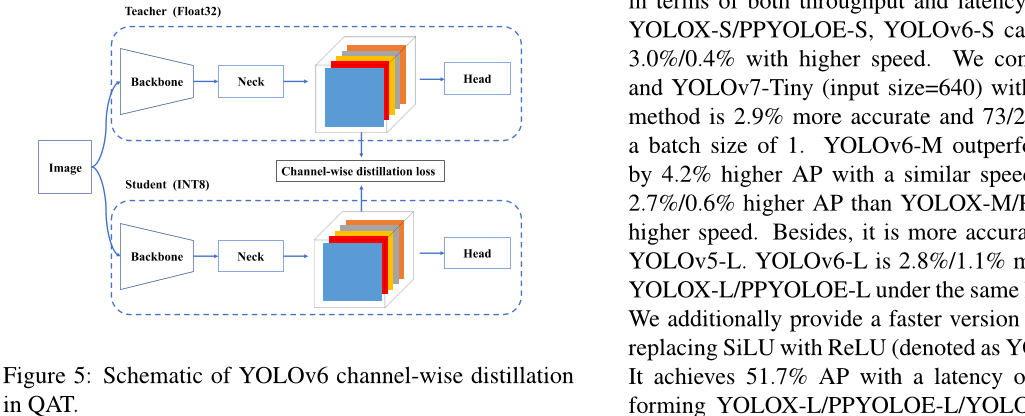
3. 实验
3.1. 实现细节
我们使用与YOLOv5 [10]相同的优化器和学习率调度程序,即带动量的随机梯度下降(SGD)和余弦衰减。我们还采用了warm-up、分组权重衰减策略和指数移动平均值(EMA)。我们在[1,7,10]中跟随了两个强大的数据增强方法(Mosaic[1,10]和Mixup[49])。完整的超参数设置列表可以在我们的发布代码中找到。我们在COCO 2017 [23]训练集上训练模型,并在COCO 2017验证集上评估准确率。除非另有说明,否则所有模型都是在8个NVIDIA A100 GPU上进行训练的,速度性能是在带有TensorRT版本7.2的NVIDIA Tesla T4 GPU上测量的。速度
在附录A中,展示了使用其他 TensorRT 版本或在其他设备上测量的性能。
3.2 比较
由于本工作的目标是为工业应用构建网络,因此我们主要关注所有模型部署后的速度性能,包括吞吐量(批大小为1或32时的FPS)和GPU延迟,而不是浮点运算次数或参数数量。我们将YOLOv6与其他YOLO系列最先进的检测器进行比较,包括YOLOv5 [10]、YOLOX [7]、PPYOLOE [45] 和 YOLOv7 [42]。请注意,我们在具有FP16精度的同一张Tesla T4 GPU上使用TensorRT [28] 测试了所有官方模型的速度性能。根据其开源代码和权重,在输入大小为416和640的情况下重新评估了YOLOv7-Tiny的性能。结果如表1和图1所示。与YOLOv5-N / YOLOv7-Tiny (input size = 416)相比,我们的YOLOv6-N在吞吐量和延迟方面分别显著提高了7.9%和2.6%。它还具有最佳的速度性能。与YOLOX-S / PPYOLOE-S相比,YOLOv6-S可以在更高的速度下提高AP 3.0% / 0.4%。我们比较了YOLOv5-S和YOLOv7-Tiny (input size = 640)与YOLOv6-T,我们的方法在批大小为1时比他们的方法更准确且速度快2.9%。YOLOv6-M以类似的速度优于YOLOv5-M,AP 高出 4.2%,并且相对于YOLOX-M / PPYOLOE-M以更快的速度实现2.7% / 0.6%的AP 提高。此外,它比YOLOv5-L 更精确且运行得更快。YOLOv6-L在相同的延迟约束下比YOLOX-L / PPYOLOE-L 更准确2.8% / 1.1%。我们通过用ReLU替换SiLU提供了一个更快版本的YOLOv6-L(标记为YOLOv6-L-ReLU)。它的精度和速度均优于YOLOX-L / PPYOLOE-L / YOLOv7,达到51.7%的AP,延迟为8.8毫秒。
3.3 裁剪研究
3.3.1 网络
backbone 和 neck 我们探索了单路径结构和多分支结构对 backbone 和 neck 的影响,以及 CSPStackRep 块中的通道系数(记为 CC)。本节中描述的所有模型都使用 TAL 作为标签分配策略、VFL 作为分类损失和带有 DFL 的 GIoU 作为回归损失。结果如表 2 所示。我们发现不同大小的模型应该有不同的最佳网络结构。
对于YOLOv6-N,单路径结构在准确性和速度方面都优于多分支结构。虽然单路径结构比多分支结构具有更多的浮点运算和参数,但它可以
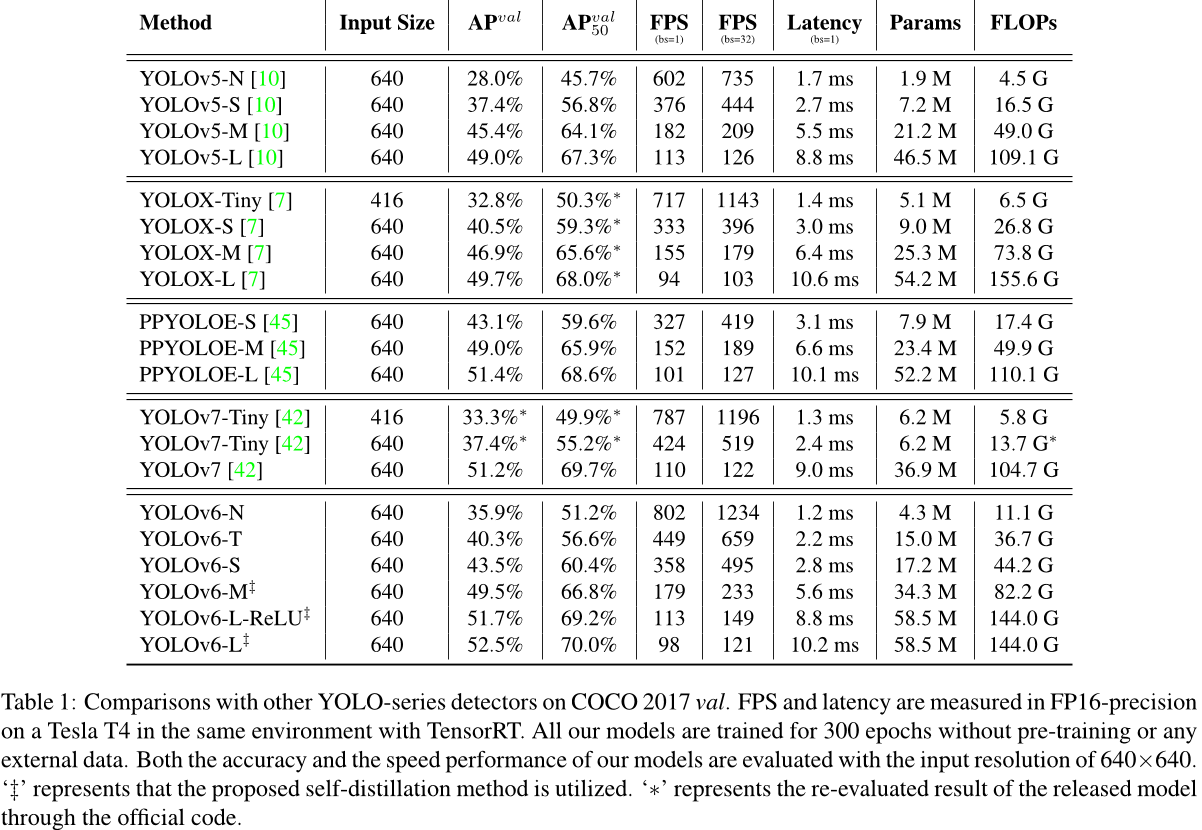
