







笔记整理:张孟垚,浙江大学硕士,研究方向为人工智能+X
链接:https://dl.acm.org/doi/10.1145/3485447.3511945
1. 动机
实体对齐是构建web级知识图谱的一个基本问题,它旨在识别不同知识图谱(KGs)之间的等效实体。标签监督被认为是精确校准的必要条件。受到最近自我监督学习进展的启发,探索在多大程度上摆脱监督实体对齐。通常,标签信息用于监督将每个正对中的实体拉得更近的过程。然而,论文的理论分析表明将未标记的负实体推远比将标记的正实体拉近更有益。通过利用这一点,文中发展了自监督的方法,SelfKG以对齐没有标签的实体。在基准数据集上进行了大量实验,SelfKG没有监督也可以达到很好的效果。
2. 方法
统一空间学习的方法已经被近期的监督或者半监督技术采纳。文中利用统一空间学习来支持SelfKG的自监督学习,将不同KG的实体嵌入到统一空间,对实体对齐任务有很大帮助。
为了学习没有标签的信息,SelfKG的主要目标是设计一种可以指导学习过程的自监督目标,在文中提出相对相似度量:
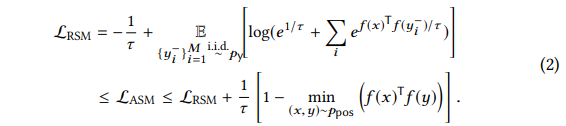
优化LRSM也就是在向量空间上,将负样本对推远。也就是说在无法把正样本对拉近的情况下,可以把负样本对推远。
负采样时,没有对标签感知的负样本采样的监督,底层的对齐实体很可能会被采样为负样本对,也就是碰撞发生。通常情况下,仅有一小部分负样本采样,这种碰撞可被忽略,但是负样本数量较多时,就会影响效果。为减轻此影响,考虑到Gx和Gy具有统一空间,提出从Gx里面提取x的负样本,为避免碰撞,简单去除x,这就是自负采样的策略。
然而,有两个问题同时出现。由于真实世界的数据质量,一个x实体在Gx可能有多个副本,这些可能被采样为负样本。同时也会有许多y的副本存在于Gy。通过一些证明,发现一定数量的噪声不会影响NCE loss。
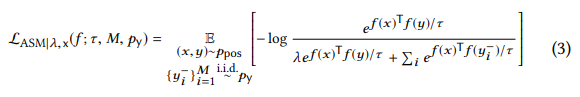
Noisy ASM表示如公式3所示,设定平均复制因子以及τ为常数,在绝对偏差衰减o( )的情况下,仍然可以收敛到相同的ASM的极限。
