







写在前面:
有很长时间没有更新学习了,因为在忙着做试验写毕业论文。但是,学习不能停止,从今天开始,换成语义分割方向进行深入学习,有兴趣的小伙伴可以和我一起讨论,也欢迎才进入这个方向学习的朋友们和我一起成长!
语义分割这个方向在大约两年前我接触过一点,但也只懂了一些皮毛,所以从现在开始,我将从基础学习,也会将自己的心得体会分享在【基于视觉的分割】这个专栏里,欢迎大家点赞关注!
言归正传~
一、一些经典的算法
1. FCN, Fully Convolutional Networks
Fully Convolutional Networks for Semantic Segmentation
首先,为什么要提出这种网络?全卷积层的优势在哪里?本文作者指出,以往分类算法后面总是会加上全连接层,但是全连接层总是会设置固定的尺寸,并会丢弃空间坐标(空间维度指的是h*w)。因此,作者将全连接层(fully connected layers)换成卷积层,提出了仅由卷积层组成的网络FCN。因此,FCN可以接收任意尺寸的图片作为输入,并输出和原图大小一致的像素预测图。
那么,怎么做到输出大小与输入图片大小一致呢?作者提出了反卷积deconvolution和skip layer connection,实现局部和全局信息的综合利用。将pool5的结果(已经是原图的1/32了)反卷积为原图的1/16,和pool4的结果(是原图的1/16)一起反卷积为原图的1/8,再和pool3的结果(是原图的1/8)一起进行8倍的反卷积,最终生成和原图大小相同的预测结果(FCN-8s)。

一些对我很有启发的blog链接: FCN的理解
2. U-Net、UNet++、U2-Net
论文:
U-Net: Convolutional Networks for Biomedical Image Segmentation
UNet++: A Nested U-Net Architecture for Medical Image Segmentation
U2-Net: Going Deeper with Nested U-Structure for Salient Object Detection
U-Net的优势:需要样本数少(文章通过弹性变形这种数据增强去处理较少的样本,但可能仅适用于生物医学领域);训练速度快。仍然仅使用卷积层,未添加全连接层。
