







UE资产优化
课程大纲
性能查看
- 整体指标
- 瓶颈定位
- Stat命令行
- Engine Scalabiity Setting
分模块优化
- 模型 +Nanite
- 材质与贴图
- 灯光与阴影 +Lumen
- 特效
目标:面向TA,美术,不影响视觉的前提下,优化运行和编辑效率
引擎:UE5.1延迟管线
平台:主流PC,Windows 10 with DX12
性能查看
整体目标
Stat FPS
在编辑器的控制台命令行中输入Stat FPS,可以看到当前场景运行的帧率,以及可以换算过来的实际生成每帧画面具体用了多少毫秒。
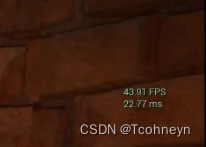
-
fps vs .ms
ms是更线性的指标
更适用于在同一平台上检查各feature的消耗。
还有一点需要注意的是在做具体的性能优化工作之前,我们需要把项目设置中的Smooth frame rate选项关闭掉,这个功能会尽量避免运行时帧率的峰值。如果开启我们在场景中各个区域做检查时可能会掩盖一些问题。
**Stat Unit**Graph
Stat Unit这个命令可以将前面帧率这个整体指标做进一步的拆解。
- Game:CPU,物体位置变换,交互,动画及物理相关
- Draw:CPU为GPU做绘制前的数据准备
- GPU:实际绘制的消耗
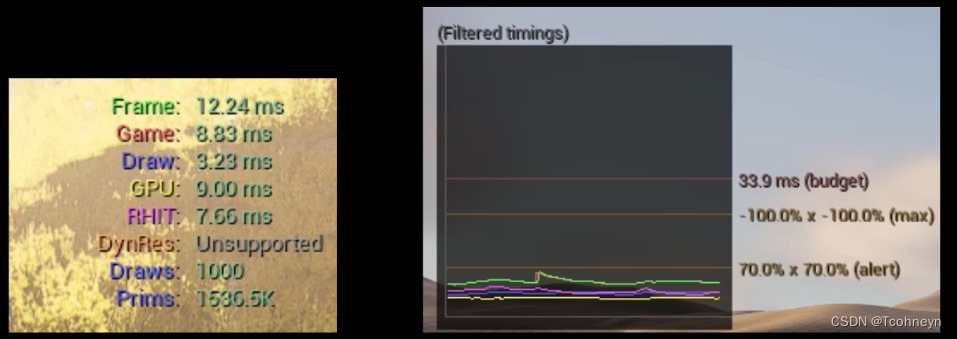
可以看出三个线程有大部分的并行内容,所以我们就可以简单通过几个线程耗时的对比,哪部分的消耗和最终的Frame消耗更接近来定位这个瓶颈。然后再考虑具体使用哪些优化手段。
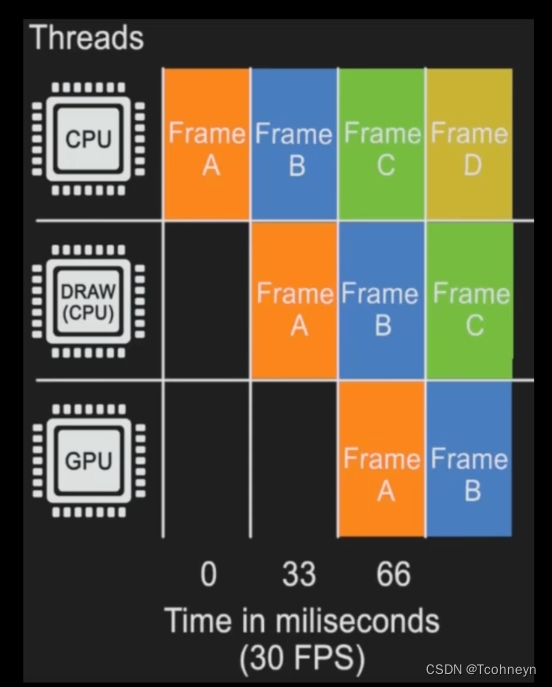
如果我们在Stat Unit后面加个graph,就可以在一定的时间窗里,把几个线程的消耗变化绘制出来。这样可以很方便的在场景当中变化视角来检查出问题的区域。

每个线程各个步骤的工作细节也有专门的指令来进行性能查看。
**Stat SceneRendering**渲染线程
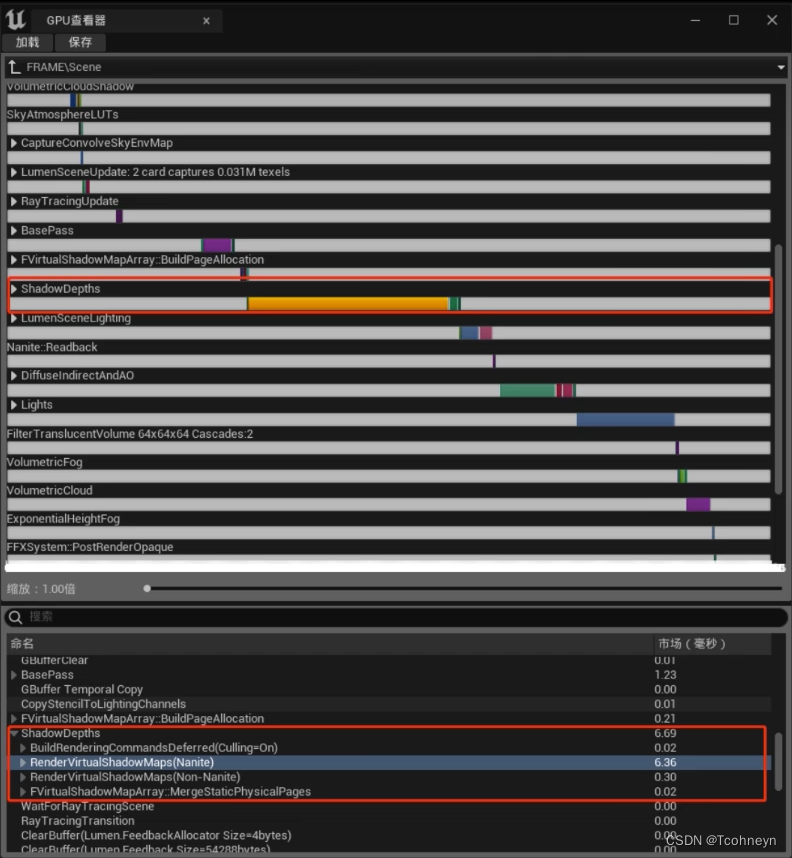
