







D*lite算法(2002|动态最优|逆向搜索):
与D*算法搜索方向类似,D*lite采用反向搜索;与LPA*算法代价计算类似,D*Lite对每个节点的终点G距离g (n)保持两个估计值:之前计算的g(n)值(和A* 、LPA*的到起点S的g (n)一致)、一个基于节点父代n’的g值的预测值rhs(n)(所有g(n’)+d(n’,n)的最小值)。同样,D*Lite通过两个 key 值来判断一个点的优先级,key 值越小优先级越高,先判断第一个 key 值再判断第二个 key 值,但是k1中的h是到起点S距离,注意起点S就是当前系统自己所在的位置:KEY={K1;K2}
K1=Min ( g(s), rhs(s)) + h(sstart , s) + km );
//这里初始Km=0;地图(路径不通)变化时Km=Km+h(s_上一点,s_当前点)
K2=Min (g(s), rhs(s))
先更新rhs,后更新g,公式中![]() 表示
表示![]() 到s的最优代价,刚开始,D*lite能够产生和A*一样的最优路径,尽管是反向算出来的。
到s的最优代价,刚开始,D*lite能够产生和A*一样的最优路径,尽管是反向算出来的。
正片开始
作者:斯文·凯尼格
乔治亚理工学院计算学院,亚特兰大,佐治亚州30312-0280 skoenig@cc.gatech.edu
摘要
增量启发式搜索方法使用启发式方法集中搜索,重用以前搜索中的信息,以比从头开始解决每个搜索任务更快的速度找到一系列相似搜索任务的解决方案。在本文中,我们将终身规划A*(LPA*)应用于未知地形下的机器人导航,包括未知地形下的目标导航和未知地形的映射。得到的D* Lite算法很容易理解和分析。它实现了与Stentz的Focussed Dynamic A*相同的行为,但在算法上有所不同。我们证明了D* Lite的特性,并通过实验证明了将增量搜索和启发式搜索相结合的优点。我们认为,这些结果为人工智能和机器人领域的快速重规划方法的进一步研究奠定了坚实的基础。
简介
增量搜索方法,如Dynamic SWSF-FP (Ramalingam & rep 1996),目前在人工智能中应用不多。它们重用以前搜索的信息,以找到一系列类似搜索任务的解决方案,比从头开始解决每个搜索任务要快得多。在(Frigioni, Marchetti- Spaccamela, & Nanni 2000)中给出了概述。另一方面,启发式搜索方法,如A* (Nilsson 1971),使用目标距离近似形式的启发式知识来集中搜索,比无信息搜索方法更快地解决搜索问题。概述见(Pearl 1985)。我们最近引入了LPA*(终身规划A*),它概括了DynamicSWSF-FP和A*,因此使用两种不同的技术来减少其规划时间(Koenig & Likhachev 2001)。本文将LPA*应用于未知地形下的机器人导航。在发现未知障碍物后,机器人可以使用传统的图形搜索方法重新规划路径。然而,对于经常使用的大型地形,最终的规划时间可以在几分钟左右,这就增加了大量的空闲时间(Stentz 1994)。Focussed Dynamic A* (D*) (Stentz 1995)是一种聪明的启发式搜索方法,通过mod-实现对重复A*搜索的一到两个数量级(!)的加速。
