






转载公众号 | 老刘说NLP
我们来看两个问题,一个关于大模型与知识图谱结合的几个综述;另一个是基于大模型进行图谱构建的4个策略对比。
这两个问题都具有指引性,大家可以多关注。
问题1:关于大模型与知识图谱结合的几个综述
1、中文期刊综述:《图模互补:知识图谱与大模型融合综述》
本文系统性地介绍知识图谱与大模型融合的方法,分别从1)大模型增强知识图谱,2)知识图谱增强大模型,两个角度进行全面的回顾和分析。最后,本文从医学诊断预测和时间知识图谱出发,介绍图模互补的领域应用,并讨论图模互补未来发展的方向。

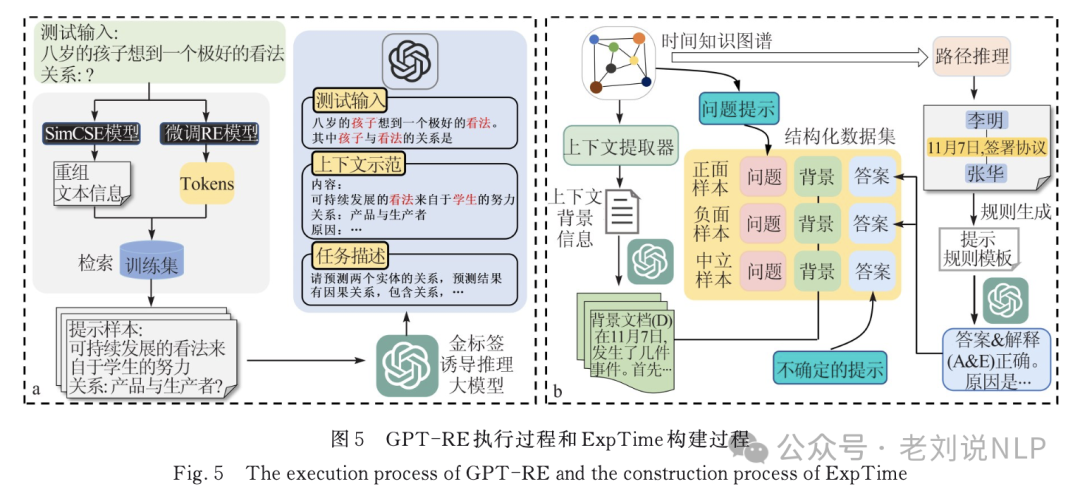
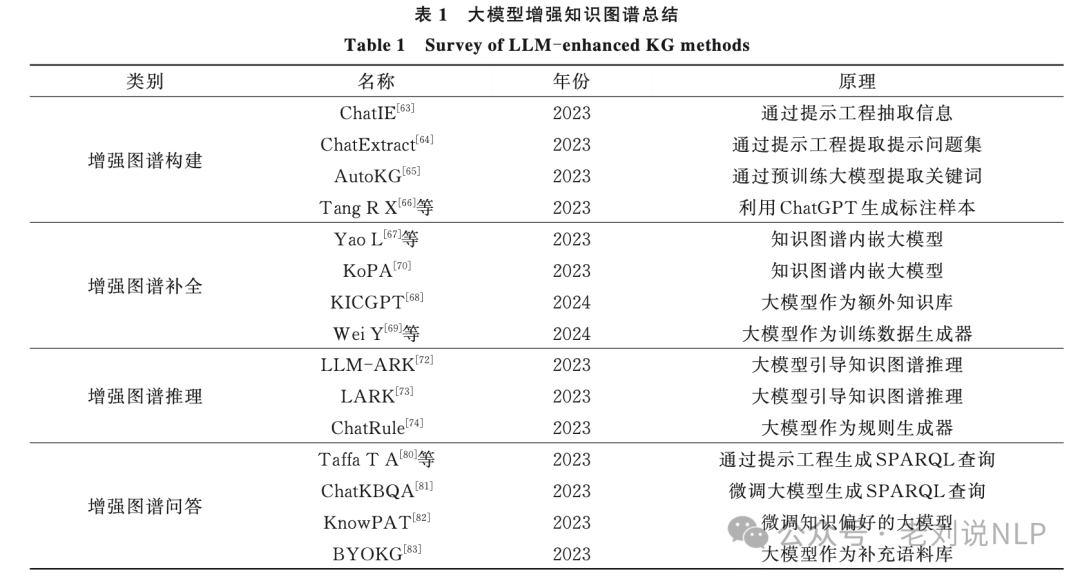
地址:http://xblx.whu.edu.cn/previewFile?id=58539306&type=pdf&lang=zh