网络结构为Encoder-Decoder,一个收缩的路径a contracting path,一个对称的扩张路径a symmetric expanding path。先进行无padding的3×3卷积,以及池化。然后采用转置卷积上采样,拿第一个上采样为例。此时是1024×28×28,上采样之后变为512×56×56;将下采样过程中得到的512×64×64中心裁剪为512×56×56;将二者拼接在一起,成为1024×56×56的特征层。
U-Net的输入输出图像大小不一样,现在常用的其实是:在卷积的过程中,padding不为0,这样在卷积过程中就不会改变图像的大小,也无需进行中心裁剪操作,可以直接拼接,并加入BN层。
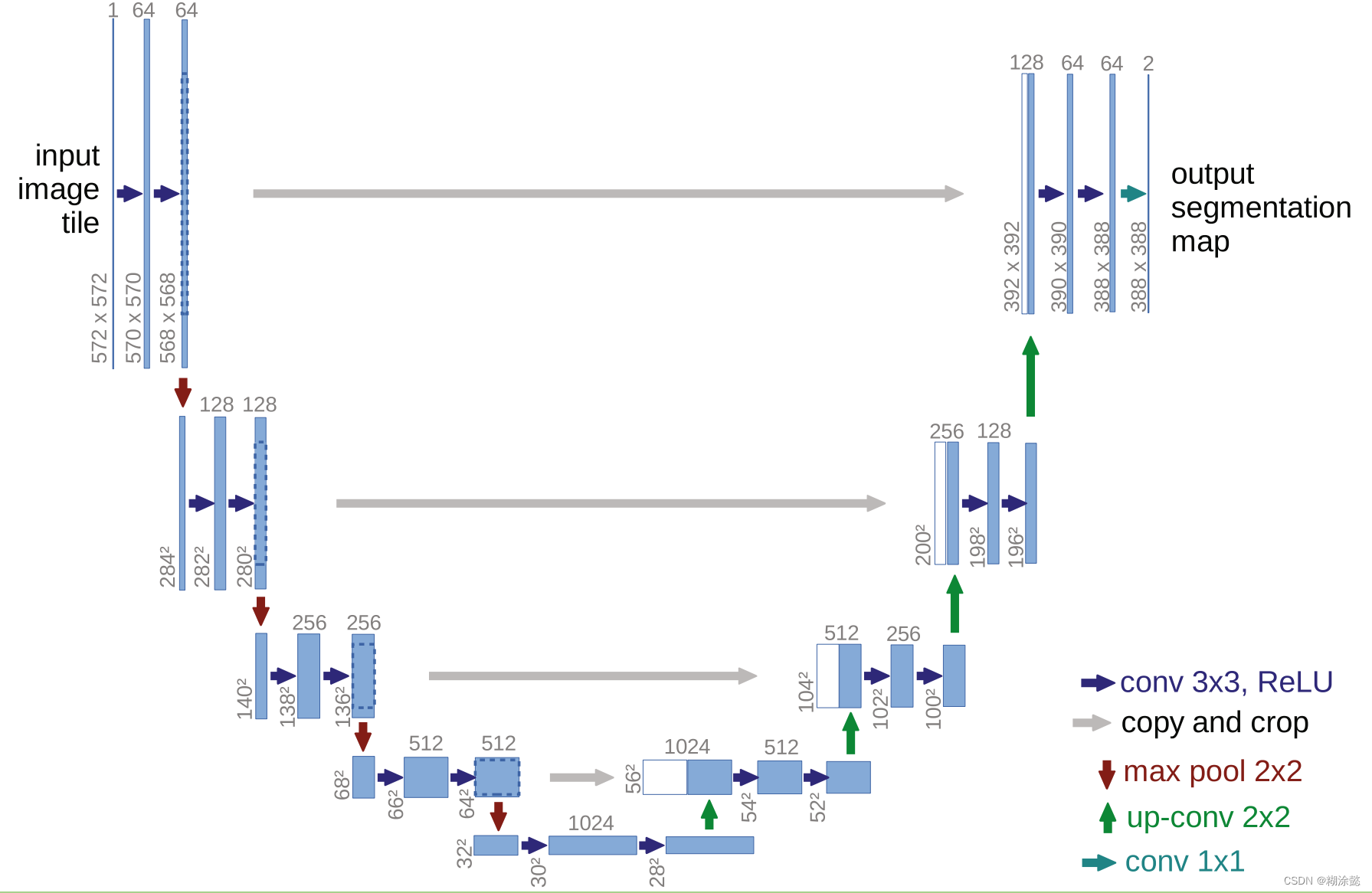
UNet++在U-Net的基础上,主要作出了三大改进:在跳跃连接路线中加入了卷积(下图中绿色的);在跳跃连接路径上加入了密集跳跃(下图蓝色);加入了深度监督(下图红色)。
卷积层的加入可以让编码器的特征映射和解码器的特征映射之间的语义差距缩小,不像直接从X0,0到X0,4差距这么大,从X0,0到X0,1语义会比较相似。密集的跳跃连接,可以改善梯度流。深度监督有利于剪枝,比如下图(c)所示。
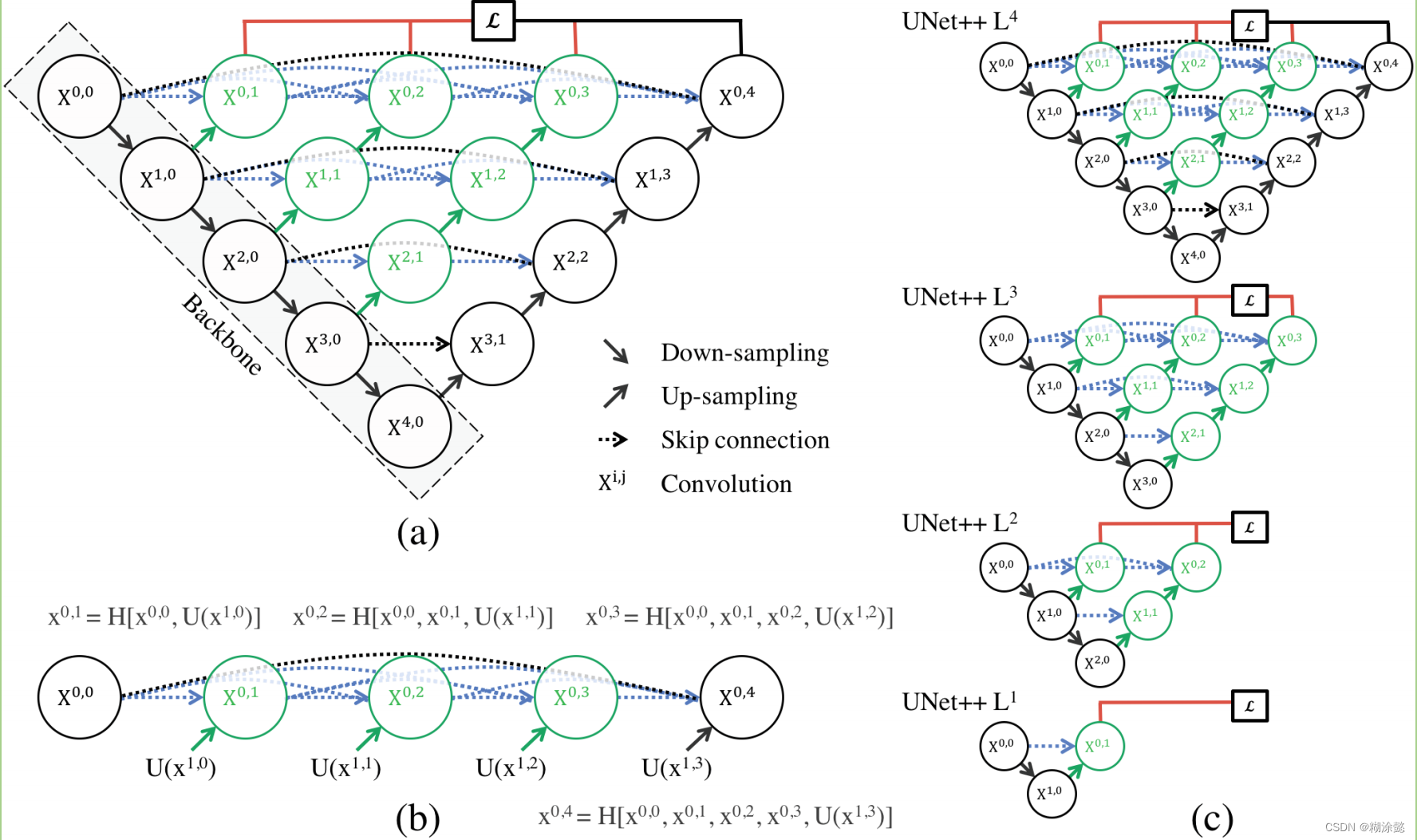
U2-Net被提出用于解决SOD(salient object detection)任务,即显著性目标检测任务,就是将图片中最吸引人的目标或区域分割出来,有点类似语义分割,但SOD任务是个二分类问题,只包含前景和背景这两大类。
U2-Net保留了U-Net的结构,只不过将每个Block的内部结构做了调整,有一部分被换成了一个U-Net,文中称为RSU,有一部分被换成了RSU-4F;同时对整个结构的输出做出调整,将每个阶段的预测输出进行融合。
En_5、En_6、De_5不再下采样是因为担心丢失过多信息,所以内部并未改变特征图的大小,采用了空洞卷积。
对我很有启发的视频链接: U-Net的理解、 UNet++的理解、 U2_Net的理解
3. SegNet
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
SegNet的优势:节省内存空间;不会丢失边界信息。仍然仅使用卷积层,未添加全连接层。
采用Encoder-Decoder结构,编码器网络采用VGG16的13个卷积层结构,解码器网络后紧跟softmax分类,从而输出与输入原图大小一致的像素级别的分割图像。
