






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
【DeepQN】基于深度Q学习的连续世界与真实机器人模拟研究
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
【DeepQN】基于深度Q学习的连续世界与真实机器人模拟研究

1. 深度Q学习(DQN)的基本原理与核心结构
深度Q网络(Deep Q-Network, DQN)是深度强化学习的里程碑式算法,通过结合Q-learning与深度神经网络,解决了传统Q-learning在高维状态空间下的局限性。其核心思想是用神经网络代替Q表来近似Q值函数,并通过 经验回放(Experience Replay) 和 目标网络(Target Network) 提升稳定性。
-
Q网络与目标网络:
Q网络负责实时预测动作价值,而目标网络定期从Q网络复制参数,用于计算目标Q值,减少训练中的波动性。例如,目标Q值的计算为: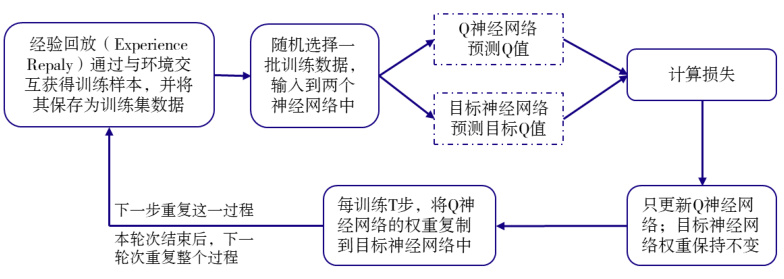
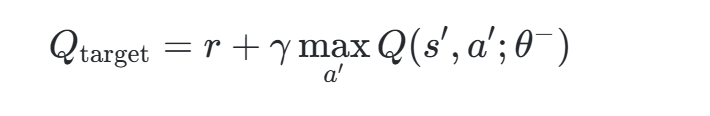
其中θ−为目标网络参数,γ为折扣因子。
-
经验回放机制:
通过与环境的交互数据存储到回放缓冲区,并随机抽样进行训练,打破数据间的相关性,避免过拟合。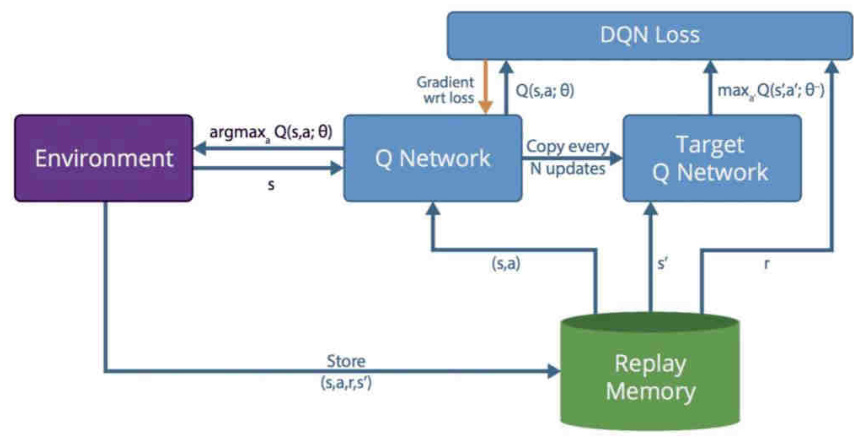
-
改进技术:
- Double DQN:分离动作选择与Q值评估,缓解Q值高估问题。
- Dueling DQN:将Q值分解为状态价值(V(s))和动作优势(A(s,a)),提升策略表达的清晰度。
2. 连续状态与动作空间的处理方法
在真实机器人场景中,状态和动作空间通常是连续的(如关节角度、速度),传统DQN需进行扩展或结合其他方法:
-
状态空间连续化:
- 函数逼近:DQN通过神经网络直接处理连续状态,如将激光雷达点云或图像输入卷积网络。
- 离散化妥协:将连续状态划分为离散区间,但可能引发维度灾难或精度损失。
-
动作空间连续化:
DQN原生仅支持离散动作,需改进算法:- DDPG(深度确定性策略梯度) :结合Actor-Critic框架,Actor网络输出连续动作,Critic网络评估动作价值。
- P-DQN(参数化DQN) :处理混合动作空间(如离散动作选择+连续参数调节),通过分离动作决策层与参数优化层实现。
- NAF(归一化优势函数) :通过设计特定网络结构直接输出连续动作的Q值。
3. 真实机器人模拟的仿真平台对比
以下平台为DQN在机器人控制中的主要仿真环境:
| 平台 | 编程语言 | 物理引擎 | ROS兼容性 | 适用场景 | |
|---|---|---|---|---|---|
| Gazebo | C++/Python | ODE/Bullet/Simbody | 支持 | 复杂环境导航、多机器人协作 | |
| MuJoCo | Python/C++ | MuJoCo引擎 | 需插件 | 高精度机械控制(如机械臂) | |
| PyBullet | Python | Bullet | 支持 | 轻量化强化学习训练 | |
