







Loss Function(损失函数)
以某种方式计算输出值(预测值)与真实值之间的误差,误差值是反向传播的起点
分类(Classification)
Kullback-Leibler Divergence(Relative Entropy)
KL散度(相对熵)
-
公式为:
D K L ( p ∣ ∣ q ) = ∑ i = 1 N p ( x i ) log p ( x i ) q ( x i ) = E [ log p ( x ) q ( x ) ] D_{KL}(p||q) = \sum\limits_{i=1}^{N}{p(x_i)\log{\frac{p(x_i)}{q(x_i)}}} = E[\log{\frac{p(x)}{q(x)}}] DKL(p∣∣q)=i=1∑Np(xi)logq(xi)p(xi)=E[logq(x)p(x)]
其中, N N N为类别总数, p ( x ) p(x) p(x)为目标分布(Label), q ( x ) q(x) q(x)为预测分布(Predict) -
KL散度只有在 p ( x ) p(x) p(x), q ( x ) q(x) q(x)分布完全一致时才等于0,其余时候都大于0。(证明见链接)
-
一个例子:假设目标分布为
p ( x ) = [ 0.95 , 0.05 ] p(x) = [0.95, 0.05] p(x)=[0.95,0.05]
预测分布为
q ( x ) = [ 0.8 , 0.2 ] q(x) = [0.8, 0.2] q(x)=[0.8,0.2]
那么
D K L ( p ∣ ∣ q ) = 0.95 × log 0.95 0.8 + 0.05 × log 0.05 0.2 D_{KL}(p||q) = 0.95×\log{\frac{0.95}{0.8}} + 0.05×\log{\frac{0.05}{0.2}} DKL(p∣∣q)=0.95×log0.80.95+0.05×log0.20.05 -
KL散度是一种非对称的散度,在计算两种分布 p p p, q q q之间的KL散度时(假设用分布 q q q去近似分布 p p p,且 p p p为混合高斯分布, q q q为高斯分布),按照顺序的不同,有两种KL散度,假设分布为连续的,则采取微积分可定义为
-
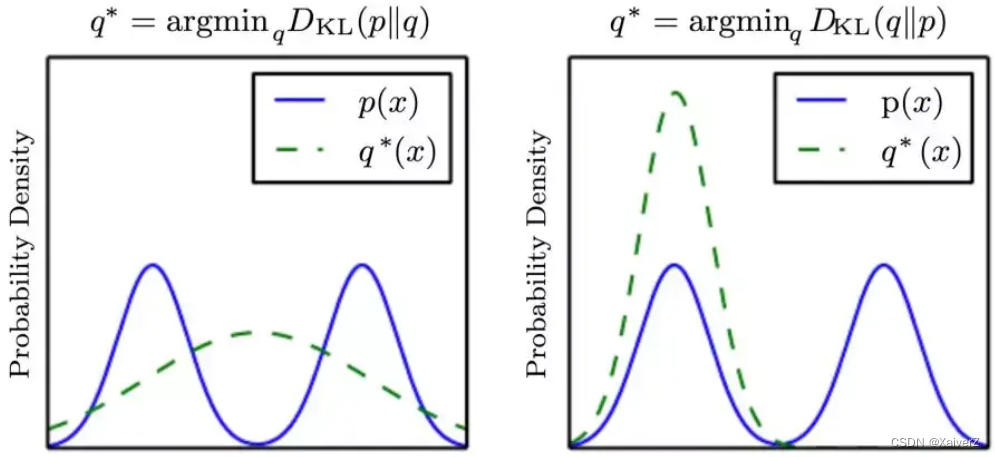
前向KL散度
Forward KL divergence
Moment projection(M-Projection)
K L ( p , q ) = ∫ p ( x ) log p ( x ) q ( x ) d x \mathrm{KL}\left(p, q\right)=\int p(\boldsymbol{x}) \log \frac{p(\boldsymbol{x})}{q(\boldsymbol{x})} \mathrm{d} \boldsymbol{x} KL(p,q)=∫p(x)logq(x)p(x)dx
-
当 p ( x ) → 0 p(x) \rightarrow 0 p(x)→0, q ( x ) > 0 q(x) > 0 q(x)>0时,KL散度为 0 0 0
-
当 p ( x ) > 0 p(x) > 0 p(x)>0, q ( x ) → 0 q(x) \rightarrow 0 q(x)→0时,KL散度趋于无穷大
-
上面两种极端情况表达的含义是,在 p ( x ) p(x) p(x)大于 0 0 0的区域(即有分布的区域),若 q ( x ) q(x) q(x)趋近于 0 0 0,则KL散度会非常大,即KL散度对这种情况很敏感, q ( x ) q(x) q(x)会尽量避免这种情况,使其在 P ( x ) P(x) P(x)大于 0 0 0的区域也都大于 0 0 0(即有分布);另一种情况,在 p ( x ) p(x) p(x)趋于0的区域(即无分布的区域),若 q ( x ) q(x) q(x)大于 0 0 0,则KL散度为 0 0 0,KL散度对这种情况并不敏感。综上,为了保证KL散度最小, q ( x ) q(x) q(x)会“高估” p ( x ) p(x) p(x)的值域,除了 p ( x ) p(x) p(x)的区域以外,其余近邻区域也会有部分分布
-
-
逆向KL散度
Reverse KL divergence