由于内存占用较低且并行度更高,运行速度更快。YOLOv6-S 的两种块风格带来了相似的表现。对于更大的模型,多分支结构在准确性和速度方面都取得了更好的效果。我们最终选择了带有通道系数2/3的多分支YOLOv6-M 和1/2的YOLOv6-L。
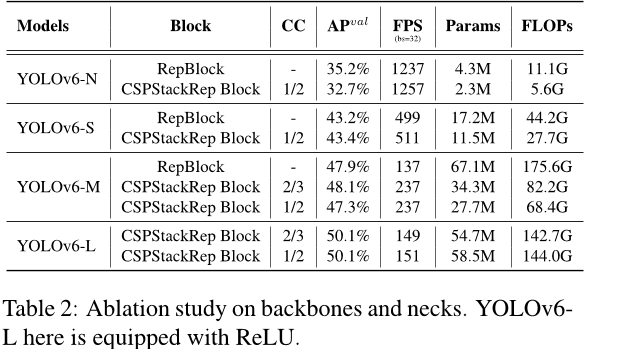
此外,我们研究了YOLOv6-L中颈部宽度和深度的影响。表3中的结果显示,细长的脖子比宽浅的脖子在相似的速度下表现得更好0.2%。
卷积层与激活函数的组合YOLO 系列采用了广泛的激活函数,包括 ReLU [27]、LReLU [25]、Swish [31]、SiLU [4] 和 Mish [26]等。在这些激活函数中,SiLU 是最常用的。一般来说,SiLU 的精度更高,并且不会带来太多的额外计算成本。然而,在工业应用中,尤其是使用 TensorRT[28] 加速部署模型时,由于其与卷积的融合,ReLU 具有更大的速度优势。
此外,我们进一步验证了不同大小网络中RepConv/普通卷积(记为Conv)和ReLU/SiLU/LReLU组合的有效性,以实现更好的权衡。如表4所示,在准确性方面,使用SiLU的Conv表现最佳,而RepConv和ReLU的组合实现了更好的权衡。建议用户在对延迟敏感的应用程序中采用带ReLU的RepConv。我们选择使用RepConv/ReLU组合-
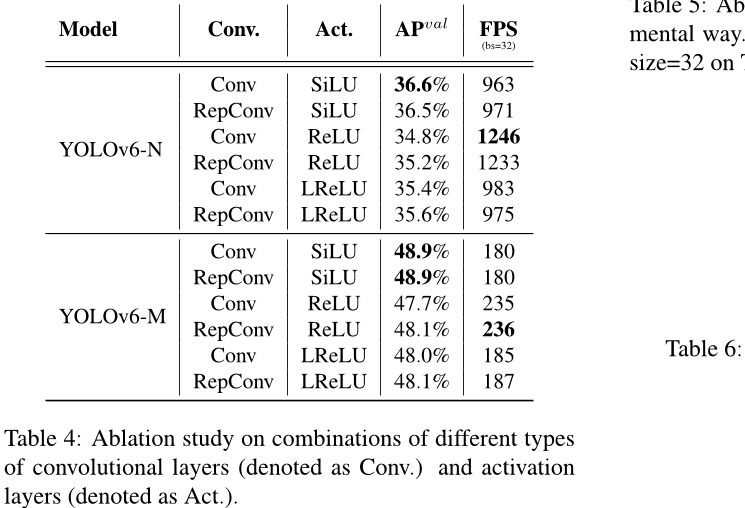
YOLOv6-N/T/S/M 使用更高效的推理速度,而大型模型 YOLOv6-L 则使用卷积/ SiLU 组合来加速训练并提高性能。
杂项设计 我们还根据YOLOv6-N在第2.1节中提到的其他网络部分进行了一系列消融研究。我们选择YOLOv5-N作为基线,并逐个添加其他组件。结果如表5所示。首先,通过解耦头部(标记为DH),我们的模型具有更高的准确率(提高了1.4%)和更高的时间开销(增加了5%)。其次,我们验证了无锚框范例比基于锚框的范例快51%,因为它的预定义锚框数量减少了3倍,从而导致输出维度降低。此外,对主干(EfficientRep Backbone)和瓶颈层(Rep-PAN neck)进行了统一修改(标记为EB+RN),带来了3.6%的AP改进,并且运行速度提高了21%。最后,优化后的解耦头(混合通道,HC)在准确度和速度上分别带来了0.2%的AP和6.8%的FPS提升。
3.3.2 标签分配
在表6中,我们分析了主流标签分配策略的有效性。我们在YOLOv6-N上进行实验。不出所料,我们观察到SimOTA和TAL是
32.5%
SimOTA [7]
TAL [5]
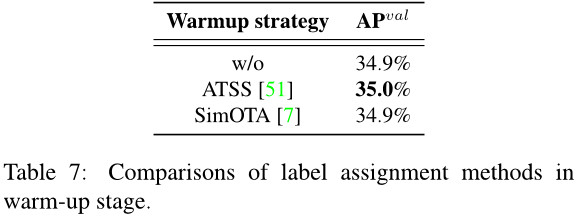
最佳策略。与ATSS相比,SimOTA可以提高AP 2.0%,而TAL比SimOTA 提高了0.5% 的AP。考虑到TAL在稳定训练和更好的准确率性能方面,我们选择TAL作为我们的标签分配策略。
此外,TOOD [5] 的实现采用 ATSS [51] 作为早期训练阶段的预热标签分配策略。我们还保留了预热策略,并对其进行了进一步探索。具体细节请参见表 7 ,我们可以发现,在没有预热或使用其他策略(即 SimOTA)进行预热的情况下,它也可以实现类似的表现。
3.3.3 损失函数
在目标检测框架中,损失函数由分类损失、回归损失和可选的目标损失组成,可以表示为:
其中Lcls、Lreg和Lobj分别是分类损失、回归损失和对象损失。 λ和μ是超参数。
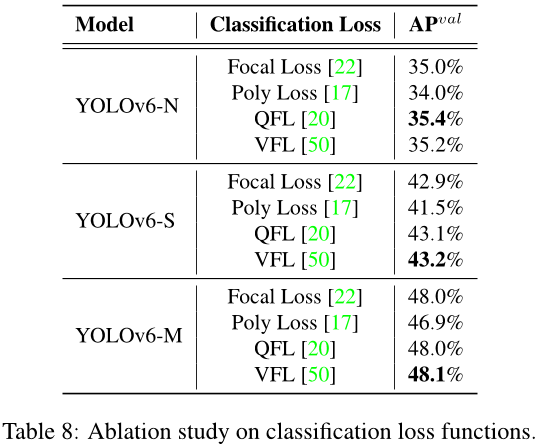