个人认为其创新点在于Encoder-Decoder结构中的Decoder部分。下采样时存储了池化层的最大池化索引,这样在上采样时无需学习,直接按照索引去填最大值,其余位置补0,从而产生稀疏的特征图;再通过卷积去学习,生成稠密的特征图。

对我很有启发的blog链接: SegNet的理解
4. PSPNet, Pyramid Scene Parsing Network
Pyramid Scene Parsing Network
FCN网络仍然存在一些问题,如:将船识别成车辆,但如果理解了当前环境,就知道河上的肯定不是车辆,应该是船舶。因此,本文提出了场景解析scene parsing对于语义分割是很重要的。
主要思路就是下图,先通过带有膨胀策略的ResNet获得feature map,然后借鉴SPPNet的思路,将其金字塔池化成4个尺度,分别是1×1、2×2、3×3、6×6,再利用卷积层分别将其维度降低。然后通过双线性插值的方法进行上采样,再将上采样的结果和之前得到的feature map拼接,一起进行卷积,最终得到像素预测图。重要的模块就是Pyramid Pooling Module,借鉴了SPPNet的思路,但又加入了拼接操作,因此该模块最终输出的特征图既包含局部上下文信息,也包含全局上下文信息。

对我很有启发的blog链接: SPPNet的理解、 PSPNet的理解、膨胀卷积的理解
5. DeepLab v1、DeepLab v2、DeepLab v3、DeepLab v3+
这几篇论文分别对应于:
(DeepLab v1) Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
(DeepLab v2) DeepLab Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
(DeepLab v3) Rethinking Atrous Convolution for Semantic Image Segmentation
(DeepLab v3+) Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
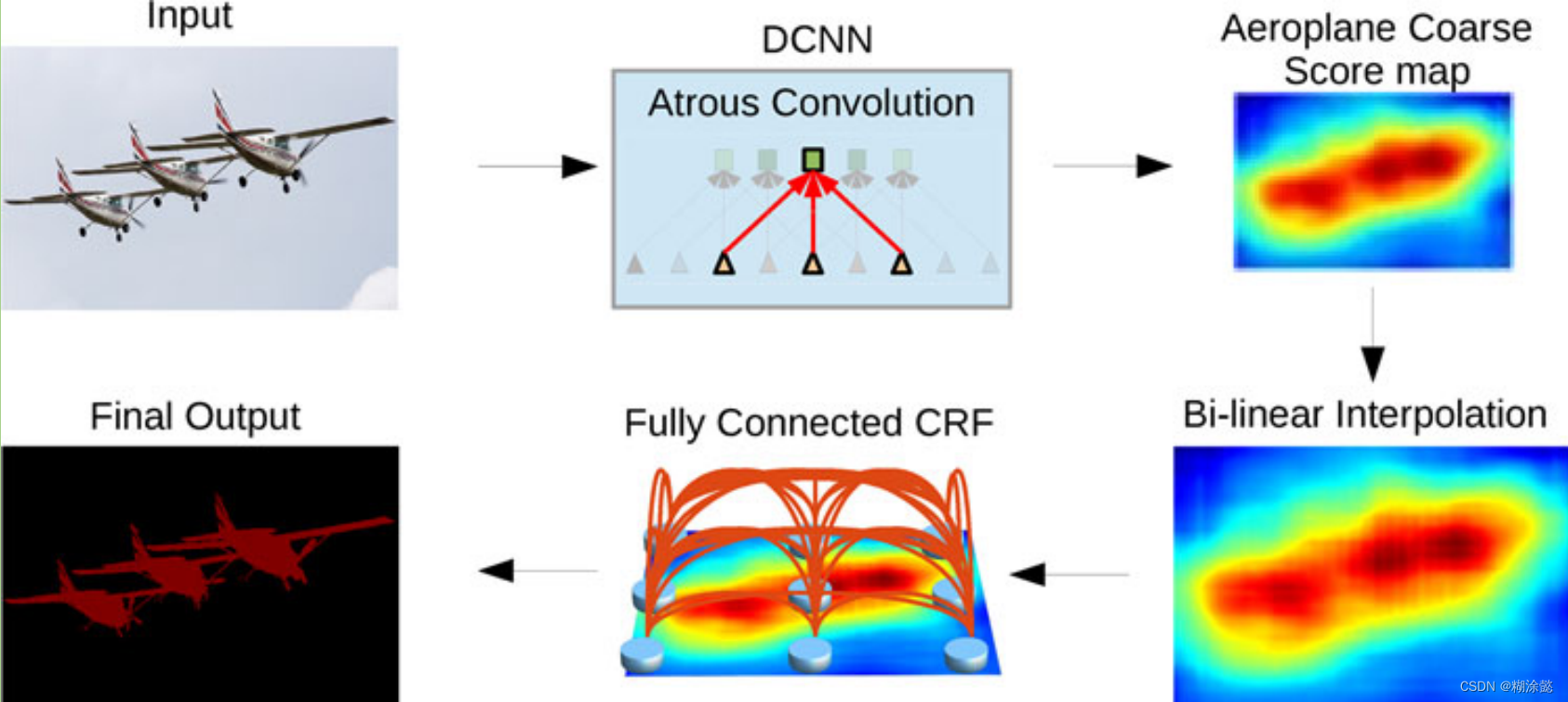
DeepLab v1采用空洞卷积,增大感受野;利用DCNNs和CRFs去实现识别与定位功能。
如果单纯使用DCNNs网络,会使特征图的空间网络分辨率明显降低。CRFs可以解决边界恢复问题,但因为后续没有再用CRFs了,所以没有对CRFs深入了解。