Information Projection(I-Projection)
K L ( q , p ) = ∫ q ( x ) log q ( x ) p ( x ) d x \mathrm{KL}\left(q, p\right)=\int q(\boldsymbol{x}) \log \frac{q(\boldsymbol{x})}{p(\boldsymbol{x})} \mathrm{d} \boldsymbol{x} KL(q,p)=∫q(x)logp(x)q(x)dx
-
当 p ( x ) → 0 p(x) \rightarrow 0 p(x)→0, q ( x ) > 0 q(x) > 0 q(x)>0时,KL散度趋于无穷大
-
当 p ( x ) > 0 p(x) > 0 p(x)>0, q ( x ) → 0 q(x) \rightarrow 0 q(x)→0时,KL散度为 0 0 0
-
上面两种极端情况表达的含义正好与前向KL散度相反,在 p ( x ) p(x) p(x)大于 0 0 0的区域(即有分布的区域),若 q ( x ) q(x) q(x)趋近于 0 0 0,则KL散度为 0 0 0,即KL散度对这种情况不敏感;另一种情况,在 p ( x ) p(x) p(x)趋于0的区域(即无分布或分布稀疏的区域),若 q ( x ) q(x) q(x)大于 0 0 0,则KL散度趋于无穷大,即KL散度对这种情况很敏感,所以 q ( x ) q(x) q(x)在 p ( x ) p(x) p(x)无分布的区域也都无分布。综上,为了保证KL散度最小, q ( x ) q(x) q(x)不会像前向KL散度那样“高估” p ( x ) p(x) p(x)的值域,反之, q ( x ) q(x) q(x)的分布会严格的限制在 p ( x ) p(x) p(x)的分布区域内;若 p ( x ) p(x) p(x)分布区域中存在稀疏区域,那么 q ( x ) q(x) q(x)为了避免第一种情况,则有可能会“低估” p ( x ) p(x) p(x)的值域
-
-
Jensen-Shannon Divergence
JS散度
-
JS散度基于KL散度作出改进
D J S ( p ∣ ∣ q ) = 1 2 D K L ( p ∣ ∣ M ) + 1 2 D K L ( q ∣ ∣ M ) , M = 1 2 ( p + q ) D_{JS}(p||q)=\frac{1}{2} D_{KL}(p||M)+\frac{1}{2} D_{KL}(q||M), \quad M = \frac{1}{2}(p+q) DJS(p∣∣q)=21DKL(p∣∣M)+21DKL(q∣∣M),M=21(p+q)
-
JS散度是对称的且取值在 [ 0 , log 2 ] [0, \log{2}] [0,log2]
-
当两个分布越接近时,JS散度的值越小;当两个分布完全相同时,其JS散度为0。但JS散度存在一个问题,当两个分布完全不相关不重叠(或有部分可忽略的小范围重叠)时,JS散度的值为一个常数。
-
由 K L ( P 1 ∥ P 2 ) = E x ∼ P 1 log P 1 P 2 K L\left(P_{1} \| P_{2}\right)=\mathbb{E}_{x \sim P_{1}} \log \frac{P_{1}}{P_{2}} KL(P1∥P2)=Ex∼P1logP2P1与 J S ( P 1 ∥ P 2 ) = 1 2 K L ( P 1 ∥ P 1 + P 2 2 ) + 1 2 K L ( P 2 ∥ P 1 + P 2 2 ) J S\left(P_{1} \| P_{2}\right)=\frac{1}{2} K L\left(P_{1} \| \frac{P_{1}+P_{2}}{2}\right)+\frac{1}{2} K L\left(P_{2} \| \frac{P_{1}+P_{2}}{2}\right) JS(P1∥P2)=21KL(P1∥2P1+P2)+21KL(P2∥2P1+P2)可知,当两个分布 P 1 P_1 P1, P 2 P_2 P2无重叠或重叠部分可忽略时,有如下四种情况
-
P 1 ( x ) = 0 , P 2 ( x ) = 0 P_1(x)=0, P_2(x)=0 P1(x)=0,P2(x)=0
-