如果瓶颈在渲染线程可以通过Stat SceneRendering命令检查渲染线程各部的实际消耗,以及它收集到的场景的渲染信息。
- Decals(贴花),Light in scene(动态灯光的数量)
- Mesh draw calls(CPU生成的模型的 Drawcall数量)
- GatherRayTracingWorldInstances(Lumen光线追踪时收集场景信息的消耗)
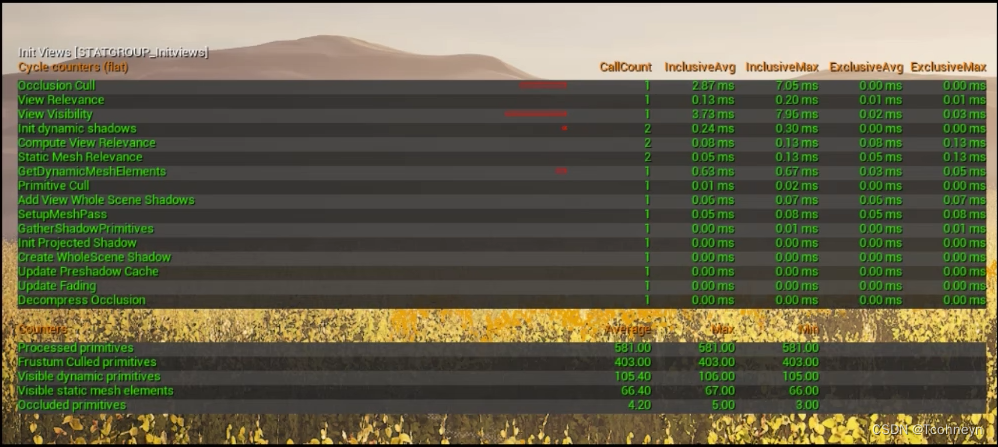
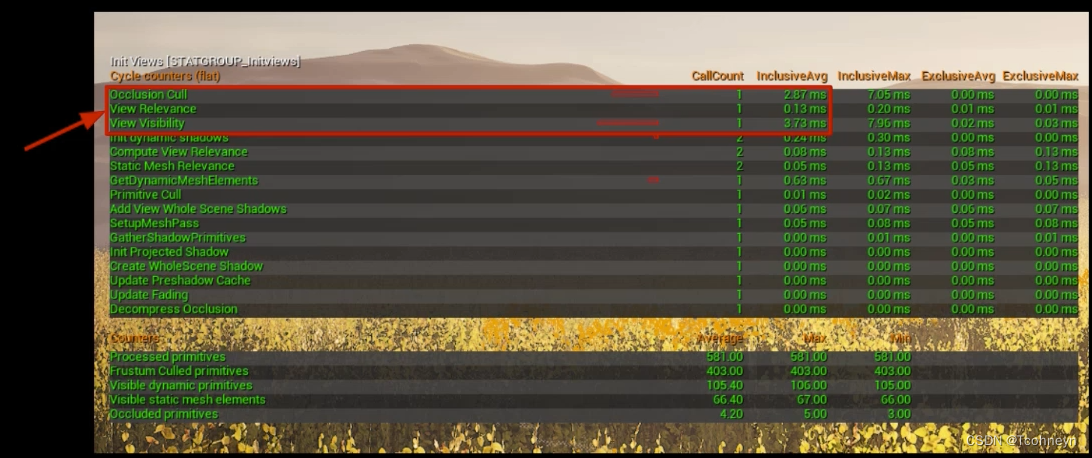
- InitViews(做物体可见性剔除时的消耗)
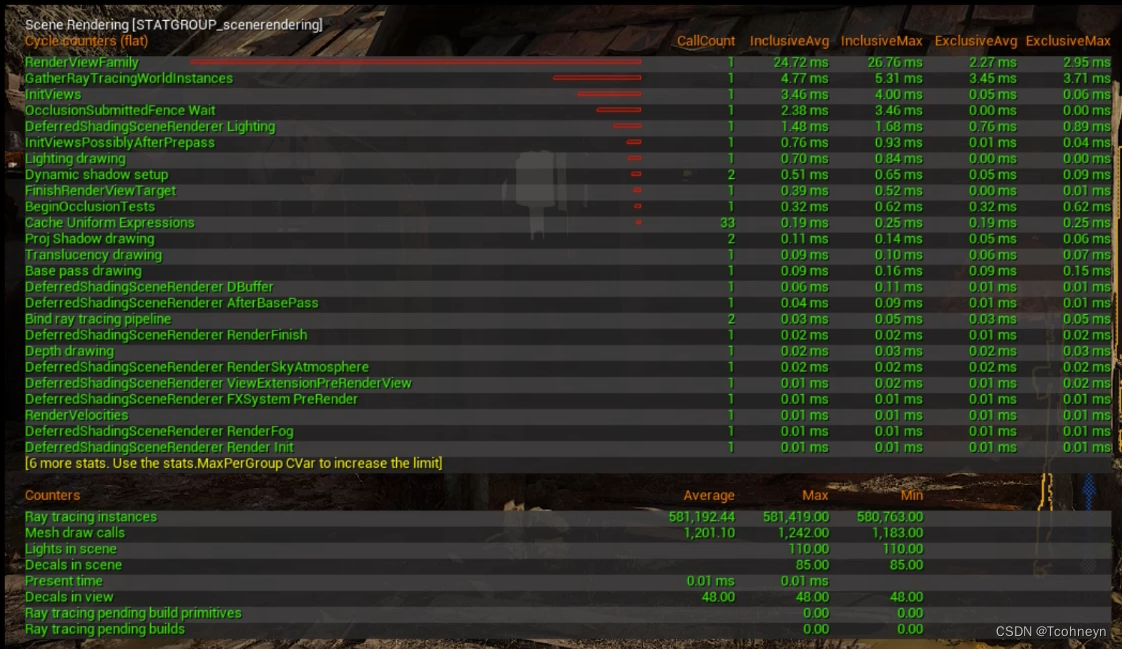
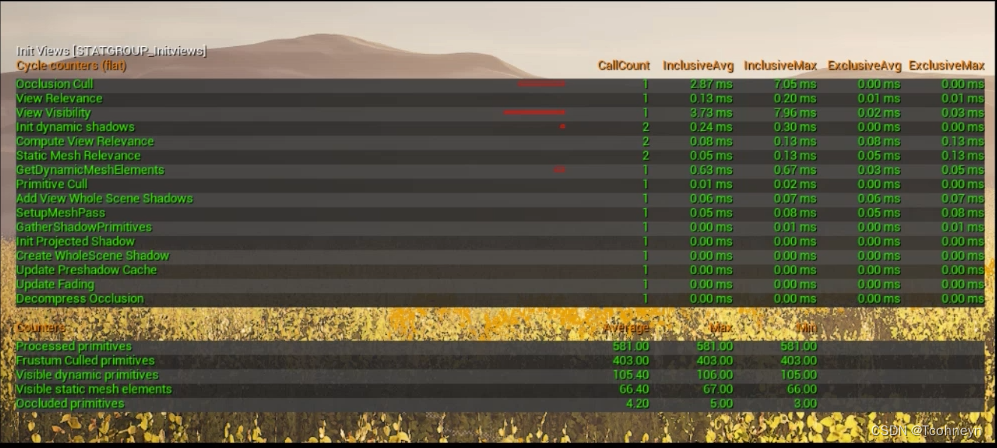
Stat InitViews
可以通过Stat InitViews命令进一步把它的详细步骤展开。
渲染线程——>Culling
- View Visibillity,Occlusion Cull:效率,剔除计算消耗
- Processed,Frustum Culled,Occluded:效果,剔除前后数量变化
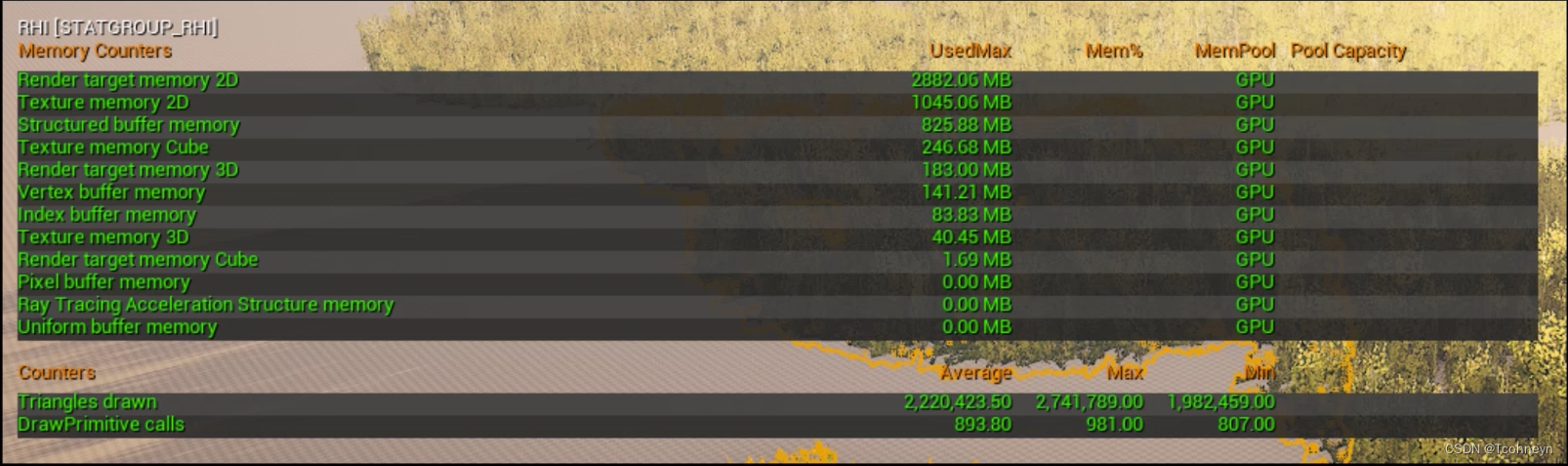
Stat RHI
Stat RHI可以帮我们查看各个Buffer在显存中的占用,渲染视图的GBuffer还有阴影贴图都包含在最上面的这个Render target memory里。下面的Texture memory是材质中用到的纹理,后面还有顶点Buffer的存储量等等。
当我们的硬件显存不高时,就需要重点关注这里,看看哪部分的消耗比较大,相应的来缩小项目的纹理大小标准。或者调整一下灯光的阴影质量。
RHI这个命令还包括Drawcall提交相关的内容,下半部分可以看到最终提交渲染的面数和Drawcall的数量。这里的DrawPrimitive calls跟前面的SceneRendering 中的MeshDrawcall相比还包括了贴花,阴影以及后处理提交的Drawcall数。