| CoppeliaSim | Lua/Python | Vortex/Bullet | 支持 | 多机器人仿真、工业自动化 | |
| Unity ML-Agents | C#/Python | PhysX | 需桥接 | 高保真视觉仿真(如自动驾驶) |
典型应用案例:
- Gazebo:用于移动机器人路径规划,结合DQN优化避障策略。
- MuJoCo:在连续控制任务中验证DDPG算法,如双足机器人行走。
- PyBullet:通过轻量化接口实现机械臂抓取任务的Sim2Real迁移。
4. 连续世界与离散世界的强化学习差异
| 维度 | 离散世界 | 连续世界 |
|---|---|---|
| 状态空间 | 有限离散状态(如网格坐标) | 无限连续状态(如传感器数据流) |
| 动作空间 | 有限动作集合(如上下左右) | 连续动作向量(如扭矩、速度) |
| 算法选择 | DQN、Q-learning | DDPG、PPO、SAC、改进DQN(如P-DQN) |
| 挑战 | 维度爆炸(状态数指数增长) | 策略收敛困难、局部最优陷阱 |
例如,倒立摆问题中,连续状态(角度、角速度)需通过函数逼近建模,而离散化可能导致控制精度不足。
5. 现有研究综述与前沿方向
-
经典研究:
- DeepMind(2013)首次将CNN与Q-learning结合,在Atari游戏中实现超越人类的表现。
- DDPG(2015)扩展DQN至连续动作领域,解决20+物理仿真任务。
-
机器人应用:
- 机械臂控制:使用DQN+DDPG在MuJoCo中实现抓取任务,Sim2Real误差<5%。
- 自动驾驶:Unity ML-Agents结合DQN训练多车协同避障策略。
-
未来方向:
- 多模态输入融合:结合视觉、触觉等多传感器数据提升状态表征能力。
- 元强化学习:通过少量样本适应新任务,减少仿真到现实的差距。
6. 挑战与解决方案
-
数据效率:
通过 优先经验回放(Prioritized Experience Replay) ,优先训练高TD误差样本,加速收敛。 -
仿真与现实的差异:
采用 域随机化(Domain Randomization) ,在仿真中随机化物理参数(如摩擦系数),提升策略鲁棒性。 -
高维动作空间:
使用 分层强化学习(HRL) ,将任务分解为子策略,降低决策复杂度。
7. 结论
DQN及其改进算法(如DDPG、P-DQN)为连续世界中的机器人控制提供了理论基础,而Gazebo、MuJoCo等仿真平台则为算法验证与迁移提供了高效环境。未来研究需进一步解决数据效率、Sim2Real差距及多任务泛化等挑战,推动深度强化学习在真实机器人场景中的落地应用。
📚2 运行结果
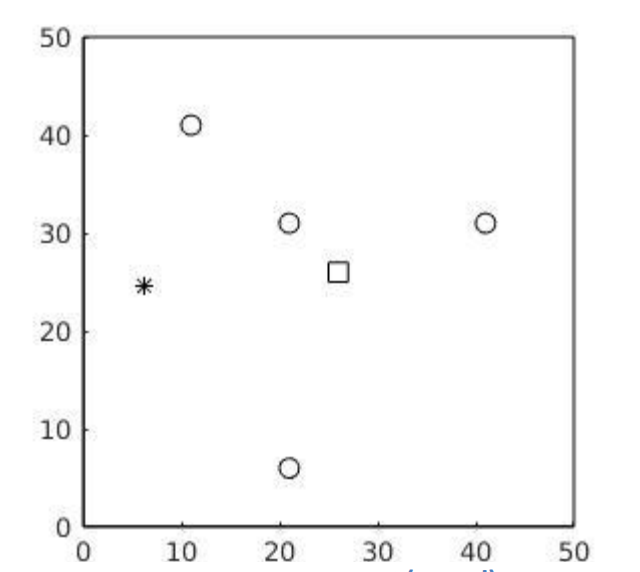
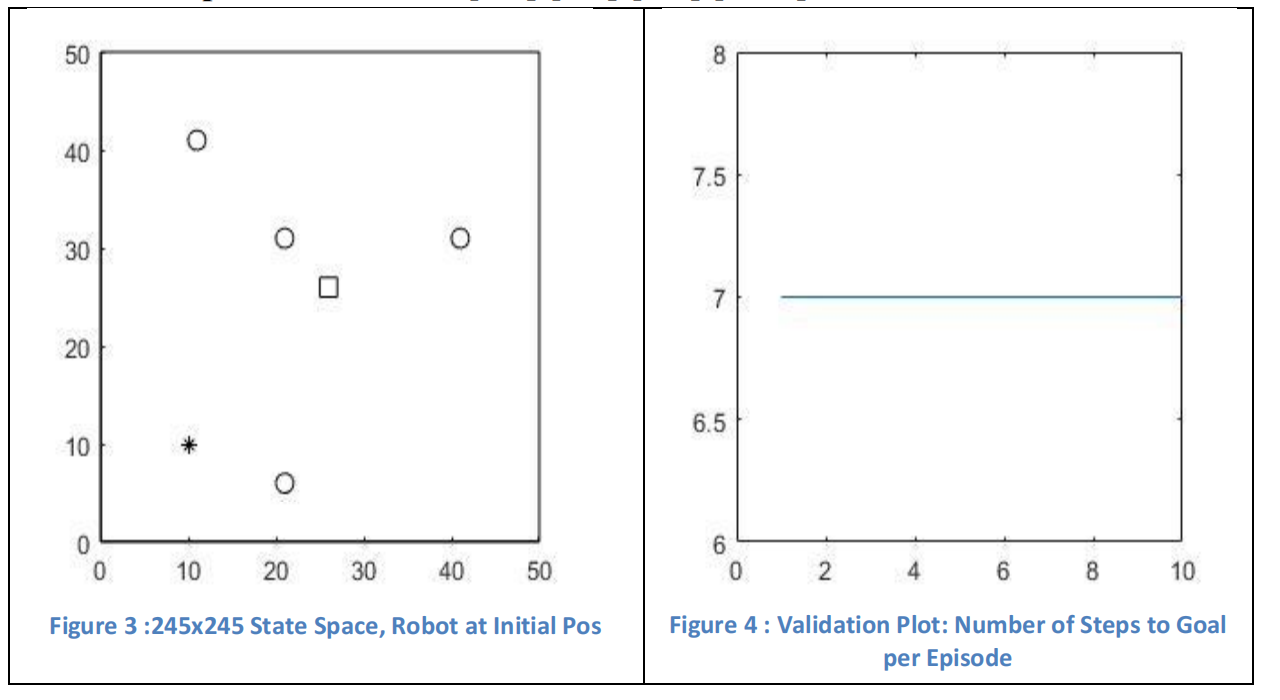
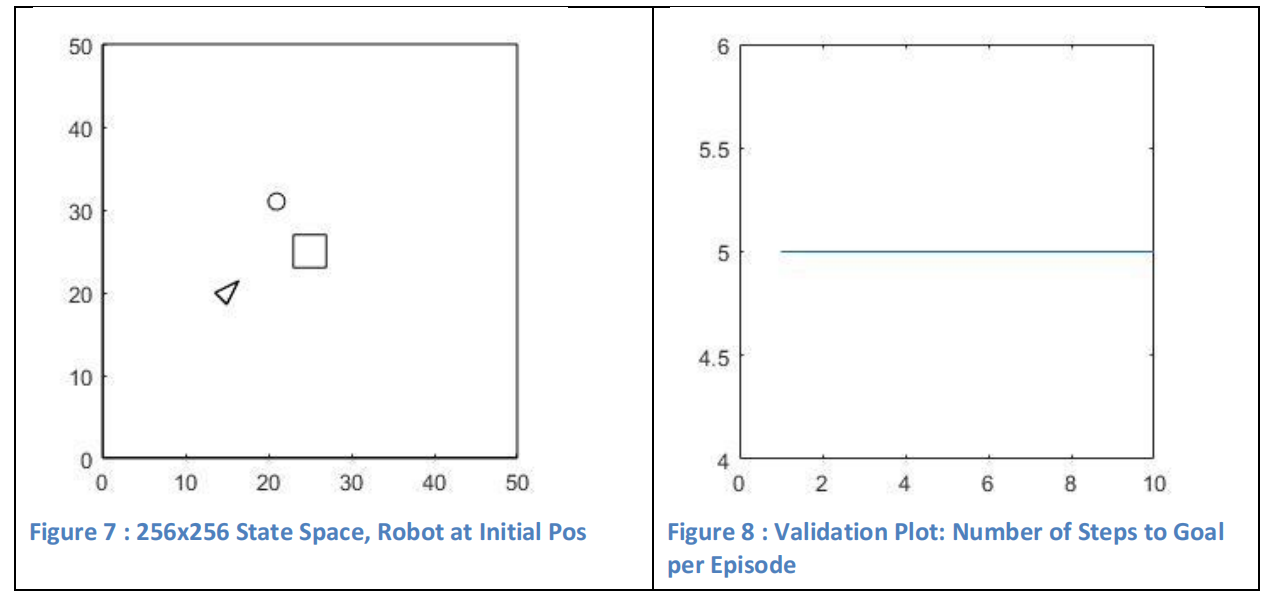

部分代码:
%Initialize the environment:
clear all
close all
X=[20;25;pi/4];
%figure('Position',[0 0 631 600]) %size to get 489x489 image saved from fig