P 1 ( x ) ≠ 0 , P 2 ( x ) ≠ 0 P_1(x)\neq0, P_2(x)\neq0 P1(x)=0,P2(x)=0
-
P 1 ( x ) = 0 , P 2 ( x ) ≠ 0 P_1(x)=0, P_2(x)\neq0 P1(x)=0,P2(x)=0
-
P 1 ( x ) ≠ 0 , P 2 ( x ) = 0 P_1(x)\neq0, P_2(x)=0 P1(x)=0,P2(x)=0
-
-
第一种情况下JS散度为 0 0 0;第二种情况由于重叠可忽略所以JS散度也为 0 0 0;第三种情况JS散度为 log 2 \log{2} log2;第四种情况类似JS散度为 log 2 \log{2} log2
-
所以,当两个分布完全不重叠时,JS散度为常数 log 2 \log{2} log2
-
Wasserstein Distance(Earth-Mover Distance)
Wasserstein距离(推土机距离)
-
对于两个分布 p p p、 q q q,它们之间的(1st)Wasserstein Distance为
W ( p , q ) = inf γ ∼ Π ( p , q ) E ( x , y ) ∼ γ [ ∥ x − y ∥ ] W\left(p, q\right)=\inf _{\gamma \sim \Pi\left(p, q\right)} \mathbb{E}_{(x, y) \sim \gamma}[\|x-y\|] W(p,q)=γ∼Π(p,q)infE(x,y)∼γ[∥x−y∥]
其中 Π ( p , q ) \Pi\left(p, q\right) Π(p,q)是 p p p与 q q q的联合分布的集合。- 上式说明,对于每一个可能的联合分布 γ \gamma γ,可以从中采样 ( x , y ) ∼ γ (x,y) \sim \gamma (x,y)∼γ分别得到 p p p与 q q q分布中的样本 x x x与 y y y,并计算出这对样本的距离 ∥ x − y ∥ \|x-y\| ∥x−y∥,写成期望形式即 E ( x , y ) ∼ γ [ ∥ x − y ∥ ] \mathbb{E}_{(x, y) \sim \gamma}[\|x-y\|] E(x,y)∼γ[∥x−y∥]。而在所有可能的联合分布中对期望取下界,即可得到Wasserstein Distance的表达式
-
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近
-
考虑如下二维空间中的两个分布 p p p与 q q q,分别在线段 A B AB AB与 C D CD CD上均匀分布, θ \theta θ表示它们之间的距离
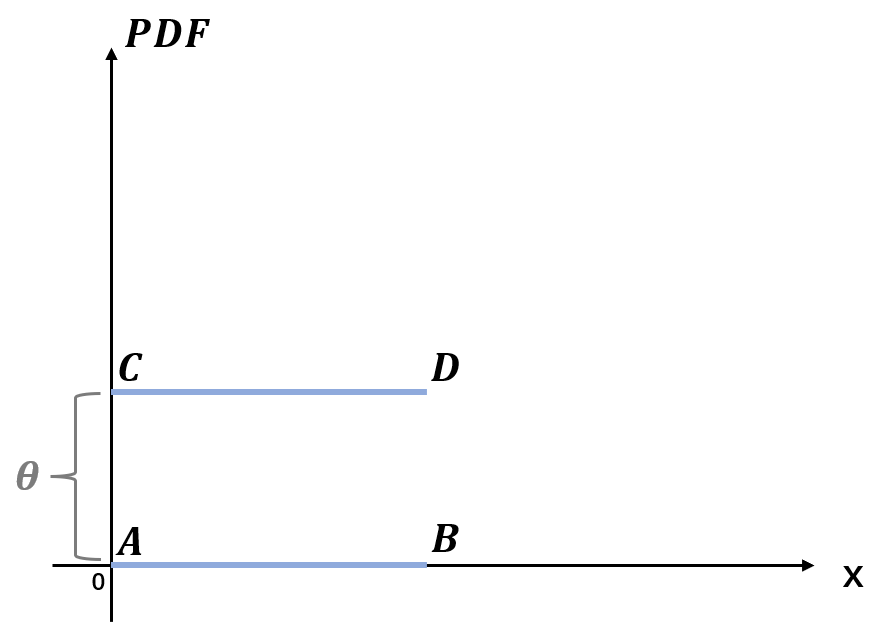
-
若使用KL散度作为度量
K L ( p ∥ q ) = K L ( p ∥ q ) = { + ∞ if θ ≠ 0 0 if θ = 0 K L\left(p \| q\right)=K L\left(p \| q\right)= \begin{cases}+\infty & \text { if } \theta \neq 0 \\ 0 & \text { if } \theta=0\end{cases} KL(p∥q)=KL(p∥q)={+∞0 if θ=0 if θ=0
-
若使用JS散度作为度量
J S ( p ∥ q ) = { log 2 if θ ≠ 0 0 if θ = 0 J S\left(p \| q\right)= \begin{cases}\log 2 & \text { if } \theta \neq 0 \\ 0 & \text { if } \theta=0\end{cases} JS(p∥q)={log20 if θ=0 if θ=0
-
若使用Wasserstein距离作为度量
W ( p , q ) = ∣ θ ∣ W\left(p, q\right)=|\theta| W(p,q)=∣θ∣
-
-
可以看到,KL散度与JS散度关于距离 θ \theta θ要么不可导,要么导数为0;而Wasserstein距离关于距离 θ \theta θ却是(几乎)处处可导且导数不为0的。若采用梯度下降法去优化 θ \theta θ这个参数,那么KL散度与JS散度完全提供不了梯度,但是Wasserstein距离却可以提供有意义的梯度
Hinge Loss