在本地修改以前的搜索结果。D*已广泛应用于真正的机器人,包括户外hmmwv (Stentz & Hebert 1995)。目前,它还被集成到火星探测器原型机和战术移动机器人原型机中,用于城市侦察(Matthies et al. 2000;Thayer等人2000年)。然而,它还没有被其他研究人员扩展。因此,在LPA*的基础上,我们提出了D* Lite,这是一种新的重新规划方法,它实现了与D*相同的导航策略,但在算法上有所不同。D* Lite比D*短很多,在比较优先级时只使用一个打破tie-break的标准,这简化了优先级的维护,并且不需要嵌套if语句,复杂的条件占用最多三行,这简化了程序流的分析。这些属性还允许人们很容易地扩展它,例如,使用不可接受的启发式和不同的打破联系的标准来获得效率。为了深入了解它的行为,我们介绍了LPA*的各种理论性质,这些性质也适用于D* Lite。我们的理论性质表明,LPA*是有效的,类似于A*,一个众所周知的和很容易理解的搜索算法。我们的实验性质表明,D* Lite至少与D*一样高效。我们还提出了在未知地形中,将增量搜索和启发式搜索结合在不同导航任务中的好处的实验评估,包括目标导向的导航和映射。我们相信,D* Lite的理论和实证分析将为人工智能和机器人领域的快速重规划方法的进一步研究奠定坚实的基础。
动机
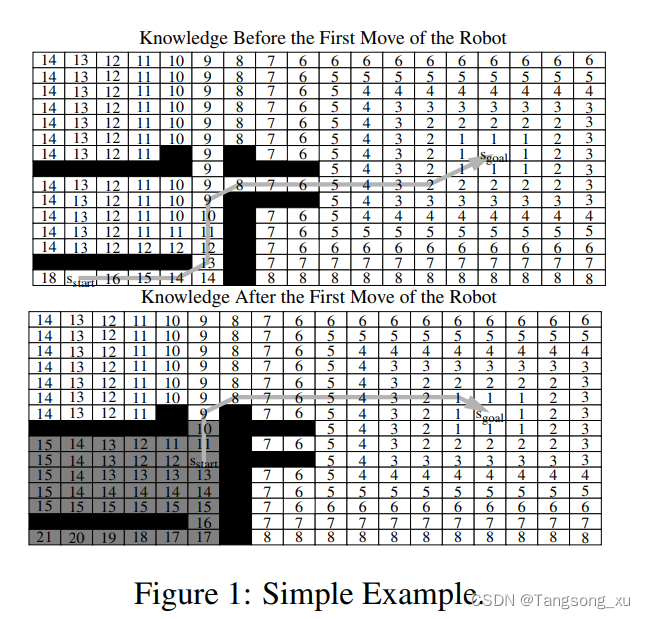
考虑一个未知地形下的目标导向机器人导航任务,在这个任务中,机器人总是观察它的8个相邻单元中哪一个是可以通过的,然后以1为代价移动到其中一个。机器人从起始单元开始移动到目标单元。它总是在可以通过未知阻塞状态的单元的前提下,计算从当前单元到目标单元的最短路径。然后,它沿着这条路径到达目标单元,在这种情况下,它成功地停止,或者它观察到一个不可遍历的单元,在这种情况下,它重新计算从当前单元到目标单元的最短路径。图1显示了所有可遍历单元的目标距离,以及机器人移动前后从当前单元到目标单元的最短路径,发现了它不知道的第一个被封锁的单元。目标距离改变的单元格为灰色。目标距离很重要,因为一旦目标距离计算出来,通过贪婪地减少目标距离,可以很容易地确定从机器人当前单元到目标单元的最短路径。注意,改变目标距离的单元格数量很小,大多数改变的目标距离与重新计算从当前单元格到目标单元格的最短路径无关。因此,只需重新计算那些已经改变(或以前没有计算过)且与重新计算最短路径相关的目标距离,就可以有效地重新计算从当前单元到目标单元的最短路径。这就是D* Lite所做的。目前的挑战是如何有效地识别这些单元。
终身规划A*:算法
终身规划A* (LPA*)如图2所示。LPA*是A*的增量版本。它适用于已知图的有限图搜索问题,已知图的边值随时间增加或减少(也可用于建模添加或删除的边或顶点)。S为图的有限顶点集。Succ(s)⊆s表示顶点s∈s的后继向量的集合。同样,Pred(s)⊆s表示顶点s∈s的后继向量的集合。0 < c(s, s')≤∞表示从顶点s移动到顶点s'∈Succ(s)。LPA*总是确定从给定起始点s开始的最短路径start ∈S到给定目标顶点Sgoal ∈S,既知道图的拓扑结构,又知道当前的边代价。我们用g∗(s)表示顶点s∈s的起始距离,即从s开始的最短路径的长度start 和A*一样,LPA*使用启发式h(s, sgoal)近似顶点的目标距离s。启发式需要非负且一致(Pearl 1985),即遵循三角形不等式: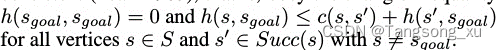

LPA*:变量
LPA*保存了每个顶点s的起始距离g *的估值g(s)。这些值直接对应于A*搜索的g值。LPA*将它们从一个搜索带到另一个搜索。LPA*还保留了第二种起始距离的估计。rhs
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1370
1370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