在本节中,我们评估了YOLOv6中的每个损失函数。除非另有说明,否则YOLOv6-N、YOLOv6-S 和 YOLOv6-M 的基线分别为使用 TAL、Focal Loss 和 GIoU Loss 训练的 35.0%、42.9% 和 48.0%。
分类损失 我们在 YOLOv6-N/S/M 上尝试了焦散损失[22]、多项式损失[17]、QFL[20] 和 VFL[50]。如表 8 所示,与焦散损失相比,VFL 在 YOLOv6-N/S/M 上分别带来了 0.2%/0.3%/0.1% 的平均精度提升。我们选择 VFL 作为分类损失函数。
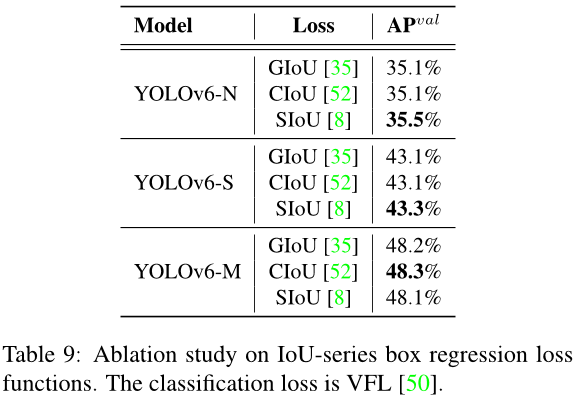
回归损失和交并比系列概率损失函数在YOLOv6-N/S/M上进行了实验。
YOLOv6-N/S/M 使用最新的 IoU 系列损失。表 9 中的实验结果表明,SIoU 损失在 YOLOv6-N 和 YOLOv6-T 上优于其他损失,而 CIoU 损失在 YOLOv6-M 上表现得更好。
对于概率损失,如表10所示,引入DFL 可以获得YOLOv6-N/S/M 的性能提升分别为0.2%/0.1%/0.2%。然而,小模型的推断速度受到很大影响。因此,只在 YOLOv6-M/L 中引入了 DFL。
目标损失 在表 11 中,我们也对 YOLOv6 进行了目标损失的实验。从表 11 可以看出,目标损失对 YOLOv6-N/S/M 网络有负面影响,其中 YOLOv6-N 的最大跌幅为 1.1%AP。这种负效应可能来自 TAL 中对象分支与其他两个分支之间的冲突。具体来说,在训练阶段,使用预测框与真实框之间的交并比 (IoU) 和分类分数来共同构建一个度量标准,作为分配标签的标准。然而,引入的对象分支将需要协调的任务数从两个增加到三个,这
损失 AP 值 FPS
bs = 32 的翻译为:
显然增加了难度。根据实验结果和分析,YOLOv6 中丢弃了目标丢失。
3.4. 行业便捷改进
更多的训练周期在实践中,更多的训练周期是一种简单而有效的方法来进一步提高准确率。我们小模型训练了300个和400个周期的结果如表12所示。我们观察到,更长的训练周期可以显著提高AP值,YOLOv6-N、T、S 分别为0.4%、0.6%、0.5%考虑到可接受的成本和产生的收益,这表明训练
300个 epoches 400个 epoches
35.9% 36.3%
40.3% 40.9%
43.4% 43.9%
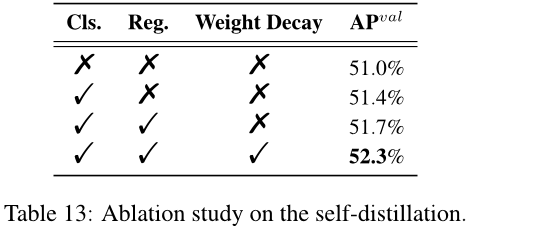
自我蒸馏 在表13中,我们对YOLOv6-L进行了详细的实验来验证所提出的自我蒸馏方法。如表所示,仅在分类分支上应用自我蒸馏可以带来0.4%的AP提升。此外,我们在边界框回归任务上简单地执行了自我蒸馏以获得0.3%的AP增加。引入权重衰减可使模型提高0.6%的AP。
在第 2.4.3 节中,我们介绍了一种策略来解决不添加灰色边框时性能下降的问题。实验结果如表 14 所示。在这些实验中,YOLOv6-N 和 YOLOv6-S 分别训练了 400 个 epoch,而 YOLOv6-M 则训练了 300 个 epoch。可以观察到,在移除灰边时,YOLOv6-N/S/M 的精度分别降低了 0.4%、0.5% 和 0.7%。然而,当采用 mosaic 模糊处理时,性能下降变为 0.2%、0.5% 和 0.5%,这表明,一方面,性能下降的问题得到了缓解;另一方面,无论是否填充灰边,小模型(YOLOv6-N/S)的精度都得到了提高。此外,我们将输入图像限制为 634×634,并在边缘周围添加了宽 3 像素的灰边(更多结果请参见附录 C)。通过这种策略,最终图像的大小将是预期的 640×640。表 14 中的结果表明,将最终图像的大小从 672 缩小到 640 后,YOLOv6-N/S/M 的最终精度甚至提高了 0.2%、0.3% 和 0.1%。