用于最大间隔分类(Maximum-margin Classification),如SVM
对于多分类
-
公式为:
L = ∑ j ≠ y i max ( 0 , s j − s y i + 1 ) L = \sum\limits_{j\not=y_i}{\max{(0, s_j - s_{y_i} + 1)}} L=j=yi∑max(0,sj−syi+1)
其中, s j s_j sj是其他标签的预测值, s y i s_{y_i} syi是目标标签的预测值 -
一个例子:一个样本经过NN后输出
s = [ 3.4 , 5.6 , 1.2 ] s = [3.4, 5.6, 1.2] s=[3.4,5.6,1.2]
其中,该样本的标签索引为0。则
L = max ( 0 , 5.6 − 3.4 + 1 ) + max ( 0 , 1.2 − 3.4 + 1 ) L = \max{(0, 5.6 - 3.4 + 1)} + \max{(0, 1.2 - 3.4 + 1)} L=max(0,5.6−3.4+1)+max(0,1.2−3.4+1)
Cross Entropy(交叉熵)
用于分类问题。以下所有内容均在PyTorch上实际验证过。
-
交叉熵向量化表述例子: O u t p u t = [ 0.1 , 0.3 , 0.4 , 0.2 ] Output = [0.1, 0.3, 0.4, 0.2] Output=[0.1,0.3,0.4,0.2] L a b e l = [ 0 , 1 , 1 , 0 ] Label = [0, 1, 1, 0] Label=[0,1,1,0]
Label一般在框架内部转换成独热码形式,输入时直接按照Label的量化值输入即可。 -
实际上,各框架交叉熵损失函数的输入可以有多种形式,例如硬标签、软标签等等,需视具体情况而定。
二分类(Binary Cross Entropy)
BCE
-
公式为:
− L = y ⋅ log p + ( 1 − y ) ⋅ log ( 1 − p ) -L = y · \log{p} + (1 - y) · \log{(1 - p)} −L=y⋅logp+(1−y)⋅log(1−p)
其中, y y y为标签, p p p为概率值 -
例子:(batch_size=2)输出概率矩阵 [ [ 0.9 ] , [ 0.6 ] ] [[0.9], [0.6]] [[0.9],[0.6]],对应的Label为 [ [ 1 ] , [ 0 ] ] [[1], [0]] [[1],[0]]。
- 计算第一个样本的损失:
− L 1 = 1 ⋅ log 0.9 + ( 1 − 1 ) ⋅ log ( 1 − 0.9 ) -L_1 = 1 · \log{0.9} + (1 - 1) · \log{(1 - 0.9)} −L1=1⋅log0.9+(1−1)⋅log(1−0.9) - 计算第二个样本的损失:
− L 2 = 0 ⋅ log 0.6 + ( 1 − 0 ) ⋅ log ( 1 − 0.6 ) -L_2 = 0 · \log{0.6} + (1 - 0) · \log{(1 - 0.6)} −L2=0⋅log0.6+(1−0)⋅log(1−0.6) - 平均batch内所有样本的损失:
L = L 1 + L 2 2 L = \frac{L_1 + L_2}{2} L=2L1+L2
- 计算第一个样本的损失:
多标签分类(Binary Cross Entropy)
BCE
-
公式为:
− L = ∑ i c y i ⋅ log p i + ( 1 − y i ) ⋅ log ( 1 − p i ) c -L = \frac{\sum\limits_i^c{y_i · \log{p_i} + (1 - y_i) · \log{(1 - p_i)}}}{c} −L=ci∑cyi⋅logpi+(1−yi)⋅log(1−pi)
其中, y i y_i yi为标签, p i p_i pi为概率值, c c c为类别总数 -
例子:(batch_size=2)输出概率矩阵 [ [ 0.9 , 0.6 , 0.7 ] , [ 0.5 , 0.8 , 0.3 ] ] [[0.9, 0.6, 0.7], [0.5, 0.8, 0.3]] [[0.9,0.6,0.7],[0.5,0.8,0.3]],对应的Label为 [ [ 1 , 0 , 1 ] , [ 0 , 1 , 0 ] ] [[1, 0, 1], [0, 1, 0]] [[1,0,1],[0,1,0]]。