DeepLab v2相比DeepLab v1的不同在于:将backbone由VGG16换成ResNet-101;引入了ASPP,从多个尺度捕获对象和图像上下文。
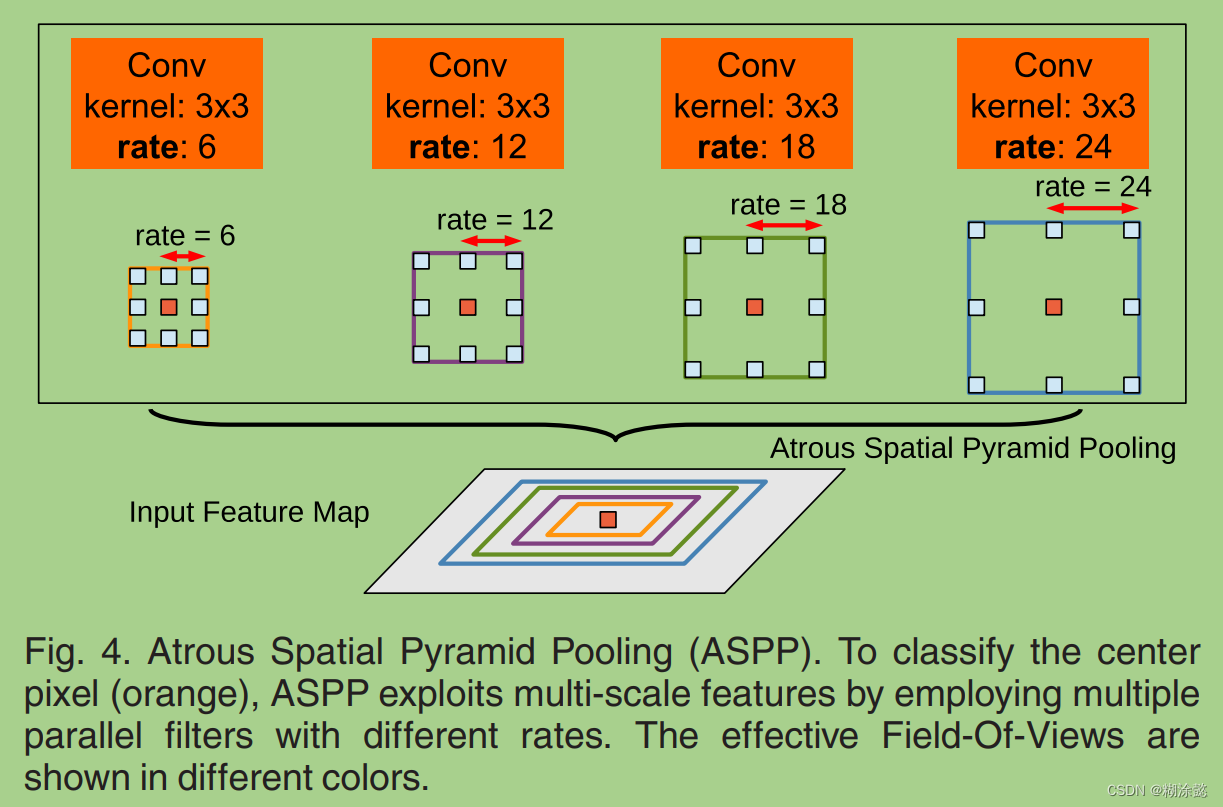
DeepLab v3相比DeepLab v2的不同在于:引入了multi-grid去定义空洞卷积的膨胀系数;改进了ASPP结构;移除CRFs后处理。
DeepLab v3对ASPP的改进在于它包含了五个并行的分支,分别为1×1卷积、3个膨胀卷积、1个全局平均池化,并且包含了batch normalization。然后将其五个分支进行拼接,再加入1×1卷积,得到该模块的最终特征图。

对我很有启发的blog链接: DeepLab v1的理解、 DeepLab v2的理解、 DeepLab系列的理解、 深度可分离卷积的理解
摘自一个博主的总结:DeepLab系列文章,最主要的是提出了空洞卷积和ASPP的概念,通过这两个策略的使用,DeepLab成功对的提升了语义分割领域的效果。但最应该关注的点并不是空洞卷积和ASPP,而是他们关注的两个问题,1)如何尽可能的在提取语义信息的时候不丢失空间信息。2)如何融合多尺度信息。
6. ESPNet, Efficient Spatial Pyramid
ESPNet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
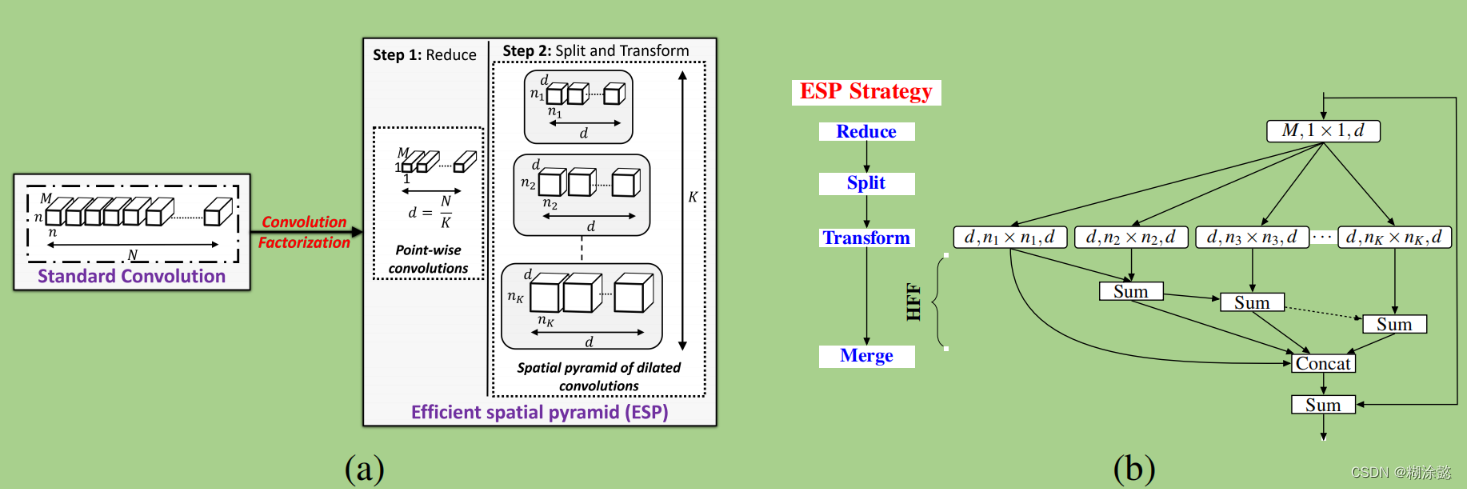
ESPNet提出将普通卷积分解成多个操作,可以降低DCNNs的计算复杂度,即convolution factorization。
ESPNet将普通卷积分解成逐点卷积和膨胀卷积的空间金字塔操作,再通过HFF模块分层叠加不同膨胀因子得到的特征图。
二、一些先进的算法
目前一些语义分割的先进算法大多都是与Transformer模块相结合。
1. ViT, Vision Transformer
An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
这篇论文题目为《An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale》,先解读一下题目:将图片分成多个16×16的patch,然后将其输入至自然语言处理中的Transformer模块中,就可以把图片看做文字,从而借用NLP中处理的操作。所以题目说An Image is Worth 16×16 Words。