Drawcall是做性能优化的一大重点,通常会比控制面数还要重要。它是发送给GPU的渲染批次,一个Grawcall内一般是一组属性相同的多边形。渲染时会通过同样的处理过程。然后,不同的平台上合适的Drawcall指标也大不相同。
- Memory:渲染尺寸 阴影质量 纹理尺寸等与显存平衡
- 渲染面数,Drawcall
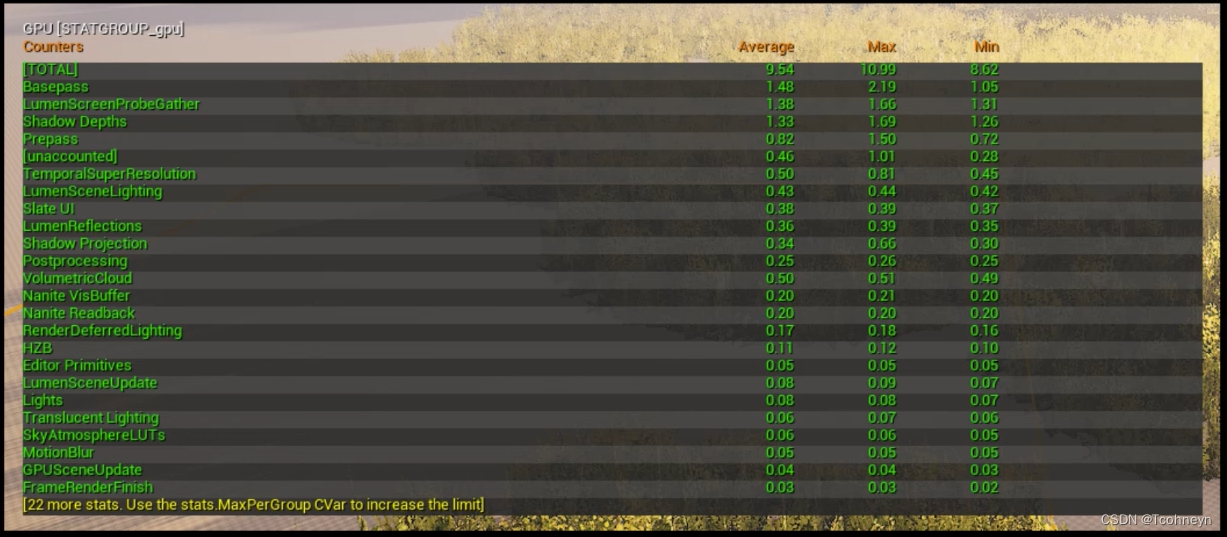
GPU
Stat GPU
如果性能瓶颈在GPU上,我们可以通过Stat GPU命令查看GPU绘制各个Pass的实际消耗。
查看各个Pass的消耗
- Prepass(深度信息的预绘制),Shadow Depth(阴影贴图的绘制消耗)
- Basepass(生成屏幕的GBuffer的消耗)
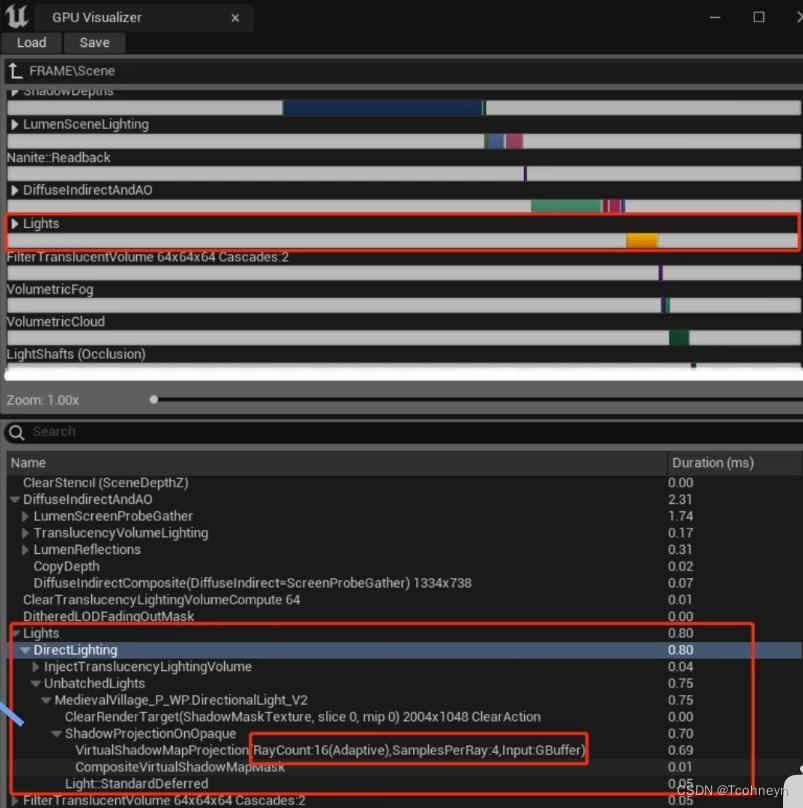
- Lights(灯光的光照计算)
- …
更直观细致的:
在编辑器中使用快捷键 ctrl+shift+,,可以打开一个更直观的GPU查看器。
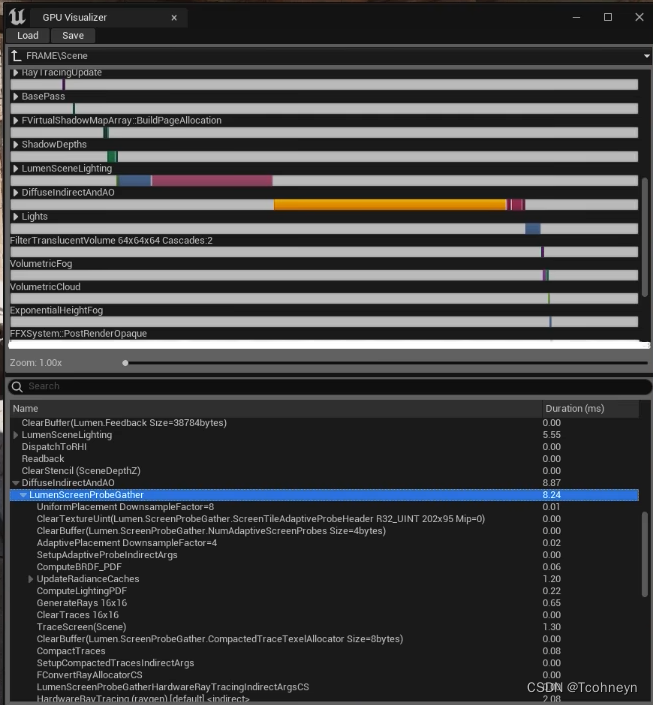
GPU Visualizer
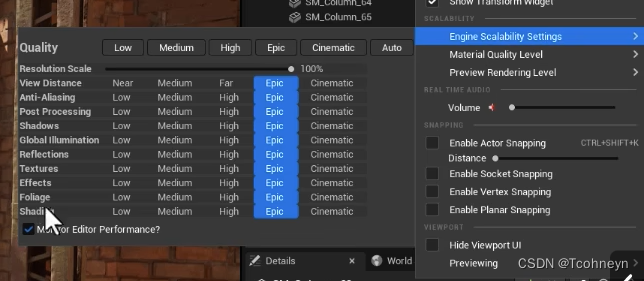
Engine Scalabiity Setting
编辑时卡顿较低点质量提高帧率。
模型
模型:优化思路
- Culling 只提交实际可见的primitive进行渲染 ↓ \downarrow ↓
- Drawcall 场景模型的拆分——>模型内材质数量 ↓ \downarrow ↓
- Quad Overdraw 基于屏幕占比控制三角形密度 ↓ \downarrow ↓
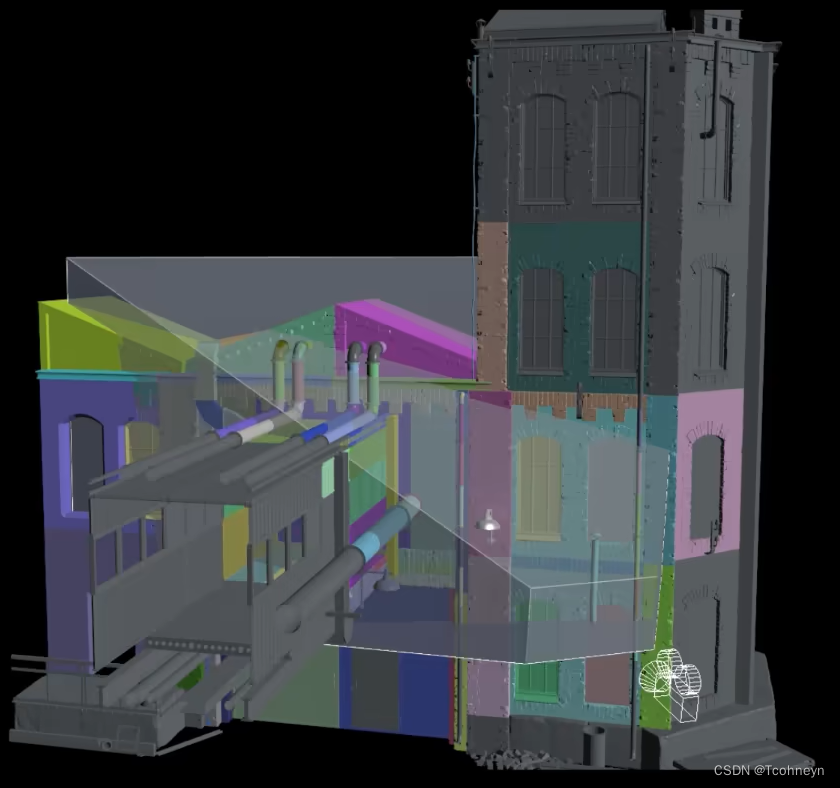
模型:Culling
Non-Nanite
逐物体/Instance剔除
对于非Nanite的物体来说剔除的单位是物体的组件或实例
它的效率一方面可以通过前面的Stat InitViews来进行查看。