- 计算第一个样本的损失:
− L 1 1 = 1 ⋅ log 0.9 + ( 1 − 1 ) ⋅ log ( 1 − 0.9 ) -L_{1_1} = 1 · \log{0.9} + (1 - 1) · \log{(1 - 0.9)} −L11=1⋅log0.9+(1−1)⋅log(1−0.9)
− L 1 2 = 0 ⋅ log 0.6 + ( 1 − 0 ) ⋅ log ( 1 − 0.6 ) -L_{1_2} = 0 · \log{0.6} + (1 - 0) · \log{(1 - 0.6)} −L12=0⋅log0.6+(1−0)⋅log(1−0.6)
− L 1 3 = 1 ⋅ log 0.7 + ( 1 − 1 ) ⋅ log ( 1 − 0.7 ) -L_{1_3} = 1 · \log{0.7} + (1 - 1) · \log{(1 - 0.7)} −L13=1⋅log0.7+(1−1)⋅log(1−0.7)
对每个标签的损失取平均值:
L 1 = L 1 1 + L 1 2 + L 1 3 3 L_1 = \frac{L_{1_1} + L_{1_2} + L_{1_3}}{3} L1=3L11+L12+L13 - 计算第二个样本的损失:
− L 2 1 = 0 ⋅ log 0.5 + ( 1 − 0 ) ⋅ log ( 1 − 0.5 ) -L_{2_1} = 0 · \log{0.5} + (1 - 0) · \log{(1 - 0.5)} −L21=0⋅log0.5+(1−0)⋅log(1−0.5)
− L 2 2 = 1 ⋅ log 0.8 + ( 1 − 1 ) ⋅ log ( 1 − 0.8 ) -L_{2_2} = 1 · \log{0.8} + (1 - 1) · \log{(1 - 0.8)} −L22=1⋅log0.8+(1−1)⋅log(1−0.8)
− L 2 3 = 0 ⋅ log 0.3 + ( 1 − 0 ) ⋅ log ( 1 − 0.3 ) -L_{2_3} = 0 · \log{0.3} + (1 - 0) · \log{(1 - 0.3)} −L23=0⋅log0.3+(1−0)⋅log(1−0.3)
对每个标签的损失取平均值:
L 2 = L 2 1 + L 2 2 + L 2 3 3 L_2 = \frac{L_{2_1} + L_{2_2} + L_{2_3}}{3} L2=3L21+L22+L23 - 平均batch内所有样本的损失:
L = L 1 + L 2 2 L = \frac{L_1 + L_2}{2} L=2L1+L2
- 计算第一个样本的损失:
-
多标签分类实际上二分类的叠加:一个样本有多个标签相等于对每一个标签做一次二分类,所以多标签分类需要对每一个标签进行交叉熵计算损失
-
在PyTorch中,可以通过指定 w e i g h t weight weight参数来对每个Label(类别)赋予不同的权重
多分类(Cross Entropy)
CE
-
公式为:
L ( x , c l a s s ) = − log ( exp ( x [ c l a s s ] ) ∑ j exp ( x [ j ] ) ) = − x [ c l a s s ] + log ( ∑ j exp ( x [ j ] ) ) L(x, class) = -\log{(\frac{\exp{(x[class])}}{\sum\limits_j{\exp{(x[j])}}})} = -x[class] + \log{(\sum\limits_j{\exp{(x[j])}})} L(x,class)=−log(j∑exp(x[j])exp(x[class]))=−x[class]+log(j∑exp(x[j]))
其中, x x x为输出的Logits值,非概率, c l a s s class class为该样本对应的label值。 -
例子:(batch_size=2)输出Logits矩阵 [ [ 1.3 , 1.2 , 1.1 ] , [ 0.6 , 1.6 , 1.7 ] ] [[1.3, 1.2, 1.1], [0.6, 1.6, 1.7]] [[1.3,1.2,1.1],[0.6,1.6,1.7]],对应的Label为 [ 2 , 1 ] [2, 1] [2,1],独热码为 [ [ 0 , 0 , 1 ] , [ 0 , 1 , 0 ] ] [[0, 0, 1], [0, 1, 0]] [[0,0,1],[0,1,0]]。