这样做的目的在于:举个例子,一张256×256×3的图像,如果直接将每个像素点都输入至Transformer Encoder模块中,那么将会产生很大的计算量;如果将图像分成多个16×16×3的图像块patch,那么这张图像就可以看作有14×14(256/16=14)个,即196个图像块。计算量将会大大减少。
除此之外,在NLP领域中,“我喜欢狗”和“狗喜欢我”是不一样的,因此文字的位置也很重要。ViT也用到了这个模块,即位置编码Position Embedding。
为了得到Transformer Encoder模块的输出,而不是多个head的输出,引入了[class] embedding,用它来学习其它embeddings中有用的信息,最终经过Transformer Encoder模块输出的MLP Head是根据[class] embedding的输出作为最后的输出特征。因此,其实输出至Transformer Encoder模块的是196+1=197个序列长度。
上面讲的都可以在下面左图ViT中体现,下面讲一讲右边的Transformer Encoder模块。将197个Embedded Patches输入至该模块,先经过一个层归一化layer normalization;然后输入多头注意力模块,该模块包含缩放点积注意力模块,也就是通过自注意力模块,即自身的点积来使大的值更大,小的值更小,从而拉大了大的和小的值的差距,可以更高效地学习显著的特征。多头注意力模块是从通道维度进行划分的,比如输入的一个patch是40×1×1000的,有4个头,那么每个头输入的均为40×1×250大小的(1000/4=250)。然后经过多头注意力模块输出40×1×1000的feature map。接着是与输入简单加在一起,不改变图像大小,对应位置相加而已。然后再经过层归一化,全连接层,相加。最后输出,输出的大小和输入的patch大小不变,所以可以叠加多个Transformer模块。

对我很有启发的学习视频链接: ViT的理解
2. SETR, SEgementation TRansformer
Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
ViT用于图像分类。SETR是基于ViT的语义分割的第一个代表模型,DETR是基于ViT的目标检测的代表模型。
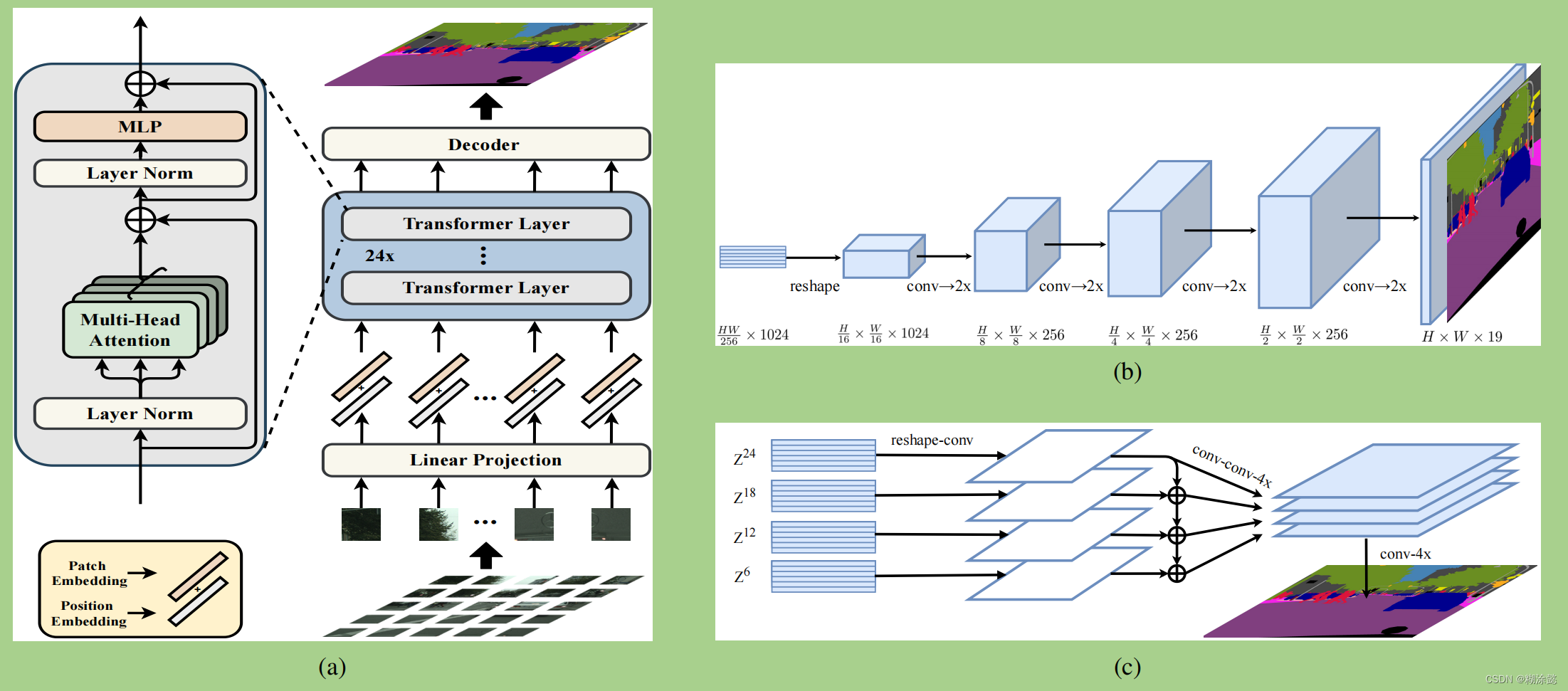