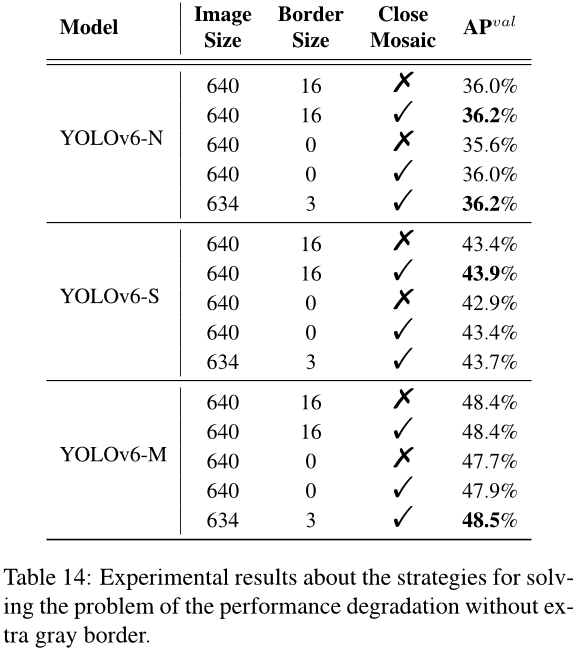
表14:没有额外灰色边框时性能退化问题的策略实验结果。
3.5 量化结果
我们以YOLOv6-S为例验证我们的量化方法。下面的实验在两个版本上进行,基准模型训练了300个时期。
3.5.1 赛事预选赛
当使用 RepOptimizer 训练模型时,平均性能显著提高。参见表 15。Re-pOptimizer 通常更快并且几乎相同。
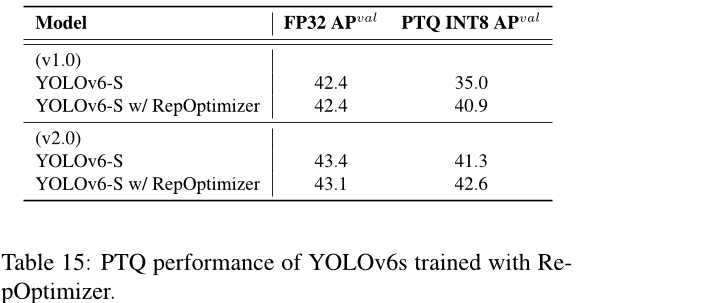
表15:使用 RepOtimizer 训练的 YOLOv6s 的 PTQ 性能。
3.5.2 QAT
对于v1.0,我们在第2.5.2节中获得的非敏感层上应用了假量化的训练来进行有意识的量化,并称之为部分QAT。我们与

由于在 v2.0 发布中删除了对量化敏感的层,我们直接使用全量 QAT 在 RepOptimizer 训练的 YOLOv6-S 上。通过图形优化消除插入的量化器以获得更高的准确性和更快的速度。我们在表 17 中比较了基于蒸馏的 PaddleSlim [30x] 量化结果。请注意,我们的量化版本YOLOv6-S 是最快且最准确的,参见图 1。
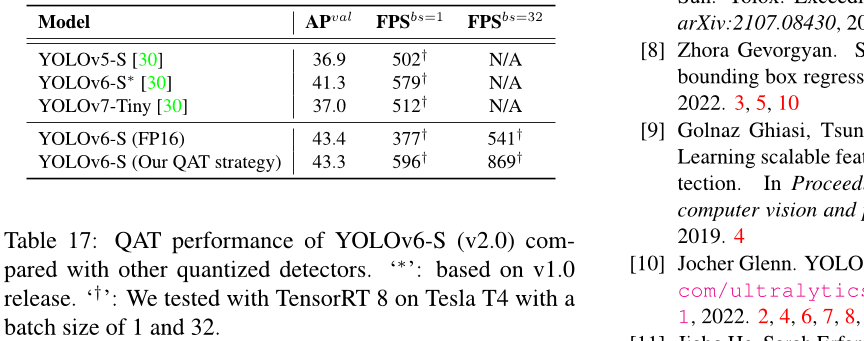
表17:YOLOv6-S (v2.0)与其他量化检测器的 QAT 性能比较。‘∗’:基于 v1.0 发布版。‘†’:我们在 Tesla T4 上使用 TensorRT 8 进行了测试,批大小为 1 和 32。
4. 结论
简而言之,考虑到持久的工业需求,我们呈现了YOLOv6 的当前形式,仔细检查了迄今为止所有目标检测器组件的进步,同时灌输我们的想法和做法。结果在准确性和速度方面都超过了其他可用的实时探测器。为了方便工业部署,我们还为 YOLOv6 提供了一个定制化的量化方法,使其具有更快的检测能力。我们真诚地感谢学术界和工业界的卓越思想和努力。未来我们将继续扩展这个项目以满足更高的标准和更苛刻的场景。
参考文献
Alexey Bochkovskiy, Chien-Yao Wang 和 Hong-Yuan Mark Liao。Yolov4:检测对象的速度和准确性。arXiv预印本arXiv:2004.10934,2020年。2、4、6、7
丁小涵,陈红豪,张翔宇,黄开琦,韩正功,丁贵光。重新参数化你的优化器而不是架构。arXiv预印本arXiv:2205.15242 ,2022 年。第 2、3、6 页。
丁小寒,张翔宇,马宁宁,韩 junkong,丁贵光,孙健。Repvgg:让 VGG 风格卷积神经网络再次伟大。在IEEE/CVF计算机视觉和模式识别会议上发表论文,第 13733-13742 页,2021 年。
Stefan Elfwing,Eiji Uchibe 和 Kenji Doya。 在强化学习中使用神经网络函数逼近的 Sigmoid 加权线性单元。 神经网络,107:3-11,2018 年。
程建峰,仲宇杰,高雨洁,马修·R·斯科特和黄伟林。Tood:面向任务的一阶段物体检测。在 ICCV,2021 年。第 2 部分,第 4 部分,第 9 部分
郑格,刘松涛,李泽明,Yoshie Osamu,孙健。OTA:用于对象检测的最优运输分配。2021 年 IEEE/CVF 计算机视觉与模式识别会议 (CVPR),第 303-312 页,2021 年。