2、英文综述《Unifying Large Language Models and Knowledge Graphs: A Roadmap》
去年的一个很火的文章,主要提出了一个前瞻性的道路图,用于统一LLMs和KGs。我们的道路图包括三个通用框架,即:
1)知识图谱增强的LLMs,在LLMs的预训练和推理阶段或为了增强LLMs学习的知识理解中纳入知识图谱;
2)LLM增强的知识图谱,利用LLMs进行不同的知识图谱任务,如嵌入、补全、构建、图到文本生成和问答;
3)协同的LLMs+KGs,在其中LLMs和KGs扮演平等的角色,以互惠互利的方式工作,通过数据和知识驱动的双向推理来增强LLMs和KGs;
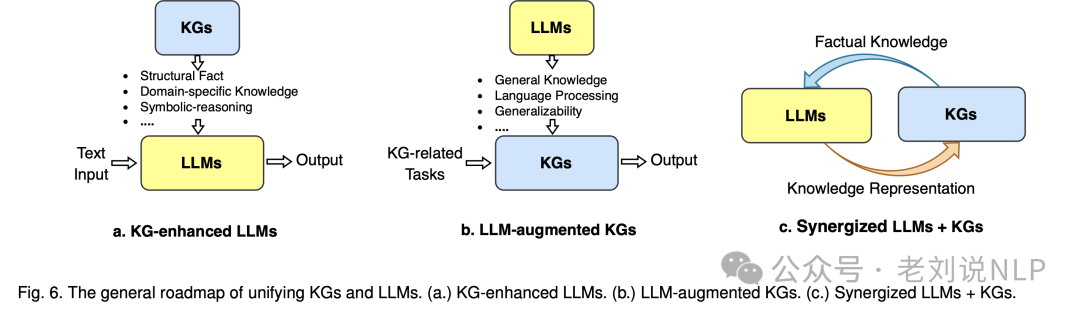
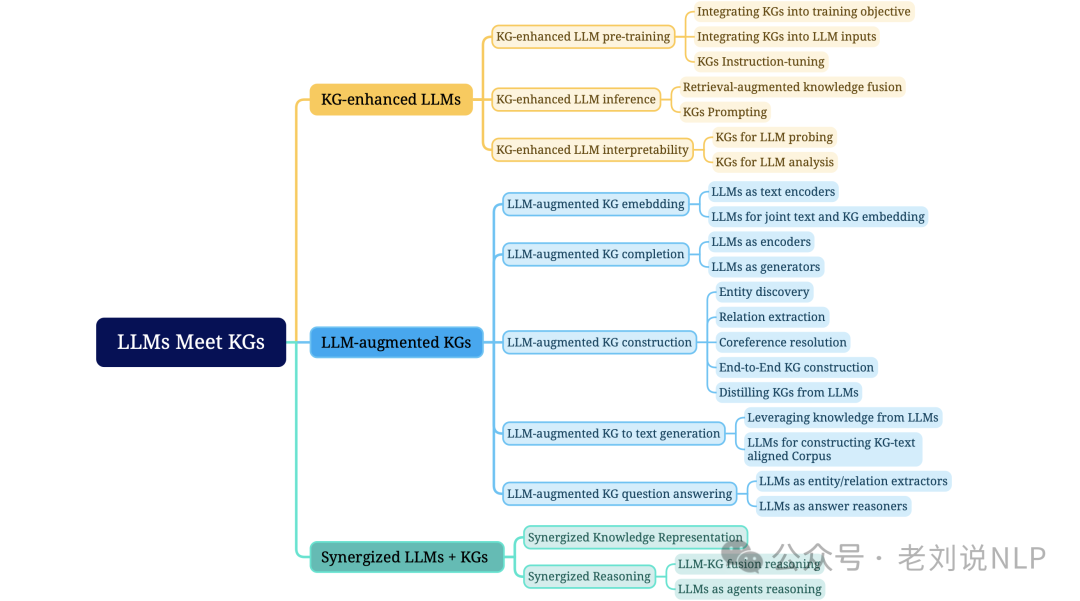