SETR提出以纯Transformer作为编码器,并提出了三种解码器结构,分别为直接双线性线性插值至原图大小(SETR-Naive)、渐进式上采样(SETR-PUP,下图(b)所示)、多层次特征融合(SETR-MLA,下图(c)所示)。
PS:与ViT不同的是,Transformer模块输出的并不是一个class embedding的结构,而是所有序列的结果。因为后续需要去decoder,所以这块是不一样的。
接下来再看一下DETR,DEtection TRansformer
End-to-End Object Detection with Transformers

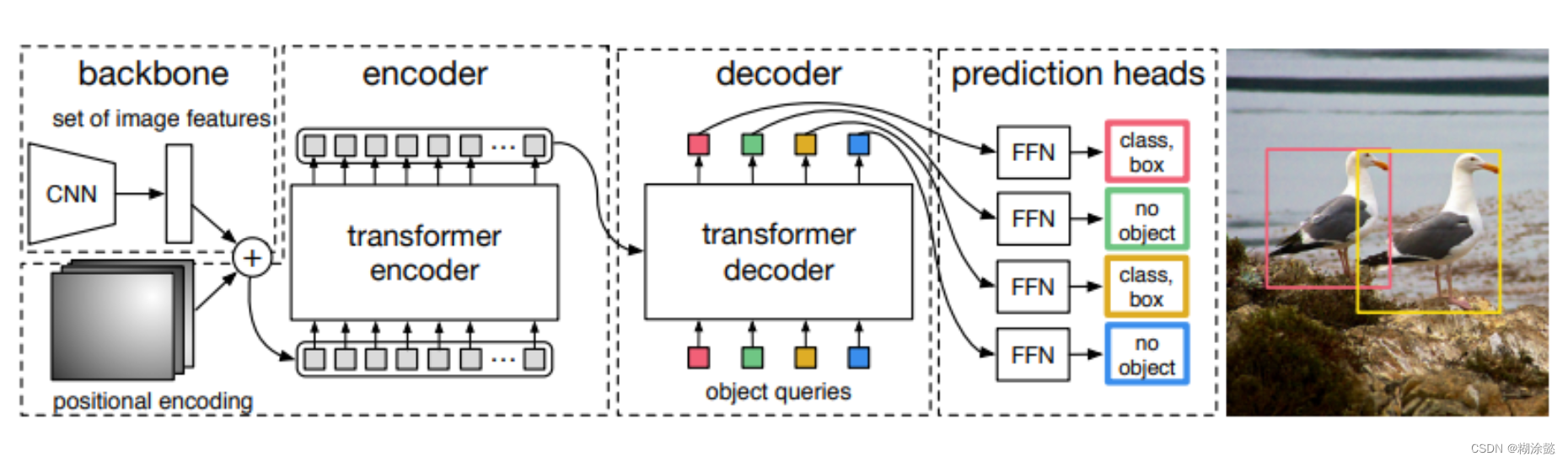
这一块我也不是很明白了,创新点之一在于set prediction并行预测。并且positional encoding对DETR很重要,在encoder和decoder内都加入了位置编码信息。还想深入学习的可以看下面DETR的链接里面的介绍吧。
对我很有启发的blog链接: SETR:基于视觉 Transformer 的语义分割模型、 重新思考语义分割范式——SETR、DETR详解
3. Segmenter
Segmenter: Transformer for Semantic Segmentation
提出了一种纯Transformer的Encoder-Decoder结构用于语义分割模型。
Segmenter的Encoder是在ViT的基础上提出的,将图片分成多个小块,将每个patch拉平为一维向量(Flatten),然后线性投影到patch embedding上(Project),再加入位置编码,一并传至Encoder模块。但是Encoder的输出依赖于所有的图像patches,并不是像ViT那样引入一个embedding输出它的结果。
Segmenter的Decoder提出了两种,一种是point-wise linear decoder,一种是Mask Transformer。以下只介绍Mask Transformer。除了将Encoder输出的结果传至Decoder模块,还输入了类编码class embeddings。(读论文没太理解加入类编码的好处,但一定是有利的。有兴趣的小伙伴可以一起讨论一下。)
Decoder输出后的结果,进行标量积scalar product处理,得到K个掩码(种类数为K)。然后双线性上采样(Upsample),得到特征映射,再在类维度上加一个softmax和Layer Norm,得到像素级的类得分,形成最终的分割图。