r.VisualizeOccludedPrimitives 1
另外,也可以通过r.VisualizeOccludedPrimitives 1这个命令行来进行直观的查看。

优化:
- 大场景的距离剔除设置
从美术方面来看这部分的优化一个是大场景需要尽量按视觉重点合理的来设置不同物件的剔除距离。距离剔除的计算很简单,而且发生在遮挡性剔除之前。像场景中细小的道具,或者是地平线上比较小的植被,都可以通过距离剔除提前的优化掉。
- 合理进行模型拆分
另一个方面就是场景的模型需要拆的多细。如果在Stat InitViews中我们看到实际剔除的计算量就已经很大了,也许这时候就要考虑把模型做一定的合并。这部分后面我们讲Drawcal的时候还会再说。
Nanite
逐Cluster剔除
效果,效率都更高
如果模型是Nanite的模型,它的剔除就相对来说高效很多。剔除的单位就不再是单个的物体,而是会细化到模型内部相邻三角面组成的Cluster,而且剔除的工作大部分是在GPU上高速完成的。
我们可以在VIEW MODE>Nanite Visualization>Clusters下进行查看,这些不同颜色的Clusters就是在提交渲染前做剔除的最小单位。随着视角的变化三角面的Cluster也会重新计算,这样就大大减少了实际进行光栅化绘制的三角面。

模型:Drawcall
Drallcall的划分(Non-Nanite)
- 场景中,不同的Object,Component
- 模型内,不同的LOD层级,材质
- ISM按种类,HISM按种类以及LOD
模型的拆分
- Culling效果和Drawcall数量间平衡
从制作角度来说,这里最重要的问题是模型应该怎么拆。比如说建筑是每面墙都是一个Mesh好,还是整个房间是一个Mesh比较好。整体的情况Drawcall的数量会少一些,但从前面剔除的效率来考虑的话,又无法剔除掉很多小物件会浪费渲染资源。相反的如果我们把模型拆的过于细,如果都是相同的模型拼接起来的还好。但如果每一个Mesh都是一个单独的模型这里就会造成Drawcall的数量过多。这时候我们就要评估是否要进行actor的合并。