郑格,刘松涛,王峰,李振明,孙建。Yolox:在2021年超越YOLO系列。arXiv预印本arXiv:2107.08430,2021年。第2、4、5、6、7、8、9、15页。
泽拉·格沃基扬。通过更强大的学习进行边界框回归。arXiv 预印本,https://arxiv.org/abs/2205.12740。2022 年 3 月 5 日。
Golnaz Ghiasi, Tsung-Yi Lin 和 Quoc V Le。Nas-FPN:学习可扩展特征金字塔结构进行目标检测。在IEEE/CVF 计算机视觉与模式识别会议上发表论文,第7036-7045页,2019年。4
[10] 约克格伦。YOLOv5 发布版 v6.1。https://github.com/ultralytics/yolov5/releases/tag/v6.1,2022 年 2 月 4 日、6 日、7 日、8 日、15 日。
何佳博,Sarah Erfani,马兴军,James Bailey,陈英驰,华先胜。α-iou:用于边界框回归的幂交并损失函数族。神经信息处理系统进展,34:20230–20242,2021年。 5
[12] 贺凯明,张祥宇,任少卿,孙剑。《深度残差网络用于图像识别》。在IEEE 计算机视觉与模式识别会议论文集中,第770-778页,2016年。
何凯明,张祥宇,任少卿,孙剑。深度残差网络中的身份映射。欧洲计算机视觉会议,第 3 卷,第 630-645 页。Springer,2016 年。
高黄,庄刘,劳伦斯·范德玛滕和基兰·韦恩伯格。密集连接卷积网络。在IEEE 计算机视觉与模式识别会议论文集中,第 4700 - 4708 页,2017 年。3
[15] Alex Krizhevsky, Ilya Sutskever 和 Geoffrey E Hinton。深度卷积神经网络在 ImageNet 分类中的应用。神经信息处理系统进展,25,2012 年。3
Hei Law 和 Jia Deng。Cornernet:检测对象作为配对关键点。欧洲计算机视觉会议 (ECCV) 论文集,第 734-750 页,2018 年。
赵琦冷,谭明星,刘晨溪,Ekin Dogan Cubuk,石晓杰,盛书阳,Dragomir Anguelov。Polyloss:一种分类损失函数的多项式展开视角。arXiv预印本arXiv:2204.12511,2022年5月10日。
[18] 谢李,陈航,卢黄立,雷张。用于目标检测的双权值标签分配方案。在IEEE/CVF 计算机视觉与模式识别会议论文集中(CVPR),第2、4、9页,2022 年6月。
[19] 赖翔,王文海,胡晓琳,李军,唐金辉,杨健。广义焦散损失v2:学习密集目标检测中可靠的定位质量估计。在IEEE/CVF 计算机视觉与模式识别会议论文集中,第11632-11641页,2021年。
李翔,王文海,吴立军,陈硕,胡晓琳,李俊,唐金辉,杨健。广义焦散损失:学习密集目标检测中的高质量和分布式边界框。神经信息处理系统进展,33:21002–21012, 2020年。3、5、6、10
林中义,Dollar Piotr,Girshick Ross,何凯明,Hariharan Bharath 和Belongie Serge。 特征金字塔网络用于物体检测。 在IEEE 计算机视觉与模式识别会议论文集中,第2117-2125页,2017年。
林宗义、Priya Goyal、Ross Girshick、何凯明和Piotr Doll。密集物体检测中的焦散损失。在IEEE国际计算机视觉会议论文集中,第2980-2988页,2017年。
