







正则化(Regularization)
防止过拟合
L1 Regularization(LASSO)
L1正则化
L2 Regularization(Ridge)
L2正则化
-
假设当前有参数: θ 0 , θ 1 , θ 2 , . . . , θ n θ_0,θ_1,θ_2,...,θ_n θ0,θ1,θ2,...,θn,则正则化项可表示为: λ ∑ j = 0 n θ j 2 λ\sum\limits_{j=0}^{n}θ_j^2 λj=0∑nθj2
-
核心思想是通过增加正则化项来缩小参数值进而减少过拟合。比如添加正则化项 100 θ 0 2 100θ_0^2 100θ02,那么在梯度下降算法中更新 θ 0 θ_0 θ0参数时,根据公式: θ i = θ i − α ∂ L ( θ 1 , θ 2 , θ 3 , . . . , θ n ) ∂ θ i θ_i = θ_i - α\frac{∂L(θ_1,θ_2,θ_3,...,θ_n)}{∂θ_i} θi=θi−α∂θi∂L(θ1,θ2,θ3,...,θn)那么 θ 0 θ_0 θ0的值就会比没有正则化时小了 200 θ 0 200θ_0 200θ0,这样就通过添加一个λ系数较大的正则化项来达到减少参数值的目的,从而避免过拟合
-
对于参数值缩小这点可以理解为:较好的拟合函数假设为 θ 2 x 2 + θ 1 x + θ 0 θ_2x^2+θ_1x+θ_0 θ2x2+θ1x+θ0另一个过拟合的函数假设为 θ 4 x 4 + θ 3 x 3 + θ 2 x 2 + θ 1 x + θ 0 θ_4x^4+θ_3x^3+θ_2x^2+θ_1x+θ_0 θ4x4+θ3x3+θ2x2+θ1x+θ0当对过拟合函数增加如下正则化项 100 θ 3 2 + 100 θ 4 2 100θ_3^2+100θ_4^2 100θ32+100θ42那么在梯度下降的不断迭代更新参数过程中, θ 3 θ_3 θ3和 θ 4 θ_4 θ4就会变得非常小,小到可以忽略不计。那么这时候就可以近似的把过拟合函数当成是较好的拟合函数,因为 θ 4 x 4 + θ 3 x 3 θ_4x^4+θ_3x^3 θ4x4+θ3x3已经小到可以忽略不计。这就是正则化项为什么能避免过拟合的原因
Elastic Net Regularization
弹性网络正则化
Weight Decay
权重衰减
-
在更新时引入衰减系数
θ t ← ( 1 − β ) θ t − 1 − α g t \theta_{t} \leftarrow(1-\beta) \theta_{t-1}-\alpha g_{t} θt←(1−β)θt−1−αgt
g t g_t gt为第 t t t步更新时的梯度, α \alpha α为学习率, β \beta β为权重衰减系数 -
在标准的梯度下降中,权重衰减与L2正则化等价,但在较复杂的优化方法(如Adam)中,两者并不等价
Early Stop
早停
- 根据验证集的损失情况判断是否需要提前结束训练
Dropout
Dropout
-
掩蔽函数
mask ( x ) = { m ⊙ x Training p x Testing \operatorname{mask}(x)= \begin{cases}m \odot x & \text { Training } \\ p x & \text { Testing }\end{cases} mask(x)={m⊙xpx Training Testing
m ∈ { 0 , 1 } D \boldsymbol{m} \in\{0,1\}^{D} m∈{0,1}D为丢弃掩码(Dropout Mask),通过以概率为 p p p的伯努利分布随机生成- 在测试时,所有的神经元都是可以激活的,这会造成训练和测试时网络的输出不一致.为了缓解这个问题,在测试时需要将神经层的输入 x x x乘以 p p p,也相当于把不同的神经网络做了平均
-
针对RNN的Dropout
-
不能直接对每个时刻的隐状态进行随机丢弃,会损害RNN的记忆能力
-
针对非循环连接进行丢弃(虚线表示丢弃,不同颜色表示不同丢弃掩码)
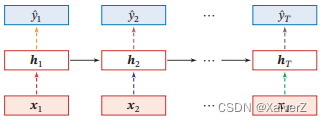
-
变分丢弃法(Variational Dropout)(相同颜色表示使用相同的丢弃掩码)
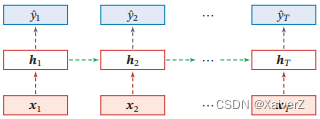
-
DropBlock
Paper : DropBlock: A regularization method for convolutional networks
DropBlock
Label Smoothing
标签平滑
Label Smoothing是对标签的独热码形式进行平滑处理。
- 例如单标签分类[0, 0, 1, 0],可以将其当成软标签(对应硬标签为2,第二类),平滑处理后变为[0.01, 0.01, 0.97, 0.01],其实就是对较少样本的类别进行损失计算,避免对样本多的类别过拟合















 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