figure('Position',[0 0 316 300]) %size to get 245x245 image saved from fig
F = getframe;
[I,Map] = frame2im(F);
while(1) %forcing to get a image of 489x489
close all;
figure('Position',[0 0 316 300]);
F = getframe;
[I,Map] = frame2im(F);
if(size(I,1)==245 && size(I,2)==245)
break;
end
end
%figure('Position',[0 0 526 500])
%figure('Position',[0 0 316 300])
rectangle('Position',[0,0,50,50]);
rectangle('Position',[25,25,2,2],'EdgeColor','k');
rectangle('Position',[10,40,2,2],'Curvature',[1 1]);
rectangle('Position',[20,30,2,2],'Curvature',[1 1]);
rectangle('Position',[20,5,2,2],'Curvature',[1 1]);
rectangle('Position',[40,30,2,2],'Curvature',[1 1]);
%plot(X(1),X(2));
hold on
p = plot(X(1),X(2),'k*');
%p=plot(X(1),X(2),'r*');
hold off
%%
% Perform random actions to generate Get Data for Training the CNN first
% time, This is analogous to Initializing the CNN with random weights.
for i=1:10
action=choose_random_action_old();
% X=[10;10;pi/4]; %can be randomized later
X=[randi([4 46]);randi([4 46]);randi([1 6])*rand()]; %randomized state
X=stateUpdate_DQN(X,action);%timestep of 1 unit
reward(:,:,:,i)=get_reward_old(X,action);%reward must be a(1x1x4) output here, for 4 actions, (as required by CNN-MATLAB)
%rewards act as random targets!
set(p,'XData',X(1));
set(p,'YData',X(2));
%p.Xdata = X(1); %MAY HAVE TO USE THESE ones IN SOME MATLAB VERSION
%p.Ydata = X(2);
drawnow;
% rectangle('Position',[X(1)-1,X(2)-1,2,2]);