林中义、迈克尔·马尔、塞尔日·贝尔隆吉埃、詹姆斯·海斯、皮耶特罗·佩罗纳、德瓦·拉马南、Piotr Doll’ar 和 C Lawrence Zitnick。Microsoft COCO: Common Objects in Context。欧洲计算机视觉会议,第740-755页。Springer,2014 年。
[24] 王树伟,刘路琪,齐海芳,石建平,贾亚娟。实例分割的路径聚合网络。 在IEEE 计算机视觉与模式识别会议论文集中,第8759-8768页,2018年。 2, 4
Andrew L Maas,Awni Y Hannun,Andrew Y Ng 等人。Rectifier 非线性可提高神经网络声学模型性能。在ICML’13: Proceedings of the 29th International Conference on Machine Learning, pp.3, 2013. 8
Diganta Misra。Mish:一个自我规范的非单调神经元激活函数。arXiv 预印本,卷。4(2):10–48550,2019 年。8
[27] Vinod Nair 和 Geoffrey E Hinton。Rectified 线性单元提高受限玻尔兹曼机。在 ICML,2010 年。8
NVIDIA。TensorRT。https://developer.nvidia.com/tensorrt,2018 年 7 月 8 日。
[29] NVIDIA。pytorch-quantization 的文档。https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/index.html,2021 年 7 月。
[30] PaddleSlim。PaddleSlim 文档。https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_yolo_series,2022 年 12 月。
Prajit Ramachandran、Barret Zoph 和 Quoc V Le。寻找激活函数。arXiv:1710.05941v8,2017 年。
[32] 约瑟夫·雷德蒙,桑托什·迪瓦拉,罗斯·吉尔希克,阿里·法哈迪。You only look once: Unified, real-time object de-tection. 在《计算机视觉与模式识别》会议论文集中,第 779-788 页,2016 年。 2
[33] 约瑟夫·雷德蒙,阿里·法尔哈迪。YOLO9000:更好、更快、更强。在IEEE 计算机视觉与模式识别会议论文集中,第7263-7271页,2017年。2
[34] 约瑟夫·雷德蒙和阿里·法尔哈迪。 yolov3:增量改进。 arXiv预印本arXiv:1804.02767,2018年。 2
哈米德·雷扎托菲吉、内森·陶伊、June Young Gwak、Amir Sadeghian、Ian Reid 和 Silvio Savarese。广义交并集:一种用于边界框回归的度量和损失函数。在IEEE/CVF 计算机视觉与模式识别会议论文集中,第 658 - 666 页,2019 年。3, 5, 10
[36] 张勇舒、刘一帆、高剑飞、郑岩、沈春华。密集预测中的通道知识蒸馏。在IEEE/CVF 国际计算机视觉会议论文集中,第 2, 3, 7 页,2021 年,第 5311-5320 页。
[37] Karen Simonyan 和 Andrew Zisserman。用于大规模图像识别的深度卷积网络。arXiv 预印本,arXiv:1409.1556,2014 年。