对我很有启发的blog链接: Segmenter论文解读、 Segmenter
4. SegFormer
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
仍然是以Transformer模块搭建的Encoder,但是没有很负责的Decoder结构,仅用了6个MLP层构成Decoder。
SegFormer的Encoder采用分层级结构,融合了不同分辨率的特征,并且没有加入位置编码,而是采用overlap patch来学习相邻patches之间的关系。
其Decoder较为简单,因为self-attention已经足够扩大感受野了,没有必要再在decoder中加入一些可以扩大感受野的结构,所以就采用四个MLP层分别处理encoder输出的四层,接着拼接concate,然后再经过一个MLP层去融合,得到通道数为C的特征图。最后经过一个MLP层去预测,得到通道数为类别数的特征图。最后输出的结果是原图的四分之一高、宽。

对我很有启发的blog链接: SegFormer: 简单有效的语义分割新思路
5. MaskFormer、Mask2Former
(MaskFormer): Per-Pixel Classification is Not All You Need for Semantic Segmentation
(Mask2Former): Masked-attention Mask Transformer for Universal Image Segmentation
在此之前,需要补一些有关 R-CNN、Fast R-CNN、Faster R-CNN、Mask R-CNN的知识,这些介绍都包含在我的另一篇blog: 【基于视觉的分割】实例分割初探索:一些经典和先进的算法
接下来回归MaskFormer和Mask2Former论文的解读。
MaskFormer:
MaskFormer提出:自FCN提出以来语义分割任务就被当做逐像素的分类任务per-pixel classification,而MaskFormer旨在可以把语义分割任务当做一个掩码分类的任务mask classification,从而可以统一解决语义分割任务和实例分割任务的步骤。
不同于语义分割任务,对每一个像素去预测类别概率,从而为当前像素选择一个概率最大的类别。MaskFormer预测一系列的二元掩码binary mask,而对于每个二元掩码都会预测一个类别。