地址:https://arxiv.org/pdf/2306.08302
3、英文综述《Research Trends for the Interplay between Large Language Models and Knowledge Graphs》
今年6月份刚放出来的一个工作,主要考察了LLMs在为知识图谱生成描述性文本和自然语言查询方面的作用,通过包括对LLM-KG互动进行分类、检查方法论以及调查协作使用和潜在偏见的结构化分析。
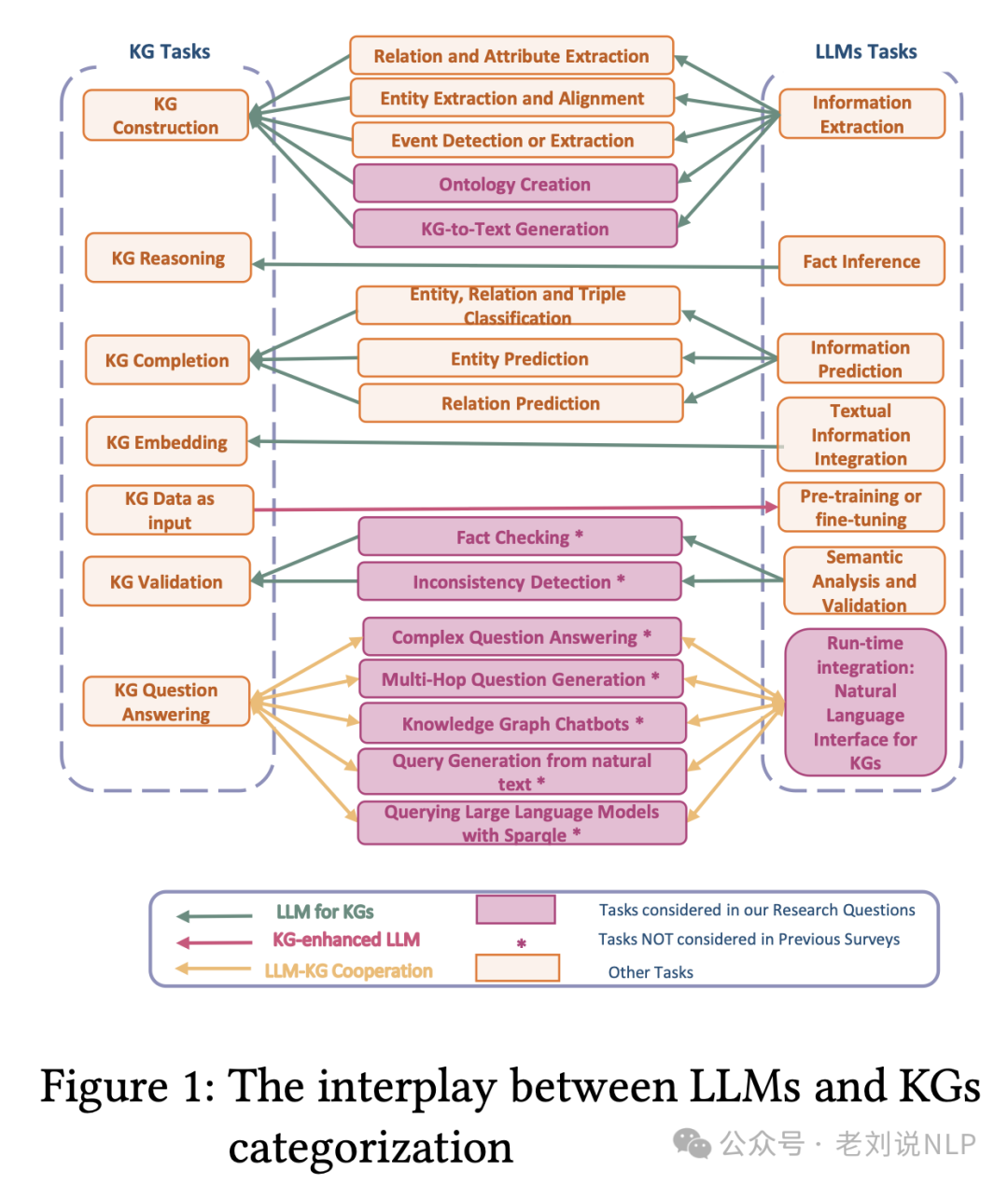
地址:https://arxiv.org/pdf/2406.08223
问题2:基于大模型进行图谱构建的4个策略对比
同样的,延续第一个话题,我们再来看看基于大模型进行知识图谱构建。