- 计算第一个样本的损失:
L 1 ( x 1 , 2 ) = − log ( exp 1.1 ∑ j exp ( x 1 [ j ] ) ) = − 1.1 + log ( ∑ j exp ( x 1 [ j ] ) ) L_1(x_1, 2) = -\log{(\frac{\exp{1.1}}{\sum\limits_j{\exp{(x_1[j])}}})} = -1.1 + \log{(\sum\limits_j{\exp{(x_1[j])}})} L1(x1,2)=−log(j∑exp(x1[j])exp1.1)=−1.1+log(j∑exp(x1[j])) - 计算第二个样本的损失:
L 2 ( x 2 , 1 ) = − log ( exp 1.6 ∑ j exp ( x 2 [ j ] ) ) = − 1.6 + log ( ∑ j exp ( x 2 [ j ] ) ) L_2(x_2, 1) = -\log{(\frac{\exp{1.6}}{\sum\limits_j{\exp{(x_2[j])}}})} = -1.6 + \log{(\sum\limits_j{\exp{(x_2[j])}})} L2(x2,1)=−log(j∑exp(x2[j])exp1.6)=−1.6+log(j∑exp(x2[j])) - 平均batch内所有样本的损失:
L = L 1 + L 2 2 L = \frac{L_1 + L_2}{2} L=2L1+L2
- 计算第一个样本的损失:
-
实际上,对于如下一组数据:
O u t p u t = [ 0.1 , 0.3 , 0.4 , 0.2 ] Output = [0.1, 0.3, 0.4, 0.2] Output=[0.1,0.3,0.4,0.2] L a b e l = [ 0 , 1 , 0 , 0 ] Label = [0, 1, 0, 0] Label=[0,1,0,0]
若该任务为多分类任务,那么仅需根据二分类交叉熵公式计算正确类别的那组数据:
L = − 1 ⋅ log 0.3 − ( 1 − 1 ) ⋅ log ( 1 − 0.3 ) L = -1 · \log{0.3} - (1 - 1) · \log{(1 - 0.3)} L=−1⋅log0.3−(1−1)⋅log(1−0.3)
若该任务为多标签分类任务,那么需要根据二分类交叉熵公式计算所有的数据:
L 1 = − 0 ⋅ log 0.1 − ( 1 − 0 ) ⋅ log ( 1 − 0.1 ) L_1 = -0 · \log{0.1} - (1 - 0) · \log{(1 - 0.1)} L1=−0⋅log0.1−(1−0)⋅log(1−0.1)
L 2 = − 1 ⋅ log 0.3 − ( 1 − 1 ) ⋅ log ( 1 − 0.3 ) L_2 = -1 · \log{0.3} - (1 - 1) · \log{(1 - 0.3)} L2=−1⋅log0.3−(1−1)⋅log(1−0.3)
L 3 = − 0 ⋅ log 0.4 − ( 1 − 0 ) ⋅ log ( 1 − 0.4 ) L_3 = -0 · \log{0.4} - (1 - 0) · \log{(1 - 0.4)} L3=−0⋅log0.4−(1−0)⋅log(1−0.4)
L 4 = − 0 ⋅ log 0.2 − ( 1 − 0 ) ⋅ log ( 1 − 0.2 ) L_4 = -0 · \log{0.2} - (1 - 0) · \log{(1 - 0.2)} L4=−0⋅log0.2−(1−0)⋅log(1−0.2)
最后再将该样本的损失取平均:
L = L 1 + L 2 + L 3 + L 4 4 L = \frac{L_1 + L_2 + L_3 + L_4}{4} L=4L1+L2+L3+L4
这就是多标签分类和多分类的重要区别 -
其实还可以从另一个角度理解多分类与多标签分类的区别:对一个样本来说,多分类只需要给该样本赋上一个标签即可,所以只需算该组标签的损失值。而多标签分类需要给样本赋上多个标签,每个标签都需要检验是否为该样本的一个标签,所以需要计算所有的损失值。
-