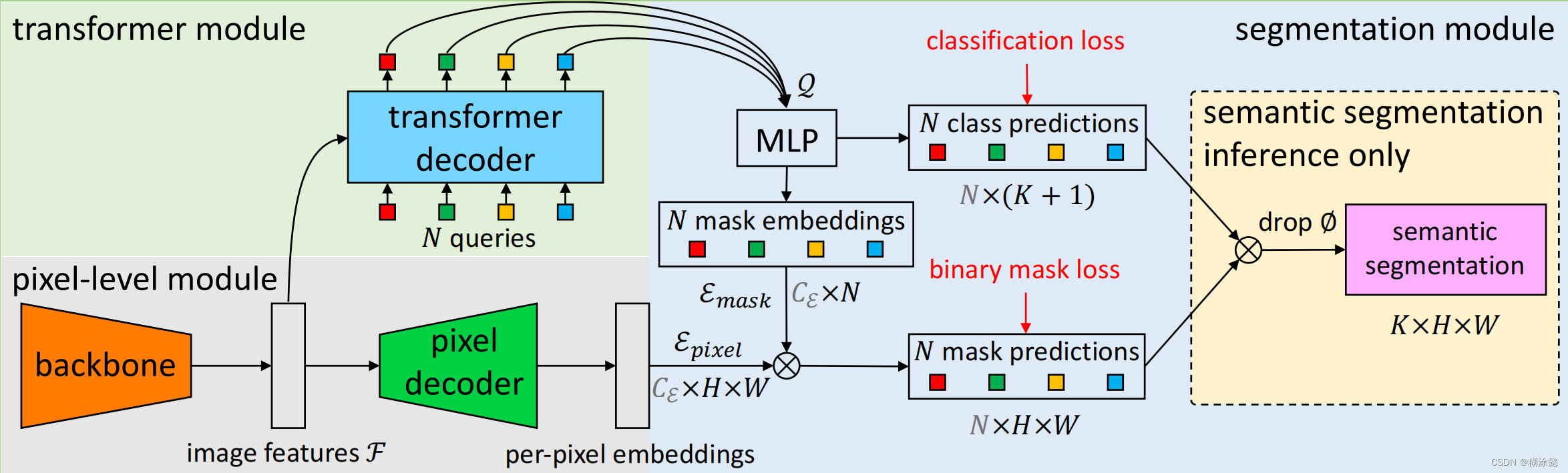
那么MaskFormer如何解决mask classification任务呢?如下图所示,MaskFormer由三部分组成:pixel-level module、transformer module、segmentation module。
pixel-level module将输入的图片经过backbone(文中用的是ResNet)得到特征图,然后经过pixel decoder(文中用FPN框架)提取每个像素的编码。
transformer module利用特征图作为输入,传入transformer decoder(文中用的是Swin - Transformer),并将其划分为N个不同的区域(N大于类别K)。
segmentation module将N个区域得到的类别预测(K+1,包含∅)和mask预测利用矩阵乘法结合在一起,并去掉∅,得到最终的预测结果。
Mask2Former:
作者针对MaskFormer统一了全景分割、实例分割、语义分割的框架,但应用并不广泛的问题,分析原因如下:MaskFormer的效果比专门的针对特定分割任务的算法弱,并且训练效率较低。
因此针对算法性能(performance)和训练效率(training efficiency)提升的目标,作者在MaskFormer的基础上提出了Mask2Former。
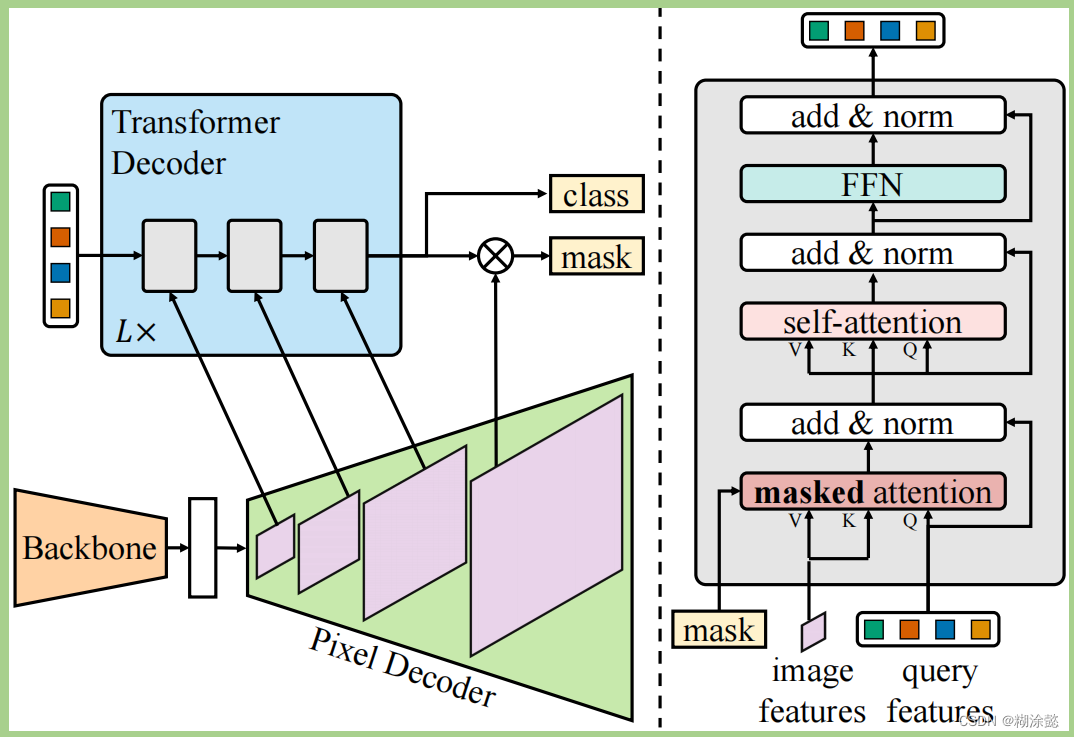
Mask2Former的改进在于:
① 在Transformer Decoder中用了masked attention代替常用的cross-attention,不用和图片上每个位置做注意力,只和附近区域做即可;
② 使用多尺度高分辨率特征,从而有助于小物体或小区域的分割;
③ 提出了一些优化提升方法,比如改变self-attention和cross-attention的位置、使query features是可学习的、去掉droppout;
④ 在较少随机采样的点上计算mask loss,从而减少训练内存。
对我很有启发的blog链接: MaskFormer、选择性搜索算法 (Selective Search)、 语义分割:论文阅读:(2021-12)Mask2Former、 Mask2Former阅读笔记















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