工作《Text-to-Graph via LLM: pre-training, prompting, or tuning?》,可以看看这个文章:https://medium.com/@peter.lawrence_47665/text-to-graph-via-llm-pre-training-prompting-or-tuning-3233d1165360,主要提了几种路线,对比如下:
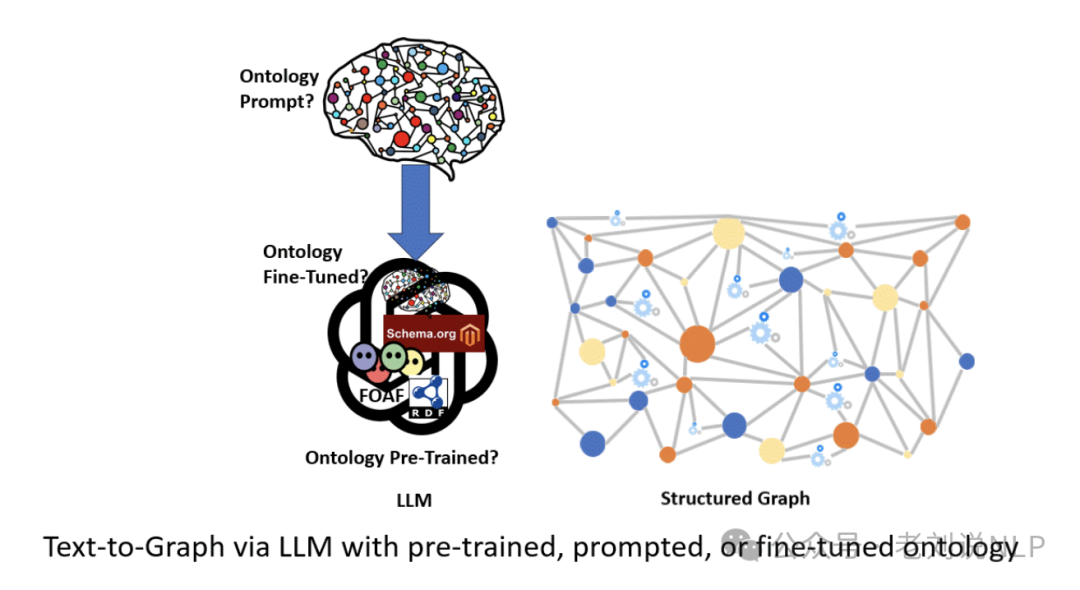
先看几个对比:
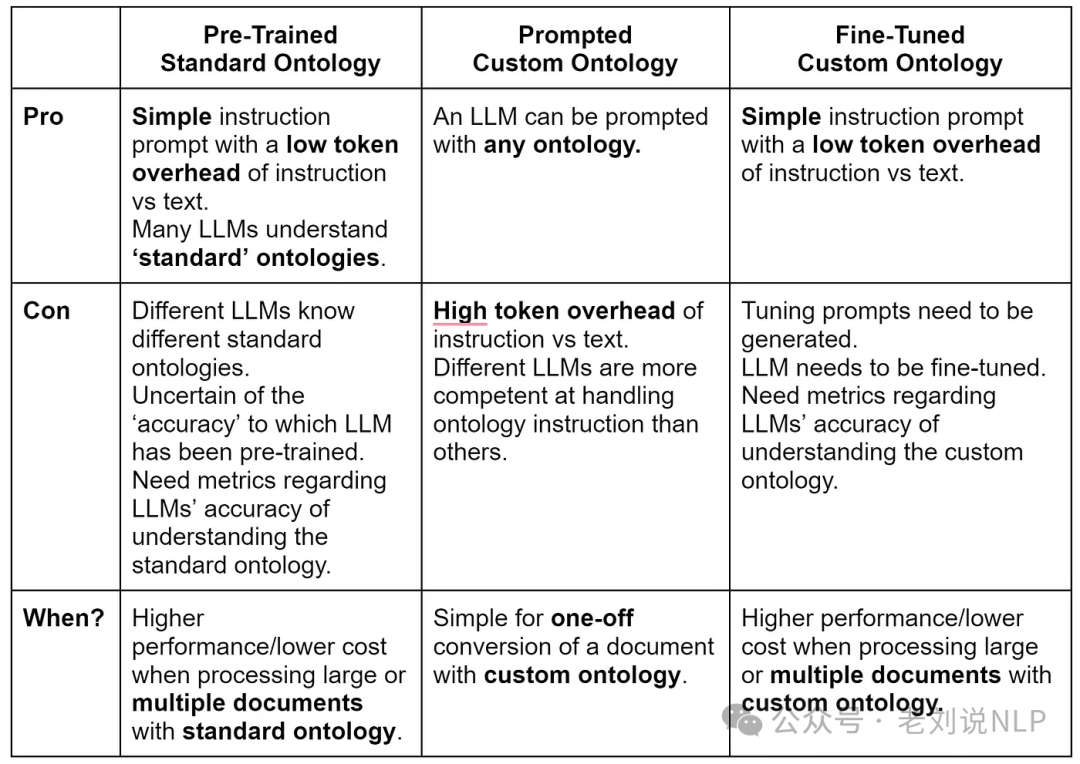
几个技术路线,可以重点看看:
1、Approach 1: LLM with pre-trained ontologies
思想在于,LLMs兴许已经在多种标准本体上进行了预训练,例如SCHEMA.ORG、FOAF、SKOS、RDF、RDFS、OWL等。
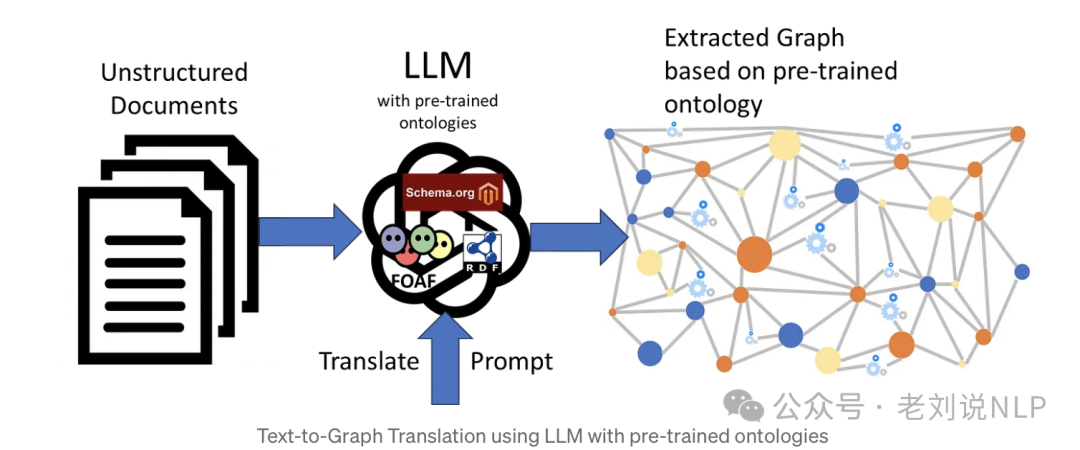