从工作流上来说,对于PC的平台还是不要提早的优化,我们都从模块化的模型做起。最终场景物件过多时,比如有几万个不同的模组类型,这时候我们在考虑是否要进行actor的合并。而且引擎中也有很方便快捷的actor合并工具。
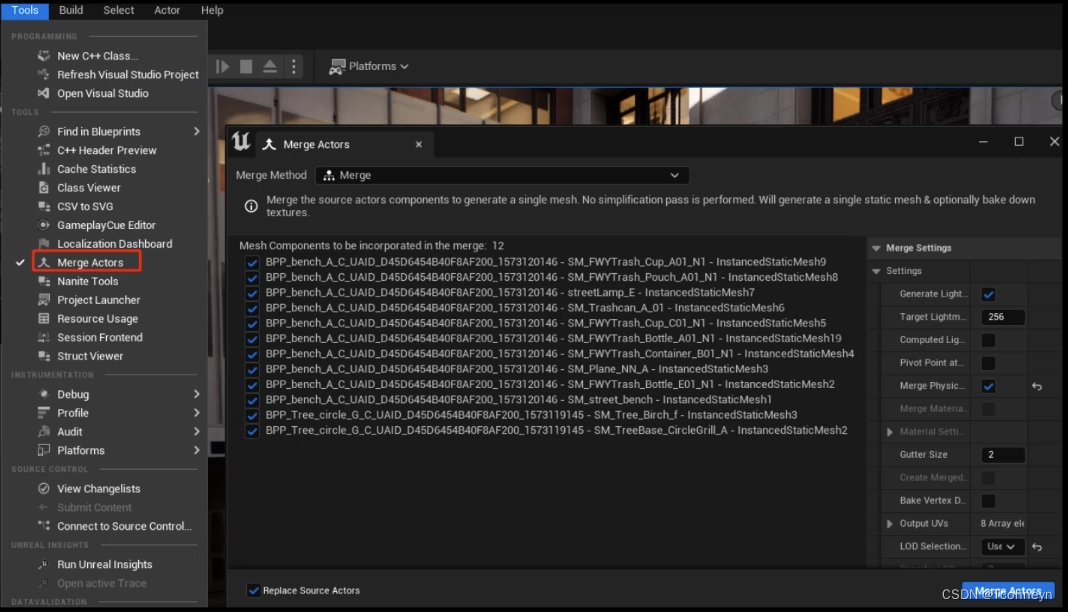
- 模组做起,后期看情况合并
- 多用Instance
另外,我们搭建场景的时候也要多考虑Instance的方案。以黑客帝国的项目为例,它是用程序化拼接的方案来搭建的整个场景。场景中有百万级别的Instance,但实际上整个工程单独的模型数量并不会过多,所以Drawcall的负担也不会太重。
Nanite的模型拆分
- 同类材质可高效合并
- 注意加载效率,内存占用

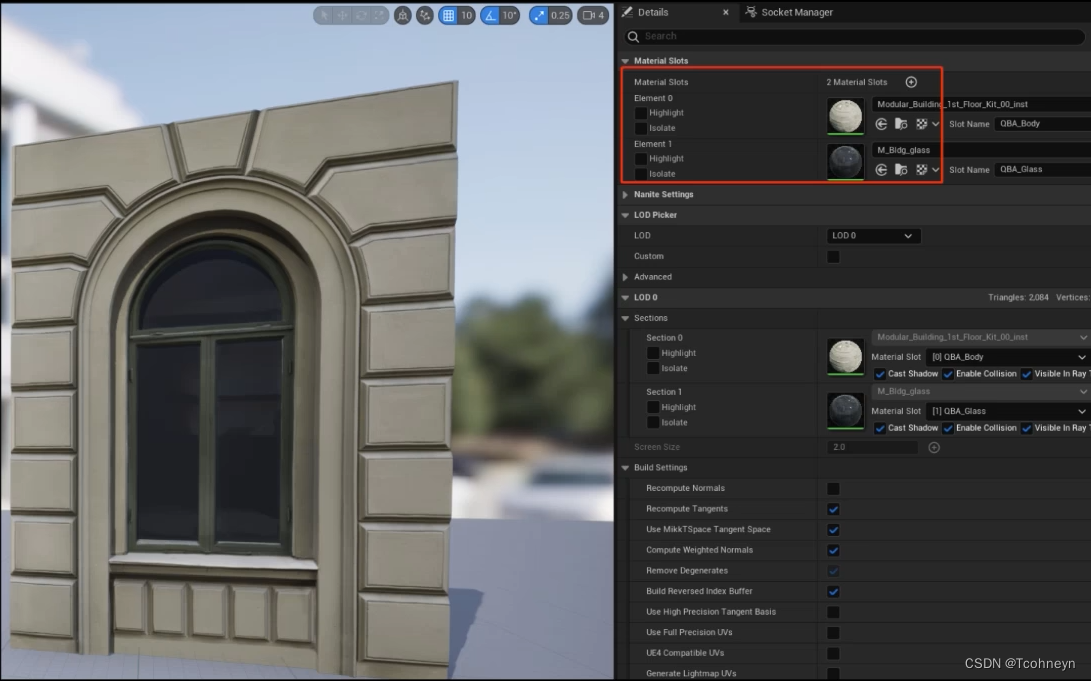
单个资产优化(Nanite同样)
- 减少材质Elements
- 低精度LOD上的材质进一步合并
模型:GPU
Quad Overdraw
三角面密度超出像素精度太多,光栅化过程有大量的浪费,这种情况主要发生在模型远离相机屏幕的占比缩小时。
- GPU:Prepass,Basepass,Shadow depth
- Optimization Viewmode
方案:LOD 依赖经验
引擎有自动的LOD生成功能以及进行批量设置的方案。
实例展示看视频
- 按模型重要性,精度,类别设置
- LOD级数合理
- 可能需要对LOD重新建模
↓ \downarrow ↓
Nanite
无级LOD
更细致的三角形密度控制
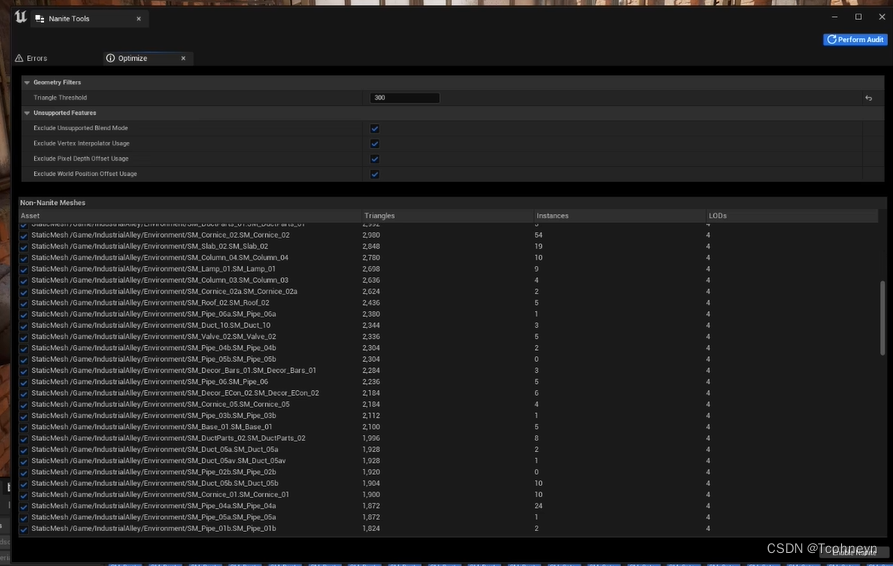
引擎有Nanite工具可以更细致的筛选模型进行启用,有面数的过滤和材质类型的过滤。
这里把面数300的模型都批量启用,GPU的消耗大大减小。
模型:Nanite
-
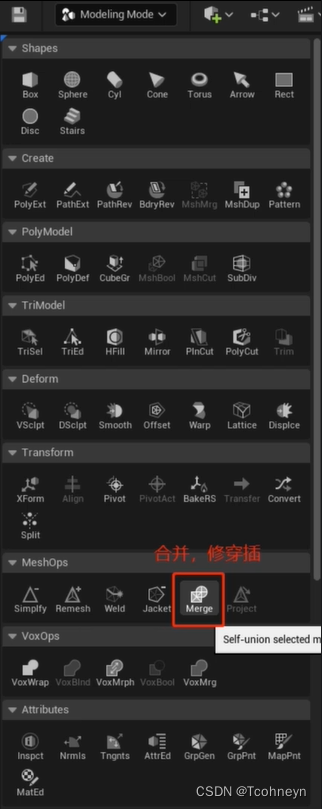
拓扑月均匀越好处理,看效果优化
-
多层堆叠的mesh处理不好,尽量规避

-
模型内部尽量少穿插