扩大负样本的数量会增加计算代价,为了解决这个问题,文中提出扩展MoCo的技术。为适应SelfKG的负样本采集策略,文中保持了两个负样本队列关联着两个输入KG。如图3所示。
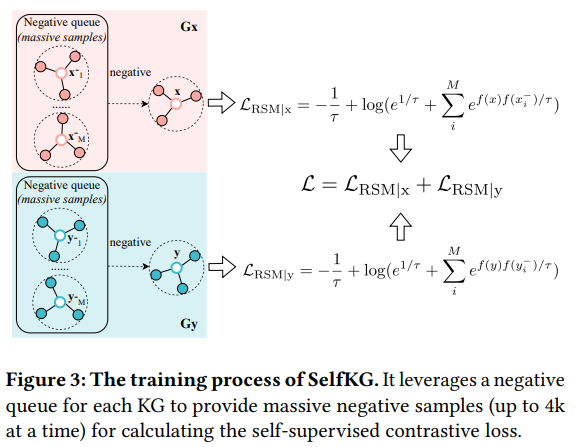
先不更新梯度,知道其中一个队列达到预定义的长度1+K,其中”1”是指当前的批次,K指之前批次的数量,之前的批次作为负样本。|E|作为KG里面的实体的数量,批次数量N受到的限制如公式6所示。
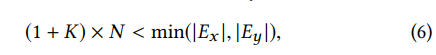
保证了不会在当前批次进行采样,因此,真实的用于当前批次的负样本数目是(1+K)*N-1。
负样本队列带来的主要挑战是相对过时的编码样本,尤其是那些在早期训练阶段得到的编码样本,在这期间,模型参数变化较剧烈。因此,端到端的训练,如果只使用一个encoder,可能会损害模型的效果。为了缓解这个情况,文中采用动量训练策略,维护了两个encoder,online encoder 和 target encoder。其中online encoder的参数随着反向传播同步更新,target encoder用于编码当前批次,然后加入到负队列,并进行异步更新。
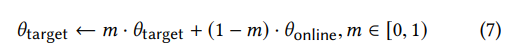
3. 实验
在DWY100K和DBP15K的数据集上进行实验。
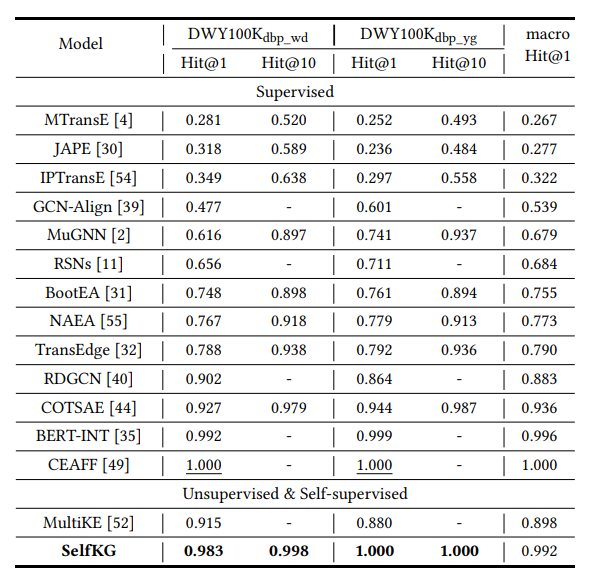
实验在DWY100K数据集上达到sota。
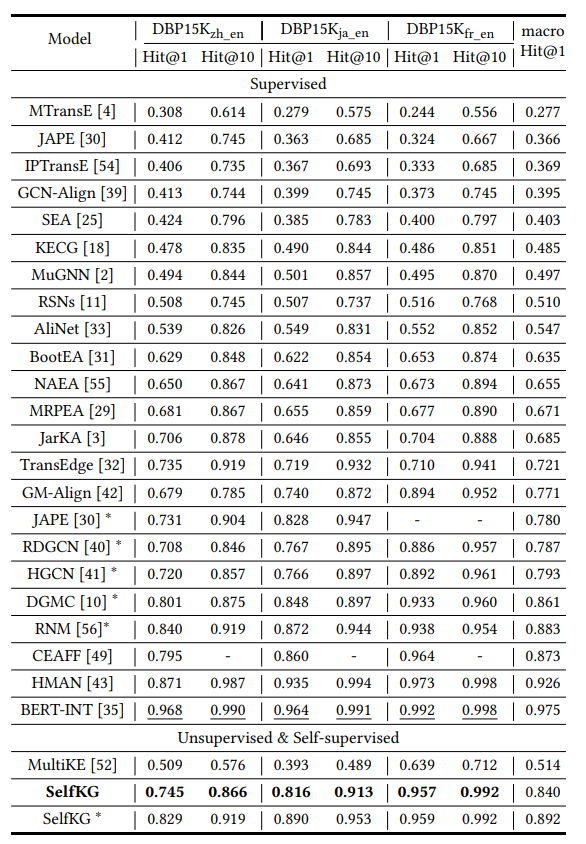
在DBP15K数据集上也达到sota。
4. 总结
这个工作重新审视了自监督在实体对齐任务中的使用和影响。基于统一空间,相对相似度,自负采样发展出自监督实体对齐算法SelfKG, 并在DWY100K和DBP15K的数据集上进行实验,达到很好的效果。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