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke 和 Andrew Rabinovich。2015年,在《IEEE 计算机视觉与模式识别会议论文集》(Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition) 上发表,第38页至46页。
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens 和 Zbigniew Wojna。重新考虑用于计算机视觉的Inception架构。在IEEE 计算机视觉与模式识别会议论文集中,第2818-2826页,2016年。3
[40] 陈明星,庞若萌,Le Quc V。Efficientdet:可扩展且高效的物体检测。在IEEE/CVF 计算机视觉与模式识别会议论文集中,第10781-10790页,2020年。
[41] 张天,沈春华,陈昊,何通。FCOS:全卷积单阶段目标检测。在国际计算机视觉会议 (ICCV) 会议上论文集,2019年。4、5
[42] 王谦遥,Alexey Bochkovskiy 和 Hong-Yuan Mark Liao。Yolov7:可训练的免费物品袋为实时目标检测器设立了新的基准。arXiv 预印本,arXiv:2207.02696,2022 年。2、6、7、8、15
[43] 王建耀,廖宏源,吴岳华,陈平阳,谢俊伟,叶志豪。CSPNet:一种可以增强卷积神经网络学习能力的新骨干。在IEEE/CVF 计算机视觉与模式识别研讨会论文集中,第390-391页,2020年。
[44] 袁尚良,王新欣,吕文宇,张琴瑶,崔成,邓开鹏,王冠中,当青青,魏胜雨,杜云宁 等。Pp-yoloe:一种 YOLO 的演化版本。arXiv eprint arXiv:2203.16250, 2022. 2
【45】徐上良,王新欣,吕文宇,张琴瑶,崔程,邓开鹏,王冠中,当庆庆,魏盛玉,杜云宁等。Pp-yoloe:一种 YOLO 的演化版本。arXiv e-print arXiv:2203.16250, 2022 年 4 月 7 日。第 8、15 页。
[46] 葛阳,刘绍辉,胡汉,王立伟,林世平。用于目标检测的点集表示Reppoints。在IEEE/CVF 国际计算机视觉会议论文集中,第 9657 - 9666 页,2019 年。
[47] 于家辉,蒋雨宁,王张阳,曹志民和黄天翔。Unitbox:一个先进的对象检测网络。在第24届ACM 国际多媒体会议论文集中,第516-520页,2016年。
Mohsen Zand, Ali Etemad 和 Michael A. Greenspan。ObjectBox:从中心到方框的无锚点目标检测。arXiv,abs/2207.06985,2022 年。
张宏毅,穆斯塔法·西塞,Yann N. Dauphin 和大卫·洛佩兹-帕斯。混合:超越经验风险最小化。arXiv 预印本。arXiv:1710.09412v1 [cs.LG], 2017 年 10 月 26 日。
[50] 张浩阳,王英,Dayoub Feras 和 Sun-derhauf Niko。Varifocalnet:一种基于 IOU 的密集物体检测器。在 2021 年 IEEE/CVF 计算机视觉与模式识别会议论文集中,第 8514-8523 页。3、5、10
张世峰,程驰,姚永强,雷振雷,Stan Z. Li。通过自适应训练样本选择弥合基于锚点和无锚点检测之间的差距。在CVPR,2020年。2, 4, 9