Tips:多分类只计算正确标签的那一组损失值,而多标签分类则计算所有的损失值。在PyTorch中,多分类的Target Label输入为一维Tensor,且Label值为量化值,非独热码。经过PyTorch测试,多分类通过直接修改Label值不能应用Label Smooth,而多标签分类与二分类是可以的。
-
在PyTorch中,可以通过指定 w e i g h t weight weight参数来对每个Label(类别)赋予不同的权重
Class Weight
Class Weight
-
样本数倒数
1 ClassSize \frac{1}{\text { ClassSize }} ClassSize 1
-
Inverse Category Frequency(ICF)
icf ( t i ) = log ( ∣ C ∣ c f ( t i ) ) \operatorname{icf}\left(t_{i}\right)=\log \left(\frac{|C|}{c f\left(t_{i}\right)}\right) icf(ti)=log(cf(ti)∣C∣)
其中, ∣ C ∣ |C| ∣C∣为样本总数, c f ( t i ) cf(t_i) cf(ti)表示第 t i t_i ti类样本的频数 -
类别最大样本数量 / 每个类别样本数量
- 例子:三个类别样本数分别为 100000 , 100 , 10 100000, 100, 10 100000,100,10,则权重系数为:
weight = [ 100000 100000 , 100000 100 , 100000 10 ] = [ 1.0 , 1000 , 10000 ] \text { weight }=\left[\frac{100000}{100000}, \frac{100000}{100}, \frac{100000}{10}\right]=[1.0,1000,10000] weight =[100000100000,100100000,10100000]=[1.0,1000,10000]
α-balanced Cross Entropy
Cross Entropy的改进,针对二分类和多标签分类,解决正负样本不均衡问题
-
将二分类公式简化为:
p t = { p , y = 1 , 1 − p , o t h e r w i s e , p_t = \begin{cases}p, \quad \ \ & y = 1,\\ 1 - p, \quad \ \ & otherwise, \end{cases} pt={p, 1−p, y=1,otherwise,
C E ( p , y ) = C E ( p t ) = − log ( p t ) CE(p, y) = CE(p_t) = -\log{(p_t)} CE(p,y)=CE(pt)=−log(pt) -
对于一个二分类任务来说,如果正样本(即Label为1)或负样本(即Label为0)占比过大的,会诱导模型朝过采样的一方学习,对欠采样的一方性能很差。
α t = { α , y = 1 , 1 − α , o t h e r w i s e , α_t = \begin{cases}α, \quad \ \ & y = 1,\\ 1 - α, \quad \ \ & otherwise, \end{cases} αt={α, 1−α, y=1,otherwise,
其中, α ∈ [ 0 , 1 ] α \in [0, 1] α∈[0,1],为超参数。通过给标准交叉熵乘上α-balanced权重 α t α_t αt,可以对过采样的一方赋予一个比较小的权重和,欠采样一方赋予一个较大的权重,达到改善正负样本不均衡的目的。
C E ( p t ) = − α t log ( p t ) CE(p_t) = -α_t\log{(p_t )} CE(pt)=−αtlog(pt) -
α-balanced并未解决类别不均衡问题,它解决的是正负样本不均衡问题。严格来说,多分类问题中只存在类别不均衡问题,即在所有的类别中,有的类别样本特别多,有的特别少。但对于一个多标签分类任务来说,也存在正负样本不均衡(把每个类别都看作是一个独立的二分类任务),即对每一个类别来说,“是与不是该类别的样本严重失衡”;从另一个角度看多标签分类任务,有的类别多,有的类别少,这也会影响模型学习。类别不均衡可通过设置 w e i g h t weight weight参数解决。其实,在多标签分类任务下,解决正负不均衡问题在一定程度上也缓解了类别不均衡问题。