boolean union(离线dcc或引擎建模工具处理)
顶点数
- 减少不必要的hard edge/光滑组
- uv不宜切的过碎
属性数
- 减少UV sets,非必要不生成lightmap UV
5.1更新
-
支持WPO:r.OptimizedWPO
-
仅必要时开启,按相机距离设置(尤其是对于远处植被的风动)

-
简化WPO的计算逻辑
-
-
支持Masked材质:性能开销较大
参考Fortnite优化经验:
Bringing Nanite to Fortnite Battle Royalein Chapter 4
材质纹理
这部分的消耗主要在GPU和内存上,VIEW MODE>Optimization Viewmodes>Shader Complexity,是专门衡量材质复杂度的视图模式。需要注意红色再往上的这些区域是要避免的。红色部分一般是半透的材质居多。

材质:GPU
除了半透明物体,材质复杂度上升的另一主要原因就是材质指令数太高了。
材质复杂度:指令数控制
- 材质编辑器Stat窗口来查看当前材质用到的指令数,这个指令数不只是包含了当前编辑器里用到的所有节点,还包含不同光照模型,不同复杂度的光照计算产生的指令数,主流PC参考:
- 300左右 正常
- 500+ 优化
- 1000+尽量减少
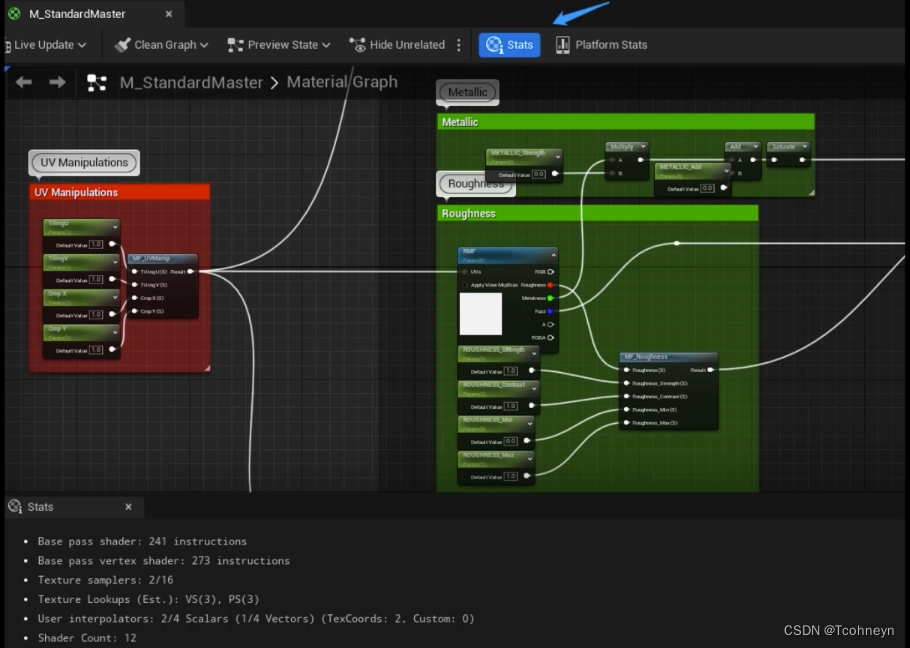
材质指令数优化
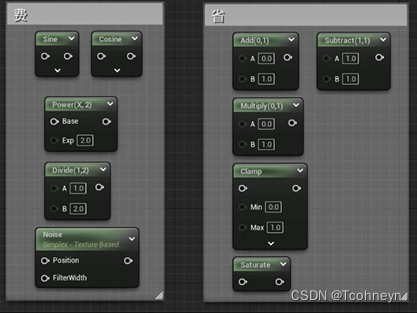
- 避免一个复杂材质覆盖所有需求,用StaticSwitch做分支
- 注意不同节点的指令数消耗
- 光泽度不高的材质可用fully rough简化,节省指令数
- 简化多pass的半透明材质,粒子尽量Unlit
纹理:Streaming 内存
纹理除了本身的材质指令消耗,纹理还需要等待Steaming进来的时间。
优化
- Pack通道节省采样数
- 压缩格式可以大大减少显存的占用
- 不能压缩时控制精度
灯光阴影
直接光:优化防向
- 光照计算复杂度
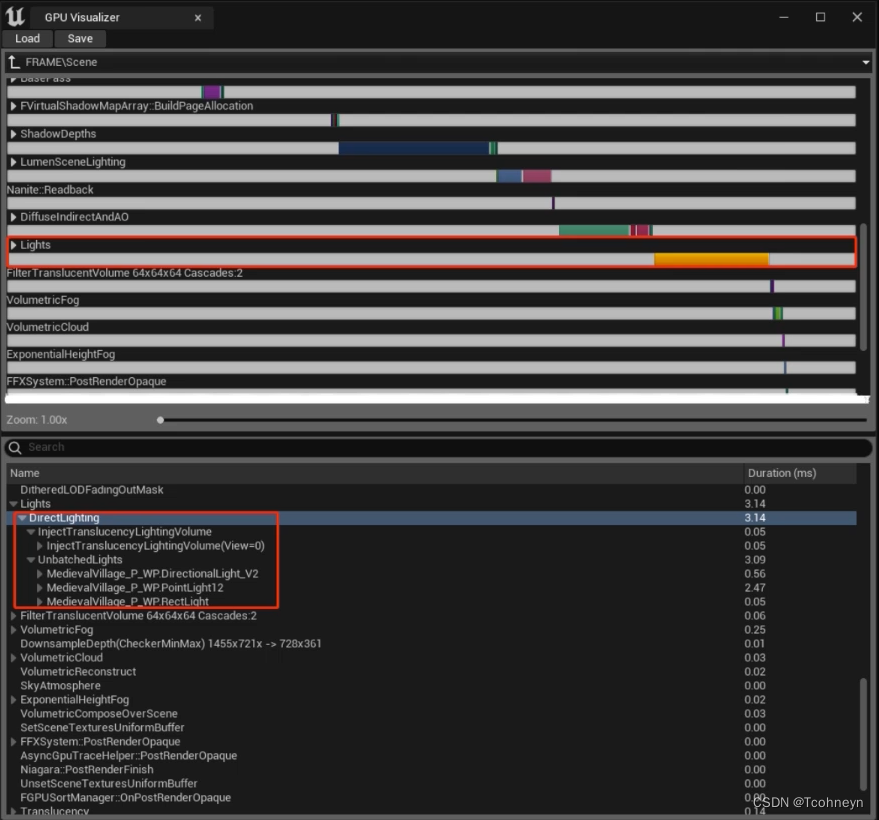