F = getframe;
[I,Map] = frame2im(F);
states(:,:,:,i)=rgb2gray(I);
% pause(0.1);
end
for i=1:50 %getting more DATA
action=choose_random_action_old();
X=[randi([4 46]);randi([4 46]);randi([1 6])*rand()]; %randomized state
X=stateUpdate_DQN(X,action);%timestep of 1 unit
reward2(:,:,:,i)=get_reward_old(X,action);%reward must be a(1x1x4) output here, for 4 actions, (as required by CNN-MATLAB)
%rewards act as random targets!
set(p,'XData',X(1));
set(p,'YData',X(2));
drawnow;
F = getframe;
[I,Map] = frame2im(F);
states2(:,:,:,i)=rgb2gray(I);
% pause(0.1);
end
%%
%Define the convolutional neural network architecture.
layers = [
%imageInputLayer([489 489 1],'Name', 'input')
imageInputLayer([245 245 1],'Name', 'input')
convolution2dLayer(8,8,'Padding',1,'Name', 'conv1')
batchNormalizationLayer('Name', 'Batch_N')
reluLayer('Name', 'relu1')
%maxPooling2dLayer(2,'Stride',2,'Name', 'maxPool1')
convolution2dLayer(4,4,'Padding',1,'Name', 'conv2')
batchNormalizationLayer('Name', 'Batch_N2')
reluLayer('Name', 'relu2')
%maxPooling2dLayer(2,'Stride',2,'Name', 'maxPool2')
convolution2dLayer(4,4,'Padding',1,'Name', 'conv3')
batchNormalizationLayer('Name', 'Batch_N3')
reluLayer('Name', 'relu3')
%fullyConnectedLayer(512,'Name', 'FullyC')% size is eual to number of actions
fullyConnectedLayer(4,'Name', 'FullyC2')% size is eual to number of actions
regressionLayer('Name','Output')];
options = trainingOptions('sgdm', ...