Focal Loss
Paper : Focal Loss for Dense Object Detection
用于目标检测中正负样本不均衡问题,而非类别不均衡。
-
公式为:
F L ( p t ) = − α t ( 1 − p t ) γ log ( p t ) FL(p_t) = -α_t(1 - p_t)^γ\log{(p_t)} FL(pt)=−αt(1−pt)γlog(pt)
其中, α t α_t αt与 p t p_t pt详见α-balanced Cross Entropy, γ γ γ为超参数正整数。 -
对于一个二分类任务来说,如果正负样不均衡的话,会导致模型朝过采样的那一方偏离。在Focal Loss中,若 p t p_t pt越大,则 1 − p t 1 - p_t 1−pt越小,也就是说给简单样本的那一方赋予一个更小的权重,让模型更聚焦于学习那些困难样本。 α t α_t αt是用来调整正负样本的比例的,例如正样本给0.25,负样本给0.75。
-
Focal Loss本质还是属于困难样本挖掘领域,注意样本少的类别≠困难样本,困难样本指学习难度大,较难学习的那些样本,这与样本少的类别不是同一个概念,Focal Loss改善的是困难样本的效果,而不是少类样本的效果。将Focal Loss用于易于学习的类别上可能会导致效果下降。
Equalized Focal Loss
Paper : Equalized Focal Loss for Dense Long-Tailed Object Detection
EFL
回归(Regression)
MAE(平均绝对误差-L1损失函数)
用于回归问题
- 公式为: M A E = ∑ i = 1 n ∣ y i − y i p ∣ n MAE = \frac{\sum\limits_{i=1}^{n}|y_i-y_i^p|}{n} MAE=ni=1∑n∣yi−yip∣其中, n n n为样本数, y i y_i yi为样本真实值, y i p y_i^p yip为模型对于该样本的预测值
MSE(均方误差-L2损失函数)
用于回归问题
- 公式为: M S E = ∑ i = 1 n ( y i − y i p ) 2 n MSE = \frac{\sum\limits_{i=1}^{n}(y_i-y_i^p)^2}{n} MSE=ni=1∑n(yi−yip)2其中, n n n为样本数, y i y_i yi为样本真实值, y i p y_i^p yip为模型对于该样本的预测值
RMSE
Root Mean Square Error
-
公式为:
R M S E = 1 n ∑ i = 1 n ( y ^ i − y i ) 2 RMSE=\sqrt{\frac{1}{n} \sum_{i=1}^{n}\left(\hat{y}_{i}-y_{i}\right)^{2}} RMSE=n1i=1∑n(y^i−yi)2
Huber(平滑平均绝对误差)
Huber Loss
-
公式为:
L δ ( y , f ( x ) ) = { 1 2 ( y − f ( x ) ) 2 for ∣ y − f ( x ) ∣ ≤ δ δ ∣ y − f ( x ) ∣ − 1 2 δ 2 otherwise L_{\delta}(y, f(x))= \begin{cases}\frac{1}{2}(y-f(x))^{2} & \text { for }|y-f(x)| \leq \delta \\ \delta|y-f(x)|-\frac{1}{2} \delta^{2} & \text { otherwise }\end{cases} Lδ(y,f(x))={21(y−f(x))2δ∣y−f(x)∣−21δ2 for ∣y−f(x)∣≤δ otherwise
当损失小于阈值 δ \delta δ时,使用MSE计算损失;当损失大于阈值 δ \delta δ时,使用MAE计算损失 -
Huber Loss降低了对异常点(离群点)的惩罚程度,对异常值的敏感性较差















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