-
灯光类型:节省面积光的使用
-
设置spot/point light的max draw distance
-
控制动态灯光的影响范围,减少重叠区域
Attenuation Radius,Cone Angle
我们可以通过灯光复杂度这种视图模式来检查这些区域。红色区域是重叠区域。
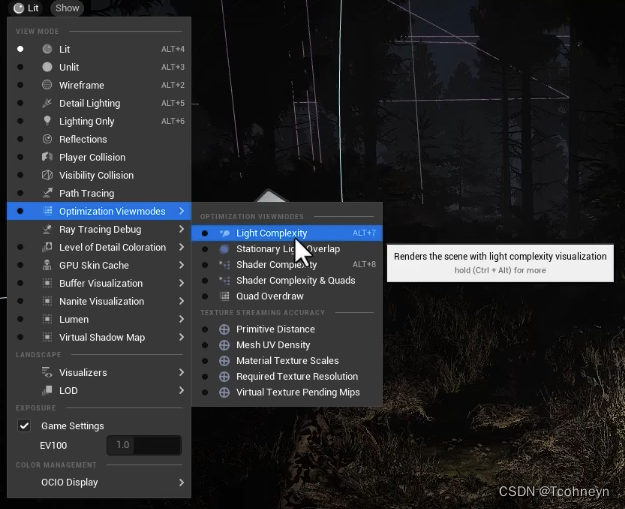

- 阴影质量:
原理:直接光阴影的主要绘制方式是从灯光方向来绘制场景的深度,计算光照时在屏幕空间通过深度的比较来判断是否在阴影中。
绘制范围,影响的物体,绘制精度
-
不同类型阴影开销:Point>Directional>Spot
-
减少投射阴影的模型数量
-
VSM虚拟阴影
- 与Nanite协作
- 高效缓存Cached page
-
VSM
纹理池上限
r.Shadow.Virtual.MaxPhysicalPages(4096)
Lod精度偏移
r.Shadow.Virtual.ResoulutionLodBiasDirectional
r.Shadow.Virtual.ResoulutionLodBiasLocal
-
VSM
SMRT:阴影贴图光线追踪
-
光线数量 半影的区域如果噪点可以接受,可以适当调低一些光线追踪数,默认是16
r.Shadow.Virtual.SMRT.RayCountLocal
r.Shadow.Virtual.SMRT.RayCountDirectional
-
逐光线采样数 然后每根光线的采样数越高,阴影会越柔和,代价也会更高
r.Shadow.Virtual.SMRT.SamplesPerRayLocal
r.Shadow.Virtual.SMRT.SamplesPerRayDirectional
-
Lumen与资产制作
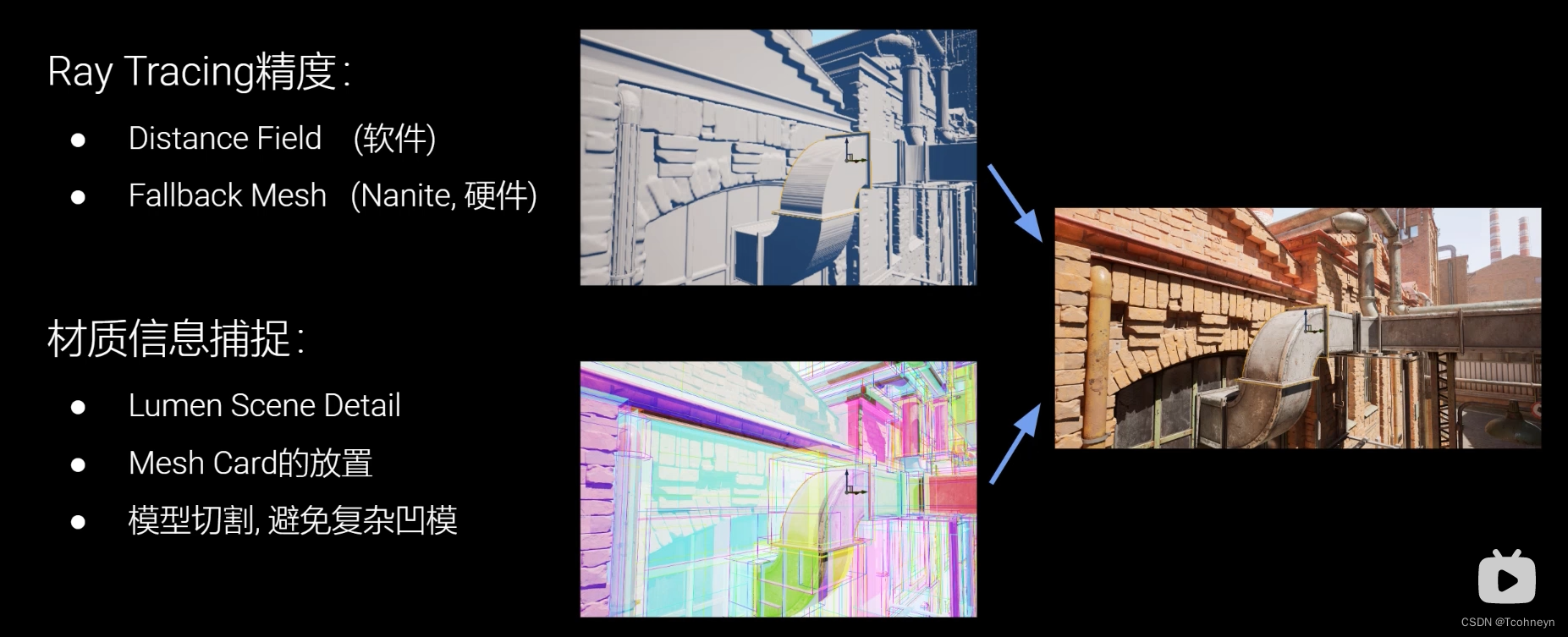
具体演示看视频
Lumen光追效率
- 优化重建光追加速结构的开销
- SkeletalMesh,破碎,毛发,Niagara…注意面数!
- Static Mesh WPO 限制开启区域!