赵会政,王平,刘伟,李金泽,叶荣光,任东伟。距离交并比损失:用于边界框回归的更快更好的学习。在AAAI 人工智能大会论文集,第34卷,第12993-13000页,2020年。5,10
[53] 章星易,王德泉,Philipp Krähenbühl。物体作为点。arXiv预印本arXiv:1904.07850,2019年4月。
A. 详细的延迟和吞吐量基准测试
A.1. 设置
除非另有说明,所有报告的延迟都是在NVIDIA Tesla T4 GPU上使用TensorRT版本7.2.1.6测量的。由于硬件和软件设置的差异很大,我们重新测量了所有模型在相同配置(硬件和软件)下的延迟和吞吐量。为了方便参考,我们在表18中切换了TensorRT版本以进行一致性检查。还包括在V100 GPU上的延迟(表19),以便于比较。这为我们提供了最先进的检测器的全谱视图。
A.2. TensorRT 8 中的 T4 GPU 延迟表
参见表 18。YOLOv6 模型的吞吐量仍然与同行相媲美。
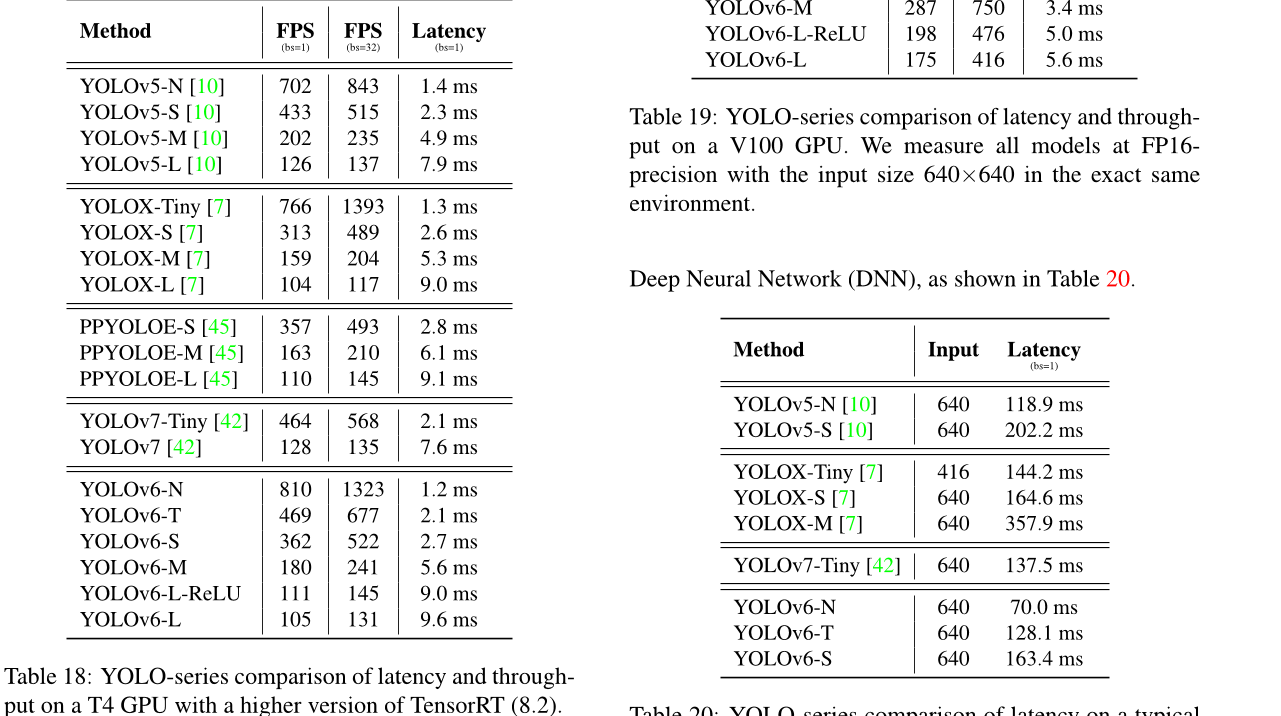
表18:在更高版本的 TensorRT (8.2) 上,使用 T4 GPU 的YOLO 系列的延迟和吞吐量比较。
A.3. V100 GPU 延迟表
参见表 19。YOLOv6 的速度优势在很大程度上得以保持。
A.4. CPU 延迟
我们使用OpenCV在 2.6 GHz英特尔酷睿i7 CPU上评估我们的模型和其他竞争对手的表现。
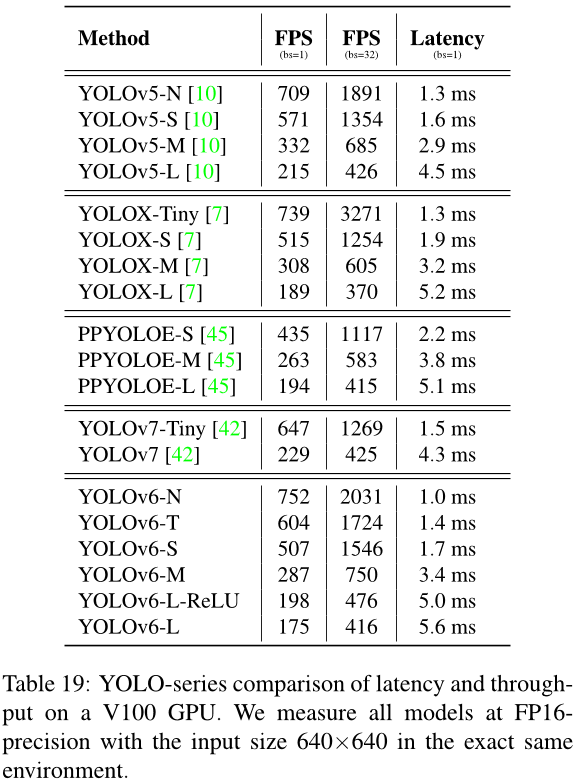
表19:在V100 GPU上,YOLO系列模型的延迟和吞吐量比较。我们在完全相同的环境中使用FP16精度测量所有模型,并且输入大小为640x640。
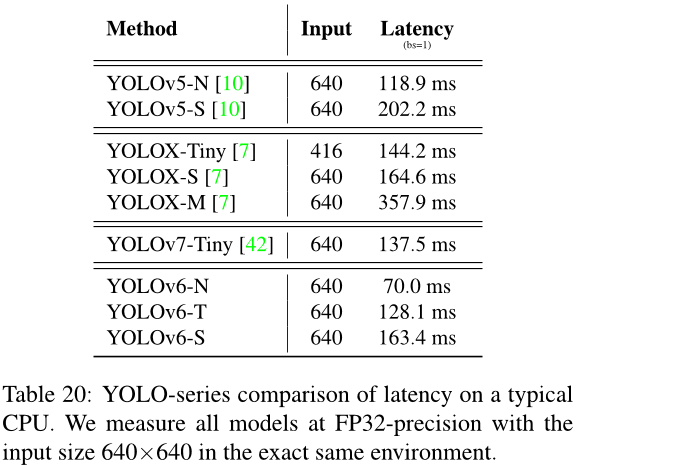
表20:YOLO系列在典型CPU上的延迟比较。我们在完全相同的环境中,以FP32精度测量所有模型,输入大小为640x640。
B. 量化细节
B.1. 特征分布比较
我们展示了更多层数的特征分布,在使用 RepOptimizer 训练后,这些层的分布得到显著缓解。见:
图6。
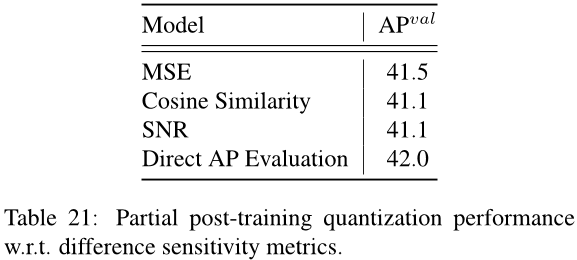
B.2 敏感性分析结果
如图 7 所示,我们观察到信噪比和余弦相似度给出了高度相关的结果。然而,直接评估平均精度 (AP) 可以产生不同的全景。尽管如此,在最终量化性能方面,均方误差 (MSE) 最接近于直接 AP 评估,请参见表 21。
C. 灰色边界的分析
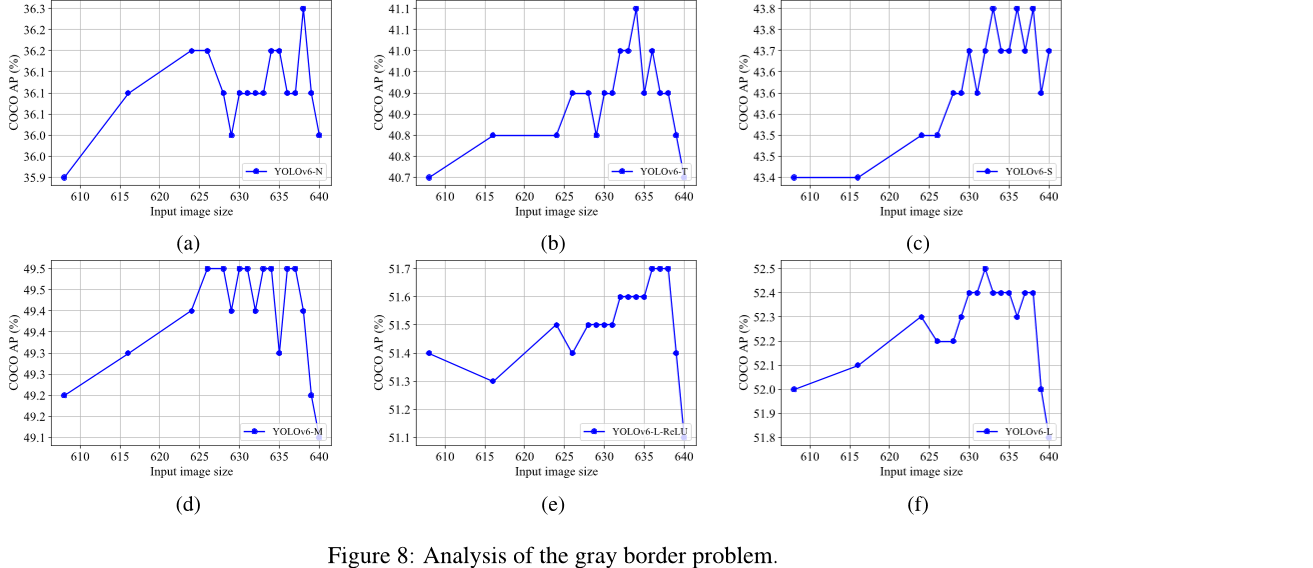
为了分析灰边框的影响,我们进一步探索了不同大小的图像加载并调整为 640x640 像素时的不同边框设置。例如,当图像大小为 608 且边框大小为 16 时。此外,通过一个简单的调整,我们可以缓解预处理和后处理之间信息对齐的问题。结果如图 8 所示。我们可以看到每个模型在不同的边框大小下都能达到最佳平均精度(AP)。另外,与输入大小为 640 相比,如果输入图像尺寸位于 632 到 638 范围内,我们的模型在平均情况下可以提高约 0.3% 的 AP。
层:脖子。Yolov6_RepVGG neck.Rep_n3.block.1.rbr_reparam 层:脖子。Yolov6_RepVGG neck.Rep_n4.block.2.rbr_reparam


















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