因此,通过使用适当的系统提示来指导使用这种预训练的本体,再加上包含非结构化文本的用户提示,可以获得转换后的知识图谱。
2、Approach 2: LLM prompted with an ontology
思想在于,有很多情况下想要使用非标准或自定义的本体。LLM很可能没有在这种本体上进行过预训练,因此需要在系统提示中包含完整的本体。所以可以进行定义: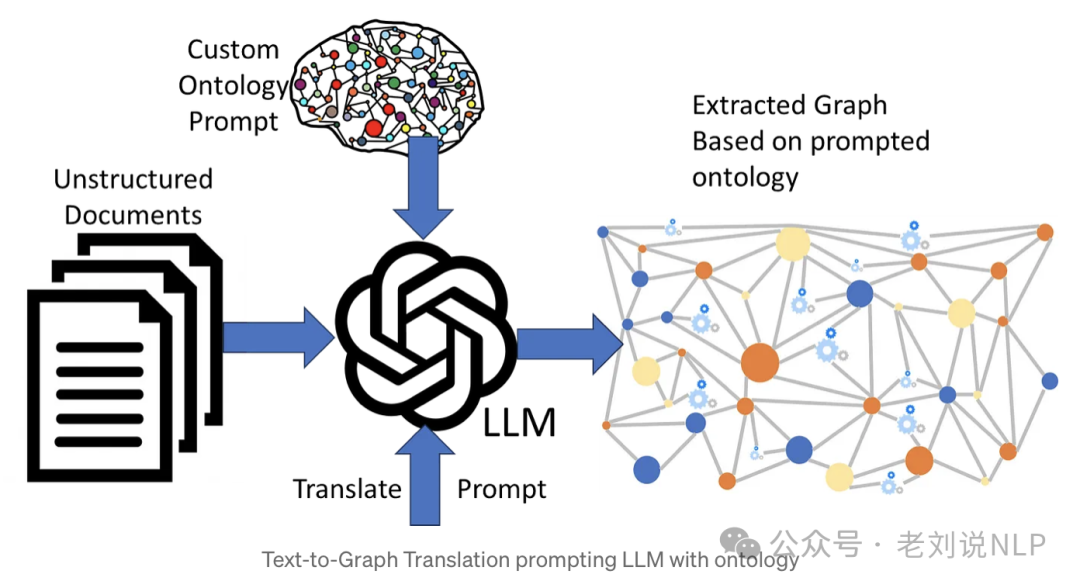
3、Approach 3: LLM fine-tuned with an ontology
思想在于对LLM进行其他本体的训练,也就是微调。
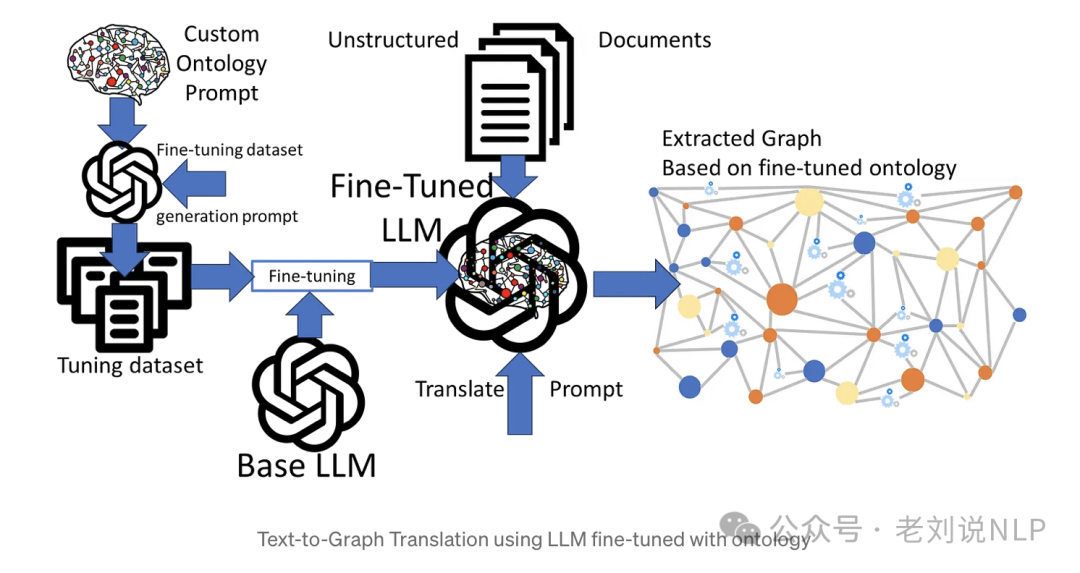
4、Approach 4: Hybrid of fine-tuned and pre-trained
思想在于给予预训和微调两种方式进行混合。
总结
今天我们主要看了两个问题,一个关于大模型与知识图谱结合的几个综述;另一个是基于大模型进行图谱构建的4个策略对比。
两个问题都很有趣,且具备指引性,供大家一起参考,可以深入到文章内容查看细节。
参考文献
1、http://xblx.whu.edu.cn/previewFile?id=58539306&type=pdf&lang=zh
2、https://arxiv.org/pdf/2306.08302
3、https://arxiv.org/pdf/2406.08223
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。















 57
57











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