- 必要时再添加
- 按相加距离开启/关闭
r.RayTracing.Geometry.StaticMeshes.WPO.CullingRadius(5000)
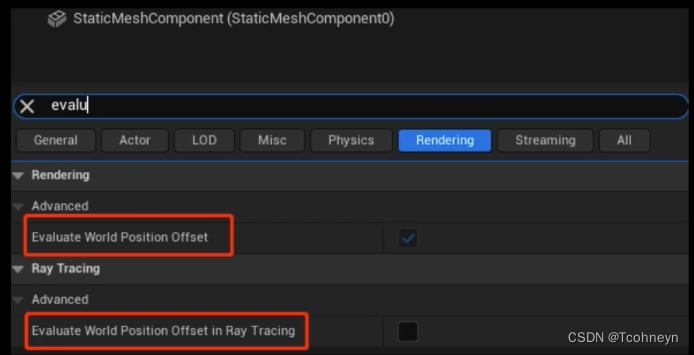
- 优化对视窗外物体的追踪
-
按角度和距离剔除
r.RayTracing.Culling
r.RayTracing.Culling.Radius 10000(100米)
r.RayTracing.Culling.Angle 1(5度)
-
设置光追组整体剔除
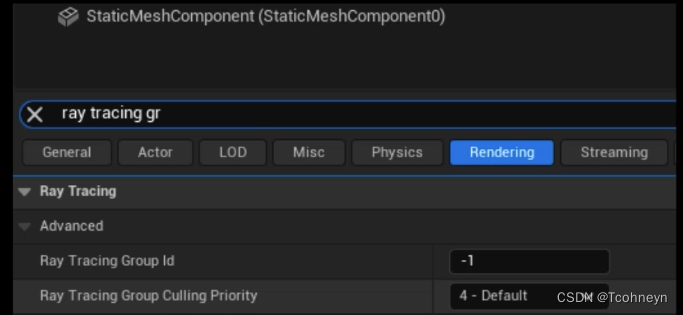
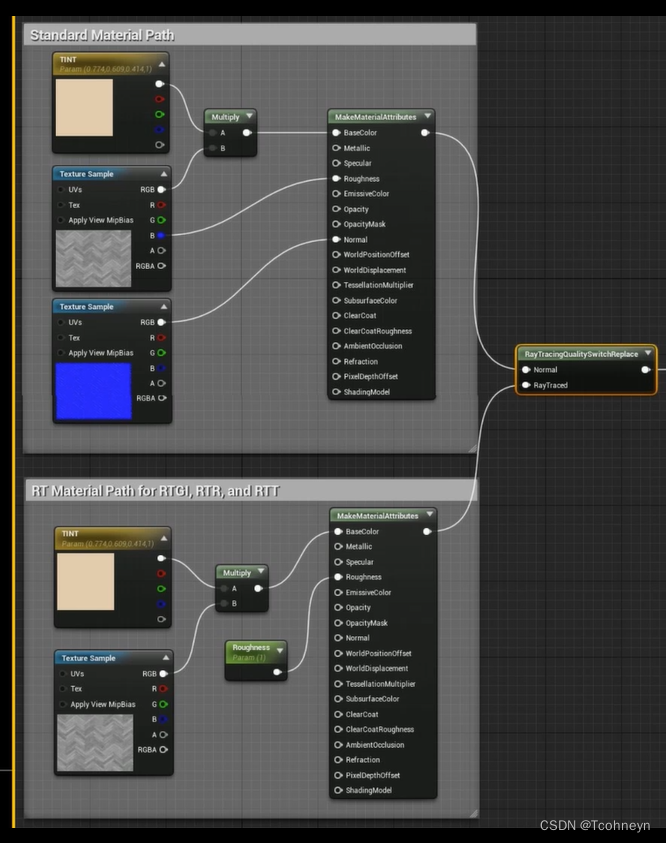
-
简化光线击中表面时的材质计算
RayTracingQualitySwitch:
- Normal:Gbuffer中的计算逻辑
- RayTraced:LumenScene中的材质计算
特效
特效的大部分优化都是在Effect Type上分类别进行设置的。
Niagara:优化方向
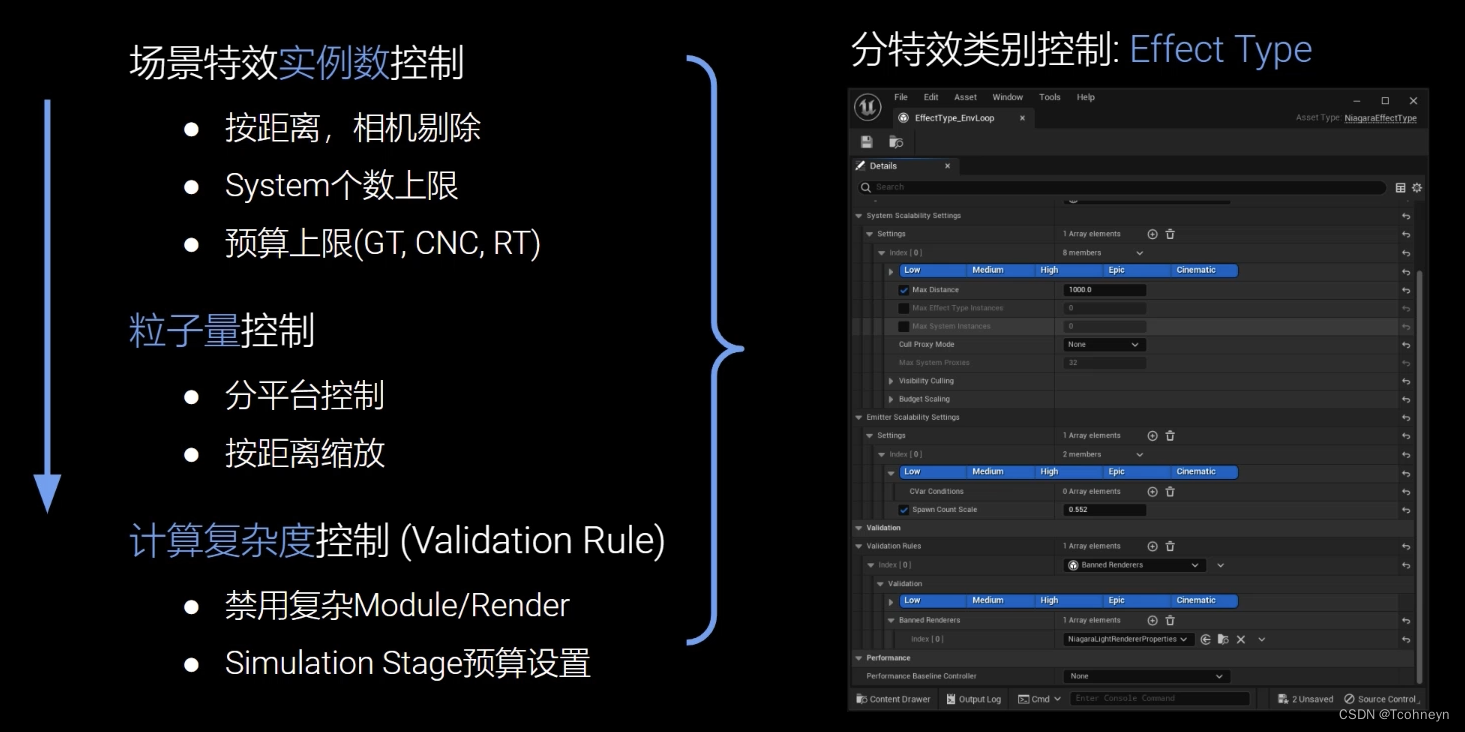
具体演示看视频















 1605
1605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