'MaxEpochs',1, ...
'InitialLearnRate',0.001, ...
'Verbose',false, ...
'Plots','training-progress');
net = trainNetwork(states,reward,layers,options);
layersTransfer = net.Layers(1:end);
net = trainNetwork(states,reward,layersTransfer,options);
%used previously generated random States,Rewarrd to train,
%thus the network is initialized and ready for DQN
%% TRAINING
options = trainingOptions('sgdm', ...
'MaxEpochs',1, ...
'InitialLearnRate',0.01, ...
'Verbose',false, ...
'Plots','none'); %to supress plot occuring at each step when CNN is trained
Max_episodes=20;
Max_steps=100;
gamma_learning=0.002; % for the target equation :target_st=reward_st+gamma*maxQ_new;
epsilon=0.8; %e-greedy algorithm factor t choose action
for ep=1:Max_episodes
%set intitial position
%X=[10;10;randi([1 6])*rand()]; %can be randomized later
if(ep<10)
X=[randi([4 46]);randi([4 46]);randi([1 6])*rand()];
else
X=[randi([4 46]);randi([4 46]);randi([1 6])*rand()];
end
set(p,'XData',X(1));
set(p,'YData',X(2));
drawnow;
Net_reward(ep)=0;
for st=1:Max_steps
%acquire current state image,
F = getframe;
[I,Map] = frame2im(F);
state(:,:,:,1)=rgb2gray(I);
%can use below created state_new variable instead of getting frame again,
%will se later!!!!
%do a full forward pass through CNN.
Q_st=predict(net,state(:,:,:,1));% acquire Q values for all acitons
Q_st(isnan(Q_st)) = 10; %Removeing NAN values
%state(:,:,:,2)=zeros(245,245);
%Q_st_extra=predict(net,state(:,:,:,2));%Targets forthe extra layer,
%adding extra layer of zeros to get 255*255*1*4 dim'n forCNN-MATLAB
%WHY ZERSOS/ONES!!,, THIS CAN CAUSE WHOLE LOT OF TROUBLE IN WEIGHTS
%BETTER DUPLICATE ABOVE LAYER ITSELF!
state(:,:,:,2)=rgb2gray(I);
Q_st_extra=predict(net,state(:,:,:,2));
Q_st_extra(isnan(Q_st_extra)) = 10;
% choose action to do
[~,act_st]=max(Q_st);%index of max Q value gives the desired action to do!
if rand()<(epsilon/(ep-epsilon*(ep))) %e-greedy algo, reducing epsilon
act_st = randi([1 4],1);
end
X=stateUpdate_DQN(X,act_st);%timestep of 1 unit
reward_st=get_reward_simple(X);%reward must be a single output here
%get new state
set(p,'XData',X(1));
set(p,'YData',X(2));
%p.Xdata = X(1); %MAY HAVE TO USE THESE ones IN SOME MATLAB VERSION
%p.Ydata = X(2);
drawnow;
F = getframe;
[I,Map] = frame2im(F);
state_new(:,:,:,1)=rgb2gray(I);
%do a full forward pass through CNN.
Q_st_new=predict(net,state_new);% acquire Q values for all acitons
Q_st_new(isnan(Q_st_new)) = 10;
[maxQ_new,~]=max(Q_st_new);%is the max possible Q_value for next state
%set Targetx for CNN
%for all actions, default target is the Q value predicted, so loss
%is zero(computed inside the CNN), hence no weights updated
target(:,:,1:4,1:2)=0; %extra 2nd layer embedded for getting dim'n as 1*1*4*2
target(:,:,1,1)= Q_st(1);target(:,:,2,1)= Q_st(2);
target(:,:,3,1)= Q_st(3);target(:,:,4,1)= Q_st(4);
target(:,:,1,2)= Q_st_extra(1);target(:,:,2,2)= Q_st_extra(2);
target(:,:,3,2)= Q_st_extra(3);target(:,:,4,2)= Q_st_extra(4);🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]张福祥.基于深度强化学习的MEC中多目标任务卸载问题研究[D].西南交通大学,2023.
[2]孙悦隽.基于深度强化学习的边缘缓存策略研究[D].杭州电子科技大学,2021.
🌈4 Matlab代码、文档下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









