






随着大语言模型(LLM)的普及,如何结合企业私有知识库提升模型输出的准确性和专业性成为关键挑战。检索增强生成(Retrieval-Augmented Generation, RAG) 技术通过将外部知识库与生成模型结合,有效解决模型幻觉和时效性问题。本文将基于 LangChain4j(Java版LangChain框架)与火山引擎的 DeepSeek R1 模型,手把手搭建一个RAG知识库系统,并提供完整代码实现步骤。
一、注册火山引擎账号
访问地址:火山引擎官网访问
https://www.volcengine.com/experience/ark?utm_term=202502dsinvite&ac=DSASUQY5&rc=NL9E82YO
注册账号,注册即享免费token调用额度
点击控制台:
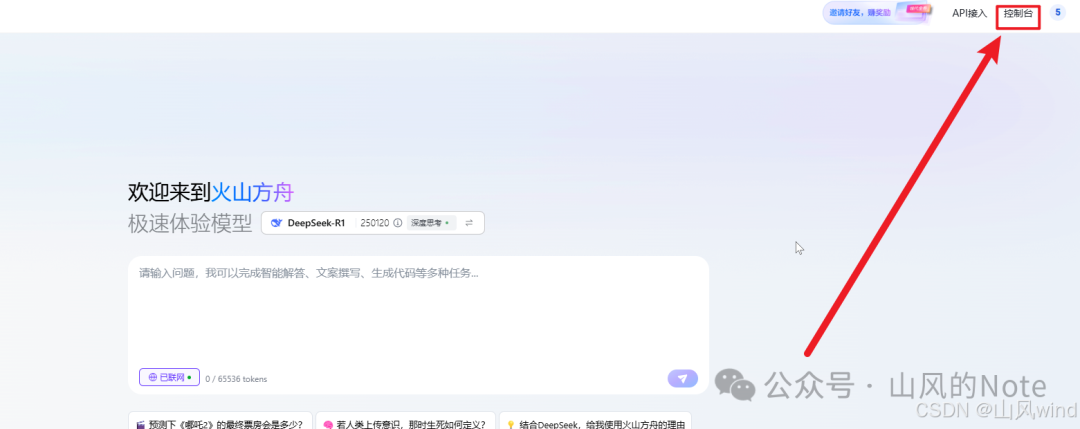
创建在线推理API key
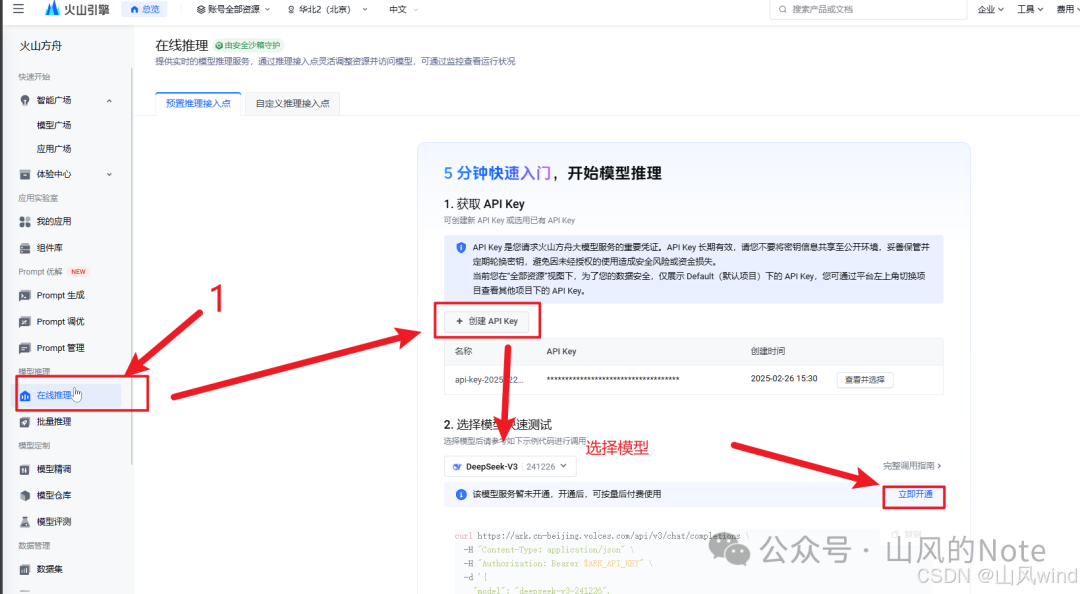
记住模型名称、地址,使用自己的key,后续代码要使用。
二、RAG技术核心原理
RAG通过以下流程增强大模型的生成能力:
-
- 检索(Retrieval):从向量数据库中检索与用户问题相关的文档片段。
-
- 增强(Augmentation):将检索结果作为上下文输入大模型。
-
- 生成(Generation):模型结合上下文生成最终答案。
优势:
-
• 数据安全性:知识库本地存储,无需上传至公网。
-
• 动态更新:可随时扩展知识库内容,无需重新训练模型。
三、环境与工具准备
1. 核心组件
| 工具/服务 | 作用 |
|---|---|
| LangChain4j | 提供RAG流程的模块化支持(文档加载、分块、检索链等) |
| 火山引擎DeepSeek R1 | 提供高性能开源LLM,支持API调用与本地部署 |
| 向量数据库 | 存储文档向量(示例使用内存数据库InMemoryEmbeddingStore) |
2. 依赖配置(Maven)
`<!-- LangChain4j 核心依赖 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-core</artifactId> <version>0.31.0</version> </dependency> <!-- 火山引擎DeepSeek集成 --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-openai</artifactId> <version>0.31.0</version> </dependency> <!-- 文本嵌入模型(示例使用Ollama) --> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-ollama</artifactId> <version>0.31.0</version> </dependency>`
四、代码实现步骤
步骤1:初始化DeepSeek模型
配置火山引擎API密钥与模型参数:
`String apiKey = "YOUR_VOLC_ENGINE_API_KEY"; String modelName = "deepseek-r1-250120"; String apiBaseUrl = "https://ark.cn-beijing.volces.com/api/v3/chat/completions"; ChatLanguageModel chatModel = OpenAiChatModel.builder() .apiKey(apiKey) .modelName(modelName) .baseUrl(apiBaseUrl) .build();`
步骤2:构建本地知识库
文档加载与分块:
// 加载本地文档(示例为TXT文件) Path documentPath = Paths.get("src/main/resources/knowledge.txt"); Document document = FileSystemDocumentLoader.loadDocument(documentPath); // 分块策略:每段500字符,重叠50字符 DocumentSplitter splitter = DocumentSplitters.recursive(500, 50, new OpenAiTokenizer()); List<TextSegment> segments = splitter.split(document); // 生成向量并存储 bge-m3的模型key也需要申请 EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder() .modelName("bge-m3") .apiKey("none") .baseUrl("url") .build(); EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); List<Embedding> embeddings = embeddingModel.embedAll(subList).content(); // 将嵌入结果存储到嵌入存储中 embeddingStore.addAll(embeddings, subList);
步骤3:执行RAG
String question = "如何配置火山引擎的DeepSeek模型?"; Query userQuery = Query.from(question); EmbeddingModel embeddingModel = OpenAiEmbeddingModel.builder() .modelName("bge-m3") .apiKey("none") .baseUrl("url") .build(); ChatLanguageModel openAiModel = OpenAiChatModel.builder() .apiKey(apiKey) .modelName(modelName) .baseUrl(apiBaseUrl) .build(); ContentRetriever retriever = EmbeddingStoreContentRetriever.builder() .embeddingStore(embeddingStore) .embeddingModel(embeddingModel) .maxResults(5) .minScore(0.6) .build(); List<Content> contentList = new ArrayList<>(); contentList.addAll(retriever.retrieve(userQuery)); ContentInjector contentInjector = new DefaultContentInjector(); UserMessage promptMessage = contentInjector.inject(contentList, userMessage); log.info("promptMessage: {}", promptMessage.singleText()); Response<AiMessage> generate = openAiModel.generate(promptMessage); log.info("AI响应: {}", generate);
五、效果验证与优化
1. 测试示例
输入问题:
“DeepSeek R1支持哪些部署方式?”
输出结果:
“根据火山引擎文档,DeepSeek R1支持两种部署方式:1) 在火山引擎机器学习平台(veMLP)中自定义部署;2) 通过火山方舟API直接调用预训练模型,适用于快速集成场景。”
2. 性能优化建议
-
• 分块策略:根据文档类型调整分块大小(如技术文档建议
chunk_size=800)。 -
• 混合检索:结合关键词检索(如Elasticsearch)与向量检索,提升召回率。
六、总结
本文通过 LangChain4j 与 火山引擎DeepSeek R1 实现了企业级RAG知识库的搭建。关键步骤包括:知识库向量化、检索链构建、模型集成。此方案既能保障数据隐私,又能动态扩展知识,适用于客服、内部知识问答等场景。
扩展方向:
-
• 接入企业数据库(如Doris)实现海量知识管理。
-
• 结合微调(Fine-tuning)进一步提升领域专业性。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 533
533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









